
Feature extraction in machine vision systems transforms raw images into meaningful data for analysis. This process reduces data complexity by keeping only the most important features, which helps machine vision models work faster and more accurately. In 2025, industries rely on feature extraction machine vision system designs to handle large volumes of visual information. For example, computer vision market growth shows strong adoption across sectors:
| Metric / Sector | Statistic / Projection | Timeframe / CAGR | Significance to Feature Extraction Adoption in Machine Vision |
|---|---|---|---|
| Computer Vision Market Size | $22 billion (2023) to $50 billion | 2023 to 2030, 21.4% CAGR | Indicates rapid growth and adoption of computer vision technologies that rely heavily on feature extraction |
| Retail Sector Adoption | 44% of retailers use computer vision | As of 2024 | Demonstrates practical deployment of feature extraction in real-world applications |
Feature extraction supports object detection, image segmentation, and image processing tasks in computer vision. By focusing on key features, machine vision systems improve object detection accuracy and speed, making them essential for modern image processing and prediction tasks.
Key Takeaways
- Feature extraction simplifies images by finding important parts like edges and textures, helping machines understand and analyze visual data faster and more accurately.
- Traditional methods like edge detection and shape recognition work well for many tasks, but deep learning models, especially CNNs, learn features automatically and improve accuracy significantly.
- Combining traditional and deep learning feature extraction techniques leads to the best results in complex image processing tasks across industries like manufacturing, healthcare, and autonomous vehicles.
- Machine vision systems face challenges like noise, environmental changes, and high data complexity, but new methods improve robustness, efficiency, and adaptability for real-world use.
- Future feature extraction will focus on smarter, faster, and more flexible systems using 3D recognition, AI integration, and multimodal data to support diverse applications and easier development.
Feature Extraction Basics
What Is Feature Extraction?
Feature extraction in a machine vision system means finding and isolating important parts of an image. This process looks for visual elements like edges, corners, and textures. These elements help computers understand what is in the image. For example, in facial recognition, the system finds features such as eyes, nose, and mouth. The feature extraction process changes raw image data into useful information. This step makes it easier for computers to classify or predict what they see.
Deep learning models, such as convolutional neural networks, use layers to extract features. Early layers find simple patterns like edges or borders. Later layers find more complex patterns, such as textures or whole objects. This step-by-step approach helps the system build a detailed understanding of the image. The feature extraction workflow allows the machine vision system to focus on what matters most in each image.
Role in Machine Vision
Feature extraction forms the foundation of image processing in machine vision. It helps turn complex images into simple, structured data. This makes it easier for computers to process and analyze images. The system uses feature extraction machine vision system designs to improve tasks like object detection and image segmentation.
Feature extraction reduces the amount of data the system needs to handle. It keeps only the most important information, which saves time and computer power.
Key reasons why feature extraction is essential in machine vision include:
- It simplifies raw image data for faster image processing.
- It lowers data dimensionality, making models more accurate.
- It highlights key image characteristics, such as edges, shapes, and textures.
- It supports object detection and image segmentation by focusing on important features.
- It helps reduce noise and prevents overfitting, so models work better in real-world situations.
The feature extraction machine vision system uses both traditional and deep learning techniques. These techniques include edge detection, texture analysis, and shape recognition. Deep learning methods can learn new features automatically, making them powerful for modern computer vision tasks. Image processing techniques rely on strong feature extraction to deliver accurate results in many fields, such as manufacturing, healthcare, and autonomous vehicles.
Feature Extraction Techniques
Traditional Methods
Traditional feature extraction techniques form the backbone of many machine vision systems. These methods help computers find important patterns in images. Edge detection stands out as a key process. It uses computer vision algorithms like the Sobel and Canny filters to highlight boundaries where brightness or texture changes. These filters help with image processing by making it easier to spot objects and shapes.
Texture analysis also plays a big role. Local Binary Patterns (LBP) and Gray Level Co-occurrence Matrix (GLCM) are popular for this task. LBP compares each pixel to its neighbors and creates a pattern that describes the texture. GLCM looks at how often pairs of pixel values appear together, which helps in medical imaging and surface inspection.
