
Self-supervised learning changes how you train machine vision models. It allows systems to learn from unlabeled data by creating their own labels. This approach proves essential when labeled datasets are scarce or expensive to produce. You can use self-supervised learning to uncover the hidden patterns in images and videos, enabling more efficient training. By tapping into the structure of data, this method lets you build smarter systems. A Self-Supervised Learning machine vision system can adapt to complex tasks without relying heavily on human annotation.
Key Takeaways
-
Self-supervised learning helps models learn without labeled data. This saves money.
-
Pretext tasks are key. They let models create labels and learn useful patterns.
-
This method helps models work well on many tasks. It adjusts to new uses easily.
-
Self-supervised learning works well in real-time, like in robots or cameras. It adapts fast.
-
Using self-supervised learning makes machine vision systems better and more accurate in many areas.
How Self-Supervised Learning Differs from Other Paradigms
Supervised Learning vs. Self-Supervised Learning
Supervised learning relies on labeled data to train models. You provide clear labels for each input, allowing the system to learn specific patterns. In contrast, self-supervised learning uses unlabeled data and creates its own labels through pretext tasks. This makes it ideal for situations where labeled data is scarce or expensive to obtain.
|
Aspect |
Supervised Learning |
Self-Supervised Learning |
|---|---|---|
|
Computational Efficiency |
Generally faster due to direct training on labeled data |
Slower due to multiple training stages and pseudo label generation |
|
Data Requirements |
Requires labeled data, which can be scarce |
Requires large amounts of unlabeled data to achieve similar accuracy |
|
Task Suitability |
Well-suited for tasks with clear labels |
Depends heavily on the choice of pretext tasks, which can vary in effectiveness |
Self-supervised learning offers flexibility by leveraging unlabeled data, but it requires more computational effort. You can use it to train models for tasks like image classification without relying on human annotations.
Unsupervised Learning vs. Self-Supervised Learning
Unsupervised learning focuses on discovering patterns in data without predefined labels. You might use it for clustering or anomaly detection. Self-supervised learning, however, generates labels from the data itself using pretext tasks. This approach allows you to train models for tasks similar to supervised learning, such as classification or regression.
|
Aspect |
Unsupervised Learning |
Self-Supervised Learning |
|---|---|---|
|
Definition |
Learns from data without predefined labels |
Generates labels from data through pretext tasks |
|
Ground Truth |
Does not measure against any known ground truth |
Measures against an implicitly derived ground truth |
|
Use Cases |
Clustering, anomaly detection, dimensionality reduction |
Classification, regression tasks typical to supervised learning |
|
Learning Mechanism |
Focuses on discovering inherent structures |
Optimized using a loss function, similar to supervised models |
|
Example |
E-commerce recommendation engine |
Predicting missing parts of input using surrounding context |
Self-supervised learning bridges the gap between unsupervised and supervised approaches by combining the strengths of both. You can use it to train models with unlabeled data while achieving results similar to supervised methods.
Bridging the Gap Between Supervised and Unsupervised Learning
Self-supervised learning acts as a middle ground between supervised and unsupervised paradigms. By carefully designing pretext tasks and tuning hyperparameters, you can achieve performance levels comparable to supervised learning. For example, methods like SimCLR and VICReg demonstrate how contrastive and non-contrastive techniques can unify different approaches. This flexibility allows you to train models that perform well across diverse tasks without relying heavily on labeled data.
Self-supervised learning transforms how you approach machine vision tasks. It reduces the need for labeled data while maintaining high accuracy, making it a powerful tool for modern AI systems.
