
An image segmentation machine vision system lets you divide images into meaningful regions, helping you detect and analyze objects with high precision. You use segmentation to make computer vision tasks more accurate and reliable.
- Segmentation gives you pixel-level classification and precise object boundaries, unlike simple bounding boxes.
- You can separate overlapping objects and understand both objects and backgrounds using semantic, instance, and panoptic segmentation.
- Deep learning models improve detection by learning detailed patterns in images.
Machine vision systems use segmentation for real-time image processing, making object detection and analysis more effective.
Key Takeaways
- Image segmentation divides images into precise regions, helping machines detect and analyze objects with clear boundaries instead of rough boxes.
- Choose the right system type—1D for simple line data, 2D for flat images, or 3D for depth and shape—to match your specific application needs.
- Semantic, instance, and panoptic segmentation offer different levels of detail; pick the one that fits your task, from general labeling to detailed object separation.
- Deep learning models like U-Net and Mask R-CNN improve segmentation accuracy and speed, making real-time analysis and complex scenes easier to handle.
- Image segmentation powers many fields such as healthcare, autonomous vehicles, agriculture, and manufacturing by enabling precise detection, quality control, and faster decisions.
Image Segmentation Machine Vision System
What It Is
You use an image segmentation machine vision system to divide images into separate regions. Each region represents a different object or part of the scene. This system helps you find, inspect, and analyze objects in images with high accuracy. The main goal is to make computer vision tasks like object detection and measurement more precise. When you use segmentation, you can see the exact shape and boundary of each object, not just a rough outline.
A typical image segmentation machine vision system includes several important parts. Here is a table that shows the main components and what they do:
| Component | Description |
|---|---|
| Image Acquisition | Captures image data using cameras, sensors, and lighting under controlled conditions. |
| Computing Platform | Processes image data quickly and reliably, often using industrial computers. |
| Processing Software | Analyzes images to perform segmentation, recognition, measurement, and decision-making. |
| Control Unit | Communicates with other equipment and acts on the results of the image analysis. |
You need all these parts to work together for the system to perform image segmentation tasks in real time.
How It Works
When you use a machine vision system for image segmentation, you start by capturing an image with a camera or sensor. The system uses special lighting to make sure the image is clear. The computer then runs processing software that looks at the image and divides it into regions. Each region might show a different object, a part of an object, or the background.
Segmentation lets you do more than just find objects. You can measure their size, check for defects, and even count how many objects appear in the image. For example, in a factory, you can use segmentation to spot broken parts on a conveyor belt. In agriculture, you can separate ripe fruit from leaves. The system gives you pixel-level details, so you can make better decisions based on what you see.
You use segmentation to improve object detection, inspection, and analysis. The system can handle overlapping objects, complex backgrounds, and different lighting conditions. This makes machine vision systems very powerful for many computer vision applications.
Tip: Segmentation helps you find not only where an object is, but also its exact shape and size. This is much more detailed than just drawing a box around it.
System Types (1D, 2D, 3D)
You can choose from different types of image segmentation machine vision systems, depending on your needs. The three main types are 1D, 2D, and 3D systems. Each type uses different hardware and software, and each works best for certain tasks.
| System Type | Hardware Requirements | Software Requirements | Key Differences |
|---|---|---|---|
| 1D | Linear sensors, basic cameras | Simple image processing software | Works with lines of data; best for barcode reading and simple inspections |
| 2D | Standard cameras, lenses | Intermediate software for flat images | Captures flat images; good for surface inspection and defect detection |
| 3D | 3D sensors, powerful computers | Advanced software, often with AI | Captures depth; best for precise measurements and robotic guidance |
- 1D systems work with single lines of image data. You use them for simple tasks like reading barcodes or checking for missing parts on a line.
- 2D systems capture flat images. You use these for most surface inspections, such as finding scratches or stains on products.
- 3D systems use special sensors to capture depth. You use them when you need to measure the height or shape of objects, or when you need to guide robots in three-dimensional space.
You should pick the system type that matches your application. For example, if you need to check the surface of a flat object, a 2D system works well. If you need to measure the volume of a part or guide a robot arm, a 3D system gives you the detail you need.
Machine vision systems with image segmentation play a key role in many industries. They help you solve complex computer vision problems, from object detection to quality control. By choosing the right system type and using segmentation, you can make your detection and analysis tasks faster and more accurate.
