
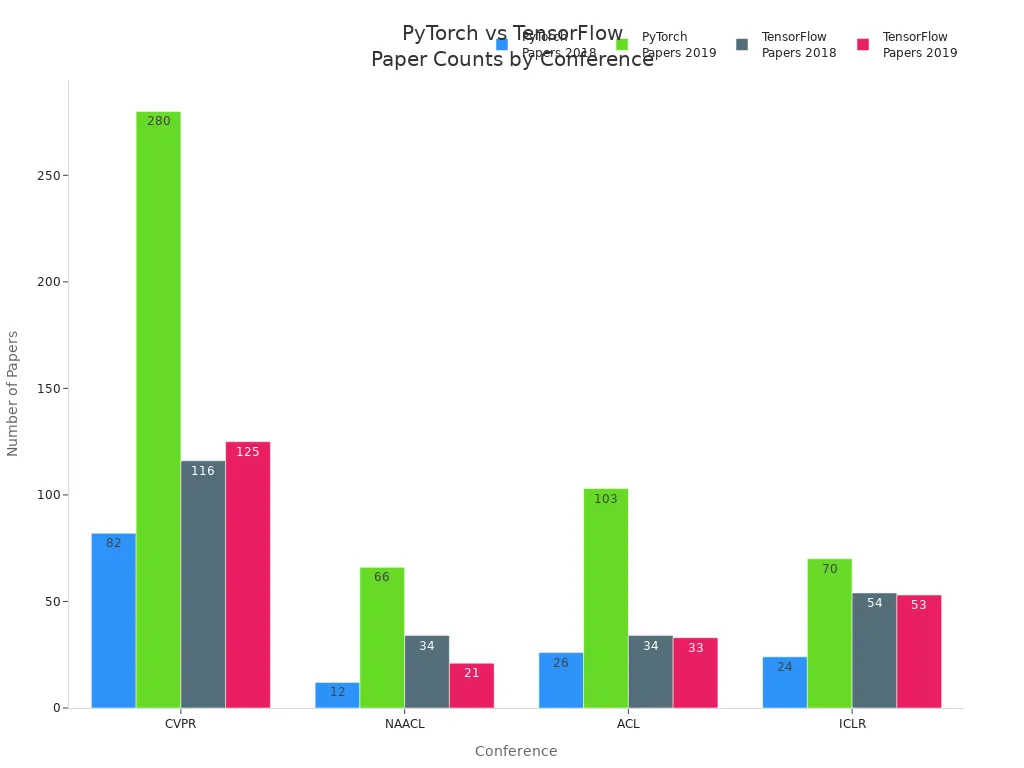
A pytorch machine vision system combines hardware and software to let machines capture and process image data for tasks such as object detection, classification, and pattern recognition. PyTorch stands out as a flexible deep learning framework, often chosen for computer vision projects because of its dynamic graph structure and easy debugging. The pytorch framework, with libraries like torchvision, supports rapid experimentation and transfer learning. Recent trends show growing adoption in research and industry, as seen in the chart below.
Key Takeaways
- PyTorch offers a flexible and modular framework that helps developers build and train computer vision models quickly and easily.
- Using pre-trained models and transfer learning in PyTorch speeds up training and improves accuracy, especially with limited data.
- Proper data preparation, including using diverse datasets and applying image transformations and augmentations, boosts model performance.
- Deploying PyTorch models involves saving them correctly, optimizing for fast inference, and choosing the right hardware for best results.
- PyTorch supports real-world applications across industries like healthcare, automotive, and manufacturing, making it a powerful tool for machine vision.
PyTorch Machine Vision System
Core Components
A pytorch machine vision system uses several important building blocks. These components work together to solve computer vision tasks such as image classification, object detection, and segmentation. The modular design of pytorch allows developers to mix and match these parts for different applications.
- Data handling uses the
DatasetandDataLoaderclasses. These tools help manage large sets of image data and create batches for efficient training. - Many projects use popular datasets from
torchvision.datasets, including MNIST, CIFAR-10, and ImageNet. These datasets provide a strong starting point for building deep learning models. - Image preprocessing happens with
transforms.Compose. This function chains steps like converting images to tensors usingToTensor()and normalizing pixel values withNormalize(mean, std). - Model construction can use pre-trained architectures from
torchvision.modelssuch as ResNet or VGG. Developers can also build custom models by subclassingnn.Moduleand adding layers likeConv2d,MaxPool2d, andLinear. - The training process includes defining a loss function, such as
CrossEntropyLoss, and choosing an optimizer like SGD or Adam. The training loop runs forward passes, computes loss, performs backpropagation withloss.backward(), and updates weights usingoptimizer.step(). - Evaluation measures how well the model performs on validation data. Metrics like accuracy help track progress and guide improvements.
