
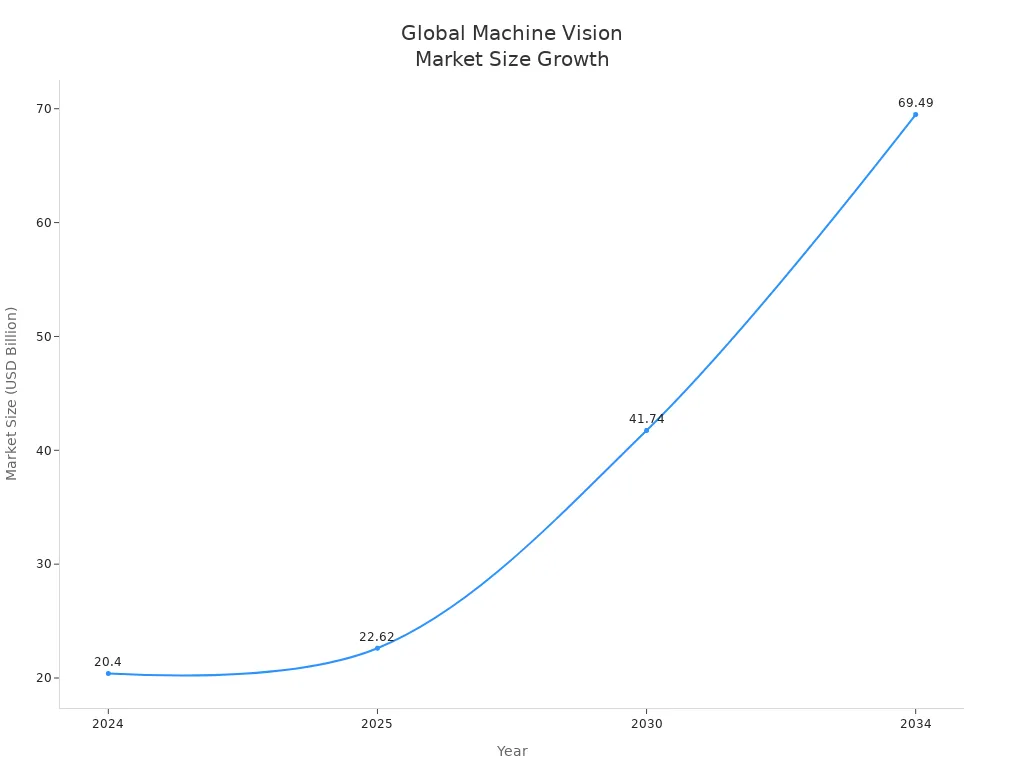
A deep learning machine vision system helps computers see and understand images, making tasks like inspection and classification automatic and accurate. These systems allow factories to spot defects in products, robots to assemble parts, and cameras to check safety gear. The global machine vision market has grown quickly, reaching $20.4 billion in 2024 and expected to hit $69.49 billion by 2034.
- Common uses for machine vision include:
- Checking quality and spotting defects on production lines
- Guiding robots during assembly or packaging
- Helping with safety by detecting hazards
Key Takeaways
- Deep learning machine vision systems help computers see and understand images, making tasks like quality inspection and safety checks faster and more accurate.
- These systems learn from large sets of images, allowing them to handle complex and changing tasks better than traditional rule-based methods.
- Machine vision improves productivity, reduces errors, and creates safer workplaces by automating visual inspections and guiding robots.
- Starting with simple projects and using beginner-friendly tools like Python and OpenCV helps newcomers build skills in deep learning machine vision.
- Deep learning models like CNNs power these systems, enabling real-time object detection, image classification, and defect spotting across industries like manufacturing, healthcare, and automotive.
What Is a Deep Learning Machine Vision System?
Definition
A deep learning machine vision system uses artificial intelligence to help computers see and understand images. This technology combines cameras, computers, and special software to capture pictures and analyze them. In industry, experts define machine vision as an engineering field focused on automating tasks that need visual inspection. The process involves several main steps:
- Image Acquisition: Cameras capture a scene and turn it into a digital image.
- Data Delivery: The system sends the digital image to a computer for analysis.
- Information Extraction: The computer looks for patterns, edges, or objects in the image.