Shape recognition uses descriptors such as Histogram of Oriented Gradients (HOG). HOG captures the direction and strength of edges in small parts of an image. This method works well for detecting people and objects. Gabor filters also help by focusing on specific frequencies and directions, making them useful for fingerprint and face recognition.
Edge detection and corner detection often work together. Edge detection finds the outlines, while corner detection locates points where edges meet. These feature extraction techniques support many image processing tasks in machine learning and computer vision.
A comparison of traditional feature extraction methods shows their strengths and best use cases:
| Feature Extractor | Strengths / Best Use Cases | Robustness to Transformations | Computational Efficiency |
|---|---|---|---|
| FAST + ORB + BF matcher | Real-time applications | Good under affine and brightness | Fastest detection and matching |
| AKAZE | Handles blurring, rotation, scaling | High robustness | Moderate computational cost |
| ORB | Affine transformations, brightness changes | Robust to affine and brightness | Efficient and fast |
| BRISK | Salt-and-pepper noise | Robust to noise | Moderate speed |
| SURF, SIFT, KAZE, AKAZE | Barrel fisheye distortion | Good matching accuracy | Higher computational cost |
| AKAZE, STAR + DAISY | Perspective distortions | Robust to perspective | Moderate computational cost |
These computer vision algorithms offer different balances between speed, accuracy, and robustness. Machine learning models often use a mix of these feature extraction techniques for better results in image processing.
Deep Learning Approaches
Deep learning has changed how feature extraction works in machine vision. Convolutional neural networks (CNNs) lead this change. CNNs take raw images and process them through several layers. Each layer finds different features, starting with simple edges and moving to complex shapes.
The steps in a CNN for feature extraction include:
- The network receives the image as a grid of pixels.
- Convolutional layers use filters to scan for local features like edges and textures, creating feature maps.
- Activation layers, such as ReLU, help the network learn complex patterns.
- Pooling layers shrink the feature maps, making image processing faster and reducing overfitting.
- Fully connected layers combine all features for final decisions, such as classifying or detecting objects.
- The output layer gives the prediction as probabilities.
CNNs allow machine vision systems to learn features directly from data. This removes the need for manual feature engineering and makes the system more flexible.
Deep learning feature extraction techniques show clear improvements over traditional methods. For example, when comparing accuracy, deep features and mixed approaches outperform traditional ones:
| Feature Extraction Method | Accuracy (%) | AUC | Notes |
|---|---|---|---|
| Traditional Quantitative Features | 77.5 | 0.712 | Using decision tree classifier |
| Deep Features (Transfer Learning, CNN) | 77.5 | 0.713 | Using decision tree classifier |
| Mixed Deep + Traditional Features | 90 | 0.935 | Using pretrained VGG-F CNN features combined with traditional features; statistically significant improvement |
| Deep Features (Single Slice, VGG-M CNN) | 82.5 | N/A | Using 5 postReLU features |
