For most of the past decade, deploying an AI visual inspection system on a new product line followed a predictable, painful timeline: identify defect categories, wait months for enough real defective parts to accumulate, manually label each image, train, validate, fail, collect more samples, and repeat. A single new defect category could add six to twelve weeks to a deployment schedule.
Generative AI has broken this bottleneck.
In 2026, manufacturers deploying AI-powered inspection can go from three real defect images to a production-ready model in under 24 hours — not by compromising on accuracy, but by fundamentally rethinking where training data comes from. This guide explains how generative AI achieves that acceleration, the underlying technical mechanisms, and how to evaluate whether a generative data approach is right for your production environment.
Key Takeaways
- Generative AI can reduce model training data collection time from months to hours by producing photorealistic synthetic defect images from as few as 3 real samples.
- The critical technical challenge is domain fidelity — synthetic defects must precisely match the lighting, sensor, and texture characteristics of your actual imaging setup to avoid the domain gap that degrades model performance.
- Diffusion model-based generation has surpassed GAN-based approaches for most industrial defect types due to higher controllability and more stable training behavior.
- Generative AI does not replace human quality judgment — it scales and accelerates it. Human verification of generated images remains an essential quality gate before training.
The Data Bottleneck: Why Training Has Always Been the Longest Step
The economics of manufacturing create a structural scarcity of defect training data. On a well-optimized production line, defect rates are deliberately kept low — often below 0.5%. At 1,000 parts per minute, a 0.1% defect rate theoretically yields one defective part per minute, but in practice, any given defect type might appear far less frequently. A specific crack morphology on a cast aluminum housing, or a particular contamination pattern on a battery electrode, might yield only 2–5 usable images per month under standard production conditions.
Traditional supervised detection models require a minimum of 50–200 labeled examples per defect class to achieve reliable generalization. The math is unforgiving: at 5 examples per month, building a robust training set takes 10–40 months per defect type. Meanwhile, product lines evolve, new models launch, and quality engineers spend their time manually inspecting rather than deploying AI. The data bottleneck has historically been the primary reason AI visual inspection deployments stall between pilot and production scale.
Generative AI directly addresses this constraint by transforming a collection problem into a generation problem. Instead of waiting for defects to occur naturally, the system creates them synthetically — at scale, with controlled variation, and precisely matched to the imaging conditions of your production line.
Three Generative Architectures Used in Industrial Defect Training
Generative Adversarial Networks (GANs)
GANs were the first generative architecture to demonstrate practical value for industrial defect augmentation. The generator network learns to produce defect images that fool a discriminator, while the discriminator learns to distinguish synthetic images from real ones. When the system converges, the generator produces images that are statistically indistinguishable from real defect photographs.
The core advantage of GANs for defect generation is their ability to learn from the distribution of existing real samples — including surface texture, subsurface gradients, and edge characteristics — and produce new examples that faithfully represent that distribution. Research published in IEEE Transactions on Instrumentation and Measurement demonstrated that GAN-generated weld defect images, when combined with real training sets, improved classification accuracy compared to training on real data alone, particularly for minority defect classes.
The practical limitation of GANs is training instability. Mode collapse — where the generator stops producing diverse outputs and repeats a narrow set of samples — is a persistent failure mode, especially with small training sets. Techniques like Wasserstein loss and gradient penalty have reduced this risk, but GAN-based pipelines still require careful tuning by engineers familiar with the architecture.
Variational Autoencoders (VAEs)
VAEs learn a compressed latent representation of defect images. Because similar defects cluster together in this latent space, interpolating between two real defect samples can generate plausible intermediate variants — useful for expanding coverage of a defect category without requiring entirely novel generation. VAE-based approaches for rail defect detection have demonstrated the ability to generate 450 realistic synthetic images from 50 original samples, achieving nearly 100% classifier accuracy on test sets combining real and synthetic images.
VAEs tend to produce smoother outputs than GANs and are more stable to train, but at the cost of some sharpness. Generated images may appear slightly blurred compared to their GAN-generated counterparts. For texture-critical defects like micro-scratches or surface haze, this fidelity gap can significant.
Diffusion Models: The 2026 Standard
Diffusion models have become the dominant generative architecture for industrial defect data in 2026, and for good reason. They generate images by iteratively denoising a random signal — a process that delivers exceptional visual fidelity, stable training behavior, and — critically for manufacturing — fine-grained control over the generated output. You can specify not just the defect type, but also its spatial location, severity, orientation, and surface context.
