Choosing a deep learning framework for manufacturing defect detection is not the same as choosing one for computer vision research. Research frameworks optimize for flexibility, rapid iteration, and publication-grade accuracy benchmarks. Manufacturing inspection, however, requires sub-50 ms edge inference, fewer than ten labeled defect samples per category, and deterministic performance across tens of thousands of parts per shift.
The frameworks that dominate AI research, and the specialized platforms purpose-built for production lines, are designed for different constraints. This comparison covers both categories. Published benchmarking in the Journal of Intelligent Manufacturing confirms that selecting the correct deep learning architecture and framework for a specific industrial application materially affects detection accuracy, with mAP scores on the standard NEU steel surface dataset ranging from 70% for older rule-based approaches to over 98% for optimized deep learning systems.
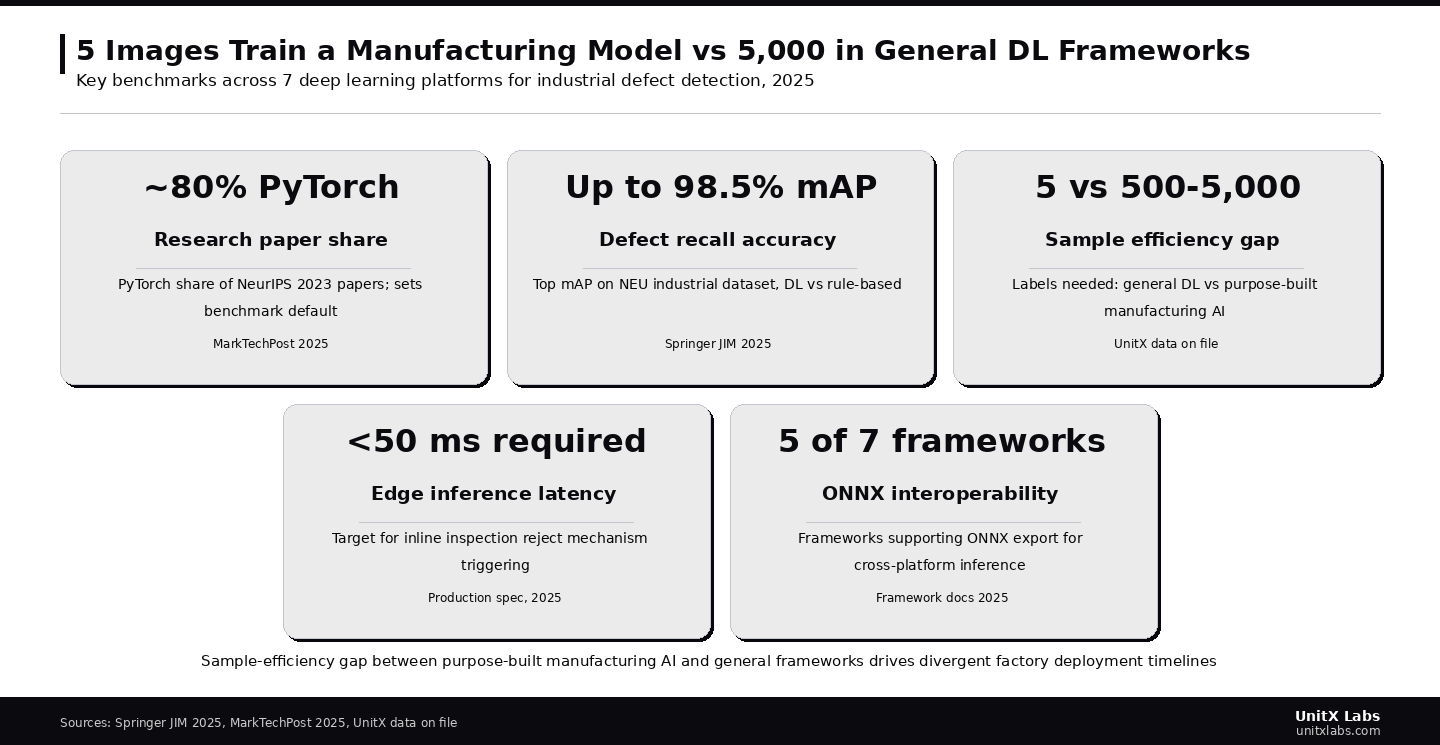
The seven frameworks below are assessed using four criteria relevant to manufacturing deployment: training data requirements, edge inference latency, ONNX interoperability, and time from dataset to production model.
Key Takeaways
- General deep learning frameworks (PyTorch, TensorFlow) typically require 500 to 5,000 labeled images per defect category to achieve reliable production performance, which is often impractical on production lines where defect events are rare by design.
- ONNX export is now supported across five of the seven frameworks, enabling model portability from research environments to production inference runtimes without retraining.
- Edge inference latency below 50 ms is achievable with TensorRT, OpenVINO, and purpose-built manufacturing platforms such as CorteX, but it requires hardware-specific optimization that standard PyTorch or TensorFlow models do not provide out of the box.
