Model distillation drives the success of the modern model distillation machine vision system by delivering compact models that perform tasks quickly and accurately. Engineers use model distillation to shrink large neural networks, making them suitable for mobile devices and embedded systems. A model distillation machine vision system can process images in real time, reducing memory use and latency. Most distilled models keep about 90–97% of the original model’s accuracy, but they run much faster and require less storage. This balance between speed and accuracy makes model distillation essential for any application that demands both high performance and strong efficiency.
Key Takeaways
- Model distillation creates smaller, faster machine vision models that keep most of the original accuracy, making them ideal for devices with limited resources.
- The teacher-student framework transfers knowledge from large models to smaller ones, enabling efficient real-time image processing with less memory and power use.
- Distilled models support edge deployment on smartphones, cameras, and IoT devices by balancing speed, accuracy, and hardware constraints.
- Combining model distillation with techniques like pruning and quantization further reduces model size and energy use without sacrificing performance.
- Model distillation improves real-world machine vision tasks by enabling faster, reliable systems while addressing challenges like bias and overfitting through careful design.
What Is Model Distillation?
Core Concept
Model distillation is a machine learning technique that helps create smaller, faster models without losing much accuracy. In deep learning, large models often perform well but require a lot of resources. Model distillation solves this by transferring knowledge from a large model to a smaller one. Researchers have found several core ideas that make model distillation effective:
- The teacher-student structure forms the foundation, where a large, pre-trained model (the teacher) guides a smaller model (the student).
- Soft targets, which are the teacher’s output probabilities, give more information than simple labels and help the student learn better.
- Different knowledge distillation methods exist, such as response-based (copying outputs), feature-based (learning from internal features), and relation-based (understanding relationships between data points).
- Distillation can happen offline, online, or even with the model learning from itself.
- Special loss functions help the student model match the teacher’s behavior.
These ideas have strong support from research and practical use in deep learning and machine learning.
Teacher and Student Models
In model distillation, the teacher model is usually large and accurate but slow. The student model is smaller and faster. The student learns by copying the teacher’s behavior. Studies show that student models often run much faster and use less memory. However, they may not always match the teacher’s accuracy, especially on hard tasks. Student models can also inherit the teacher’s mistakes or biases. Still, student models offer many benefits:
- Smaller size and lower computational cost
- Faster inference, which is important for real-time applications
- Better generalization, as they focus on key features and avoid overfitting
Recent research shows that advanced knowledge distillation methods can help student models reach or even surpass the teacher’s performance in some cases.
Knowledge Transfer
Knowledge transfer is the heart of model distillation. It measures how well the student model learns from the teacher. Researchers use special metrics to check this process. The table below shows some ways to measure knowledge transfer in model distillation:
| Metric Name | Purpose | Methodology | Key Findings |
|---|---|---|---|
| Response Similarity Evaluation (RSE) | Measures how closely student models imitate teacher models | Compares outputs of student and teacher models across style, logic, and content; uses a scoring system | Higher scores mean better imitation; base models show higher distillation; fine-tuning can reduce negative effects |
| Identity Consistency Evaluation (ICE) | Detects inconsistencies in student model’s identity cognition | Uses adversarial prompts to reveal identity-related inconsistencies | Shows that student models can inherit unwanted traits or biases from teachers |
This approach helps researchers improve knowledge distillation methods and build better machine vision systems.
Model Distillation in Computer Vision

Efficiency Gains
Model distillation helps create smaller and faster models for computer vision tasks. In image classification, large teacher models often achieve high performance but need a lot of resources. By using model distillation, engineers can train student models that keep most of the teacher’s accuracy while using less memory and power. This process allows a model distillation machine vision system to run on devices with limited hardware.
