
Synthetic data machine vision system technology reshapes how organizations train and deploy machine vision systems in 2025. Automated synthetic data generation enables rapid scaling, reduces bias, and protects privacy while delivering high-quality annotation. Companies no longer depend on costly manual data labeling, which previously consumed over 90% of project resources. Recent projects, such as autonomous vehicle training and healthcare research, show that synthetic data machine vision system models can outperform those trained only on real data. Engineers now create thousands of diverse data samples instantly, allowing machine vision systems to adapt quickly to new challenges.
Key Takeaways
- Synthetic data helps create large, diverse datasets quickly and cheaply, speeding up machine vision training.
- Using synthetic data reduces bias and protects privacy by avoiding real personal information.
- Combining synthetic and real data improves accuracy and makes machine vision systems more reliable.
- Synthetic data provides precise labels automatically, improving the quality and adaptability of AI models.
- Industries like automotive, healthcare, and manufacturing benefit from synthetic data to build safer and smarter vision systems.
Synthetic Data in Machine Vision Systems
What Is Synthetic Data
Synthetic data refers to information that artificial intelligence models generate to mimic real-world data. Experts describe synthetic data as data points created by models, not by humans or direct observation. In computer vision, synthetic data generation uses advanced techniques like generative adversarial networks (GANs) and variational autoencoders (VAEs). These models learn patterns from real datasets and then produce new, artificial examples. Synthetic data machine vision system technology relies on this process to create images, videos, and sensor readings that look and behave like real data. This approach allows engineers to simulate rare events, dangerous scenarios, or privacy-sensitive situations without collecting actual data from the field.
Synthetic datasets play a crucial role in training computer vision models. For example, in autonomous vehicles, synthetic data generation can simulate thousands of driving conditions, weather patterns, and road hazards. This method helps machine vision systems learn to recognize objects, avoid obstacles, and make safe decisions. Synthetic data also supports applications in healthcare, manufacturing, and robotics, where collecting real data may be expensive, risky, or slow.
Why It Matters in 2025
In 2025, synthetic data machine vision system solutions have become essential for building reliable and scalable computer vision applications. Synthetic data generation addresses several key challenges:
- It enables the creation of large, diverse datasets for training machine vision systems, even when real data is scarce.
- It reduces bias by generating balanced samples across different demographics and scenarios.
- It protects privacy by using artificial faces or objects instead of real people or sensitive information.