Mechanisms of Self-Supervised Learning
Pretext Tasks in Self-Supervised Learning
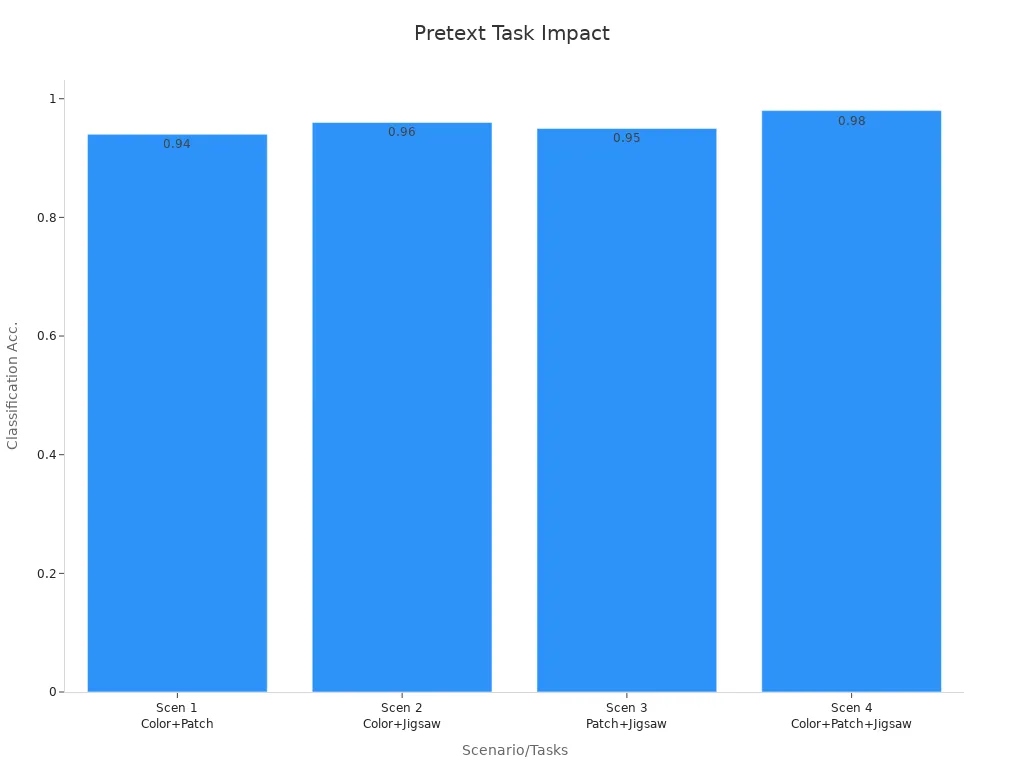
Pretext tasks play a crucial role in self-supervised learning by enabling models to generate labels from unlabeled data. These tasks involve solving auxiliary problems that help the model learn meaningful representations. For example, you can use tasks like colorization, patch prediction, or solving jigsaw puzzles to train a deep learning model. Combining multiple pretext tasks often leads to better results.
|
Scenario |
Pretext Tasks Combined |
Classification Accuracy |
|---|---|---|
|
1 |
Colorization + Patch Prediction |
0.94 |
|
2 |
Colorization + Jigsaw Puzzle |
0.96 |
|
3 |
Patch Prediction + Jigsaw Puzzle |
0.95 |
|
4 |
Colorization + Patch Prediction + Jigsaw Puzzle |
0.98 |
These tasks improve learning efficiency by encouraging the model to focus on the inherent structure of the data. For instance, combining colorization with patch prediction and jigsaw puzzles achieves a classification accuracy of 0.98, showcasing the effectiveness of multi-task learning.
Contrastive Learning Techniques
Contrastive learning techniques help models learn by comparing data samples. You can train a model to identify similarities and differences between pairs of images. This approach uses a loss function that minimizes the distance between similar samples while maximizing the distance between dissimilar ones. Methods like SimCLR and MoCo have demonstrated significant improvements in representation learning for self-supervised learning. These techniques are particularly effective in tasks like image classification, where understanding subtle differences between classes is essential.