| Deep Features (Multiple Slice, VGG-F CNN) | 87.5 | N/A | Using postReLU features |
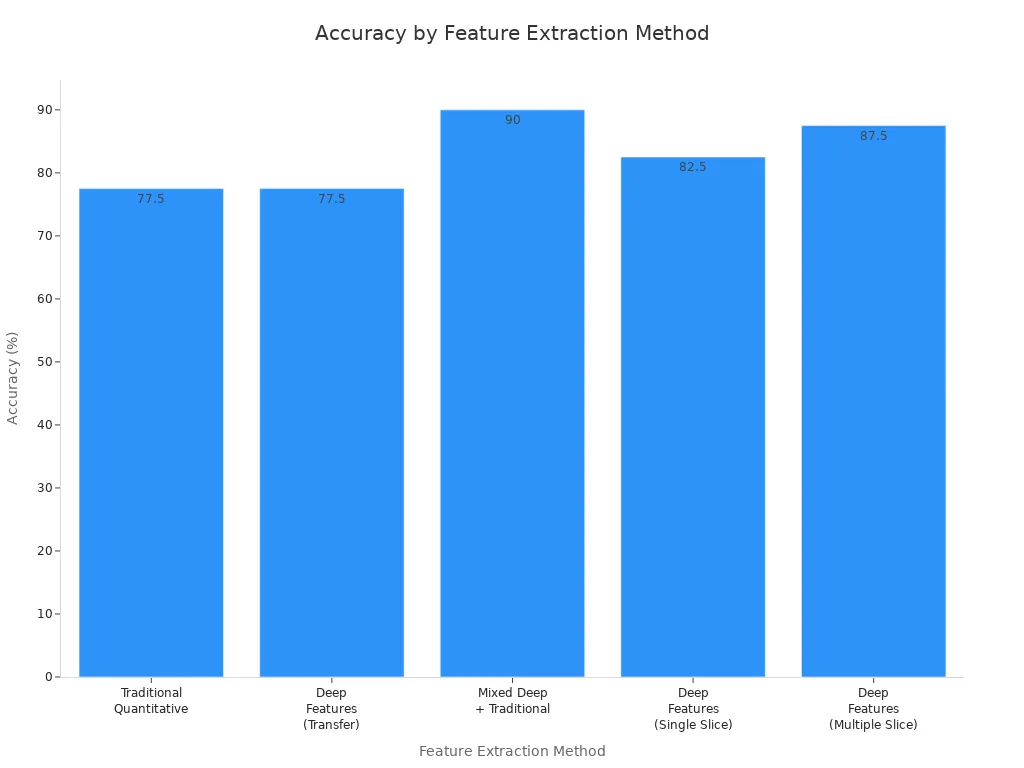
This chart shows that combining deep and traditional feature extraction techniques leads to the highest accuracy in image processing tasks. Machine learning models benefit from this mix, especially in complex computer vision problems.
Automated Feature Extraction
Automated feature extraction uses artificial intelligence to learn features from images without much human help. Deep learning models, especially CNNs, handle this process by training on large datasets. The system finds patterns, edges, and corners on its own, making it more adaptable to new tasks.
A comparison between automated and manual feature extraction shows key differences:
| Aspect | Automated Feature Extraction (Deep Learning) | Manual/Traditional Feature Extraction (Computer Vision) |
|---|---|---|
| Feature Identification | Learned automatically by models from raw image data through multiple layers | Manually designed using expert knowledge (e.g., edge detection, texture analysis, SIFT) |
| Human Intervention | Minimal human involvement; features emerge during training | Requires significant manual tuning and domain expertise |
| Adaptability & Scalability | High adaptability to complex tasks and large datasets; hierarchical feature learning | Less flexible; handcrafted features may not generalize well across varied scenarios |
| Performance | Superior on complex tasks like classification, detection, segmentation with sufficient data and compute | Often less effective on complex or variable data |
| Computational Requirements | High computational demand, needs GPUs and large labeled datasets | Lower hardware requirements, suitable for simpler tasks and limited data |
Recent advancements in automated feature extraction include self-supervised learning (SSL) methods. These techniques, such as Bootstrap Your Own Latent (BYOL), Momentum Contrast (MoCo), SimCLR, and Masked Autoencoders (MAE), help models learn from unlabeled data. SSL methods now use vision transformers, which improve data efficiency and representation quality. These new computer vision algorithms make automated feature extraction more powerful and scalable for image processing.
Automated feature extraction techniques allow machine vision systems to handle complex image processing tasks with less manual work. This shift supports the growing use of machine learning and artificial intelligence in computer vision.
Applications in Machine Vision

Manufacturing
Manufacturing relies on machine vision to improve quality and efficiency. Feature extraction helps identify defects and ensure products meet standards. Common applications include:
- Gear machining inspection
- Stator core inspection
- Battery tab laser weld inspection
- Flexible plastic packaging inspection
- Syringe final inspection
Techniques like Histogram of Oriented Gradients and texture analysis help detect small defects. These methods support image acquisition and image recognition, making the process faster and more reliable. Advanced feature extraction modules, such as the Edge Information Feature Enhancement Module and Content-Aware Reorganization Feature Module, increase accuracy and reduce computational costs. The Dynamic Detection Head also improves efficiency and decision-making.