- It improves annotation quality because each synthetic sample comes with precise, programmatically generated labels.
Synthetic data generation also saves time and resources by automating the labeling process, which once required extensive manual effort.
The impact of synthetic data on machine vision systems is clear. The following table shows how combining real and synthetic data improves key performance metrics:
| Metric | Real Data Only | Real + Synthetic Data |
|---|---|---|
| Accuracy | 0.57 | 0.60 |
| Precision | 77.46% | 82.56% |
| Recall | 58.06% | 61.71% |
| Mean Average Precision | 64.50% | 70.37% |
| F1 Score | 0.662 | 0.705 |
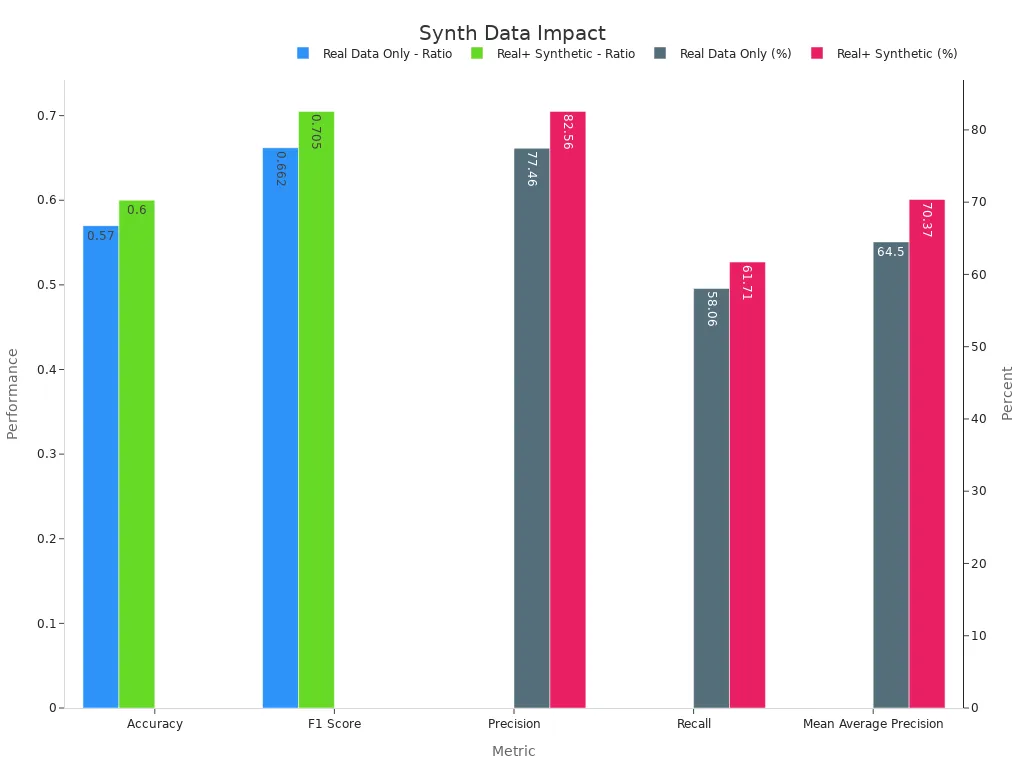
Synthetic datasets now power computer vision in industries such as automotive, healthcare, and manufacturing. Machine vision systems trained with synthetic data can handle rare events, improve safety, and adapt to new challenges faster than ever before. Synthetic data generation has transformed how organizations approach data collection, making computer vision more accessible, accurate, and secure.
Key Benefits of Synthetic Data
Scalability and Cost
Synthetic data has transformed the way organizations approach computer vision projects. Traditional data collection often limits machine vision systems due to high costs and slow processes. Synthetic data generation removes these barriers by enabling the creation of vast, diverse datasets in a fraction of the time. Engineers can now generate millions of labeled images for object detection, segmentation, and image segmentation tasks without the need for manual annotation.
A synthetic data machine vision system can scale instantly to meet new demands. This flexibility supports rapid prototyping and deployment of machine learning models. Companies like Unity have reported saving up to 95% in time and money while improving model quality. The following table highlights documented successes and quantitative impacts:
| Documented Success / Benefit | Description | Quantitative Impact |
|---|---|---|
| Unity’s synthetic data usage | Saved about 95% in time and money while creating better models | ~95% time and cost savings |
| Caper’s intelligent shopping carts | Achieved 99% recognition accuracy using synthetic images | 99% recognition accuracy |
| Data collection cost reduction | Synthetic data generation reduces costs by about 40% | 40% cost reduction |
| AI development speed | Synthetic datasets can speed up development timelines by up to 40% | 40% faster development |
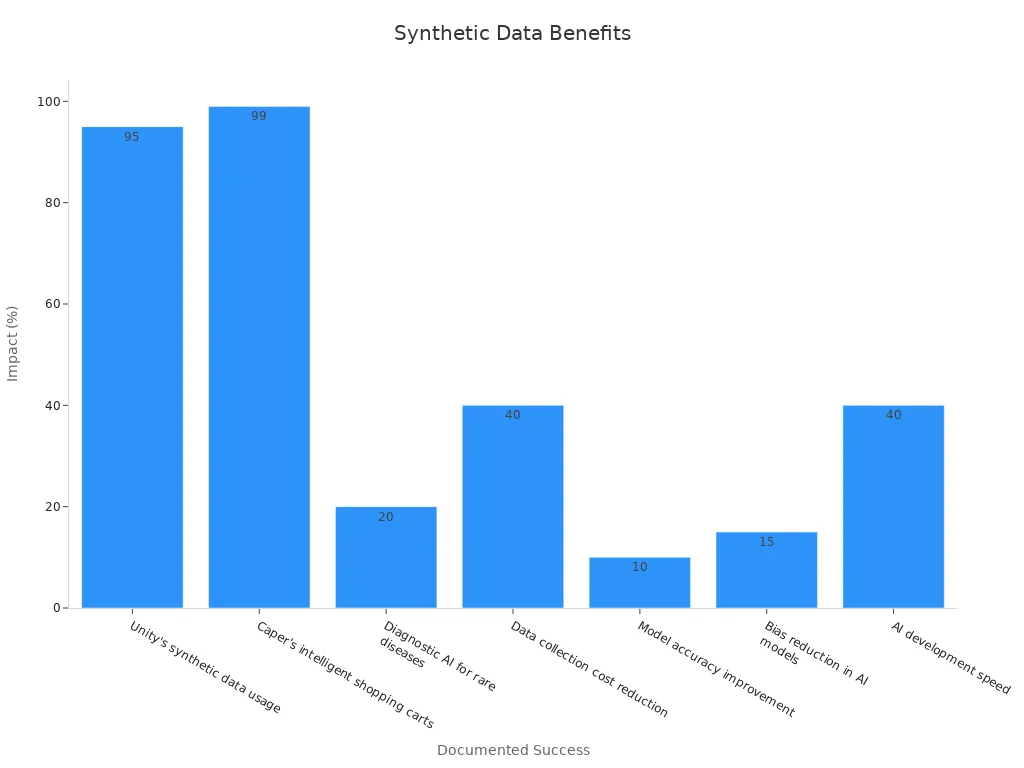
Industry reports show that synthetic data offers up to 99% cost savings compared to traditional methods. QA engineers save almost half their time, and the market for synthetic data is growing rapidly. Machine vision systems can now overcome real data limitations, supporting large-scale ai training and deployment.
Bias and Privacy
Bias and privacy remain major concerns in computer vision. Synthetic data addresses these challenges by allowing engineers to control the composition of datasets. They can generate balanced samples that represent different demographics, environments, and rare scenarios. This approach helps reduce bias in ai models and ensures fairer outcomes.