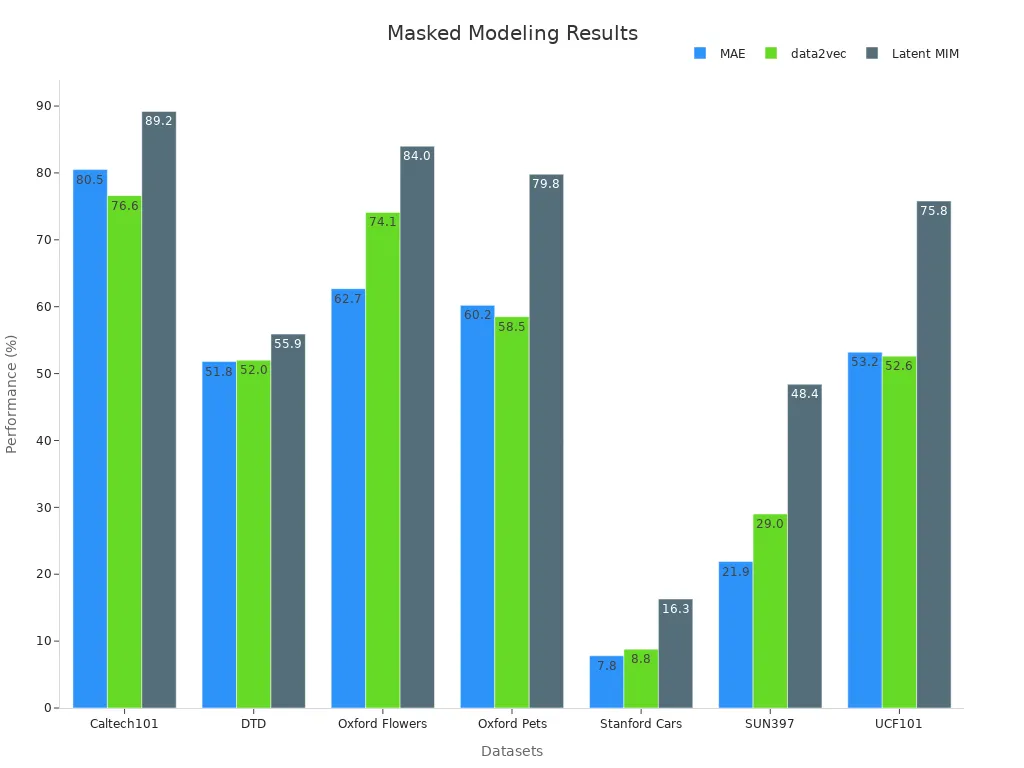
Self-Predictive Learning and Masked Modeling
Self-predictive learning focuses on predicting missing parts of the input data. Masked modeling, a popular method in this category, involves masking portions of an image and training the model to reconstruct them. This technique helps the model capture global and local features effectively. For example, OBI-CMF outperforms methods like MAE and MFM by capturing global details better, making it ideal for distinguishing classes with large inter-class differences.
|
Model |
Performance Description |
|---|---|
|
OBI-CMF |
Captures global details better than MAE and MFM, effective in distinguishing classes with large inter-class differences. |
|
MAE |
Less effective in capturing global details compared to OBI-CMF. |
|
MFM |
Similar limitations as MAE in handling difficult samples. |
Masked modeling has shown promising results across various datasets, including Caltech101 and Oxford Flowers.
Techniques for Self-Supervised Learning in Machine Vision Systems

Image Augmentation and Representation Learning
Image augmentation plays a vital role in improving self-supervised learning. By applying transformations like random cropping, flipping, and color distortion, you can help computer vision models learn robust features. These techniques force the model to focus on the essential patterns in images, rather than superficial details. For example, random cropping ensures the model adapts to different perspectives, while color distortion challenges it to identify objects regardless of lighting conditions.
Generative adversarial networks (GANs) take augmentation a step further. They create tailored transformations that push the model to learn deeper representations. This approach enhances the generalization capabilities of self-supervised learning models, making them more effective in downstream tasks like object detection and image classification. Diverse augmentation strategies combined with representation learning significantly improve the robustness and adaptability of computer vision models.
Contrastive Pretraining for Vision Tasks
Contrastive pretraining helps you train computer vision models by comparing pairs of images. This technique teaches the model to identify similarities and differences between samples. For instance, methods like DINO and SimCLR use contrastive loss functions to pull similar images closer in the feature space while pushing dissimilar ones apart.
Contrastive methods reduce the need for labeled data, addressing one of the biggest challenges in self-supervised learning. Models like DINO demonstrate competitive performance without fine-tuning, proving their effectiveness. Experiments show that models trained on curated datasets outperform those trained on less curated data. Additionally, distilling a model from a larger one yields better results than training from scratch. These findings highlight the importance of data quality and pretraining strategies in self-supervised learning.
Clustering-Based Approaches in Machine Vision
Clustering-based techniques group similar data points together to learn meaningful representations. You can use these methods to train computer vision models without labels. For example, clustering algorithms like k-means or hierarchical clustering help the model identify patterns and structures in the data.
DINOv2 showcases the power of clustering-based approaches. It uses self-supervised learning to group similar images, enabling the model to learn features that generalize well across tasks. Performance improves as the amount of training data increases, emphasizing the scalability of clustering methods. These techniques reduce the reliance on expensive data annotation, making them ideal for large-scale machine vision systems.
