
Imagine a camera system that must analyze thousands of images every second. Machine learning applications often rely on gpu acceleration to process data quickly. nvidia provides a solution with its container toolkit. This toolkit allows users to run docker containers that access nvidia gpus without complex setup. The toolkit automates driver and library configuration for each container. Users can deploy ai and ml workloads with fewer steps. The nvidia toolkit removes manual gpu provisioning, making docker deployment easier for beginners. Many computer vision projects now use the NVIDlA Container Toolkit machine vision system for efficient gpu access. nvidia’s integration with docker helps machine learning applications scale across different hardware. nvidia has made gpu-powered containers more accessible to everyone.
Key Takeaways
- The NVIDIA Container Toolkit lets you run GPU-powered applications inside Docker containers easily, without complex setup.
- Machine vision systems gain faster processing and better efficiency by using the toolkit to access NVIDIA GPUs in containers.
- To use the toolkit, your system needs a compatible NVIDIA GPU (Volta or newer), proper drivers, Docker, and a supported OS like Ubuntu or Windows with WSL2.
- Setting up involves installing NVIDIA drivers, Docker, and the container toolkit, then configuring Docker to allow GPU access for containers.
- Keep your system updated, use official GPU-enabled container images, and monitor GPU usage to ensure secure and efficient machine vision workloads.
What Is the NVIDIA Container Toolkit?
The NVIDIA Container Toolkit helps users run GPU-accelerated applications inside containers. This toolkit provides open-source utilities that make it easy to deploy machine learning applications and AI workloads in Docker containers. Users do not need to change their applications to access GPU resources. The toolkit works with many Linux distributions and supports different container runtimes, including Docker and containerd. The NVIDIA Container Toolkit includes a container runtime library and other tools that configure containers to use NVIDIA GPUs. This setup allows seamless containerization and isolation of GPU-accelerated workloads.
Key Features
- The NVIDIA Container Toolkit includes the NVIDIA Container Runtime, Runtime Hook, Container Library and CLI, and the Toolkit CLI.
- These components automatically configure Linux containers to use NVIDIA GPUs, which is important for machine vision and machine learning applications.
- The toolkit supports many container runtimes, such as Docker, containerd, cri-o, and lxc.
- It provides utilities for configuring runtimes and generating Container Device Interface (CDI) specifications.
- The NVIDIA Container Runtime Hook injects GPU devices into containers before they start, so containers can access GPU resources.
- The NVIDIA Container Library and CLI offer APIs and command-line tools to help with GPU support in containers.
- The NVIDIA Container Runtime acts as a wrapper around native runtimes, adding GPU devices and mounts to container specifications.
- The Toolkit CLI helps users configure container runtimes and manage device specifications, making deployment easier.
Why Use for Machine Vision?
Machine vision systems need fast processing for tasks like image recognition and object detection. The NVIDIA Container Toolkit gives these systems access to GPU acceleration inside containers. This toolkit improves performance and efficiency for AI and ML workloads. The table below shows how the toolkit helps machine vision workflows:
| Feature/Capability | Description | Benefit to Machine Vision Workflows |
|---|---|---|
| GPU-accelerated Docker containers | Runs containers that use NVIDIA GPUs without manual setup | Makes deployment easy and ensures fast GPU access for AI and ML workloads |
| Container runtime library/utilities | Configures containers to use NVIDIA GPUs | Saves time and improves resource use |
| GPU Partitioning (vGPU and MIG) | Allows sharing GPU resources among different workloads | Increases efficiency for smaller machine vision tasks |
| Peer-to-peer GPU communication | Connects GPUs directly for faster data transfer | Speeds up training and inference in machine vision |
| Multi-node scaling with Horovod | Trains models across many GPUs and nodes | Reduces training time for large machine vision models |
The NVIDIA Container Toolkit helps users deploy, scale, and manage machine learning applications in Docker containers. It supports AI and ML workloads by making GPU acceleration simple and reliable.