PyTorch’s object-oriented approach with
nn.Modulemakes each part reusable and easy to update. This modularity supports fast experimentation and helps teams maintain and scale their projects. Developers can swap layers, add new features, or change architectures without starting from scratch. PyTorch also supports complex models and custom operations, making it flexible for many computer vision applications.
Use Cases
PyTorch machine vision systems power many real-world applications. These systems appear in industries such as automotive, healthcare, and manufacturing. They help solve problems like real-time video analytics, industrial inspection, and mobile health monitoring.
| Industry Sector | Example Applications/Use Cases |
|---|---|
| Automotive | Real-time video analytics, autonomous vehicles |
| PCBA | Inspection of printed circuit board assemblies |
| Battery Manufacturing | Battery tab laser weld inspection |
| Semiconductor | Stator core inspection |
| Connectors | Gear machining inspection |
| Packaging | Flexible plastic packaging inspection |
| Healthcare | Syringe final inspection, mobile health monitoring |
PyTorch Mobile lets developers deploy models on mobile and edge devices. This feature supports applications like augmented reality and mobile health monitoring. On-device inference reduces latency and keeps data private. Quantization helps shrink model size and speed up predictions, which is important for resource-limited devices.
Many computer vision tasks use pytorch, including image classification, object detection, and image segmentation. For example, the Central Asian Food Scenes Dataset (CAFSD) contains over 21,000 images and supports detection and segmentation tasks. Models like YOLOv8, trained with pytorch, show strong performance on this dataset. The chart below compares mAP and inference times for different YOLOv8 models using pytorch.
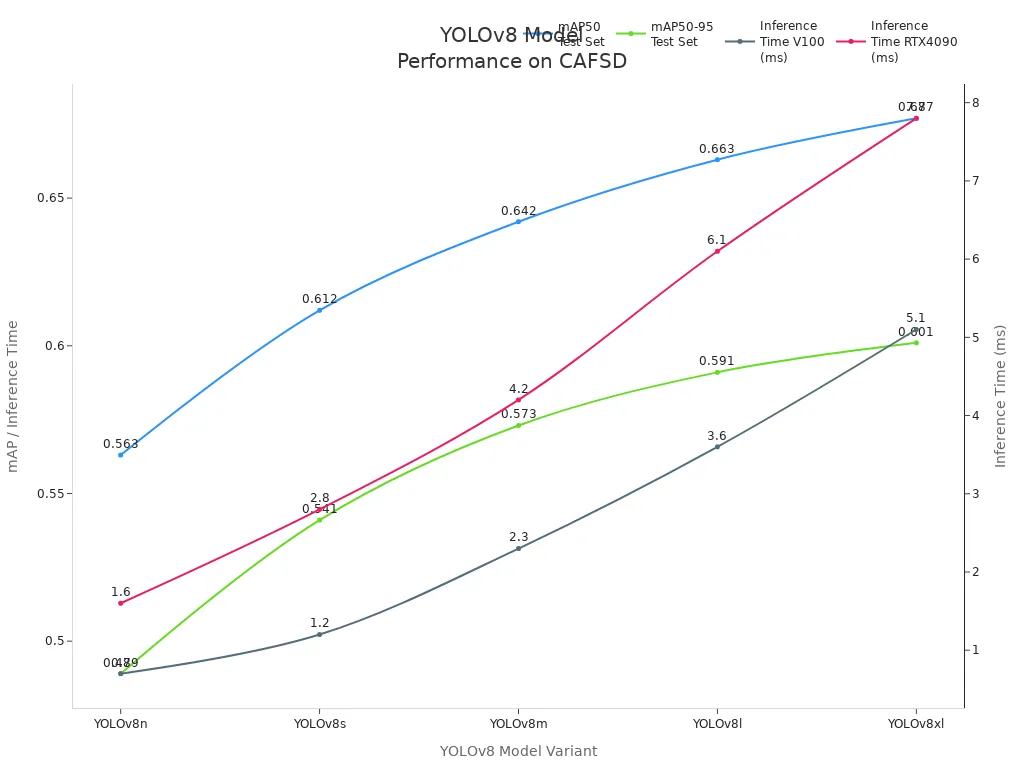
The CAFSD dataset includes images from real-life and web sources, with bounding boxes for 239 food classes. The diversity in image quality and class distribution reflects real-world challenges. PyTorch machine vision systems handle these challenges by supporting advanced deep learning models and efficient training workflows.
