
An optical character recognition machine vision system in 2025 uses advanced AI to read and extract text from images, documents, and product labels. These systems now achieve over 99% character accuracy and process more than 2,000 pages per minute. Organizations rely on them to cut costs and boost efficiency in daily tasks. Their high accuracy in defect detection and diagnostics supports large-scale adoption. The table below shows how these machine vision solutions deliver strong results across industries:
| Metric Category | Performance Range/Value |
|---|---|
| Character accuracy | Over 99% |
| Processing speed | 2,000+ pages/minute |
| Field detection rate | 95–99% |
| Handwriting recognition | 65–90% accuracy |
Key Takeaways
- OCR machine vision systems in 2025 use advanced AI to read text from images and documents with over 99% accuracy and very fast processing speeds.
- These systems include key parts like high-quality cameras, AI-powered text recognition engines, and error-correcting language models to ensure precise text extraction.
- Modern OCR supports many languages and handwriting styles, making it useful for global businesses and diverse document types.
- Flexible deployment options let companies choose cloud, edge, or hybrid setups to fit their speed, security, and volume needs.
- OCR technology boosts efficiency by automating tasks in industries like manufacturing, healthcare, and finance, saving time and reducing errors.
Optical Character Recognition Machine Vision System
Definition and Purpose
An optical character recognition machine vision system in 2025 serves as a powerful tool for extracting text from images, scanned documents, and product packaging. These systems help businesses and industries automate the process of reading and understanding printed or handwritten text. They use advanced ocr technology to extract text from images with high accuracy, making them essential for tasks like document ocr, quality control, and compliance checks.
The main purpose of an optical character recognition machine vision system is to extract text and data from a wide range of sources. Companies use these systems to process documents, verify labels, and digitize records. In manufacturing, ocr technology checks product labels for accuracy. In healthcare, it helps manage patient documents and improves data accuracy. Banks use ocr to process checks and digitize forms. Logistics companies rely on ocr to track packages and sort shipments efficiently.
The global machine vision market continues to grow rapidly. Experts predict a compound annual growth rate of 9.8% from 2025 to 2032, with the market reaching over USD 28.6 billion by 2032. This growth comes from the integration of AI, deep learning, and 3D vision technology. These trends make ocr systems more capable and flexible, supporting automated inspection and fast data extraction in many industries.
Note: Image processing machine vision systems now replace manual inspection with automated, algorithm-driven analysis. They provide high accuracy, real-time processing, and easy integration with robotics. These features are critical for ocr applications that require precise and efficient text extraction and quality assurance.
Core Components
Every optical character recognition machine vision system includes several key components that work together to extract text from images and documents. These components ensure the system can handle different types of text, document formats, and image qualities.
- Imaging Hardware: High-resolution cameras and sensors capture clear images of documents and labels. Good lighting and lens quality help the system extract text from images with minimal errors.
- Image Processing Unit: This unit cleans and enhances the captured images. It removes noise, adjusts contrast, and prepares the image for text extraction.
- OCR Engine: The core of the system uses advanced ocr technology, including AI and neural networks, to recognize and extract text from images. Modern ocr engines support over 50 languages and can read both printed and handwritten text.
- Postprocessing Module: Fine-tuned large language models (LLMs) correct errors and improve the accuracy of extracted text and data. For example, using LLMs has reduced the character error rate by 56% in recent systems.
- Confidence Scoring and Review: The system assigns confidence scores to each extracted text segment. If the score falls below a set threshold (usually 86–90%), the system flags the result for human review.
- Integration and Output: The system exports the extracted data to business applications, databases, or robotic systems for further processing.
| Metric/Feature | Value/Description |
|---|---|
| OCR Accuracy (printed text) | Approximately 98% accuracy with Google Cloud Vision |
| Confidence Score Thresholds | 86–90% for auto-acceptance vs human review |
| Language Support | 50+ languages supported |
Modern document ocr systems also support clinical natural language processing models. These models achieve F1 scores between 0.80 and 0.90 for medical entity extraction, sometimes exceeding 0.90. This high performance demonstrates the reliability of ocr technology in extracting text and data from complex documents.
Tip: Companies can choose from different deployment options, such as edge devices, cloud-based solutions, or hybrid systems. This flexibility allows them to match the ocr system to their specific needs and environments.