Research on diffusion model-based steel surface defect generation shows that this approach produces high-fidelity synthetic images that measurably improve detection performance on real datasets — even under severe sample scarcity conditions. Key enabling mechanisms include mask-guided generation ( ensuring defects appear in physically plausible locations) and low-rank adaptation fine-tuning,which reduces the computational cost of adapting a pretrained diffusion model to a new defect type. See how FleX-Gen applies these principles to accelerate model training across automotive, battery, and semiconductor production lines.
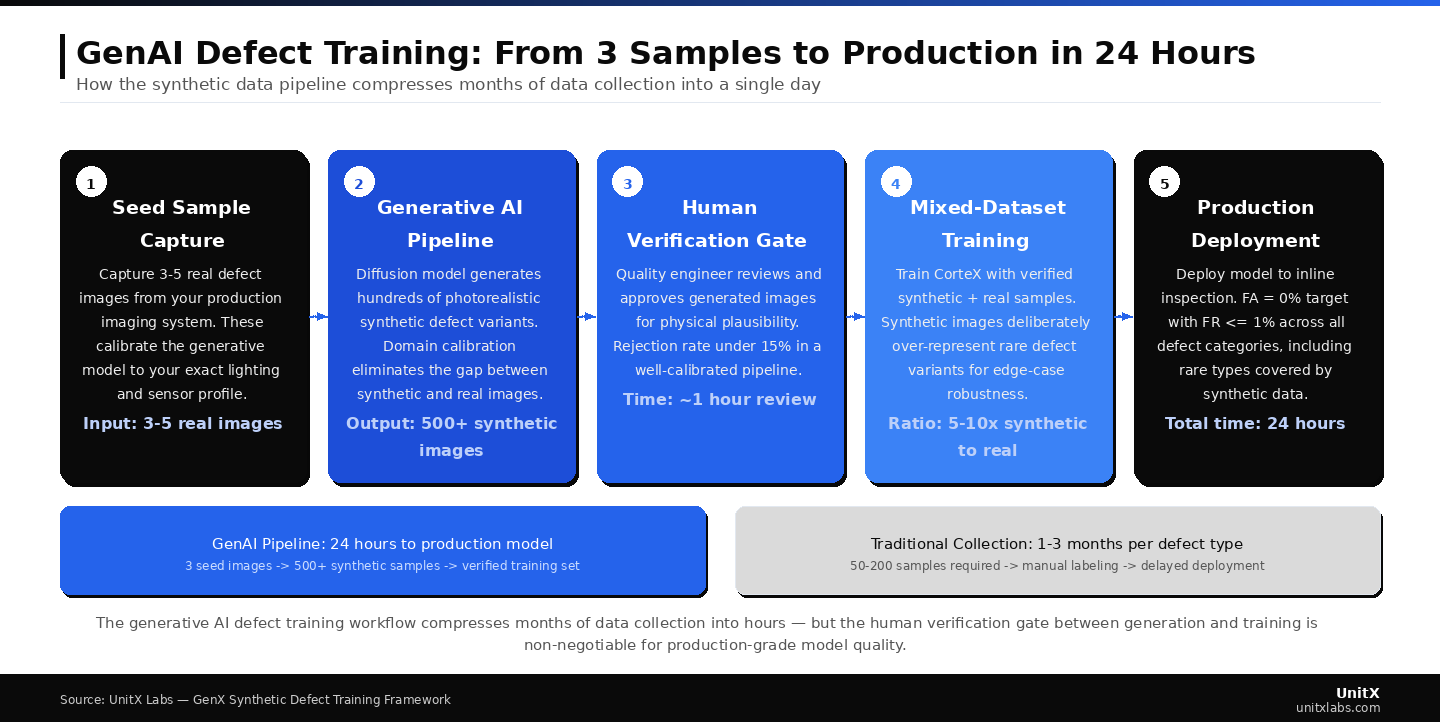
The generative AI defect training workflow compresses months of data collection into hours — but the human verification gate between generation and training is non-negotiable for production-grade model quality.