Industrial computer vision relies on pytorch for inspection tasks, while healthcare uses it for monitoring and diagnostics. These examples show the wide reach of pytorch machine vision systems in modern machine learning applications.
Environment Setup
Setting up a PyTorch machine vision system starts with the right environment. This step ensures smooth installation, efficient model training, and a reliable pytorch workflow.
PyTorch Installation
Before installing pytorch, users should check their hardware and software. PyTorch supports Linux, macOS, and Windows. Most users need a 64-bit CPU with AVX or AVX2 support. For faster training, an NVIDIA GPU with Compute Capability 3.5+ or an AMD GPU with ROCm support is helpful. More demanding projects may need extra RAM and storage.
- Supported operating systems: Linux (Ubuntu, Fedora, CentOS), macOS (10.13+), Windows (7, 8, 10)
- Supported Python versions: 3.9 to 3.12
- Package managers: pip or conda
- Virtual environments: Recommended for clean installations
To install pytorch and torchvision, users can run:
pip install torch torchvision
or with conda:
conda install pytorch torchvision -c pytorch
Common installation issues include environment mismatches, missing dependencies, or installing the wrong version. Users often find that Jupyter Notebook cannot import torch because it uses a different Python environment. Creating a fresh virtual environment and installing pytorch there solves most problems. If using a GPU, users should check CUDA compatibility and use the official installation commands.
Torchvision and Dependencies
Torchvision extends pytorch for computer vision. It provides pre-trained models, data transformations, and utilities for image processing. Torchvision relies on PIL for lightweight image handling. Some projects use OpenCV for more advanced tasks. Torchvision’s transforms module offers functions like random rotations and normalization, which help speed up the pytorch workflow. These tools reduce the need for custom code and make pipelines easier to build.
For best results, users should install compatible versions of torch and torchvision. On platforms like Jetson Orin, building torchvision from source with CUDA support can improve performance. Containers with pre-installed pytorch, torchvision, and OpenCV simplify setup for large projects.
Device Configuration
Choosing the right device affects performance in pytorch machine vision systems. CPUs handle data preprocessing and general tasks well. GPUs excel at training deep learning models because they process many operations at once. For inference, CPUs work best for single requests, while GPUs handle many requests quickly.
- CPUs: Good for preprocessing, prototyping, and small models
- GPUs: Best for training and high-throughput inference
- TPUs: Useful for large-scale tensor computations in advanced setups
A hybrid approach often works best. CPUs manage data and business logic, while GPUs handle heavy computations. After installation, users can check GPU access in Python:
import torch
print(torch.cuda.is_available())
This command returns True if pytorch can use the GPU. For distributed training, pytorch supports multiple GPUs or TPUs, which helps scale up projects.
Tip: Always match pytorch, torchvision, and CUDA versions for smooth operation and fewer errors.
Data Preparation
Datasets for Computer Vision
Selecting the right dataset is a key step in building a computer vision system. PyTorch supports many well-known datasets that help researchers and engineers train and evaluate their models. The table below lists some of the most widely used datasets, covering domains like medical imaging, object detection, and video action recognition.
| Dataset Name | Domain | Size/Content Description | Annotations/Use Cases |
|---|---|---|---|
| BRATS | Medical Imaging | 200+ high-res 3D MRI scans with 4 modalities | Brain tumor segmentation |
| Caltech 101 | Image Classification | 9,144 images across 101 object categories | Classification benchmarks |
| CelebA | Face Attribute Recognition | 200,000+ celebrity images with 40 facial attributes | Face detection, attribute recognition |
| VOC | Object Detection/Segmentation | ~5,000 training images, 10,000 test images | Object detection, segmentation |
| KITTI | Autonomous Driving | 4,000+ high-res images, LIDAR, sensor data | Object detection, tracking, segmentation |
A diverse dataset helps a model learn to recognize patterns in many situations. Studies show that dataset diversity predicts model performance better than size alone. The chart below compares accuracy and AUC scores for several medical imaging datasets. Models trained on more diverse data achieve higher accuracy and generalization.