How OCR Works

Image Processing
OCR systems in 2025 start with image capture. High-resolution cameras or scanners create digital images of documents, labels, or packaging. The system then uses preprocessing to improve the quality of these images. Preprocessing steps include binarization, which turns images into black and white, and contrast enhancement, which makes text stand out. Deskewing corrects tilted pages, and denoising removes unwanted marks or smudges. These steps help the OCR models find and separate text from the background, a process called text segmentation.
Technical benchmarks help measure the efficiency of image processing in OCR:
| Benchmark / Metric | Description | Typical Performance / Impact |
|---|---|---|
| Character Error Rate (CER) | Ratio of character insertions, deletions, substitutions to total characters | Industry-leading solutions achieve CER < 1% |
| Word Error Rate (WER) | Similar to CER but at word level | WER < 2% for high-quality printed documents |
| Field Extraction Rate | Percentage of correctly identified and extracted fields | 97–99% for standardized forms |
| Field Value Accuracy | Correctness of extracted field values | 95–97% for clear printed text fields |
| Confidence Scores | Confidence assigned to recognized characters, words, or fields | Used to flag low-confidence results and optimize workflows |
| Image Quality Factors | Resolution (DPI), contrast, noise, skew, alignment | 300 DPI standard; preprocessing can improve accuracy by 15–30% |
| Preprocessing Techniques | Binarization, deskewing, denoising, DPI normalization | Deskewing improves accuracy by 5–15%, denoising by 3–8% |
| Testing Methodologies | Ground truth comparison, cross-validation, real-world testing | Ensures robust evaluation of OCR efficiency |
Most OCR systems use a 300 DPI standard for regular text. For small fonts, 400–600 DPI works best. Preprocessing can improve accuracy by up to 30%. Text segmentation and field extraction ensure the system finds every word and number.
AI and Neural Networks
Modern OCR models rely on AI, deep learning, and neural networks to boost text recognition. These systems use deep learning OCR tools to analyze patterns in letters and words. The recognition process starts with text segmentation, where the system divides the image into lines, words, and characters. Machine-learning-based OCR then compares these segments to millions of examples stored in its memory.
Neural networks help the OCR models learn from new data. They adapt to different fonts, languages, and even handwriting. The recognition process becomes faster and more accurate with each update. AI-driven OCR can now handle over 50 languages and complex layouts. These advances make text extraction from images much more reliable.
Note: Companies use OCR for many tasks, such as document scanning, quality checks, and data entry. The combination of AI and advanced image processing gives businesses high-speed, accurate text recognition.
Key Features
Accuracy and Speed
Modern OCR systems in 2025 show remarkable improvements in both accuracy and speed. These systems now reach digit recognition accuracy rates of 92.4%, with a 95% confidence interval between 91.6% and 93.2%. This high level of precision means fewer errors when extracting text from images or documents. Processing speed has also increased. Current OCR solutions operate about three times faster than older data entry methods. This speed allows organizations to process thousands of pages or labels every minute. High accuracy and fast processing help reduce manual work and improve business efficiency. Reliable OCR systems now support real-time text extraction in busy environments like hospitals, warehouses, and offices.
Note: High accuracy and speed in OCR systems lead to better data quality and faster decision-making.
Multilingual and Handwriting Support
OCR technology in 2025 supports a wide range of languages and scripts. Deep learning models and large language models (LLMs) help these systems recognize text in over 80 languages. They also handle complex layouts and ambiguous characters. Handwriting recognition has improved greatly. For example, OCR systems can now achieve up to 99.94% character recognition accuracy for handwritten Devanagari numbers and up to 99.99% for Bangla numerals. On standard documents, LLM-powered OCR systems reach accuracy rates between 98.97% and 99.56%. Even on poor quality images, accuracy improves by 20-30% compared to older systems.
| Language/Script | Dataset Description | Recognition Accuracy | Notes |
|---|---|---|---|
| Devanagari | 22,556 handwritten numbers, 300 dpi grayscale images | Up to 99.94% | Supports deep learning models |
| Bangla | 23,392 handwritten numerals, 300 dpi grayscale images | Up to 99.99% | Large dataset |
| Arabic | CENPARMI Arabic database | N/A | Suitable for offline handwriting recognition |
| Urdu | CENPARMI Urdu database | N/A | Useful for deep learning |
| Farsi | CENPARMI Farsi database, 432,357 images | N/A | Large-scale, supports symbol and digit recognition |
These advances make OCR a strong tool for global businesses and organizations that handle documents in many languages.