A comparison of training schemes shows how feature extraction impacts defect detection accuracy:
| Training Scheme | Feature Extractor Initialization | Pretraining on MS COCO Dataset | mAPbbox on GDXray Test Set | mAPmask on GDXray Test Set |
|---|---|---|---|---|
| a | Random (Xavier Initialization) | No | 0.651 | 0.420 |
| b | Pretrained ImageNet Weights | No | 0.874 | 0.721 |
| c | Pretrained ImageNet Weights | Yes | 0.957 | 0.930 |
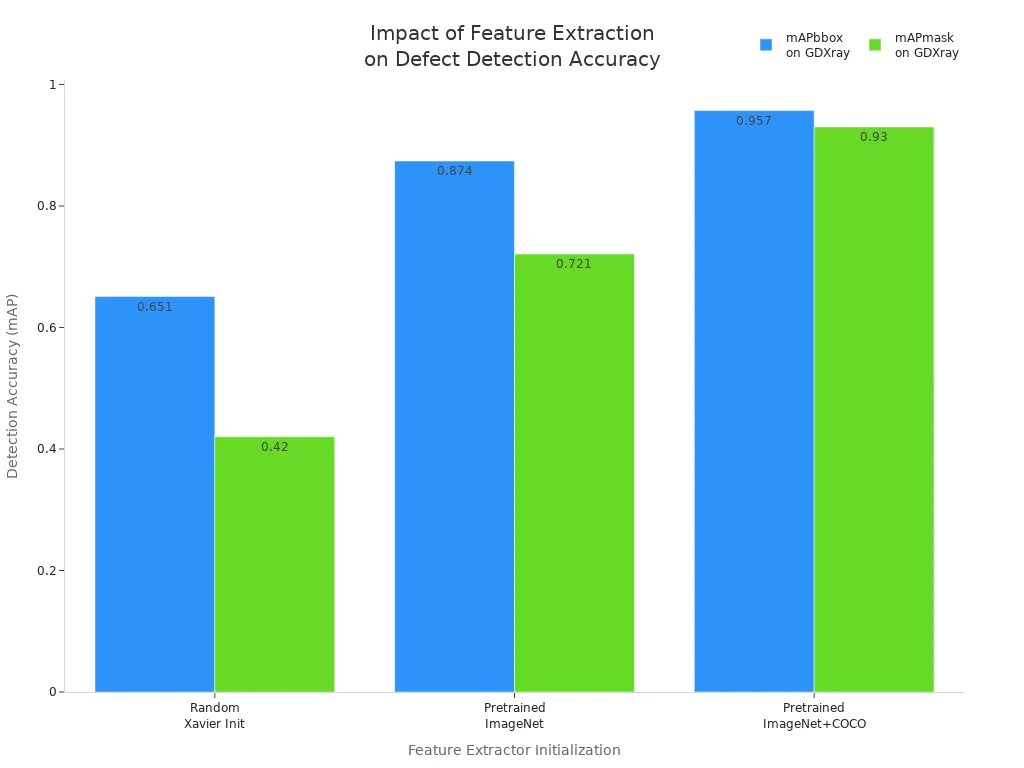
These results show that using pretrained weights and advanced modules leads to better defect detection. Machine vision systems in manufacturing now support predictive modeling and real-time decision making.
Healthcare
Healthcare imaging uses machine vision to support diagnosis and treatment. Feature extraction helps identify patterns in medical images, such as tumors or lesions. Convolutional neural networks extract spatial hierarchies, while diffusion models improve image quality by removing noise. Denoising Diffusion Probabilistic Models reveal subtle features that may be hidden in low-contrast images.
Both handcrafted and learned features play a role in medical image segmentation and classification. Transfer learning adapts pre-trained models to new medical datasets, improving performance even with limited data. These methods support predictive modeling and clinical decision-making. For example, combining deep learning features with radiomics improves prostate cancer grading. In breast cancer detection, deep learning models achieve high accuracy and reduce false negatives. Polyp segmentation in colonoscopy and diabetic retinopathy detection also benefit from advanced feature extraction.