Image Segmentation Types

Semantic Segmentation
You use semantic segmentation to label every pixel in an image with a class name. This type of segmentation does not separate different objects of the same class. For example, if you have three cars in an image, semantic segmentation marks all car pixels as "car" without telling you which pixels belong to each car.
- Semantic segmentation works well for labeling regions like sky, grass, or road.
- You often use it in autonomous driving, medical imaging, and agriculture.
- Early methods used sliding windows, but these lost spatial details.
- Fully convolutional networks (FCNs) improved this by predicting all pixels at once.
- U-Net and similar encoder-decoder models help you get finer segmentation maps.
- Newer models, like vision transformers, use global attention to improve segmentation quality.
Semantic segmentation gives you a broad understanding of the scene. You can see where each class appears in your images, but you cannot tell objects apart within the same class.
Instance Segmentation
Instance segmentation takes things further. You not only label each pixel with a class, but you also separate each object instance. If you have three cars, instance segmentation gives each car its own label and mask. This helps you find and count each object, even if they overlap.
| Criteria | Instance Segmentation | Semantic Segmentation |
|---|---|---|
| Definition | Identifies and segments individual object instances at the pixel level. | Classifies each pixel into categories without distinguishing between instances. |
| Objective | Provides detailed segmentation by differentiating between instances of the same class. | Offers a broad understanding by segmenting pixels into semantic categories without instance detail. |
| Detail Level | Granular, distinguishing individual object instances within the same category. | Broader, grouping pixels into general object categories. |
| Differentiation Ability | Can assign unique labels to different instances of the same category. | Cannot differentiate between instances; all pixels of the same class are grouped together. |
| Approach | Combines object detection and segmentation techniques to produce instance masks. | Focuses on pixel-wise classification to generate semantic segmentation maps. |
| Output | Produces pixel-level masks for each object instance, enabling precise localization. | Outputs a segmentation map labeling pixels by category without instance separation. |
| Complexity | More computationally intensive due to instance-level differentiation. | Less complex, focusing on category-level pixel classification. |
You use instance segmentation when you need to know exactly how many objects are present and where each one is. This is important for tasks like counting products or tracking objects in images.
Panoptic Segmentation
Panoptic segmentation combines the strengths of semantic and instance segmentation. You label every pixel in the image with both a semantic class and an instance ID. This means you can identify both "stuff" (like sky or road) and "things" (like cars or people) in one unified output.
- Panoptic segmentation gives you a complete view of the scene.
- You can see both the overall context and each object instance.
- This approach helps you with tasks that need full scene understanding, such as urban planning or augmented reality.
- Panoptic segmentation uses a special metric called Panoptic Quality (PQ) to measure both segmentation and recognition quality.
Note: Panoptic segmentation does not allow overlapping segments. Each pixel belongs to one class and one instance only.
Key Differences
You can compare these three segmentation types by looking at what they offer:
| Aspect | Semantic Segmentation | Instance Segmentation | Panoptic Segmentation |
|---|---|---|---|
| Definition | Assigns a class label to each pixel; groups all objects of the same class as one entity. | Assigns class labels and distinguishes individual object instances. | Combines semantic and instance segmentation by labeling each pixel with both class and instance ID. |
| Instance Identification | No | Yes | Yes |
| Overlapping Segments | No | Yes | No |
| Evaluation Metrics | IoU, pixel accuracy | Average Precision (AP) | Panoptic Quality (PQ) |
| Main Use | General class-level segmentation | Differentiating individual objects | Unified scene understanding |
You should choose the segmentation type that fits your application. If you want to know where each class appears, use semantic segmentation. If you need to count and separate objects, use instance segmentation. For the most complete scene understanding, panoptic segmentation gives you both context and detail.
Image Segmentation Techniques
Traditional Methods
You can start with traditional image segmentation techniques when you want to divide images into regions. These methods use simple rules and mathematical operations. You often see three main types: thresholding, region-based, and edge-based segmentation.
- Thresholding: You set a value, and the system separates pixels above or below this value. This works well when the objects in your image have clear differences in brightness or color. For example, you can use thresholding to separate black text from a white background.
- Region-based segmentation: You group pixels that have similar properties, such as color or intensity. The system starts from a seed point and grows the region by adding neighboring pixels that match the criteria. This helps you find objects that have smooth and connected areas.
- Edge-based segmentation: You look for sudden changes in pixel values. The system detects edges, which are the boundaries between different regions. You can use this to find the outlines of objects in your images.
Traditional image segmentation techniques work best when your images are simple and have clear differences between objects and backgrounds. However, these methods struggle with complex images, noise, or overlapping objects. You may find that they do not always give you precise boundaries or handle different lighting conditions well.