Prerequisites for NVIDIA GPU
Hardware Requirements
Before setting up the NVIDIA Container Toolkit, users need to check if their system meets the hardware requirements. A compatible system should have an x86-64 or ARM64 architecture. Most modern desktops and servers use these architectures. The system must include a nvidia gpu with Volta architecture or newer. This means the gpu should have a compute capability of at least 7.0. Popular models like the NVIDIA A6000, A100, or H100 meet this requirement and offer at least 32 GB of memory. The CPU should have at least 4 cores to handle machine vision workloads efficiently. System memory should be at least 16 GB RAM, but more memory helps with larger datasets. Storage space should be at least 100 GB on an NVMe SSD for fast data access.
Tip: Apple M2 chips can run the toolkit, but performance drops due to emulation.
A table below lists some supported nvidia gpus for machine vision tasks:
| GPU Model | Architecture | Memory |
|---|---|---|
| NVIDIA A6000 | Ampere | 48 GB |
| NVIDIA A100 | Ampere | 40/80 GB |
| NVIDIA H100 | Hopper | 80 GB |
Software and Drivers
The right software and drivers are essential for running the NVIDIA Container Toolkit. The system must use recent nvidia drivers, with version 525.60.13 or higher on Linux. For Windows, version 527.41 or higher is needed. The operating system should be a recent Linux distribution, such as Ubuntu 20.04 or newer, or Windows 11 with WSL2. Docker must be installed, with version 19.03 or higher recommended. The toolkit works with Docker versions 18.09, 19.03, and 20.10 on amd64, ppc64le, and arm64 systems. The Linux kernel should be version 3.10 or newer.
The CUDA libraries do not need to be installed on the host, but the nvidia gpu must support CUDA version 12.0 or higher. The drivers must match the CUDA libraries used inside containers. This setup ensures that machine vision applications can access the gpu for accelerated processing.
Note: On some Linux distributions, Docker support may be limited. Users can try alternative container runtimes if needed.
Setup with Docker and GPU Support
Setting up a machine vision system with docker and gpu support involves several steps. Each step ensures that containers can access the gpu for accelerated workloads. The process includes installing nvidia drivers, docker, the nvidia container toolkit, and configuring docker for gpu access. This guide explains each step in detail.
Install NVIDIA Drivers
Proper nvidia drivers are essential for gpu access in containers. The following steps outline the installation process on a Linux system:
- Confirm that the system uses x86_64 architecture and a Linux kernel version above 3.10.
- Use the package manager for your Linux distribution to install nvidia drivers. This method is recommended for stability.
- Alternatively, download the official .run installer from the nvidia driver downloads page and execute it.
- Some distributions support installing drivers from the CUDA network repository. Follow the official guide for this method.
- Ensure the installed nvidia driver version is at least 418.81.07. This version supports the nvidia container runtime and docker with gpu support.
- Verify that the gpu is compatible (Kepler architecture or newer).
- After installing drivers, proceed to docker installation.
Tip: After installation, run
nvidia-smiin the terminal. This command checks if the gpu is recognized and the drivers are loaded.
Common issues during driver installation include the failure of nvidia-smi to communicate with the gpu. This often happens when the wrong driver version is installed. Users should check that the driver matches the gpu and cuda libraries. If errors occur, uninstall existing drivers and reinstall the correct version. The table below lists frequent problems and solutions:
| Common Issue | Description | Cause | Resolution |
|---|---|---|---|
| Driver and CUDA Toolkit Version Mismatch | Errors like "CUDA driver version is insufficient for CUDA runtime version" | Driver version incompatible with CUDA toolkit | Update or downgrade driver to match CUDA requirements |
| PATH and LD_LIBRARY_PATH Misconfiguration | Errors such as nvcc: command not found |
Environment variables not set correctly | Set PATH and LD_LIBRARY_PATH to CUDA toolkit directories |
| Kernel Module Failing to Load | nvidia-smi fails with communication error |
Kernel module not loaded or Secure Boot interference | Reinstall kernel module or adjust Secure Boot settings |
Note: XID errors may appear in virtualized environments. These errors indicate hardware or driver issues. Users should consult nvidia documentation for specific XID codes.