The Domain Gap Problem: Why Not All Synthetic Data Helps
The central technical challenge in generative defect augmentation is not generating visually convincing images — modern diffusion models can do that from just a handful of samples. The real challenge is generating images that are indistinguishable from the output of your specific imaging system.
If your production line uses a 50MP high-resolution camera with darkfield illumination optimized for detecting surface microcracks, a synthetic image generated from a generic industrial dataset will carry a slightly different lighting signature, noise floor, and depth-of-field response. A neural network will detect these differences, learn spurious features to distinguish synthetic from real data, and ultimately underperform on actual production images.
This phenomenon — known as the domain gap — is the reason early generative augmentation experiments in manufacturing often produced inconsistent results. The solution in 2026 is imaging-specific calibration: the generative pipeline is conditioned on images captured by your actual inspection system, not on generic industrial imagery. Synthetic defects are injected onto backgrounds captured by your camera, using your lighting profile and your sensor’s characteristic noise level. This zero-domain-gap approach is what separates effective generative augmentation from well-intentioned methods that ultimately degrade model performance.
Concretely, this means any generative defect tool you evaluate should demonstrate that its outputs are conditioned on your specific imaging hardware parameters — resolution preset, illumination profile, and sensor noise characteristics — not generic defaults. Domain randomization, which deliberately varies these parameters during generation, is a complementary technique that improves model robustness to production-floor lighting variability.
The Human Verification Gate: Non-Negotiable Quality Control
A common misconception about generative AI for defect training is that it is a fully automated pipeline — generate data, feed it into a model, and deploy. In 2026, the most effective implementations all retain a human verification step between generation and training. This is not a limitation to be engineered away; it is a structural feature of systems designed to produce reliable models.
The verification step is not laborious. With a well-designed interface, a quality engineer can review and accept or reject several hundred generated images in under an hour — far faster than labeling the same number of real images. The key difference is that the engineer is exercising quality judgment on already-labeled images, rather than making labeling decisions from scratch. Generated images that appear physically implausible — a scratch that seems to float above the surface, a defect placed in an impossible geometric location, or a texture that does not match the part material — are rejected before they can compromise the training set.
According to industry analysis on 2026 inspection trends, leading systems use human judgment efficiently — shifting the work from artisanal data collection to high-speed curation and validation. This distinction is important: generative AI does not reduce the need for quality engineering expertise; it redirects that expertise toward higher-leverage decisions.
Quantified Impact: What Generative Training Acceleration Looks Like in Practice
| Metric | Traditional Data Collection | Generative AI Pipeline |
| Dataset collection time (new defect type) | 1–3 months | 24 hours |
| Minimum real samples required | 50–200 per class | 3–5 per class |
| Edge case coverage (rare defect variants) | Limited by production occurrence | Controlled, on-demand generation |
| False Acceptance Rate improvement | Baseline | Up to 9x reduction in defect escapes |
| New product variant adaptation | Repeat full collection cycle | Generate from existing model with new background images |
These figures are not theoretical. They reflect the operational reality across multiple industries — including automotive casting inspection, EV battery electrode quality, and consumer electronics surface finishing — where the generative AI approach has been validated in real production deployments.
Explore UnitX customer results across these sectors in the case study library.
The Generative AI Training Workflow: Step by Step
Step 1: Collect Seed Samples
Capture 3–10 real examples of the target defect type using your production imaging system. These seed images should represent the typical manifestation of the defect — not necessarily its rarest or most extreme variants. The generative model will learn the general characteristics and produce the variation you need. Image quality matters: use your standard production imaging settings, not a special high-resolution capture mode that differs from normal operating conditions.
Step 2: Calibrate the Generative Model to Your Imaging Setup
Provide the generative pipeline with a set of background images — normal parts captured by your production camera under your standard lighting configuration. These backgrounds are what the synthetic defects will be composited onto. If your inspection system uses software-defined illumination with multiple independent lighting channels, capture representative examples across the lighting conditions your line actually uses. The generative model uses these backgrounds to calibrate its output to your specific domain.
Step 3: Generate Defect Variants with Controlled Parameters
Configure generation parameters: defect severity range, spatial placement constraints (for example, defects must appear within a specific region of interest), and morphological variation. Run the generation pipeline. For most industrial defect types using current diffusion-based tools, a generation run producing several hundred synthetic samples takes only a matter of hours on modern GPU hardware.