Machine vision in healthcare improves image acquisition, supports image recognition, and enables more accurate predictive modeling for patient care.
Autonomous Vehicles
Autonomous vehicles depend on machine vision for safe navigation. Feature extraction allows vehicles to detect objects, recognize lane lines, and understand traffic scenes. Convolutional neural networks process camera inputs to identify vehicles, pedestrians, and signs. Multi-scale feature maps and fusion techniques, such as Feature Pyramid Networks, improve detection of small or distant objects.
Semantic segmentation transforms feature maps into high-resolution maps, helping vehicles find drivable areas. Vision-language models combine visual and text data, supporting complex scene understanding and decision making. Recent improvements in radar feature extraction use neural networks to process radar data quickly, making real-time object recognition possible. Enhanced algorithms, like those in YOLOv8, use attention mechanisms to filter key features and improve detection in urban environments.
Machine vision systems in autonomous vehicles rely on fast image acquisition, accurate image classification, and robust predictive modeling. These systems support real-time decision-making, helping vehicles respond to changing road conditions.
Challenges and Trends
Robustness
Machine vision systems must handle many challenges to achieve robust feature extraction. Weather, noise, blur, and digital distortions can lower the quality of image processing. These problems make it hard for models to work well in real-world settings. Adversarial attacks, such as pixel changes or hidden patches, can trick neural networks. Even with better architectures, a gap remains between clean and corrupted images. Human vision stays strong against many of these issues, but artificial systems still struggle. Researchers use adversarial training and contrastive learning to help models resist attacks. They also test models with benchmarks like ImageNet-C to measure how well feature extraction works under tough conditions. Environmental changes, such as different seasons or locations, can also affect how well features get extracted. Using process controls and careful testing helps improve reliability.
- Common robustness challenges:
- Weather effects and digital noise
- Adversarial attacks on neural networks
- Gaps in performance between clean and corrupted data
- Environmental variability across locations and times
Data Dimensionality
High data dimensionality makes feature extraction in machine vision more complex. When images have many features, models need more power and time to process them. This can slow down image processing and make it harder to find useful patterns. Advanced methods, like joint tensor decomposition, help reduce the number of features while keeping important information. These methods improve accuracy and make models easier to use. Techniques such as Principal Component Analysis and Linear Discriminant Analysis help remove extra features and lower the risk of overfitting. Deep learning methods, like autoencoders, can also select the best features for machine learning tasks. Choosing the right method depends on the type of data and the problem at hand.
Efficiency
Efficiency is key for real-time machine vision. Feature extraction often needs to process large amounts of data quickly. On small devices, limited resources can slow down image processing. Some methods, like Optical Flow, can cause delays and lower frame rates. New designs, such as the Integrated Motion Feature Extractor, help speed up processing without losing accuracy. Developers use GPU acceleration and multi-threading to make feature extraction faster. Recent models, like improved Swin Transformers and supervised autoencoders, show better efficiency and accuracy. These advances help machine vision systems support fast decision-making in real-world tasks.
- Recent improvements in efficiency:
- Use of probabilistic PCA and variational autoencoders
- Pre-trained deep learning models for faster feature extraction
- Multi-stage architectures for better performance
Future Directions
Feature extraction in machine vision will keep evolving. Systems now move from 2D to 3D recognition, allowing deeper object analysis. Explainability and interpretability of features are becoming more important, helping users understand how models make decisions. Transfer learning and few-shot learning let models adapt to new tasks with less data. Multimodal feature extraction combines images with text or other data for richer results. Hybrid approaches mix traditional and deep learning methods for better accuracy. Advances in computational power and algorithms will support more complex tasks, especially in 3D image processing. Trends for the next five years include more AI integration, better pre-trained models, and easier pipelines for developers. Edge computing and cloud solutions will help real-time decision making on many devices. Open-source projects and community efforts will drive new ideas and improvements.
The future of feature extraction in machine vision will focus on making systems smarter, faster, and easier to use for many industries.