Tip: Traditional segmentation is fast and easy to use, but it may not work well for detailed or noisy images.
Deep Learning Methods
You can use deep learning models to improve segmentation accuracy and speed. These models learn patterns from large sets of labeled images. They can handle complex scenes and provide pixel-level precision. Some of the most popular image segmentation models include convolutional neural networks (CNNs), U-Net, and Mask R-CNNs.
- CNNs: You use CNNs to extract features from images. They help you recognize shapes, textures, and patterns. CNNs form the backbone of many modern segmentation models.
- U-Net: This model uses a U-shaped architecture with skip connections. You get precise localization and detailed segmentation, even with limited training data. U-Net works well for semantic segmentation in medical images, where you need to find exact boundaries. Studies show that U-Net outperforms traditional methods in both accuracy and speed. For example, U-Net achieved Intersection Over Union (IOU) scores of 92% on the PhC-U373 dataset and 77.5% on the DIC-HeLa dataset. Its fully convolutional design lets you process large images quickly, making it ideal for real-time machine vision systems.
- Mask R-CNNs: You use Mask R-CNNs for instance segmentation. This model detects objects and creates masks for each one. Mask R-CNNs help you separate overlapping objects and count them. They combine object detection and segmentation, giving you both bounding boxes and pixel-level masks.
Deep learning methods have changed how you approach image segmentation. You can now solve problems that traditional techniques cannot handle. These models adapt to different types of images and work well in noisy or cluttered scenes. You get better results for tasks like semantic segmentation, instance segmentation, and panoptic segmentation.
Note: Deep learning models need labeled data for training, but they give you much higher accuracy and flexibility in machine vision systems.
Advanced Approaches
You can explore advanced image segmentation techniques to make your machine vision systems even more adaptable. One exciting development is zero-shot segmentation models, such as the Segment Anything Model (SAM). These models use prompts or instructions to guide segmentation, even on new types of images.
- Zero-shot models (e.g., SAM): You do not need to retrain these models for every new task. SAM can generalize to new data types, such as medical images, without extra labeled data. This makes your machine vision systems more flexible and easier to deploy in different environments. While SAM may not always reach the highest accuracy in specialized tasks, it gives you a strong starting point for further improvements.
Advanced segmentation approaches help you handle new challenges in computer vision. You can use them to build machine vision systems that work across many industries, from healthcare to robotics. These models reduce the need for manual labeling and speed up the development of new applications.
Callout: Advanced image segmentation techniques let you adapt quickly to new problems and data types. You can save time and resources while keeping high performance.
Training and Evaluation
Datasets
You need high-quality datasets to train and test your image segmentation machine vision system. These datasets give you labeled images that help your machine learn to separate different regions and objects. Some datasets focus on semantic segmentation, while others support object recognition and instance segmentation. Here is a table showing some of the most common datasets:
| Dataset | Description | Scale and Annotations | Common Usage |
|---|---|---|---|
| COCO (Common Objects in Context) | Large-scale dataset for object detection, segmentation, and captioning | Contains numerous images with detailed segmentation masks across many object categories | Widely used benchmark for segmentation and detection tasks |
| ADE20K | Semantic segmentation dataset with pixel-level annotations | Over 20,000 images annotated with 150 semantic categories including objects and stuff (e.g., sky, road) | Standard dataset for semantic segmentation research |
| ImageNet | Primarily classification and object detection dataset | Over 14 million images with image-level labels and bounding boxes for some objects | Used mainly for classification and detection, less for segmentation |
| CIFAR-100 and MNIST | Smaller datasets focused on classification | Contain labeled images but lack detailed segmentation annotations | Mainly used for classification tasks, not segmentation |
You should pick a dataset that matches your machine vision task. For example, if you want to train a system for semantic segmentation, ADE20K works well.