Deployment Options
OCR systems in 2025 offer flexible deployment choices. Companies can use edge devices for on-site processing, cloud-based solutions for large-scale operations, or hybrid models that combine both. Edge deployment works well for environments that need fast, local text extraction, such as manufacturing lines or logistics hubs. Cloud deployment supports high-volume document processing and easy integration with other business tools. Hybrid options give organizations the ability to balance speed, security, and scalability. This flexibility ensures that OCR technology fits different business needs and technical environments.
Character Recognition Applications

Industrial Automation
Character recognition systems play a key role in industrial automation. These systems read labels, verify expiration dates, and inspect packaging on production lines. Companies use character recognition to automate accounts payable and invoice processing. For example, Applied Industrial Technologies achieved major gains with AI-driven character recognition. The company processed 87% of accounts payable tasks autonomously, reduced staff needs by 40%, and processed 91% of invoices in under two minutes. Data flowed into their ERP system quickly, with 87% of information transferred within ten minutes.
| Metric | Value | Description |
|---|---|---|
| Autonomous AP processing | 87% | Percentage of accounts payable processing done autonomously using AI-driven OCR |
| Reduction in FTE headcount | 40% | Decrease in full-time equivalent staff due to automation |
| Invoices processed under 2 min | 91% | Percentage of invoices processed within 2 minutes |
| Data throughput to ERP system | 87% within 10 min | Percentage of data flowing directly into ERP system within 10 minutes |
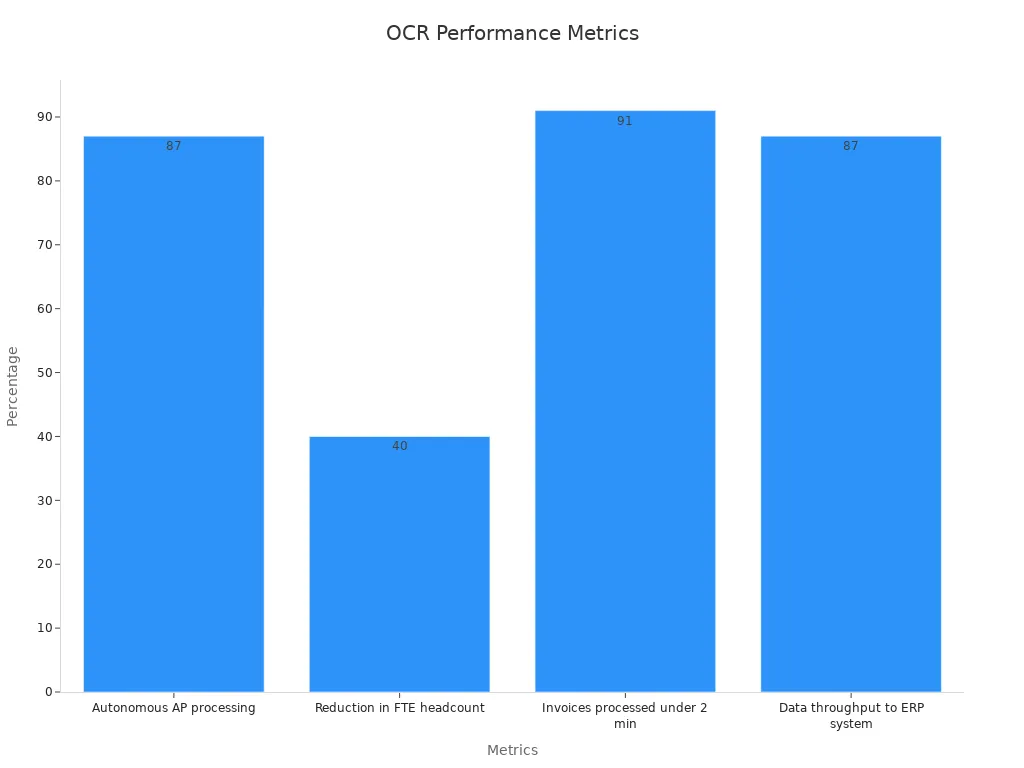
These results show how character recognition increases efficiency and reduces errors in the pipeline.