- Synthetic data avoids the use of sensitive real-world data, which protects privacy.
- It enables the creation of diverse datasets, improving model robustness and reducing bias.
- Automated labeling enhances precision and efficiency in ai training.
- Synthetic data supports compliance with privacy regulations such as HIPAA and GDPR.
- Techniques like differential privacy and privacy risk analysis further secure synthetic datasets.
Synthetic data generation allows organizations to mask or remove personal identifiers. This process eliminates risks linked to sensitive information. Studies show that synthetic data can reduce bias in ai models by up to 15%. It also helps organizations meet strict privacy standards while still training effective machine vision systems.
Annotation and Adaptability
Accurate annotation is critical for machine vision systems, especially in object detection, segmentation, and image segmentation. Synthetic data provides programmatically generated labels, ensuring high annotation quality. This process removes human error and speeds up dataset creation.
Quality assurance metrics, such as specificity, coherence, and solvability, help validate synthetic datasets. Automated metrics, including accuracy, precision, recall, and F1 score, confirm that synthetic data matches or exceeds the quality of real data. Inter-annotator agreement and consensus algorithms further improve reliability.
- Intrinsic metrics and in-context evaluation filter out low-quality synthetic data.
- High-quality synthetic datasets enable fine-tuning of machine learning models for real-time adaptability.
- Manual and automated checks ensure consistent, reliable annotations.
Machine vision systems benefit from this adaptability. Engineers can update datasets quickly to reflect new conditions or requirements. This flexibility supports real-time quality control and continuous improvement in ai models. Synthetic data generation empowers organizations to maintain high standards in annotation and respond rapidly to changing needs.
Synthetic Data Generation Methods

Synthetic data generation methods have advanced rapidly, providing high-quality datasets for machine vision. Each approach offers unique strengths for ai models and data generation.
GANs and AI Techniques
Generative Adversarial Networks (GANs) and other ai techniques lead the field in synthetic data generation. GANs use two neural networks that compete to create realistic data. Researchers have developed advanced models like EMR-WGAN, which can generate complex datasets for electronic health records. These methods help preserve privacy and improve ai training. GAN-based data generation can handle both conditional and nonconditional scenarios, making it flexible for many applications. Studies show that GANs produce synthetic data that closely matches real-world data, with only minor differences in subgroup representation and rare conditions. However, the quality of the generated data depends on the training process and the original data used.