Metrics
You use different metrics to measure how well your segmentation model works. These metrics help you see if your machine vision system can find the right regions and boundaries in images. Here is a table with some standard metrics:
| Metric | Formula/Definition | Interpretation and Use Case | ||
|---|---|---|---|---|
| Intersection over Union (IoU) | IoU = Area of Overlap / Area of Union | Measures overlap between predicted and ground truth segments; ranges 0-1; critical for precise boundary tasks like medical imaging and autonomous driving. | ||
| Dice Coefficient | Dice = 2 × Area of Overlap / Total Pixels in Both Segmentations | Measures similarity between predicted and ground truth; ranges 0-1; widely used in medical imaging for tumor and organ segmentation. | ||
| Precision | Precision = True Positives / (True Positives + False Positives) | Proportion of correctly predicted positive pixels; indicates false positive rate; balances over-segmentation. | ||
| Recall | Recall = True Positives / (True Positives + False Negatives) | Proportion of actual positive pixels correctly identified; indicates false negative rate; balances under-segmentation. | ||
| F1 Score | F1 = 2 × (Precision × Recall) / (Precision + Recall) | Harmonic mean of precision and recall; balances false positives and negatives; useful for imbalanced classes. | ||
| Mean Absolute Error (MAE) | MAE = (1/n) × Σ | Predicted – Actual | Measures average magnitude of prediction errors; useful for understanding absolute differences between prediction and ground truth. | |
| Hausdorff Distance | d_H(A, B) = max(h(A, B), h(B, A)) | Measures worst-case boundary discrepancy; important for strict boundary adherence in segmentation. | ||
| Pixel Accuracy | Pixel Accuracy = Number of Correct Pixels / Total Number of Pixels | Measures overall pixel-wise correctness; simple but can be misleading with imbalanced classes. |
Tip: You should use more than one metric to get a full picture of your segmentation model’s performance.
Challenges
You may face several challenges when training and evaluating image segmentation systems. First, labeling images for segmentation takes a lot of time and effort. Some objects have unclear boundaries, which makes annotation hard. You might also see class imbalance, where some semantic classes appear much more often than others. This can make your machine vision model less accurate for rare classes.
Noise, lighting changes, and overlapping objects can confuse your segmentation model. You need to test your system on many types of images to make sure it works well in real-world conditions. Keeping your machine vision system accurate and robust helps you achieve better object recognition and semantic understanding.
Applications

Healthcare
You can use image segmentation in healthcare to help doctors find tumors and outline organs in medical images. Deep learning models, like U-Net and D-FCN 4S, let you quickly and accurately separate organs and tumors in CT or MRI scans. This makes radiotherapy planning faster and more precise. For example, the system can segment the right lung with 97.22% accuracy and the pericardium with 97.16% accuracy. However, doctors still need to check the results, especially for tricky areas like the esophagus.
| Organ | Dice Coefficient (%) | Description |
|---|---|---|
| Left Lung | 87.11 | High accuracy automated segmentation close to manual delineation |
| Right Lung | 97.22 | Highest accuracy in lung segmentation |
| Pericardium | 97.16 | High accuracy segmentation supporting radiotherapy planning |
| Trachea | 89.92 | Moderate accuracy; lower similarity due to anatomical variability |
| Esophagus | 70.51 | Lower accuracy; challenges due to organ variability and physician delineation disagreement |
AI-powered segmentation reduces human error and helps spot small problems in images, leading to faster and more accurate diagnoses.
Autonomous Vehicles
You rely on segmentation to help self-driving cars understand the road. Machine vision systems use deep learning to label every pixel in an image, so the car can see drivable areas, other vehicles, people, and road signs. This detailed object detection supports safe navigation and quick decision-making. Real-time instance segmentation lets the car react instantly to changes, even in busy or complex scenes. These applications improve safety and make autonomous driving possible.
Agriculture
You can use segmentation to monitor crops and estimate yields. For example, image segmentation applications can count grape bunches, measure their size, and separate fruit from leaves in images. This helps you estimate crop volume and weight with less than 30% error compared to manual checks. You can also use segmentation to spot pests, diseases, and analyze crop cover. These applications support precision farming and help you create high-resolution yield maps for better planning.
- Detect and count fruit automatically
- Separate crops from background for 3D mapping
- Estimate yield and monitor plant health
Robotics and Manufacturing
In factories, you use image segmentation for quality control and defect detection. Machine vision systems with U-Net models can find tiny defects on products by dividing images into defect and non-defect regions. This process is fast and accurate, allowing robots to remove faulty parts in real time. You can inspect hundreds of items per minute with over 99% accuracy, which reduces errors and saves money.