Document Processing
Character recognition transforms document processing for many businesses. Intelligent document processing systems extract data from digital documents and paper records. Companies save four to six hours per week for each employee by automating routine document tasks. The intelligent document processing pipeline reduces costs by 24% in the first year. Over half of companies say faster document processing is the top benefit. Data accuracy improves from 50-70% to over 95% when AI and human validation work together.
| Metric / Benefit | Statistic / Data | Explanation |
|---|---|---|
| IDP Market Growth | CAGR of 32.5% (2023-2030) | Indicates strong adoption driven by efficiency gains |
| Time Savings | 4 to 6 hours saved per week per employee | Automation reduces routine task time |
| Cost Reduction | 24% average cost reduction in first year | Document automation lowers operational costs (Deloitte) |
| Document Processing Priority | 55% of companies rank accelerating document processing as top benefit | Shows importance of speed improvements |
| Break-even Time | 59% of businesses break even within a year using paperless software | Demonstrates quick ROI from digitization |
| Data Accuracy Improvement | From 50-70% to over 95% with AI + human validation | Reduces costly errors, improves data quality |
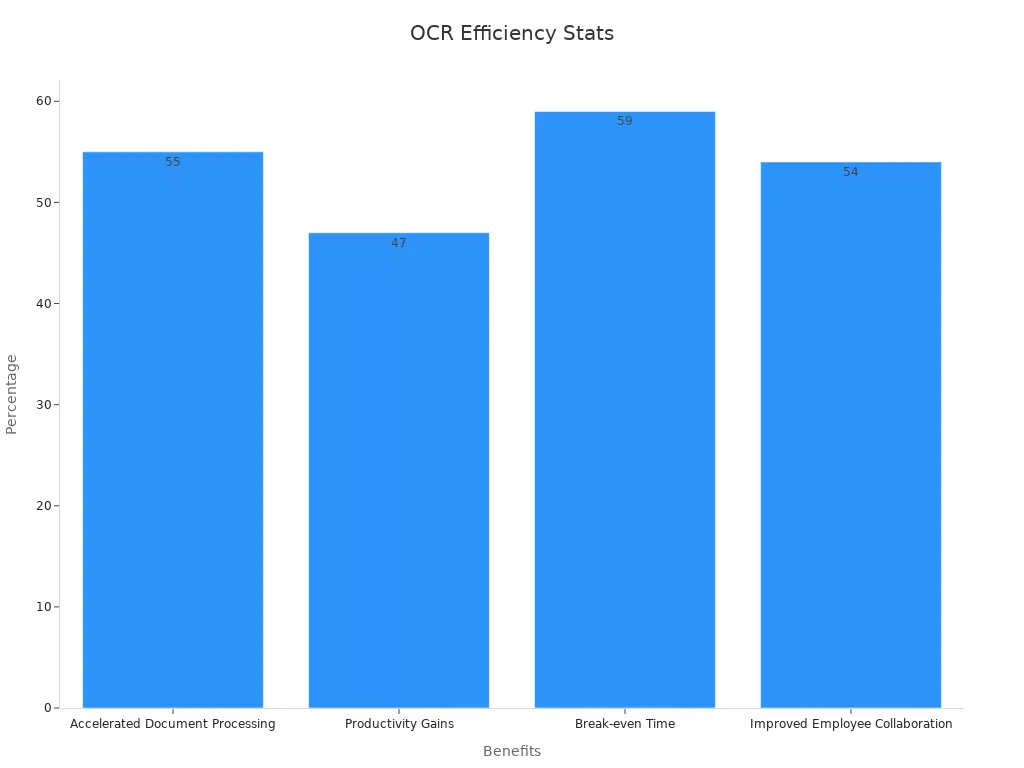
Character recognition in the document processing pipeline supports better document intelligence and automated data extraction.