- Purpose-built manufacturing AI platforms address the sample-efficiency and deployment-speed gap by handling lighting diversity, model versioning, and PLC integration as first-class features rather than add-on engineering tasks.
Why Framework Selection Matters More in Manufacturing Than in Research
In research settings, deep learning engineers can collect thousands of labeled samples, train models over days or weeks on multi-GPU clusters, and continuously iterate on model architectures. In manufacturing inspection, however, a quality engineer often needs to configure a working model before the next production run. Defect samples are rare by design on well-controlled lines. The inspection station must make a binary pass or fail decision in under 50 ms. Retraining must happen without production line downtime.
These constraints fundamentally change how frameworks are evaluated. A framework that achieves state-of-the-art mAP on academic benchmarks using 10,000 labeled training images may be less useful than a platform that achieves 97% recall with only 5 labeled images. Research published in Scientific Reports demonstrates that attention-guided hybrid learning approaches, which combine supervised and unsupervised signals, can substantially reduce the labeled data requirements for manufacturing defect classification compared to purely supervised methods. Research published in Frontiers in Artificial Intelligence further confirms that semi-supervised frameworks for micron-scale industrial defect detection can match fully supervised accuracy while using dramatically fewer labeled samples.
When these findings are considered alongside a systematic review of deep learning for industrial defect detection published in Artificial Intelligence Review, a clear pattern emerges: the industrial defect detection field has bifurcated. General-purpose YOLO and transformer architectures continue advancing on public benchmarks with large training datasets, while manufacturing-specific platforms are advancing in sample efficiency and deployment speed, the factors that ultimately determine whether a system reaches production. The two tracks are optimizing for different outcomes, and practitioners who conflate them frequently discover the gap during pilot deployment.
The 7 Frameworks Compared
1. UnitX CorteX
CorteX is a sample-efficient deep learning and inference platform purpose-built for manufacturing defect detection. It addresses the three constraints that often disqualify general frameworks from factory deployment: data scarcity, latency requirements, and integration complexity.
Training data: CorteX trains effective models using as few as 5 labeled images per defect category. FleX-Gen reduces this requirement even further, to as few as 3 real samples, by generating synthetic defect variants, compared to the 500 to 5,000 labeled images that general frameworks typically require.
Inference: CorteX delivers 100 MP/s throughput at sub-50 ms edge latency natively, without requiring a separate TensorRT or OpenVINO optimization step.
Integration: PLC triggering, reject mechanism signaling, and MES connectivity are built into the platform as first-class features rather than engineering add-ons.
The tradeoff is that CorteX is a closed platform optimized for factory deployment rather than open-ended research. MDPI research confirms that purpose-built AI tools with domain-specific training strategies are increasingly outperforming general frameworks on manufacturing-specific benchmarks.
Schedule a demo with a UnitX expert to see a live training cycle on your defect type.
2. YOLO Ecosystem (YOLOv8, YOLOv9, YOLOv10)
The YOLO architecture family remains the dominant choice for real-time object detection in manufacturing contexts where both defect localization and classification are needed simultaneously.
YOLOv8, released by Ultralytics in 2023, became the benchmark standard for industrial defect detection research throughout 2024 and 2025. Research published in the International Journal of Advanced Manufacturing Technology confirms that YOLOv8-based systems achieve state-of-the-art detection accuracy on industrial surface defect benchmarks.
YOLOv9 and subsequent versions continue improving mAP scores on public datasets, although the practical gains over YOLOv8 for specific industrial applications vary.
YOLO models are typically trained in PyTorch and support ONNX and TensorRT export. However, data requirements still range from several hundred to several thousand labeled images per class to achieve production-grade recall, which remains a constraint on production lines where defect events are intentionally rare.
3. PyTorch
PyTorch is the dominant framework in AI research, with approximately 80% of NeurIPS 2023 papers developed using PyTorch. Its dynamic computation graph, Python-native syntax, and extensive ecosystem (including torchvision for image models and TIMM for pretrained architectures) make it the standard starting point for custom defect detection model development.
DigitalOcean’s analysis places PyTorch at approximately 55% production market share as of Q3 2025, reflecting its transition from research dominance into enterprise deployment.
For manufacturing, PyTorch is a valid choice for teams with substantial ML engineering expertise that require full control over model architecture. However, it generally requires 500 to 5,000 labeled images per defect category to achieve reliable industrial recall.
ONNX export is supported through torch.onnx, enabling downstream deployment to TensorRT or ONNX Runtime.
4. TensorFlow and Keras 3
TensorFlow retains a strong position in enterprise production pipelines, particularly for organizations with existing TensorFlow infrastructure.
Keras 3, now framework-agnostic across TensorFlow, JAX, and PyTorch backends, reduces the switching cost between ecosystems. TensorFlow Lite also enables deployment to mobile and edge devices, with model quantization capabilities that are currently more mature than PyTorch’s ExecuTorch alternative.
For manufacturing applications, TensorFlow’s primary strength lies in its deployment tooling rather than its training ergonomics. Data requirements are generally comparable to those of PyTorch.