- Decision Making: Deep learning algorithms help the computer decide what the image shows or what action to take.
Deep learning is a special type of machine learning that uses neural networks. These networks learn from large sets of images. They can recognize objects, classify images, and even spot tiny defects. Unlike older machine vision systems that rely on fixed rules, deep learning machine vision systems learn from data. This makes them better at handling complex and changing tasks.
Note: Machine vision is mostly used in factories and industrial settings. It always uses cameras and often follows strict rules. Computer vision, which includes deep learning, is more flexible and can learn from new data.
Significance
Deep learning machine vision systems have changed how industries work. They help companies automate tasks that once needed human eyes. This leads to faster, more accurate, and safer operations. The impact of these systems includes:
- Faster image processing and analysis, which speeds up production lines.
- Improved quality control by finding small defects that people might miss.
- Lower costs because machines can do inspections without breaks.
- Safer workplaces, as machines can handle dangerous inspection jobs.
- Real-time data collection, which helps companies predict problems and fix them before they cause delays.
Deep learning allows machine vision to move beyond simple, rule-based tasks. It can handle complex jobs like sorting mixed objects, reading messy handwriting, or guiding robots. As a result, deep learning machine vision systems play a key role in modern factories, smart manufacturing, and even self-driving cars.
| Aspect | Traditional Machine Vision (Rule-Based) | Deep Learning Machine Vision |
|---|---|---|
| Programming | Manual rules | Learns from large datasets |
| Data Requirements | Low | High |
| Adaptability | Limited | High |
| Task Suitability | Simple, consistent tasks | Complex, variable tasks |
| Strengths | Precision, speed, explainability | Automatic feature learning, adaptability |
| Weaknesses | Poor generalization | High data and computational needs |
Deep learning machine vision systems continue to grow in importance. They help industries improve productivity, reduce errors, and stay competitive in a fast-changing world.
How It Works
Image Input to Output
A deep learning machine vision system follows a clear path from capturing an image to making a decision. The process starts when a camera takes a picture or records a video frame. The system then prepares the image for analysis. This preparation includes several important steps:
- Normalization: The system scales pixel values, usually between 0 and 1. This step helps the neural network learn faster and more accurately.
- Resizing: All images must have the same size before entering the neural network. The system resizes each image, keeping its shape to avoid distortion.
- Augmentation: The system creates new images by rotating, flipping, or changing brightness. This step increases the variety of images and helps the model learn better.
After preprocessing, the system may remove noise or sharpen edges. It can also focus on certain areas, called regions of interest, to find important details. The neural network then analyzes the image, looking for patterns or objects. The final step involves interpreting the results and making a decision, such as classifying an object or detecting a defect.
Tip: Preprocessing steps like normalization and augmentation help the system handle different lighting, angles, and backgrounds. This makes the vision system more reliable in real-world settings.
The entire process allows deep learning models to move from raw image input to a clear output, such as a label or a location on the image.
Deep Learning in Vision
Deep learning has changed how computers understand images. In the past, engineers wrote rules to find features like edges or shapes. Now, deep learning algorithms learn these features from data. This approach makes vision systems more flexible and accurate.
The most common neural network for vision tasks is the Convolutional Neural Network (CNN). CNNs use layers of filters to find edges, textures, and shapes in images. Other popular architectures include:
| Architecture | Primary Use Case | Key Characteristics and Advantages |
|---|---|---|
| Convolutional Neural Networks (CNNs) | Image recognition, object detection, segmentation | Capture spatial hierarchies; fewer parameters; maintain pixel locality; foundational for vision tasks. |
| Residual Networks (ResNet) | Deep image recognition | Introduce skip connections to ease training of very deep networks; prevent gradient vanishing/explosion. |
| U-Net | Image segmentation | Combines downsampling and upsampling paths to maintain spatial resolution for pixel-wise labeling. |
| YOLO | Real-time object detection | Fast, unified detection model enabling real-time performance. |
| Autoencoders | Feature extraction, compression | Encoder-decoder structure for dimensionality reduction and reconstruction. |
| Generative Adversarial Networks (GANs) | Image generation | Two-network adversarial setup for generating realistic images and data samples. |
Deep learning models like CNNs and ResNets have set new records in image recognition. For example, AlexNet reduced error rates in major competitions, and later models like VGG and RCNN improved accuracy even more. These advances show how deep learning algorithms can learn complex patterns and adapt to new tasks.