Install Docker
Docker provides the foundation for running containers with gpu support. The steps below guide users through the installation:
- Verify that the Linux distribution and gpu meet the requirements.
- Install Docker Community Edition (CE) version 18.09 or newer.
- Confirm that nvidia drivers are installed and meet the minimum version.
- After installing docker, test the service with
sudo systemctl status docker.
If docker installation fails, users can try these troubleshooting steps:
- Check if the docker service is running.
- Add the user to the docker group for proper permissions:
sudo usermod -aG docker $USER - Inspect docker daemon logs for errors:
sudo journalctl -u docker.service - Ensure enough CPU and memory are available.
- Reinstall docker if startup issues persist.
- Free disk space with:
docker system prune -a - Check network configurations and firewall rules.
- Verify volume mount paths and permissions.
Tip: On Windows, enable WSL2 and virtualization in BIOS before installing Docker Desktop.
Install NVIDIA Container Toolkit
The nvidia container toolkit enables docker with gpu support. The following steps explain how to install it:
- Add the nvidia repository by importing the GPG key and repository list.
- Optionally, enable experimental packages by editing the repository list.
- Update the package list using the package manager.
- Install the nvidia container toolkit package.
- Configure docker to use the nvidia container runtime:
sudo nvidia-ctk runtime configure --runtime=docker - Restart the docker daemon to apply changes.
Note: The system must have docker and nvidia drivers installed before this step.
Users may encounter errors during installation. A common error is ‘Conflicting values set for option Signed-By’ during apt update. This occurs when multiple repository files reference the same nvidia repository inconsistently. To fix this, remove conflicting files such as libnvidia-container.list or nvidia-docker.list from /etc/apt/sources.list.d/. Another issue is permission denied errors in SELinux environments. Adjust SELinux policies to grant necessary permissions.
Some users report the error ‘nvidia-container-cli: initialization error: nvml error: driver not loaded: unknown’ on Ubuntu 24.04. This usually means the nvidia driver is not loaded or is incompatible with the toolkit. Users should verify driver installation and ensure compatibility with the toolkit version.
Configure Docker with GPU Support
Configuring gpu access in docker ensures containers can use the gpu for machine vision workloads. The nvidia container runtime handles this process. The table below shows key configuration properties:
| Property | Description |
|---|---|
| capabilities | List of device capabilities, e.g., [gpu]. Must be set for deployment. |
| count | Number of gpus to reserve. Defaults to all if not set. |
| device_ids | List of gpu device IDs from the host. Mutually exclusive with count. |
| driver | Specifies the driver, e.g., ‘nvidia’. |
| options | Key-value pairs for driver-specific options. |
A sample Docker Compose file reserves one gpu for a container:
services:
test:
image: nvidia/cuda:12.9.0-base-ubuntu22.04
command: nvidia-smi
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
Run this configuration with:
docker compose up
To verify gpu support in docker, run:
docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
This command checks if the container can access the gpu.
For machine learning frameworks, pull gpu-enabled images such as TensorFlow with gpu support:
docker run --gpus all -it tensorflow/tensorflow:latest-gpu bash
Inside the container, use framework commands to confirm gpu access.
Tip: Always use official pre-built gpu-enabled images. Monitor gpu usage with
nvidia-smiinside containers. Isolate gpu resources with the--gpusflag. Match cuda libraries in containers with host drivers for best results.
Monitoring tools such as DCGM Exporter, Prometheus, and Grafana help track gpu utilization. Deploy these tools in a docker compose stack for real-time monitoring. Avoid installing gpu drivers inside containers. The nvidia container runtime exposes the necessary drivers for gpu access.
Configuring gpu access in docker with the nvidia container runtime allows machine vision workloads to run efficiently. Proper installation and configuration ensure reliable gpu support in docker for all containers.