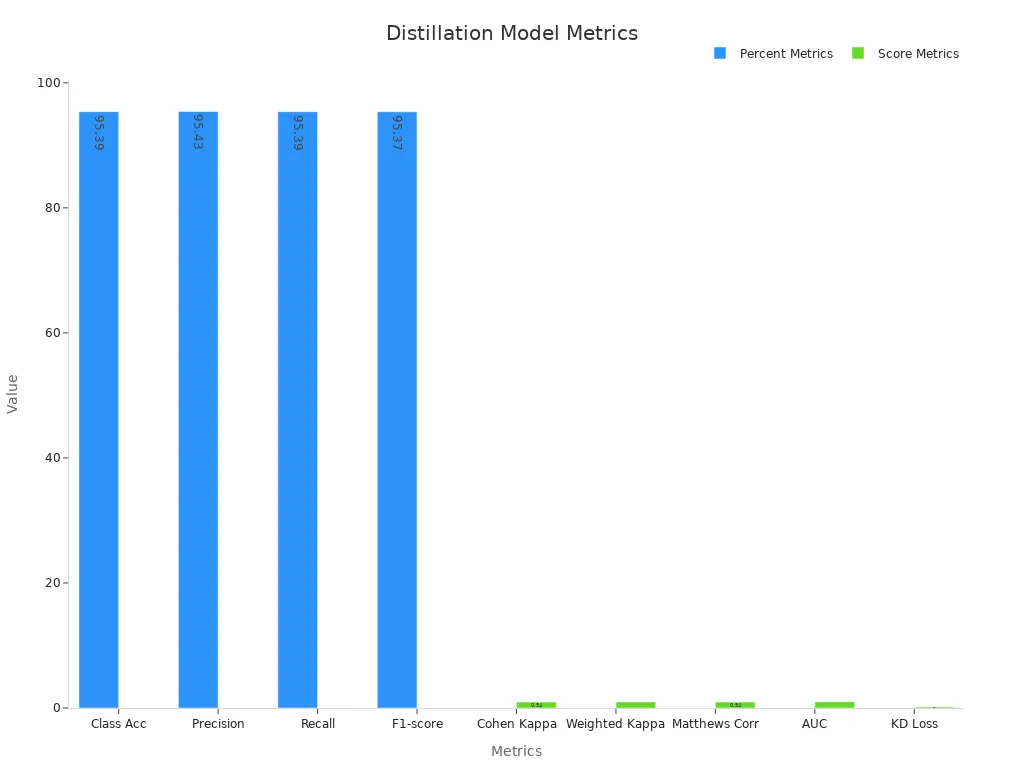
A case study shows how a lightweight EfficientNet-B0 student model, distilled from a transformer-based teacher, achieves strong results:
| Metric | Value |
|---|---|
| Classification Accuracy | 95.39% |
| Precision | 95.43% |
| Recall | 95.39% |
| F1-score | 95.37% |
| Cohen’s Kappa Score | 0.94 |
| Weighted Kappa Score | 0.97 |
| Matthews Correlation Coefficient | 0.94 |
| AUC | 0.99 |
| Knowledge Distillation Loss | 0.17 |
| Computational Cost (FLOPs) | 0.38 G |
This table shows that the student model keeps high accuracy and other performance metrics while cutting computational cost. The chart below also compares these metrics visually:
Distilled models often have fewer parameters and run faster than traditional models. For example, a distilled model can be 40% smaller and 60% faster, while keeping 97% of the original accuracy. This makes model distillation a key tool for building efficient computer vision systems.
Edge Deployment
Many real-world applications need computer vision models to work on edge devices, such as smartphones, cameras, and IoT sensors. These devices have limited memory and processing power. Model distillation allows engineers to deploy high-performing models on these devices without losing much accuracy.
Some important points about edge deployment include:
- Student models from model distillation use fewer resources, making them suitable for embedded systems.
- The AutoDistill pipeline combines model distillation with other techniques to create models that meet strict hardware limits.
- Engineers measure latency, memory use, and computational cost to pick the best models for edge deployment.
- Smaller models from model distillation machine vision system can match the performance of larger teacher models while fitting within device constraints.
| Aspect | Description / Quantitative Data |
|---|---|
| Model Compression Techniques | Includes pruning, quantization, tensor decomposition, and distillation to reduce model size and resource usage. |
| Knowledge Distillation (KD) | Transfers knowledge from large teacher to smaller student model with minimal performance loss. |
| AutoDistill Pipeline | Combines Bayesian NAS, distillation, and hardware-aware objectives to produce smaller models meeting constraints. |
| Flash Distillation Efficiency | Uses ~5% of full training steps to predict final accuracy, showing high correlation with full distillation results. |
| Hardware Metrics Evaluated | Latency, FLOPs, memory usage measured during iterative search to guide architecture selection. |
| Final Outcome | Smaller models approximating teacher performance while satisfying hardware constraints for edge deployment. |
| Integrated Frameworks & Benchmarks | NAS-Bench-101/201/301, APQ, DARTS, AWQ, AutoDistill used to systematically evaluate and optimize models. |
Model distillation machine vision system technology supports deployment in production environments where resources are limited. This makes it possible to use advanced computer vision in places where large models would not fit.