Learn how CorteX integrates with this training pipeline for fast, accurate model deployment.
Step 4: Human Verification Gate
Review generated images for physical plausibility. Reject images where the defect composite is visually inconsistent — such as incorrect lighting angles, impossible placement, or texture discontinuities at defect boundaries. A well-implemented generation pipeline should have a rejection rate below 10–15% at this stage. Accept the remainder. Your labeled synthetic training set is now ready.
Step 5: Train with Mixed Real and Generative Data
Combine your verified synthetic images with your real labeled samples for training. The ratio of synthetic to real data typically ranges from 5:1 to 10:1 for minority defect classes, with real images retained at full weight. Training with this mixed dataset produces models that are more robust to edge-case defect variants than models trained on real data alone, because the synthetic generation step can deliberately over-represent rare variants that the production line would only produce occasionally.
Where Generative AI Cannot Replace Real Data
Generative AI is a powerful accelerator, not a universal solution. There are specific conditions where real samples remain essential and should not be replaced entirely by synthetic generation.
Defect types with complex three-dimensional subsurface structures — for example, internal porosity in a casting, or delamination within a multi-layer electrode stack — are fundamentally challenging because 2D imaging does not fully capture the defect geometry. Generative models trained on 2D images cannot faithfully reproduce these subsurface characteristics from a small seed set. Real examples are essential to validate that the model detects the true failure mode, not just a visually similar surface anomaly.
Second, if your production process changes significantly — such as a new material supplier, new tooling geometry, or a different surface finish specification — synthetic images generated from the pre-change baseline may no longer represent the new defect appearance. New real samples should be captured after any significant process change, even if the synthetic pipeline is used to expand from those new seeds.
Finally, regulatory environments in certain industries (pharmaceutical, aerospace, medical device) may require documented real-world validation datasets as part of inspection system qualification. In these contexts, synthetic data can supplement but typically cannot replace a real sample validation set for compliance purposes. Consult your quality system and regulatory pathway before designing a fully synthetic training pipeline for these applications. The UnitX technical blog covers compliance considerations for AI inspection systems in depth.
Common Questions
How does generative AI produce realistic defect images from only 3 samples?
Modern diffusion models and GAN-based architectures start from pretrained representations that have already learned the fundamental visual properties of materials and surfaces from large datasets. Fine-tuning on 3–5 domain-specific defect samples teaches the model the specific appearance of your defect type — morphology, depth cues, and texture integration — without requiring it to learn material physics from scratch. Low-rank adaptation techniques reduce the number of parameters that need to be updated, making this fine-tuning practical even with very small seed sets.
Can generative training data meet the accuracy requirements for zero-escape inspection?
Yes, when generation is conditioned on your specific imaging hardware and subject to human verification before training. The key metric is False Acceptance Rate (FA). Systems trained with properly calibrated synthetic data can achieve FA = 0% on held-out real defect validation sets — the same target as models trained purely real-data. The advantage of synthetic data is particularly evident for rare defect types, where real training sets are often too small to achieve reliable performance.
What happens if my generative model produces images that do not look realistic enough?
This is exactly what the human verification gate is designed to catch. Images that fail the physical plausibility check are rejected before training. If the rejection rate is consistently high — above 20–25% — this indicates that the calibration step needs improvement: more representative background images, additional seed samples, or tighter placement constraints. Do not skip the verification step under schedule pressure; training on low-fidelity synthetic data will degrade model performance and defeat the purpose of the approach.
How does generative AI training handle defects that vary significantly in appearance?
High morphological variation is one area where generative approaches outperform traditional data collection. When a defect type appears in many different forms — for example, a scratch that can be shallow or deep, oriented in any direction, and of varying length — real-world collection tends to under-represent rare extreme variants. Generative pipelines can be configured to deliberately over-represent these cases, producing a training set that covers the full severity range rather than just the most common manifestations.
Is the 24-hour data collection timeline realistic for all defect types?
For most surface defects on standard industrial materials — such as scratches, pitting, inclusions, contamination, and dimensional deformation — the answer is yes. The 24-hour figure refers to generation compute time after seed samples and background images have been captured and calibration has been configured. More complex defect types with subtle contrast signatures or fine spatial structure may require longer generation runs or additional human verification iterations, but the total timeline remains orders of magnitude shorter than traditional data collection.