Running Machine Learning Applications

NVIDIA Container Toolkit Machine Vision System
The nvidla container toolkit machine vision system gives developers a way to run containerized applications that need gpu access. Many industries use this system for tasks like object detection, video analytics, and natural language processing. The toolkit supports deep learning frameworks such as tensorflow and pytorch. These frameworks help with training large models and running inference at scale. The nvidia container runtime manages gpu access for each container, making it easy to deploy ai and ml workloads.
A table below shows popular machine learning application areas that benefit from gpu acceleration:
| Application Area | Popularity Indicator (Approximate) |
|---|---|
| Natural Language Processing | High (19 mentions) |
| Language Modeling | High (13 mentions) |
| Video Analytics | High (12 mentions) |
| Drug Discovery | High (11 mentions) |
| High Performance Computing | Moderate (10 mentions) |
| Object Detection | Moderate (10 mentions) |
| Recommendation Systems | Moderate (9 mentions) |
| Question Answering | Moderate (8 mentions) |
| Natural Language Understanding | Moderate (7 mentions) |
| Speech to Text | Moderate (7 mentions) |
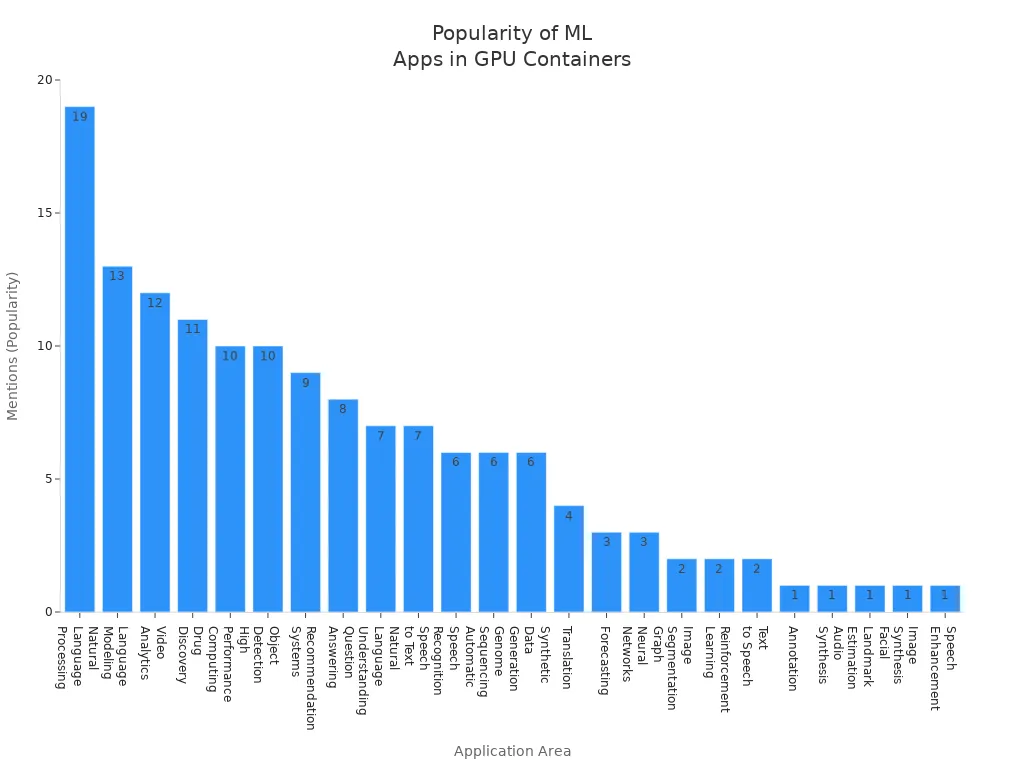
Popular containerized applications include tensorflow serving, pytorch, Frigate, DeepStack, and Stable Diffusion. The nvidia container runtime ensures these containers use the gpu efficiently.
Example: Docker with GPU Support
Developers can use docker with gpu support to run a sample machine vision application. The steps below outline the process:
- Install nvidia drivers on the host system.
- Install docker and add the user to the docker group.
- Install the nvidia container toolkit.