3D Simulation
3D simulation uses physics-based models to create synthetic data that mimics real environments. Engineers use tools like Ansys AVxcelerate and NVIDIA DRIVE Sim to build virtual worlds for data generation. These simulations can produce images, depth maps, and sensor data under different lighting and weather conditions. Simulation-based studies highlight the precision and control offered by 3D simulation. This method allows ai models to train on millions of scenarios safely. It is especially useful for applications like autonomous driving and robotics, where accuracy is critical. 3D simulation excels at replicating real-world conditions, making it a powerful tool for synthetic data generation.
Domain Randomization
Domain randomization introduces variety into synthetic data by changing textures, shapes, lighting, and camera angles. Engineers use this method to expose ai models to a wide range of scenarios during data generation. Case studies show that domain randomization improves model accuracy and robustness. For example, robotic grasping tasks achieved up to 80% success when trained with randomized synthetic images. Human pose estimation and facial recognition also benefit from this approach. Domain randomization helps reduce the gap between synthetic and real data, supporting better generalization in ai models.
Note: While synthetic data generation methods offer strong results, experts recommend combining synthetic and real data for the best outcomes. Synthetic data can closely approximate real-world data, but it may not fully capture rare events or complex relationships.
Applications in 2025

Industrial Machine Vision
Industrial machine vision systems in 2025 rely on synthetic data to improve defect detection, quality control, and assembly line monitoring. Manufacturers use computer vision to inspect products at high speed, identifying flaws that human eyes might miss. Synthetic data allows engineers to create millions of labeled images for object detection and segmentation tasks, even when real-world samples are rare. By combining synthetic and real data, companies achieve higher accuracy and precision in machine vision systems. The following chart shows how performance improves when using both data types:
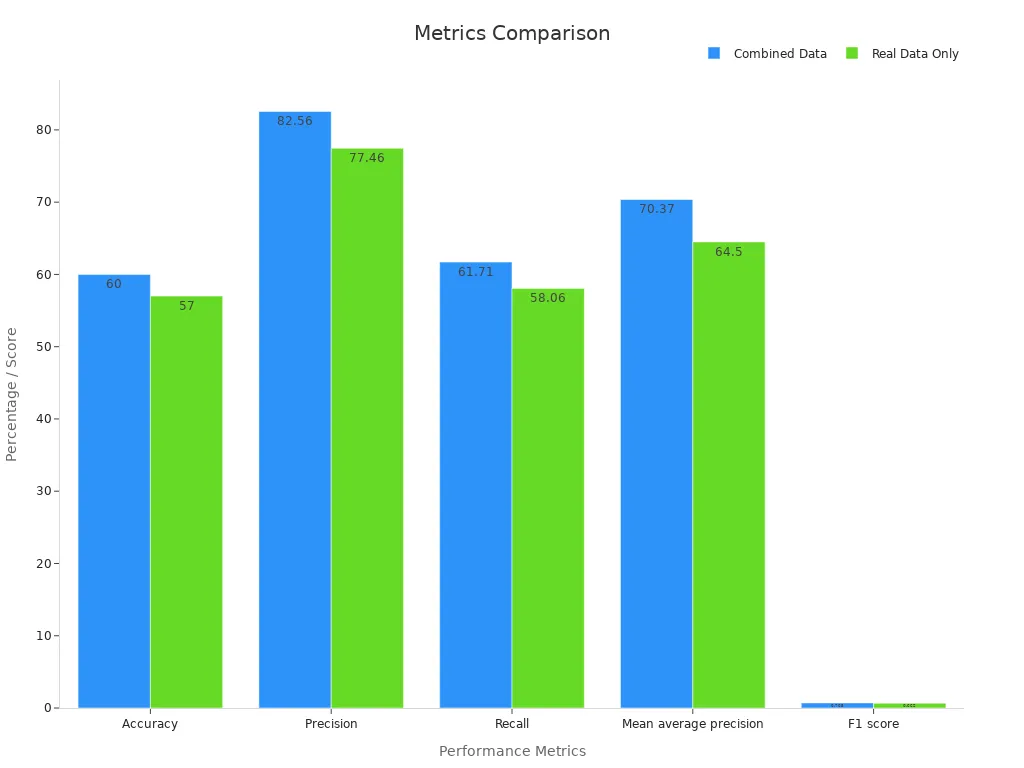
Manufacturers report a 47% reduction in data acquisition costs and can scale test data volumes by over 1,000%. These advances make computer vision applications more reliable and cost-effective for industries worldwide.