Real-Time Performance
Real-time applications, such as video analysis and autonomous vehicles, need fast and accurate computer vision. Model distillation helps meet these needs by creating models that process images quickly without a big drop in performance.
Recent research shows that distilled models can reach optimal performance in fewer training steps and require less time per step. For example, in X-ray image classification, a distilled Resnetv2_50x1 student model matches the F1 score of a much larger teacher model but trains faster and uses less memory. This means a model distillation machine vision system can deliver results with low latency, which is critical for real-time tasks.
| Aspect | Evidence Summary | Impact on Real-Time Performance Metrics |
|---|---|---|
| Performance Trade-offs | Distilled models show efficiency gains but degrade on complex reasoning tasks (Baek and Tegmark, 2025). | Efficiency improves real-time deployment; reasoning degradation may reduce accuracy in time-sensitive tasks. |
| Model Size and Scaling | Larger distilled models develop more structured representations, correlating with better distillation outcomes. | Larger distilled models better maintain real-time performance, balancing size and capability. |
| Quantification Frameworks | Lee et al. (2025) introduced Response Similarity Evaluation and Identity Consistency Evaluation to measure distillation quality. | Enables systematic assessment of real-time behavioral similarity between teacher and student models. |
| Branch-Merge Distillation | New two-phase method improves accuracy and efficiency, achieving near-equal performance to larger models on benchmarks. | Enhances real-time inference by reducing computational cost while maintaining accuracy. |
| Domain-Specific Distillation | Speculative decoding techniques improve latency and accuracy trade-offs in domain-specific models (Hong et al., 2025). | Addresses real-time inference speed and accuracy in specialized applications. |
| Edge and Mobile Applications | Distilled models enable efficient AI on resource-constrained devices (smartphones, IoT, autonomous systems). | Reduced latency, power consumption, and improved responsiveness critical for real-time applications on edge devices. |
Tip: Model distillation not only speeds up inference but also helps maintain high accuracy, which is vital for safety and reliability in real-time computer vision systems.
How It Works

Distillation Process
The model distillation process follows a careful sequence to create stable and accurate student models. Researchers use a hypothesis testing framework based on the central limit theorem to select the best student models. They measure stability by checking how often unique student model structures appear over 100 repetitions. Entropy metrics summarize this consistency. Fidelity is checked by comparing the prediction accuracy or mean squared error between the student and teacher models. The process includes repeated dataset splits, such as 80% for training and 20% for testing, and runs 100 times to test performance on different datasets. Sensitivity analyses on hyperparameters, like the number of candidate models and tree depth, confirm the robustness of the distillation algorithm. Theoretical analysis models the testing as a Markov process, which helps set bounds on stabilization difficulty as model complexity grows. Empirical results show that stabilization improves both stability and fidelity, especially on complex datasets. The model distillation process is reproducible and uses multiple testing corrections to ensure reliable results.
- Use hypothesis testing to select stable student models.
- Measure stability and summarize with entropy.
- Compare student and teacher accuracy for fidelity.
- Repeat dataset splits and model training 100 times.
- Analyze sensitivity to hyperparameters.
- Model the process as a Markov process.
- Confirm improvements in stability and fidelity.
- Ensure reproducibility and reliability.
Types of Distillation
Model distillation supports several types, each with unique strengths. Researchers have compared nine different student architectures distilled from a Transformer teacher model. They used alignment techniques like matrix mixing, QKV copying, and hidden-state alignment. The xLSTM model achieved the highest scores on downstream tasks. Combining initialization strategies with alignment methods improved knowledge transfer. All student models trained on a 1 billion token web text dataset. Evaluation covered many downstream tasks. Some models, such as Mamba, did not benefit as much due to architectural differences. These findings show that the effectiveness of each distillation algorithm depends on the student model’s design and training conditions.