- Verify gpu access inside a container with:
docker run --gpus all nvidia/cuda:11.0-base nvidia-smi - Run tensorflow or pytorch containers with gpu support:
docker run --gpus all tensorflow/tensorflow:latest-gpu - Use nvidia gpu cloud to pull optimized images for tensorflow and pytorch.
- Configure the nvidia container runtime for default gpu access.
This setup allows efficient resource allocation and isolation for multiple workloads.
Security Considerations
Running gpu-accelerated containers introduces security risks. Attackers may exploit vulnerabilities like CVE-2025-23359 to gain unauthorized access. Data theft, operational disruption, and privilege escalation can occur. The nvidia container runtime and nvidla container toolkit machine vision system must stay updated with security patches. Administrators should restrict docker API access and avoid unnecessary root privileges. Disabling nonessential toolkit features reduces the attack surface. Using VM-level containment and hardware GPU slicing helps isolate workloads. Monitoring tools and strong access controls protect against threats. Regularly applying patches and using hardened base images improve security for all containers.
Best Practices and Next Steps
Optimize for Machine Vision
Machine vision projects need careful tuning for the best results. Developers should select a container image that matches the required machine learning framework. They can use images from trusted sources like the nvidia NGC catalog. Each container should only include the libraries and tools needed for the task. This approach keeps the container lightweight and secure. Developers should assign the right number of gpu resources to each container. They can use the --gpus flag in Docker to control gpu usage. Monitoring tools help track gpu performance and spot bottlenecks.
Tip: Use a dedicated gpu for critical machine vision tasks to avoid resource conflicts.
Maintain and Update
Regular updates keep the system secure and efficient. Developers should update the nvidia drivers and the container toolkit when new versions become available. They should also update the container images to include the latest security patches. Automated scripts can help check for updates and apply them. Testing updates in a staging environment prevents problems in production. Keeping documentation for each container setup helps teams manage changes over time.
A simple update check script example:
docker pull nvidia/cuda:latest
sudo apt update && sudo apt upgrade nvidia-driver
Resources
Many resources help beginners learn more about gpu-accelerated containers. The nvidia NGC catalog offers pre-built container images for deep learning and machine vision. The official Docker documentation explains how to manage containers and gpu support. Community forums and GitHub repositories provide troubleshooting tips and sample projects.
| Resource | Description |
|---|---|
| NVIDIA NGC Catalog | Pre-built container images and models |
| Docker Documentation | Guides for container management |
| NVIDIA Developer Forums | Community support and troubleshooting |
| GitHub | Open-source container projects |
Exploring these resources helps users improve their machine vision systems and stay updated with new tools.
The NVIDIA Container Toolkit helps users run machine vision applications with GPU acceleration. Beginners often follow these steps:
- Restart Docker to apply changes.
- Log in to Docker Hub.
- Pull a CUDA Docker image.
- Run the image to check GPU access.
- Use Docker features to scale and test models.
The NGC catalog offers many GPU-optimized containers, pre-trained models, and frameworks for deep learning and computer vision. With the right setup, anyone can build powerful AI solutions and explore new ideas in machine vision.
FAQ
What operating systems support the NVIDIA Container Toolkit?
Linux distributions like Ubuntu, CentOS, and Debian support the toolkit. Windows users can use it through WSL2. Most users choose Ubuntu for the best compatibility and community support.
Can users run multiple containers with GPU access at the same time?
Yes. The toolkit allows several containers to share one or more GPUs. Users can set the number of GPUs for each container using the --gpus flag in Docker.
Does the toolkit work with all NVIDIA GPUs?
No. The toolkit supports GPUs with Volta architecture or newer. Older GPUs may not work. Users should check the GPU model and compute capability before starting.
How can users check if a container uses the GPU?
Users can run this command inside the container:
nvidia-smi
If the GPU appears in the output, the container has GPU access.
See Also
A Deep Dive Into SDKs For Machine Vision Technology
Top Libraries Used In Image Processing For Machine Vision
Complete Overview Of Machine Vision Applications In Automation
Neural Network Platforms Transforming The Future Of Machine Vision