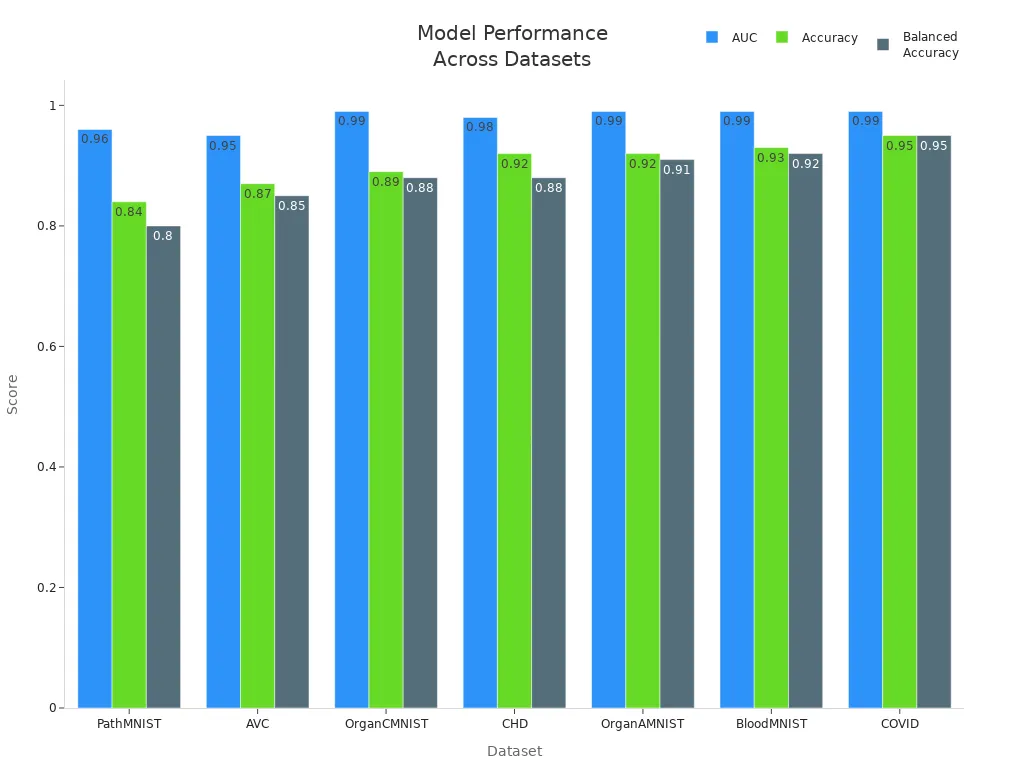
Tip: When using small or less diverse datasets, freezing batch normalization layers during training can improve results.
Image Transformations
Image transformations prepare raw data for computer vision tasks. PyTorch’s torchvision.transforms module offers many tools for this purpose. Common transformations include:
- Resize: Changes the image size to a standard shape, such as 256×256 pixels.
- ToTensor: Converts images to tensor format for model input.
- Normalize: Adjusts pixel values to help models learn faster.
- RandomCrop: Crops images at random locations to add variety.
- RandomHorizontalFlip: Flips images horizontally to simulate different viewpoints.
- RandomRotation: Rotates images within a set angle range.
These transformations help standardize input data and make the training process more stable.
Data Augmentation
Data augmentation increases the variety of images seen during training. This process helps models generalize better and reduces overfitting. PyTorch supports several augmentation strategies:
- Geometric transformations: Random flips, rotations, and crops change the position and orientation of objects.
- Color adjustments: Techniques like ColorJitter simulate lighting changes.
- Occlusion methods: Cutout and RandomErasing hide parts of the image, forcing the model to focus on different features.
- Sample mixing: Mixup and CutMix blend images and labels to create new samples.
These methods expose the model to many versions of each image, helping it learn robust features for computer vision tasks.
Model Training

Model Architectures
PyTorch supports many powerful model architectures for computer vision. These architectures help solve tasks like image classification, object detection, and segmentation. Developers often use convolutional neural network designs because they work well with image data. Some of the most popular models in PyTorch include:
- ResNet: Used for image classification. It uses skip connections to help the model learn deeper features.
- Faster R-CNN: Designed for object detection. It finds objects in images and draws bounding boxes around them.
- Mask R-CNN: Used for segmentation. It not only detects objects but also outlines their exact shapes in the image.