Quality Control
Character recognition ensures high quality in production environments. Companies use these systems to check product labels, verify codes, and maintain document integrity. Benchmarks like Exact Match, BLEU, and ROUGE help measure system performance. Docsumo’s character recognition pipeline preserves document layout and structure, achieving high extraction accuracy and fast processing times. Quality control teams use diverse test samples and compare results to ground truth data. They check precision, recall, and layout consistency. Continuous feedback and real-time data help refine accuracy in the pipeline. These steps ensure robust document intelligence and reliable character recognition for every document.
Character recognition supports efficiency, reduces errors, and delivers strong business impact across industrial automation, document processing, and quality control pipelines.
Comparing OCR Generations
Technological Advancements
OCR technology in 2025 shows major improvements over earlier versions. Several new features set these systems apart:
- Computer vision now helps OCR detect and classify each character. This step improves the first stage of recognition.
- Natural language processing algorithms correct mistakes by understanding the context of words. These algorithms can estimate missing characters, which increases accuracy.
- Supervised deep learning allows OCR to learn from huge labeled datasets. The system can recognize many fonts and fix errors more easily.
- Large language models boost accuracy, especially for handwriting and cursive text. These models help OCR handle difficult cases that older systems could not solve.
- The combination of these advancements pushes OCR accuracy above 99% for typewritten text. Complex scenarios, such as mixed layouts or poor image quality, now see much better results.
Industry standards have also evolved. Modern OCR systems support structured outputs, such as markdown or LaTeX, and can process multi-page documents. Integration with business software and robotic systems is now much easier, making the OCR pipeline more flexible and powerful.
Performance Differences
Current OCR models outperform traditional systems in many ways. New models like GOT use a unified end-to-end architecture. This design removes the need for separate detection and recognition steps. The OCR pipeline now handles complex documents, scene text, and even mathematical formulas.
- GOT supports multiple input styles, including scene and document images.
- The model can process multi-page documents and generate structured outputs.
- Fine-grained OCR allows region-specific recognition and dynamic resolution handling.
Traditional OCR works best with high-volume, simple-layout documents. It offers fast processing and low latency. Newer models and large language models excel with variable layouts and content that needs context, such as receipts or medical records. Hybrid approaches combine both strengths, using OCR for structured data and language models for deeper understanding. While traditional OCR uses less computing power, modern systems offer more versatility and accuracy, especially in complex pipelines.
Optical character recognition machine vision systems in 2025 help companies read and process text from every document quickly and accurately. These systems use AI to improve text recognition, layout understanding, and handwriting detection. When choosing a system, users should check accuracy, speed, reliability, and how well it handles different document types. Real-time processing and strong cloud integration make these tools useful for many documents. Companies can use these systems to save time, lower costs, and keep document data safe. For more details, readers can explore guides on document automation and text extraction.
FAQ
What types of document can OCR machine vision systems process in 2025?
OCR machine vision systems can process many types of document. These include printed forms, handwritten notes, invoices, receipts, and product labels. The systems also handle multi-page document files and complex layouts. Businesses use them to digitize and organize every document they receive.
How do OCR systems ensure document accuracy?
OCR systems use advanced AI and neural networks to check each document for errors. They assign confidence scores to every document segment. If the score is low, the system flags the document for review. This process helps keep document data accurate and reliable.
Can OCR machine vision systems read handwritten document content?
Yes, OCR machine vision systems in 2025 can read handwritten document content. Deep learning models help the system recognize many handwriting styles. The system can extract text from a handwritten document with high accuracy. This feature supports schools, hospitals, and offices that use handwritten document records.
What are the main benefits of using OCR for document management?
OCR helps companies manage document storage, search, and retrieval. The system turns paper document files into digital records. This makes it easy to find any document quickly. Businesses save time, reduce errors, and improve document security by using OCR for document management.
How do companies deploy OCR systems for document processing?
Companies can deploy OCR systems on edge devices, in the cloud, or with hybrid setups. Edge deployment processes document data locally. Cloud deployment handles large document volumes. Hybrid models combine both. Each option helps companies match their document processing needs and security requirements.
See Also
Understanding Machine Vision Systems Through Image Processing
The Role Of Character Recognition In Advanced Vision Systems
Exploring Machine Vision Systems And Computer Vision Models
Comparing Firmware-Based Vision Systems With Traditional Methods