Feature extraction drives progress in machine vision by enabling accurate object detection, segmentation, and prediction. Mastery of both traditional and deep learning techniques lets professionals choose the best approach for each task, improving quality and efficiency. Recent advancements have increased accuracy and reduced resource use, as shown below:
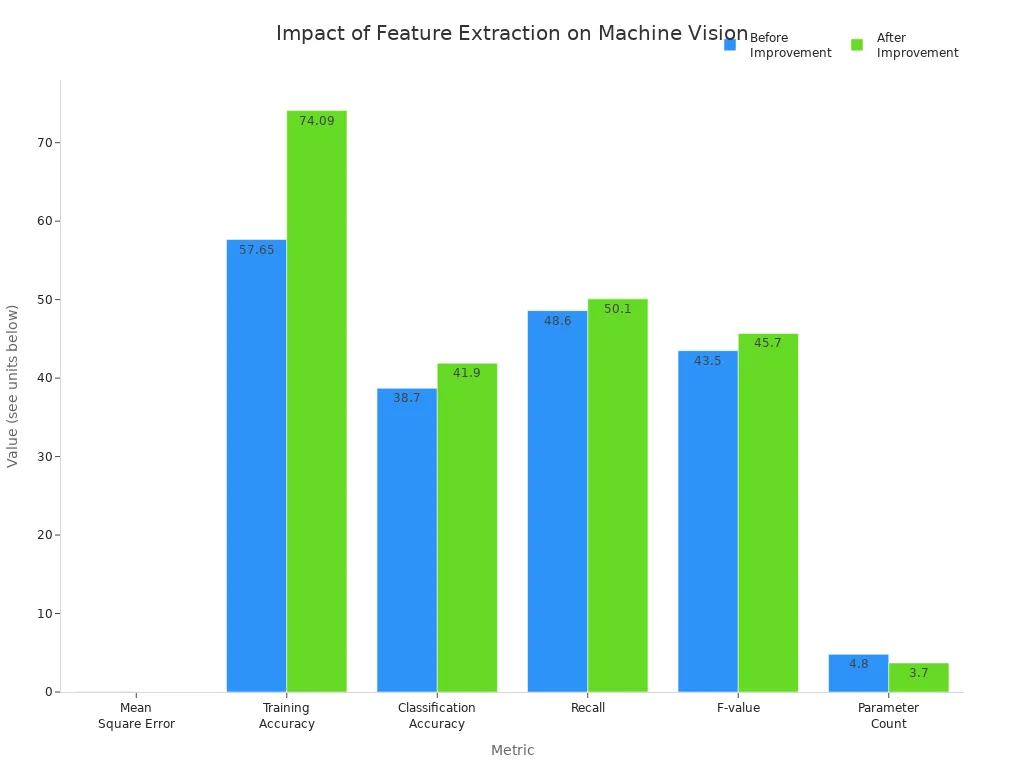
Staying updated on trends helps industries unlock new value from machine vision. For deeper learning, resources like "Mastering Feature Extraction in Computer Vision" and "Pattern Recognition and Machine Learning" offer practical and theoretical insights.
FAQ
What is the main goal of feature extraction in machine vision?
Feature extraction helps a computer find the most important parts of an image. This process makes it easier for the system to recognize objects, patterns, or actions in pictures or videos.
How do deep learning models improve feature extraction?
Deep learning models, like CNNs, learn to find useful features by looking at many images. They can spot patterns that humans might miss. This makes the system more accurate and flexible.
Can feature extraction work with videos as well as images?
Yes, feature extraction works with both images and videos. In videos, the system looks at each frame to find important features. This helps with tasks like tracking moving objects.
Why does reducing data dimensionality matter?
Reducing data dimensionality removes extra information from images. This makes the computer work faster and helps models focus on what matters most. It also lowers the chance of mistakes.
See Also
The Role Of Feature Extraction In Machine Vision
Advancements In Machine Vision Segmentation For 2025
Understanding Edge AI Applications In Real-Time Vision 2025