PyTorch makes these models available in the torchvision package. Developers can use pre-trained versions or build custom models by combining layers like Conv2d, MaxPool2d, and Linear. The dynamic computational graph in PyTorch allows easy changes and fast experimentation. Researchers often choose PyTorch for its flexibility and Pythonic style.
PyTorch Lightning helps organize code and manage the training process. It improves productivity and keeps projects clean.
The table below shows how different convolutional neural network models perform on real tasks:
| Study / Task | Model(s) Used | Framework | Accuracy / Result |
|---|---|---|---|
| Nitrogen content estimation in wheat | CNN with 5 conv + 3 pooling layers | PyTorch | 97.5% calibration accuracy, 86.1% validation accuracy |
| Potato disease detection | GoogleNet, VGGNet, EfficientNet | PyTorch | EfficientNet best suited for real-world use |
| Fashion MNIST classification | LeNet-5 | PyTorch vs TensorFlow | TensorFlow slightly better (~2% higher accuracy) |
These results show that convolutional neural network models in PyTorch achieve high accuracy in many domains. PyTorch performs well compared to other frameworks, making it a strong choice for model training and testing.
Transfer Learning
Transfer learning is a method that uses knowledge from one task to help solve another. In PyTorch, transfer learning often means starting with a model trained on a large dataset, like ImageNet, and fine-tuning it for a new task. This approach saves time and improves accuracy, especially when the new dataset is small.
The steps for transfer learning in PyTorch are:
- Select a pre-trained model from torchvision.models, such as ResNet.
- Load the model with its pre-trained weights.
- Freeze some layers to keep their learned features. This is helpful when the new dataset is similar to the original.
- Replace the final layer to match the number of classes in the new classification task.
- Prepare the image dataset with the right preprocessing and augmentation.
- Train the model by fine-tuning with an optimizer and learning rate scheduler.
- Test and optimize the model to improve results.
Transfer learning offers many benefits:
- Training is faster because the model already knows useful features.
- Accuracy improves, often by 10-20% or more, compared to training from scratch.
- The model needs fewer labeled images, sometimes only a few thousand instead of millions.
- Fine-tuning can reduce training time by up to 90%.
- Real-world projects, like medical imaging, have reached up to 99% precision and recall using transfer learning in PyTorch.
Transfer learning helps teams build strong models quickly, even with limited data. It also makes AI development more accessible and scalable.
Training and Evaluation
The training process in PyTorch involves several key steps. First, developers choose a loss function that matches the task. For image classification, CrossEntropyLoss is common. For regression, MSELoss works well. Segmentation tasks often use Dice Loss or Focal Loss. The table below lists popular loss functions and optimizers:
| Category | Examples in PyTorch | Description and Usage |
|---|---|---|
| Loss Functions | nn.MSELoss (Mean Squared Error) | Used for regression tasks, measures average squared difference between predicted and true values. |
| nn.CrossEntropyLoss | Used for classification tasks, outputs prediction error on logits. | |
| nn.NLLLoss (Negative Log Likelihood) | Used for classification, often with LogSoftmax. | |
| Dice Loss | Used for segmentation, measures overlap between predicted and true masks. | |
| Focal Loss | Used for object detection, focuses on hard-to-classify examples. | |
| Optimizers | torch.optim.SGD (Stochastic Gradient Descent) | Adjusts model parameters using gradients, common in training loops. |
| torch.optim.Adam | Adaptive optimizer, often faster and more effective for many models. | |
| torch.optim.RMSprop | Adapts learning rates, useful for some neural network training scenarios. |
During model training, the optimizer updates the model weights to reduce the loss. The training process repeats for several epochs, with the model learning from batches of image data. After training the model, developers use testing to measure how well it performs.
Testing uses evaluation metrics to check the model’s accuracy and reliability. For classification and object detection, important metrics include:
- Precision: Measures how many positive predictions are correct.
- Recall: Checks how many actual positives the model finds.
- F1 Score: Balances precision and recall.
- AUC: Shows overall classification performance.
- Intersection over Union (IoU): Measures overlap between predicted and true bounding boxes in object detection.
For regression tasks, metrics like Mean Absolute Error (MAE), Mean Squared Error (MSE), and R-squared help evaluate prediction accuracy. Using several metrics gives a better picture of model performance, especially with imbalanced datasets.
Benchmarking on datasets like ImageNet and MS COCO helps compare models and improve testing standards.
PyTorch makes it easy to switch between CPU and GPU during training and testing. This flexibility helps teams scale their projects and speed up the training process. Developers can also use tools like PyTorch Lightning to organize code and manage experiments.