- Matrix mixing aligns attention matrices.
- QKV copying transfers key projections.
- Hidden-state alignment matches internal representations.
- Progressive alignment and initialization boost performance.
- Model architecture and dataset size affect results.
Loss Functions
Loss functions guide the model distillation process and impact student model performance. Researchers use several loss functions to compare student and teacher outputs. The table below summarizes their effects:
| Metric / Loss Function | Description | Impact on Distilled Model Performance |
|---|---|---|
| Maximum Mean Discrepancy (MMD) | Measures distance between feature distributions. | Low MMD means better feature preservation and accuracy. |
| Wasserstein Distance | Calculates cost to align distributions. | Low values support robust training. |
| Kullback–Leibler (KL) Divergence | Measures difference between probability distributions. | Helps maintain classification accuracy. |
| Jensen–Shannon (JS) Divergence | Balanced measure of output similarity. | Aids in output fidelity. |
| Iterative Loss Function | Compares performance on distilled vs. full data. | Improves generalization and model accuracy. |
| Category Distillation Loss | Based on Spearman correlation of outputs. | Enhances knowledge transfer and accuracy. |
| Sample Distillation Loss | Focuses on batch consistency. | Reduces negative impact of uncertain predictions. |
| Adaptive Temperature Adjustment | Adjusts temperature during training. | Improves alignment and final performance. |
Advanced loss functions, such as Category Distillation Loss and Sample Distillation Loss, use Spearman correlation to improve knowledge transfer. Adaptive temperature adjustment further tunes the process, helping the student model match the teacher more closely. These techniques help the model distillation process achieve strong generalization and accuracy.
Applications and Challenges
Machine Vision System Use Cases
Model distillation helps machine vision systems work better in real-world settings. In one study, researchers used a medium-small model pair to improve performance in tasks like detecting false information in images. The smaller model gave correct answers and spotted unverifiable claims more accurately than larger models, which sometimes made mistakes. These results show that model distillation can help systems avoid errors and work well in practical situations, such as checking facts in images or videos.
Benefits and Limitations
Model compression brings many benefits to machine vision. Smaller models run faster and use less memory, which means devices like smartphones and sensors can process images quickly. Metrics like the Performance-Cost Ratio (PCR) show that these models balance speed, accuracy, and cost. For example, DistilBERT keeps about 97% of BERT’s accuracy but uses 40% fewer parameters. This makes real-time applications possible on devices with limited resources.
Model compression also has some challenges. Sometimes, the student model does not match the teacher’s performance. The process can be sensitive to settings like learning rates. Some tasks need special changes, which can take extra time and effort. The table below shows more details about these challenges:
| Distillation Method(s) | Performance (Accuracy) | Explainability | Challenges / Limitations |
|---|---|---|---|
| Multitask Training | Strong student model performance | Robust explainability | Needs more evaluation for explanation ability |
| Counterfactual Training | Improves faithfulness and consistency | Enhances explanation quality | Automated checks may lack reliability; needs human review |
| Critique-Revision Prompting | Aims to improve training data quality | Improves explanation quality | Effectiveness in distillation not fully explored |
| Combination Methods | No improvement in both answering and explanation | Trade-off observed | Shows trade-offs and limits in combining methods |
| General Challenges | Varies by model setup | Hard to compare across studies | Differences in models and training make generalization difficult |
Note: Model compression can also lead to overfitting, inherited biases, and ethical concerns. Careful monitoring and expert guidance help reduce these risks.