- The use of max-pooling and GPU acceleration made training deep networks much faster.
- CNNs now outperform older methods like Support Vector Machines (SVMs) in both speed and accuracy. For example, on the MNIST dataset, CNNs reached 98% accuracy in less time than SVMs, which only reached 88%.
Deep learning in vision systems allows computers to recognize objects, detect defects, and even understand scenes. These systems can handle tasks that change over time or involve many different types of images. As a result, deep learning has become the foundation for modern machine vision.
Components
Image Acquisition
Image acquisition forms the first step in any machine vision process. High-resolution cameras act as the eyes of the system, capturing detailed images or video frames. Proper lighting, such as backlighting or ring lighting, helps highlight important features and prevents shadows. Sensors, including CMOS or CCD types, collect raw data. Some systems use advanced sensors like Lidar or time-of-flight for extra detail. AI can adjust camera settings and lighting in real time, ensuring clear images even when conditions change. The quality of image acquisition directly affects the speed and accuracy of later analysis.
| Machine Vision System Type | Operational Principle | Typical Applications | Technical Specifications |
|---|---|---|---|
| 1D Machine Vision System | Uses linear sensors to scan objects line-by-line | Simple inspection tasks requiring measurement along a single dimension | Linear sensor type, line scan method |
| 2D Area Array Scan System | Captures full 2D images using area sensors | Food packaging inspection, electronics assembly, OCR verification | Area sensor type, full frame capture, analyzes length and width |
| 2D Line Scan System | Uses line sensors to scan objects line-by-line, building 2D images | High-speed production lines, continuous web inspection | Linear sensor type, line-by-line scanning, suitable for fast moving objects |
| 3D Machine Vision System | Captures depth information using multiple cameras, structured light, or laser triangulation | Automotive part inspection, 3D measurement, logistics volume scanning | Uses specialized 3D technologies (laser scanning, structured light, stereo vision), provides depth and dimensional data |
Data Preprocessing
Before analysis, the system prepares images through data preprocessing. This step includes resizing images to a standard size, normalizing pixel values, and reducing noise with filters. Grayscale conversion can simplify images, making them easier to process. Techniques like histogram equalization improve contrast, while edge detection highlights important shapes. Data augmentation, such as flipping or rotating images, increases the variety of training data. These steps help neural networks learn faster and perform better, even when images vary in lighting or angle.
Deep Learning Models
Deep learning models, especially neural networks like CNNs and FCNs, analyze the processed images. CNNs excel at finding patterns and classifying objects. FCNs handle tasks like image segmentation, where each pixel gets a label. For different machine vision tasks, specific models work best:
| Machine Vision Task | Effective Deep Learning Models | Notes on Usage and Advantages |
|---|---|---|
| Image Classification | ResNet, VGGNet | High accuracy for sorting images |
| Object Detection | Faster R-CNN, YOLOv7, SSD | Real-time detection and localization |
| Semantic Segmentation | FastFCN, DeepLab, U-Net | Pixel-level scene understanding |
| Instance Segmentation | SAM, Mask R-CNN | Differentiates between similar objects |
| Pose Estimation | OpenPose, MoveNet, PoseNet | Detects human body positions |
| Image Generation | DALL-E | Creates new images from text |
Hardware like GPUs and FPGAs boosts the speed of these models, making real-time vision possible in factories and vehicles.
Output
The output from a deep learning machine vision system provides actionable results. In manufacturing, the system might spot a defect and trigger a rejection mechanism. In traffic management, it can track vehicles and adjust signals for better flow. The system uses metrics like accuracy and precision to ensure reliable results. Outputs help automate decisions, improve quality, and increase speed in many industries. For example, in a bottling plant, the system can detect faulty seals and remove defective bottles, improving product quality and reducing waste.
Deep Learning vs. Traditional Vision
Feature Extraction
Feature extraction is a key difference between traditional and modern vision systems. Traditional vision systems depend on experts to design features by hand. These features might include edges, corners, or textures. Engineers use tools like edge detection or SIFT to find important parts of an image. This process takes time and often misses flaws in complex or changing scenes.