Automation and Robotics
Automation and robotics benefit from synthetic data by enabling rapid training of object detection and image segmentation models. Self-driving cars use synthetic data to simulate thousands of driving scenarios, including rare events and edge cases. Robotics teams apply 3D Gaussian Splatting to generate diverse, annotated datasets for dynamic environments. This method improves model generalization and supports real-time adaptation in tasks like robot soccer or warehouse automation. Hybrid training, which combines synthetic and real data, leads to higher Dice scores in detection and segmentation tasks, proving essential for robust machine vision systems.
| Model | Training Data Type | Task | Dice Score (Real Test Data) |
|---|---|---|---|
| 4 | Hybrid (Synthetic + Real) | Detection | 0.954 |
| 4 | Hybrid (Synthetic + Real) | Segmentation | 0.920 |
Self-driving cars and industrial robots now adapt quickly to new challenges, thanks to synthetic data-driven computer vision.
Healthcare and Retail
Healthcare and retail sectors use synthetic data to overcome privacy and data scarcity challenges. In healthcare, synthetic data simulates electronic health records for AI diagnostics and rare disease research. Machine vision systems trained on synthetic data achieve similar accuracy to those using real data, supporting safe and effective diagnostics. Retailers use synthetic data to create customer profiles, optimize inventory, and train recommendation engines while protecting privacy.
- Synthetic data augments datasets with rare scenarios, reducing bias and improving model robustness.
- Computer vision applications in healthcare and retail benefit from scalable, diverse, and privacy-compliant data.
The global synthetic data market is expanding rapidly, with projections estimating growth from $2 billion in 2025 to over $10 billion by 2033. Major technology companies and startups continue to invest in synthetic data platforms, driving innovation across sectors.
Synthetic Data vs Real Data
Strengths and Limitations
Synthetic data offers several advantages for ai training and machine learning models. It provides privacy preservation, cost-effectiveness, and scalability. Organizations use synthetic data to fill gaps when real data is scarce or sensitive. Synthetic data generation allows teams to create diverse datasets quickly, supporting rapid development of ai models.
However, synthetic data challenges remain. Synthetic data may lack the realism of real data and sometimes struggles to capture complex relationships. Validation can be difficult, and diversity may be limited if the data generation process is not carefully managed. Real data delivers higher precision and broader insights, which are crucial for models that must handle real-world complexities. Yet, real data often comes with high costs, privacy concerns, and bias risks.
| Strengths of Synthetic Data | Limitations of Synthetic Data | Strengths of Real Data | Limitations of Real Data |
|---|---|---|---|
| Privacy preservation | Less realism | High precision | High cost |
| Cost-effective | Validation challenges | Broad insights | Privacy concerns |
| Scalable | Limited diversity | Real-world complexity | Bias risk |
| Fills data gaps | Hard to capture complexity | Difficult acquisition |
Note: Validation techniques such as statistical hypothesis testing and visual inspection help ensure synthetic data quality.
Hybrid Approaches
Hybrid approaches combine synthetic data with real data to improve ai model performance. This strategy leverages the strengths of both data types. Hybrid-trained ai models outperform those trained on only real or synthetic data. These models show higher scores in empathy, relevance, and consistency. For example, hybrid models scored 8.64 in empathy and 8.66 in relevance, surpassing models trained solely on real data.
- Hybrid datasets enrich training by covering edge cases and niche scenarios.
- Real data brings authenticity, while synthetic data increases diversity and volume.
- Hybrid approaches support transfer learning, allowing ai models to generalize better across tasks.
Hybrid datasets also help address synthetic data challenges, such as lack of realism and limited diversity. This method leads to more robust and reliable machine learning models.
Overcoming Challenges
Organizations face several synthetic data challenges, including ensuring data quality and avoiding bias. Teams must validate synthetic data against real-world distributions using statistical tests and visual tools. Transparency in the data generation process builds trust and improves interpretability.
- Start with high-quality real data to guide synthetic data generation.
- Use synthetic data to balance class distributions and reduce bias in ai models.
- Regularly update synthetic datasets to reflect changes in real-world data.
- Apply transfer learning to adapt ai models trained on synthetic data to new domains.
- Prioritize data ethics and privacy to prevent misuse or bias propagation.