Combining with Other Techniques
Engineers often combine model compression with other methods to get the best results. Pruning and quantization work well with model distillation to shrink models further and save energy. For example, when researchers used pruning and distillation together on BERT, they cut energy use by over 32% while keeping high accuracy. The table below shows how different techniques affect performance and energy use:
| Model | Compression Techniques | Energy Consumption Reduction (%) | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) | ROC AUC (%) |
|---|---|---|---|---|---|---|---|
| BERT | Pruning + Distillation | 32.10 | 95.90 | 95.90 | 95.90 | 95.90 | 98.87 |
| DistilBERT | Pruning | 6.71 | 95.87 | 95.87 | 95.87 | 95.87 | 99.06 |
| ELECTRA | Pruning + Distillation | 23.93 | 95.92 | 95.92 | 95.92 | 95.92 | 99.30 |
| ALBERT | Quantization (no distillation) | 7.12 | 65.44 | 67.82 | 65.44 | 63.46 | 72.31 |
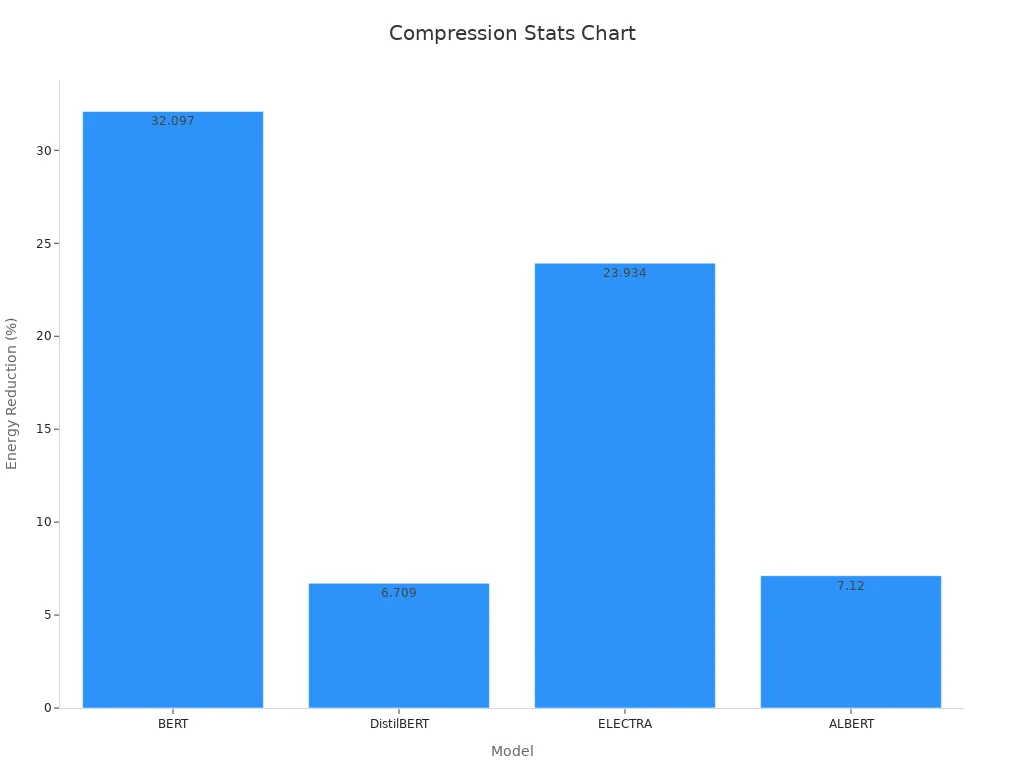
These results show that combining model compression techniques can make machine vision systems more efficient and ready for use in many settings.
Model distillation gives machine vision systems advanced abilities on devices with limited resources. Empirical studies show that a MobileNetV2 student model distilled from a Vision Transformer teacher reached 72% accuracy, much higher than the 63% from training alone. This process helps smaller models run faster and stay accurate. Engineers can balance speed, accuracy, and efficiency with this method.
Those interested in model distillation can:
- Explore Hugging Face Transformers documentation
- Test distillation on custom datasets
- Study new research on model compression techniques
FAQ
What is the main benefit of model distillation for machine vision?
Model distillation creates smaller models that run faster and use less memory. These models work well on devices with limited resources, such as smartphones or cameras.
Can model distillation reduce accuracy in computer vision tasks?
Sometimes, student models lose a small amount of accuracy compared to teacher models. However, most distilled models keep about 90–97% of the original accuracy.
Where do engineers use distilled models in real life?
Engineers use distilled models in self-driving cars, security cameras, and mobile apps. These models help devices process images quickly and efficiently.
How does model distillation compare to other compression methods?
Model distillation often works best when combined with pruning or quantization. This combination helps models become even smaller and faster while keeping strong performance.