Modern vision systems use neural networks to learn features directly from raw images. These networks process images through many layers, each finding more complex patterns. The system learns to spot flaws, shapes, and textures without human help. This approach increases robustness and reduces the chance of missing important details. The table below shows a clear comparison:
| Aspect | Traditional Machine Vision | Deep Learning Approaches |
|---|---|---|
| Feature Extraction | Handcrafted by experts | Learned automatically from data |
| Adaptability | Limited | High |
| Human Intervention | High | Low |
| Performance | Struggles with complex flaws | Handles complex flaws well |
| Robustness | Lower | Higher |
Adaptability
Adaptability measures how well a vision system handles new tasks or changes. Traditional systems work best with fixed, simple tasks. They struggle when lighting, object types, or backgrounds change. Engineers must update rules by hand to fix flaws or adjust to new products.
Modern vision systems show much greater robustness. They learn from large datasets and adapt to new situations. These systems can spot flaws in different shapes, sizes, or lighting conditions. Automation helps them make decisions quickly and accurately, even in complex environments. For example, in factories, these systems adjust to new products without manual updates. They also support real-time quality checks and reduce errors. This level of adaptability makes modern vision systems more reliable and cost-effective over time.
Applications

Manufacturing
Manufacturing leads in adopting machine vision for factory automation. Companies use vision systems for quality inspection, object detection, and robotics. These systems find defects in products, guide robotic arms, and read barcodes at high speed. The table below shows common use cases and their results:
| Use Case | Description | Reported Results / Metrics |
|---|---|---|
| Quality Inspection | Automated defect detection and label inspection | Inspecting over 1,000 labels per minute; 98% accuracy |
| Supply Chain Optimization | Enhancing operational efficiency and cost reduction | 15% cost decrease per line per year |
| Equipment Monitoring | Preventing failures and downtime | Improved operational uptime |
| Workforce and Equipment Safety | Monitoring compliance with safety protocols | Automated mask detection |
| Real-time Barcode Reading | Automated reading and verification | Increased speed and accuracy |
| Automated Product Assembly | Guiding robotic assembly processes | Enhanced precision, fewer manual errors |
Vision systems perform detailed inspections, spot defects, and support factory automation, improving reliability and speed.
Healthcare
Healthcare uses machine vision for medical imaging and diagnostics. Systems powered by advanced algorithms analyze X-rays, MRIs, and ECG signals. They segment images, detect tumors, and classify diseases. These tools help doctors find defects in tissues and monitor disease progression. Python libraries like TensorFlow and PyTorch support these tasks. The result is higher accuracy in diagnosis and better patient care.
Automotive
Automotive industries rely on machine vision for safety and autonomous driving. Vision systems detect road hazards, vehicles, and pedestrians. Upgraded models like YOLOv5s improve small target detection and image learning. Real-world tests show reliable target position and depth information. Control integration with vehicle systems leads to stable speed and steering. These advances increase safety and reduce traffic congestion.
| Aspect | Description | Impact on Automotive Safety and Autonomous Driving |
|---|---|---|
| Algorithmic Improvement | Upgraded YOLOv5s for better detection | Faster convergence, improved learning |
| Performance Metrics | Enhanced mAP, precision, recall | More accurate detection of hazards |
| Real-World Testing | Vehicle-mounted camera on routes | Reliable target acquisition |
| Control Integration | Combined with vehicle control algorithms | Stable speed and steering |
| Safety Outcomes | Improved obstacle avoidance | Enhanced personal safety |
Security
Security and surveillance benefit from machine vision through real-time video analysis. Edge AI enables fast processing on local devices, reducing network delays and privacy risks. Intelligent cameras detect people, analyze crowds, and spot illegal activity. These systems improve face recognition and track objects across multiple feeds. They also reduce false positives and help operators respond quickly.
- Real-time video processing on edge devices
- Person and object detection
- Intrusion and anomaly detection
- Automated video summarization
- Enhanced accuracy in face recognition
Agriculture & Logistics
Agriculture uses machine vision for crop monitoring and pest management. Systems analyze real-time data from sensors and drones to check crop health. They help farmers choose crops, manage nutrients, and control pests. These tools improve prediction accuracy and support better decisions, leading to higher productivity. In logistics, vision systems track packages and verify labels, supporting factory automation and detailed inspections.