By following these strategies, organizations can overcome synthetic data challenges and unlock the full potential of ai in machine vision systems.
Future Trends
Generative AI Advances
Generative AI continues to transform synthetic data generation for machine vision systems. Companies now use advanced models like GANs, VAEs, and diffusion models to create hyperrealistic synthetic data. These models help industries such as healthcare and finance protect privacy while improving data quality. For example, pharmaceutical firms generate synthetic patient records to test new drugs without exposing real patient information.
AI-powered data augmentation tools use these models to expand datasets, making machine vision systems more robust. E-commerce companies generate synthetic customer profiles to improve product recommendations. Transformer models also play a key role by discovering new features from sensor data, which helps manufacturing firms predict equipment failures. Multi-modal data synthesis combines images, text, audio, and sensor data, creating richer datasets for autonomous vehicles and robotics.
Note: Explainable and controllable data generation is now possible with conditional GANs and VAEs. Financial institutions use these tools to create synthetic loan applications with specific credit scores, improving risk assessment.
The following table shows projected growth for key technologies driving synthetic data in machine vision:
| Technology | Market Projection (Year) | CAGR (%) | Key Impact on Synthetic Data Applications in Machine Vision Systems |
|---|---|---|---|
| Generative AI (GANs) | $20.9B (2024) to $136.7B (2030) | 36.7 | Enhances synthetic data generation for training, improving model accuracy and data diversity. |
| Self-Supervised Learning | $7.5B (2021) to $126.8B (2031) | 33.1 | Reduces dependency on labeled data by up to 80%, facilitating synthetic data use. |
| Vision Transformers (ViTs) | $280.75M (2024) to $2,783.66M (2032) | 33.2 | Improves object detection and segmentation, benefiting from synthetic data augmentation. |
Regulation and Adoption
Regulation and adoption trends shape the future of synthetic data in machine vision. Privacy laws like HIPAA and GDPR push organizations to use synthetic data instead of real personal information. Companies adopt privacy-preserving techniques such as federated learning and differential privacy to meet these requirements.
Industries like manufacturing, healthcare, aerospace, and autonomous systems lead the way in adopting synthetic data. AI-driven models and simulation techniques help detect rare defects and improve reliability. Self-supervised learning models learn from unlabeled data, making systems more adaptive. Transformer-based frameworks increase precision and reduce errors in rare event detection.
- Synthetic data helps solve the long tail problem by generating diverse datasets.
- Automated feature engineering and multi-modal synthesis drive innovation.
- Adoption of these technologies increases efficiency and supports compliance with global regulations.
Generative AI services now hold a 76% trend share in computer vision, showing strong industry adoption. As regulations evolve, organizations will continue to invest in synthetic data to ensure privacy, accuracy, and scalability in machine vision systems.
Synthetic data drives innovation in machine vision systems in 2025. Organizations see major benefits in scalability, bias reduction, privacy, and adaptability. Key examples include:
- Autonomous vehicles use synthetic data to train on rare driving scenarios, improving safety.
- Computer vision models gain accuracy from diverse, labeled images with controlled variations.
- Privacy concerns decrease as sensitive information stays protected.
- Companies reduce costs and speed up development with scalable data generation.
Teams should view synthetic data as a strategic asset and explore pilot projects to unlock its full potential.
FAQ
What is synthetic data in machine vision?
Synthetic data refers to computer-generated images or sensor readings. Engineers use it to train machine vision systems. This data mimics real-world scenarios and helps models learn faster.
How does synthetic data improve privacy?
Synthetic data does not use real personal information. It replaces sensitive details with artificial examples. This approach protects user privacy and supports compliance with regulations.
Can synthetic data fully replace real data?
Synthetic data works best when combined with real data. Real data captures complex situations. Synthetic data fills gaps and increases diversity. Hybrid approaches deliver the strongest results.
What industries benefit most from synthetic data in 2025?
- Automotive
- Healthcare
- Manufacturing
- Retail
These industries use synthetic data to improve safety, accuracy, and efficiency in machine vision systems.
See Also
How Synthetic Data Is Transforming Machine Vision Capabilities
A Deep Dive Into Synthetic Data For Vision Systems
Key Insights On Synthetic Data For AI Inspection In 2025