ONNX export from TensorFlow has historically been less reliable than PyTorch export workflows, although the gap narrowed significantly in 2024 and 2025 releases.
5. ONNX Runtime
ONNX Runtime is not a training framework. Instead, it is an inference runtime designed to accelerate and standardize deployment for models trained in PyTorch, TensorFlow, or other ONNX-supporting frameworks.
Its industrial relevance comes from model portability. An engineer can train a model in PyTorch on a workstation, export it to ONNX, and deploy inference on virtually any edge device with an ONNX Runtime backend, without rewriting the model.
ONNX Runtime supports CPU, GPU, and NPU execution and is often the preferred deployment runtime for industrial edge hardware when the training framework is not fixed to a specific hardware vendor.
Five of the seven frameworks in this comparison support ONNX export.
6. NVIDIA TensorRT
TensorRT is NVIDIA’s inference optimization SDK for deploying trained models on NVIDIA GPUs with maximum throughput and minimum latency.
It applies model quantization (INT8 or FP16), kernel fusion, and memory layout optimization to reduce inference latency by 2x to 6x compared to standard PyTorch or TensorFlow inference on the same hardware.
For manufacturing lines requiring edge GPU inference at sub-50 ms latency, TensorRT is the standard optimization layer. However, it is not a training framework and does not address data labeling requirements.
TensorRT models are also not portable across hardware vendors; a TensorRT engine compiled for one NVIDIA GPU generation typically requires recompilation for another.
7. Intel OpenVINO
Intel OpenVINO is an inference optimization and deployment toolkit for Intel CPUs, integrated graphics, FPGAs, and VPUs. It serves as the Intel equivalent of TensorRT.
OpenVINO accepts models from ONNX, PyTorch, TensorFlow, and other formats, then applies graph optimization for Intel hardware. For industrial edge deployments running on standard x86 servers or industrial PCs without discrete GPUs, OpenVINO provides enough performance headroom to achieve sub-100 ms inference on multi-channel input streams without requiring dedicated GPU hardware. It is widely used in industrial automation environments where NVIDIA GPU deployments are either cost-prohibitive or physically impractical.
Framework Selection Summary
| # | Framework | Type | Training data | <50 ms edge | ONNX | Best fit |
|---|---|---|---|---|---|---|
| 1 | UnitX CorteX | Training + inference | 5 images (3 w/ FleX-Gen) | Yes (native) | No (closed) | Factory deployment, low-label |
| 2 | YOLO ecosystem | Training + inference | 200–2,000 images | Via TensorRT | Yes | Real-time location + class |
| 3 | PyTorch | Training | 500–5,000 images | Requires TensorRT | Yes | ML-team custom models |
| 4 | TensorFlow / Keras 3 | Training + deployment | 500–5,000 images | Via TF Lite | Partial | Enterprise pipelines |
| 5 | ONNX Runtime | Inference only | N/A | Yes (CPU/GPU) | Accepts | Portable inference layer |
| 6 | NVIDIA TensorRT | Inference optimization | N/A | Yes (NVIDIA GPU) | Accepts | GPU-accelerated edge |
| 7 | Intel OpenVINO | Inference optimization | N/A | Yes (Intel CPU) | Accepts | CPU-only industrial edge |
Frequently Asked Questions
Can a general PyTorch model be used for in-line manufacturing inspection?
Yes, but it requires additional engineering. A PyTorch model must be exported to ONNX or TensorRT format to achieve production-grade edge inference. The model also needs to be trained on a sufficiently large labeled dataset, which typically requires 500 or more samples per defect class.
PLC integration, reject mechanism triggering, and MES connectivity are not provided by PyTorch and must be developed separately. Teams with strong ML and integration engineering capabilities can build production systems on PyTorch, but teams without that capacity will likely find the overall development timeline substantially longer than with purpose-built alternatives.
Research on machine vision and PLC integration confirms that this integration layer is a significant cost driver in industrial deployments.
Is YOLOv8 or YOLOv9 better for manufacturing defect detection?
For most manufacturing defect detection applications, YOLOv8 and YOLOv9 perform comparably on production datasets where sufficient training data is available.
Published benchmarks show YOLOv9 improving mAP by approximately 1 to 2 percentage points over YOLOv8 on standard surface defect datasets. In practice, however, the limiting factor is rarely the YOLO version itself and more often the training set size and labeling quality. Both versions support ONNX and TensorRT export for edge deployment.
What is the practical difference between a general DL framework and CorteX for a factory team?
A factory quality engineer using a general deep learning framework must manage multiple steps independently: collecting and labeling training data, selecting a model architecture, running training, evaluating and tuning recall and precision, exporting and optimizing for edge inference, integrating PLC triggers, configuring reject mechanisms, and connecting to MES systems. Each step requires a different set of engineering expertise.
CorteX addresses these steps within a single platform, with the training process requiring as few as 5 labeled images rather than hundreds. The practical outcome is that a quality engineer can configure a new part inspection model in approximately 30 minutes, compared to several days at minimum for a custom PyTorch development cycle on a new part type (based on UnitX internal data).