Applications of Self-Supervised Learning in Machine Vision
Image Classification and Object Detection
Self-supervised learning has revolutionized image classification and object detection tasks. You can train models to recognize objects and classify images without relying on large labeled datasets. By leveraging pretext tasks, these models learn to identify patterns and features in images. For example, predicting the rotation of an image or reconstructing missing parts helps the model understand spatial relationships and object structures.
This approach proves especially useful in scenarios where labeled data is limited. For instance, in wildlife monitoring, you can use self-supervised learning to classify animal species from camera trap images. The model learns from the unlabeled data and achieves high accuracy in identifying objects. Additionally, self-supervised learning methods like SimCLR and BYOL have demonstrated competitive performance in object detection benchmarks, rivaling supervised models.
Image Synthesis and Generation
Self-supervised learning enables you to create realistic images through synthesis and generation. Models trained with this approach can generate high-quality images by learning the underlying structure of visual data. For example, generative adversarial networks (GANs) combined with self-supervised learning produce detailed and lifelike images.
You can apply this capability in fields like entertainment, where generating realistic backgrounds or characters is essential. In medical imaging, self-supervised learning helps synthesize images for rare conditions, aiding in diagnosis and research. The ability to generate synthetic data also reduces the dependency on expensive labeled datasets. This makes self-supervised learning a cost-effective solution for various industries.
Video Understanding and Action Recognition
Self-supervised learning plays a critical role in video understanding and action recognition. By analyzing unlabeled video data, models can learn to identify actions and events. You can use pretext tasks like predicting the order of video frames or reconstructing missing frames to train these models.
Research has shown that self-supervised learning achieves state-of-the-art results in video action recognition. Key findings include:
-
Establishing benchmarks for self-supervised video representation learning, enabling fair comparisons of pretext tasks.
-
Demonstrating high performance with significantly less pretraining data.
-
Highlighting the importance of dataset size and task complexity in achieving optimal results.
For example, self-supervised learning allows you to train models for surveillance systems, where recognizing suspicious activities is crucial. Experiments with PackNet have shown that self-supervised networks can match or exceed the performance of LiDAR-supervised models. This is particularly significant for robotics and autonomous systems.
The scalability of self-supervised learning makes it ideal for video-based applications. As the resolution and size of datasets increase, the performance of these models improves, making them suitable for real-world scenarios.
Medical Imaging and Diagnostics
Medical imaging has seen remarkable advancements with the integration of self-supervised learning. This approach allows you to train models on vast amounts of unlabeled medical data, such as X-rays, MRIs, and CT scans. By leveraging pretext tasks, these models can learn to identify patterns and anomalies that are critical for accurate diagnostics.
One of the key benefits of self-supervised learning in medical imaging is its ability to reduce dependency on labeled datasets. Annotating medical images requires expertise and time, making labeled data scarce and expensive. With self-supervised learning, you can use unlabeled images to pretrain models, which can then be fine-tuned for specific diagnostic tasks. For example, a model trained on unlabeled chest X-rays can later be adapted to detect pneumonia or lung cancer.
Tip: Self-supervised learning helps you uncover subtle patterns in medical images that might be missed by traditional methods.
Another advantage lies in its ability to enhance diagnostic accuracy. Models trained with self-supervised learning can identify complex features in medical images, such as the texture of tissues or the shape of abnormalities. These features often play a crucial role in detecting diseases at an early stage. For instance, in mammography, self-supervised models can analyze breast tissue to identify early signs of cancer, improving patient outcomes.
Self-supervised learning also supports the development of robust models for rare diseases. You can train models on limited datasets by using techniques like contrastive learning or masked modeling. These methods enable the model to generalize better, even when the available data is minimal. This capability is particularly valuable in diagnosing rare conditions, where collecting large datasets is challenging.
In addition to diagnostics, self-supervised learning contributes to medical image synthesis. You can generate synthetic images to augment training datasets, which improves model performance. For example, generating synthetic MRI scans can help train models to detect brain tumors more effectively. This reduces the reliance on real-world data and accelerates the development of diagnostic tools.
The application of self-supervised learning in medical imaging is transforming healthcare. It empowers you to build models that are not only accurate but also scalable and cost-effective. By utilizing this approach, you can address some of the most pressing challenges in medical diagnostics, paving the way for better patient care.