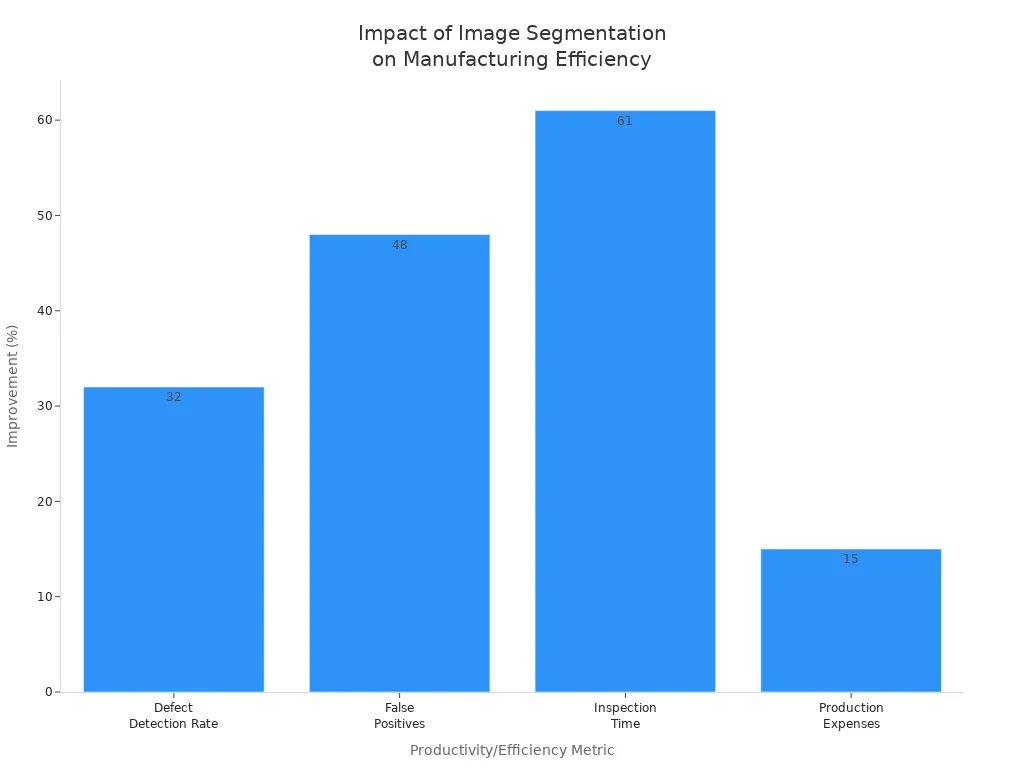
You see big gains in productivity, such as a 32% increase in defect detection rates and a 61% drop in inspection time.
Other Uses
Image segmentation applications reach many other fields:
| Emerging Field | Application Example |
|---|---|
| Retail | Enhance analytics with accurate data tagging |
| Security & Surveillance | Improve video labeling for better security |
| Biotechnology | Provide precise data insights |
| Energy | Optimize systems with smart data labeling |
| Sports Vision | Boost sports analysis with video annotations |
| Media & Advertising | Create immersive gaming and AR experiences |
You can use segmentation for object recognition, scene understanding, and real-time analysis in these areas. Machine vision systems help you make quick, reliable decisions across many industries.
Tip: Real-time segmentation in machine vision systems lets you spot problems and act fast, improving quality control and safety.
You gain powerful tools when you understand segmentation in machine vision systems.
- You can choose the right segmentation type for your task, balancing accuracy, speed, and cost.
- You improve object detection, scene analysis, and quality control across many fields.
| Sector | Innovation Example |
|---|---|
| Healthcare | Tumor detection and diagnosis |
| Industry | Defect detection and sorting |
| Agriculture | Crop yield estimation |
Image segmentation lets you spot subtle details and make confident decisions. Explore new segmentation techniques to drive progress in your field.
FAQ
What is the main benefit of using image segmentation in machine vision?
You get precise object boundaries and detailed analysis. This helps you detect, measure, and inspect objects more accurately than with simple bounding boxes.
Can you use image segmentation for real-time applications?
Yes! You can use fast models like U-Net or Mask R-CNN for real-time tasks. These models help you inspect products, guide robots, or drive vehicles safely.
How do you choose between 2D and 3D segmentation systems?
You pick 2D systems for flat surfaces or simple inspections. You choose 3D systems when you need depth, such as measuring object height or guiding robots in space.
Do you need a lot of labeled data to train segmentation models?
You usually need many labeled images for deep learning models. Some advanced models, like SAM, can work with fewer labels or adapt to new tasks with less data.
Tip: Start with public datasets to save time and improve your results.
See Also
Understanding How Machine Vision Systems Process Images
Future Trends Of Machine Vision Segmentation In 2025
Exploring Pixel-Based Machine Vision For Today’s Uses
Essential Principles Behind Edge Detection In Machine Vision