Deployment
Saving and Loading Models
Saving and loading a pytorch model is an important step before deployment. Developers use several methods to make sure the model works well in production:
- Save and load the model state dictionary with
torch.save()andtorch.load(). This method stores the model’s learned parameters. - Use
model.state_dict()to save only the parameters. This approach is memory efficient. Developers must recreate the model architecture before loading these parameters. - Save checkpoints that include the model state, optimizer state, epoch, and loss. This helps resume training or recover from errors.
- Convert the model to TorchScript format with
torch.jit.traceand save it usingtorch.jit.save. TorchScript models run without Python, which is useful for production. - Export the model to ONNX format with
torch.onnx.export. ONNX models work across different platforms and can use ONNX Runtime for fast inference. - Serve models with TorchServe. This tool supports features like multi-model serving, versioning, and monitoring.
- Developers can also build custom REST APIs with Flask or FastAPI for more control.
Tip: Always test the saved and loaded model to make sure it gives the same results as before.
Inference
Inference means using a trained pytorch model to make predictions on new image data. For best results, developers follow these steps:
- Switch the model to evaluation mode with
model.eval(). This step ensures layers like dropout and batch normalization work correctly during testing. - Use
torch.no_grad()to turn off gradient calculations. This saves memory and speeds up inference. - Optimize the model with TorchScript or PyTorch 2.0’s
torch.compile()for faster execution. - Apply quantization to reduce model size and speed up predictions, especially on CPUs.
- Benchmark the model in the target environment to find the best settings.
- Avoid mistakes like forgetting to set evaluation mode or disabling gradients, which can cause errors during testing.
These steps help achieve real-time inference and reliable automation in computer vision systems.
Scaling and Production
Scaling pytorch machine vision systems for production requires careful planning. Large companies have used pytorch models to process billions of daily inferences. They often use ONNX Runtime and hardware like NVIDIA GPUs to boost throughput. For example, ONNX Runtime can improve throughput by over 25% on CPUs and nearly triple it with quantization on GPUs. Tools like NVIDIA Triton Inference Server help manage many models and requests at once.
Teams face challenges such as data management, deployment complexity, and monitoring. The table below shows common issues and their impact:
| Challenge Category | Specific Challenges | Description / Impact |
|---|---|---|
| Data and Management | Data quality, privacy, storage | Affects model performance and lifecycle |
| Model Development and Training | Model selection, overfitting, resources | Impacts robustness and efficiency |
| Deployment and Infrastructure | Monitoring, scalability, latency | Key for real-time and reliable automation |
| Organizational and Strategic | Skills, budget, compliance | Influences deployment success |
Platforms like Northflank simplify deployment by offering GPU support, autoscaling, and real-time logs. PyTorch also supports API tracking and custom extensions, making it easier to manage and monitor models in production. These features help teams deliver fast, reliable, and scalable machine vision solutions.
Building a PyTorch machine vision system involves setting up the environment, preparing image data, training models, and deploying solutions. PyTorch’s ecosystem supports advanced techniques like transfer learning, which speeds up progress in computer vision. Many leading companies use PyTorch for real-world applications.
- Practitioners can explore new datasets, try advanced tasks like real-time detection, or join community events to keep learning.
Staying updated with trends such as edge computing and ethical AI helps improve future projects.
FAQ
What is the main advantage of using PyTorch for computer vision?
PyTorch gives developers flexibility and control. They can build, test, and change models quickly. The dynamic graph structure helps with debugging and fast experiments. Many researchers and companies choose PyTorch for these reasons.
How does transfer learning help with small datasets?
Transfer learning uses knowledge from large datasets. A model trained on many images can learn new tasks with fewer examples. This method saves time and improves accuracy, especially when data is limited.
Can PyTorch models run on mobile devices?
Yes, PyTorch Mobile allows models to run on phones and tablets. Developers can use quantization to make models smaller and faster. This helps with real-time tasks like image recognition on mobile apps.
What should developers check before deploying a model?
Developers should test the model with new data. They need to check accuracy, speed, and memory use. Saving the model in TorchScript or ONNX format helps with deployment. Testing ensures the model works well in real-world situations.
See Also
Understanding The Fundamentals Of Image Processing In Vision
The Role Of Cameras Within Machine Vision Technology
Exploring Computer Vision Models Used In Machine Systems
Deep Learning Techniques Improving Machine Vision Performance