The Future of Self-Supervised Learning in Machine Vision Systems
Reducing Dependence on Labeled Data
You can expect self-supervised learning to significantly reduce the reliance on labeled data in the future. This machine learning technique allows models to learn directly from raw, unlabeled data by creating their own labels through pretext tasks. As a result, you can train models without the need for expensive and time-consuming manual annotations. For example, in industries like healthcare or autonomous driving, where labeled datasets are often limited, self-supervised learning can unlock new possibilities.
Advancements in algorithms and computational power will further enhance this capability. Researchers are developing more efficient pretext tasks and architectures that require less data to achieve high accuracy. This progress will make it easier for you to deploy machine vision systems in real-world scenarios, even when labeled data is scarce.
Enhancing Generalization Across Vision Tasks
Self-supervised learning is also transforming how models generalize across different vision tasks. Instead of overfitting to specific datasets, models trained with this approach can adapt to new tasks and environments. Emerging methods like Curriculum Reinforcement Learning (Curr-ReFT) are leading the way.
-
Curr-ReFT improves the generalization of Vision Language Models (VLMs) across diverse tasks.
-
Unlike traditional supervised fine-tuning, it avoids overfitting and performs well in out-of-domain (OOD) settings.
-
Models trained with Curr-ReFT match the performance of larger models, even in challenging scenarios.
These advancements mean you can build models that perform consistently across various applications, from object detection to video understanding. This flexibility makes self-supervised learning a powerful tool for future machine vision systems.
Real-Time Applications in Machine Vision
The future of self-supervised learning includes real-time applications in machine vision. You can use this approach to develop systems that process and analyze visual data instantly. For instance, in surveillance, self-supervised models can detect unusual activities in real time, enhancing security.
In robotics, these models enable machines to navigate and interact with their environment more effectively. By learning from unlabeled data, robots can adapt to new tasks without extensive retraining. This adaptability is crucial for applications like warehouse automation or disaster response.
As hardware becomes more powerful, real-time self-supervised systems will become more accessible. You’ll see these technologies integrated into everyday devices, from smartphones to autonomous vehicles, making them smarter and more efficient.
Self-supervised learning offers unique advantages for machine vision systems. It enables you to train models using unlabeled data, reducing the need for costly annotations. This approach improves efficiency by uncovering patterns and structures within raw data. You can apply it across diverse tasks, from image classification to video understanding, achieving results comparable to supervised methods.
The proposed algorithm, Contextual Self Supervised Learning (ContextSSL), learns equivariance to all transformations (as opposed to invariance). In this way, the model can learn to encode all relevant features as general representations while having the versatility to tail down to task-wise symmetries when given a few examples as the context. Empirically, we demonstrate significant performance gains over existing methods on equivariance-related tasks, supported by both qualitative and quantitative evaluations.
The transformative potential of self-supervised learning lies in its ability to generalize across tasks and adapt to real-world challenges. As advancements continue, you can expect this paradigm to redefine the future of AI and machine vision applications.
FAQ
What is the main advantage of self-supervised learning in computer vision?
Self-supervised learning allows you to train models using unlabeled data, reducing the need for expensive annotations. This approach helps you uncover patterns in images and videos, making it easier to develop robust computer vision systems for tasks like object detection and image classification.
How does self-supervised learning improve computer vision tasks?
By leveraging pretext tasks, self-supervised learning helps models learn meaningful representations from raw data. This improves the accuracy of computer vision tasks, such as recognizing objects or understanding video content, even when labeled datasets are limited.
Can self-supervised learning replace supervised learning in computer vision?
Self-supervised learning complements supervised learning rather than replacing it. You can use it to pretrain models on unlabeled data, which reduces the need for labeled datasets. This makes it a valuable tool for enhancing computer vision systems in scenarios with limited annotations.
What role does contrastive learning play in computer vision?
Contrastive learning helps you train models to identify similarities and differences between images. This technique improves the ability of computer vision systems to recognize patterns and features, making it essential for tasks like image classification and object detection.
Is self-supervised learning suitable for real-time computer vision applications?
Yes, self-supervised learning can power real-time applications like surveillance and robotics. By learning from unlabeled data, models adapt quickly to new environments. This makes them ideal for dynamic computer vision tasks requiring instant analysis and decision-making.
See Also
Understanding Few-Shot And Active Learning In Machine Vision
The Impact Of Deep Learning On Machine Vision Systems
Essential Insights Into Transfer Learning For Machine Vision
Utilizing Synthetic Data To Improve Machine Vision Systems
Defining Predictive Maintenance In Machine Vision Applications