Deep learning expands machine vision by adapting to new products, lighting, and environments. Industries now achieve higher accuracy, reliability, and speed in inspection and automation.
Getting Started
Beginner Steps
Starting with deep learning machine vision can feel overwhelming, but simple steps help build confidence and skills. Beginners often succeed by following a clear path:
- Begin with small projects, such as detecting shapes or colors in images. These tasks help learners understand basic image processing.
- Use Python, a beginner-friendly language, because it works well with popular computer vision libraries.
- Install open-source tools like OpenCV and Scikit-image using package managers such as pip or conda. These tools make it easy to process and analyze images.
- Learn core concepts, including image acquisition, edge detection, feature detection, segmentation, and object detection.
- Follow step-by-step tutorials online to gain hands-on experience.
- Try both OpenCV and Scikit-image to see which library fits your needs best.
- Explore deep learning models like convolutional neural networks (CNNs) and practical tools such as YOLOv5 and YOLOX for real-world tasks.
Tip: Beginners often face challenges like data quality, hardware limits, and understanding complex images. Starting with simple projects and using well-documented tools helps overcome these hurdles.
Many new learners believe AI works just like the human brain or that it can operate without human help. In reality, neural networks only mimic some brain functions, and human oversight remains important for safe and fair results.
Resources
Many high-quality resources help beginners learn deep learning machine vision. The table below lists some top choices:
| Resource Type | Name & Description |
|---|---|
| Online Course | Stanford CS231N: "Deep Learning for Computer Vision" (YouTube) – Covers CNNs, RNNs, and real-world projects. |
| Online Course | University of Michigan: "Deep Learning for Computer Vision" (YouTube) – Explains fundamentals and practical coding. |
| Online Course | Coursera: "Convolutional Neural Networks" by DeepLearning.ai – Focuses on CNNs, object detection, and face recognition. |
| Book (Beginner) | "Deep Learning with Python" by François Chollet – Explains neural networks with easy code examples. |
| Book (Beginner) | "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron – Offers practical exercises and case studies. |
| Book (Advanced) | "Deep Learning" by Ian Goodfellow et al. – Covers theory and advanced architectures. |
Learners can also explore the Modern Computer Vision Track on YouTube for lectures from top universities. These resources combine theory with hands-on practice, helping beginners build strong skills in deep learning machine vision.
Deep learning machine vision systems use high-quality cameras and smart algorithms to help computers see and make decisions. These systems reduce inspection errors by over 90% and lower labor costs in factories. AutoML and neural architecture search now make these tools easier for beginners and non-experts to use. Anyone can start learning and building projects with the right resources.
- Try a step-by-step guide to building neural networks.
- Explore frameworks like TensorFlow or PyTorch.
- Practice data labeling and image augmentation.
- Use hands-on books such as the Practical Deep Learning Book.
- Test models on devices like Raspberry Pi or Jetson Nano.
With these tools and tips, anyone can explore deep learning machine vision and create real-world solutions.
FAQ
What is the main difference between machine vision and computer vision?
Machine vision focuses on industrial tasks like inspection and automation. Computer vision covers a wider range of applications, including entertainment and healthcare. Machine vision often uses fixed rules, while computer vision uses learning algorithms.
Can deep learning machine vision systems work in low light?
Yes, many systems use special cameras and image enhancement techniques. These tools help capture clear images even in poor lighting. Deep learning models can also learn to handle shadows and glare.
Do you need a lot of data to train a deep learning vision system?
Deep learning models perform best with large datasets. More images help the system learn better. Some models use data augmentation to create more training examples from fewer images.
What hardware do you need for deep learning machine vision?
Most systems use high-resolution cameras and computers with GPUs. Some projects run on small devices like Raspberry Pi or Jetson Nano. The right hardware depends on the task and speed needed.
How accurate are deep learning machine vision systems?
Accuracy depends on the quality of data and the model used. Many systems reach over 95% accuracy in real-world tasks. Regular updates and retraining help maintain high performance.
See Also
The Impact Of Deep Learning On Machine Vision
Understanding Computer Vision Models And Machine Vision Systems
A Detailed Look At Image Processing In Machine Vision
Comprehensive Guide To Semiconductor-Based Machine Vision Systems








