
A Data Augmentation Pipeline machine vision system transforms existing image datasets into more diverse and robust collections. This system involves applying techniques like rotation, scaling, and color adjustments to simulate real-world scenarios. In 2025, the importance of a Data Augmentation Pipeline machine vision system continues to grow as it helps address limited data availability. Studies show that data augmentation can enhance model accuracy by 5-10% and reduce overfitting by up to 30%. While methods like GANs demonstrate potential, their impact often depends on the specific use case. By leveraging modern augmentation techniques within a Data Augmentation Pipeline machine vision system, you ensure that your models perform better and generalize effectively.
Key Takeaways
-
A data augmentation pipeline improves image datasets by changing them. It uses methods like rotating and resizing to make models better.
-
Set clear goals for your pipeline. This helps you pick the right ways to change the images for your project.
-
Use different methods to change data, like shapes or colors. This helps your model learn from many examples and avoid mistakes.
-
Add the pipeline to your computer vision system. This makes sure data moves smoothly and helps the model train better.
-
Test and improve your pipeline often. Try new methods and settings to keep data good and models accurate.
Understanding Data Augmentation in Machine Vision
What is a Data Augmentation Pipeline?
A data augmentation pipeline is a structured process that enhances your dataset by applying various transformations to existing images. These transformations include rotation, scaling, and translation, which create modified versions of your original data while preserving their labels. This process is essential for improving the robustness of computer vision models, especially when working with limited datasets. By introducing diverse variations, the pipeline ensures your model learns to generalize better across unseen scenarios.
An effective data augmentation pipeline machine vision system depends on several factors. These include the nature of the task, the architecture of the model, and the characteristics of the dataset. For example, in object recognition tasks, augmentations like flipping or cropping can simulate real-world conditions, helping your model achieve higher accuracy. Advanced techniques can even generate thousands of unique outputs from a single input, significantly expanding your dataset.
Types of Data Augmentation Techniques
Data augmentation techniques can be broadly categorized into two types: geometric transformations and color-based transformations. Geometric transformations, such as rotation, flipping, and scaling, alter the spatial properties of an image. These are particularly useful for tasks like image segmentation and object detection, where spatial relationships are critical.
Color-based transformations, on the other hand, modify the color properties of an image. Techniques like hue adjustment, saturation changes, and channel swapping can help your model adapt to varying lighting conditions. For instance, a study comparing augmentation techniques showed that combining multiple transformations improved model accuracy from 44% to over 96%.
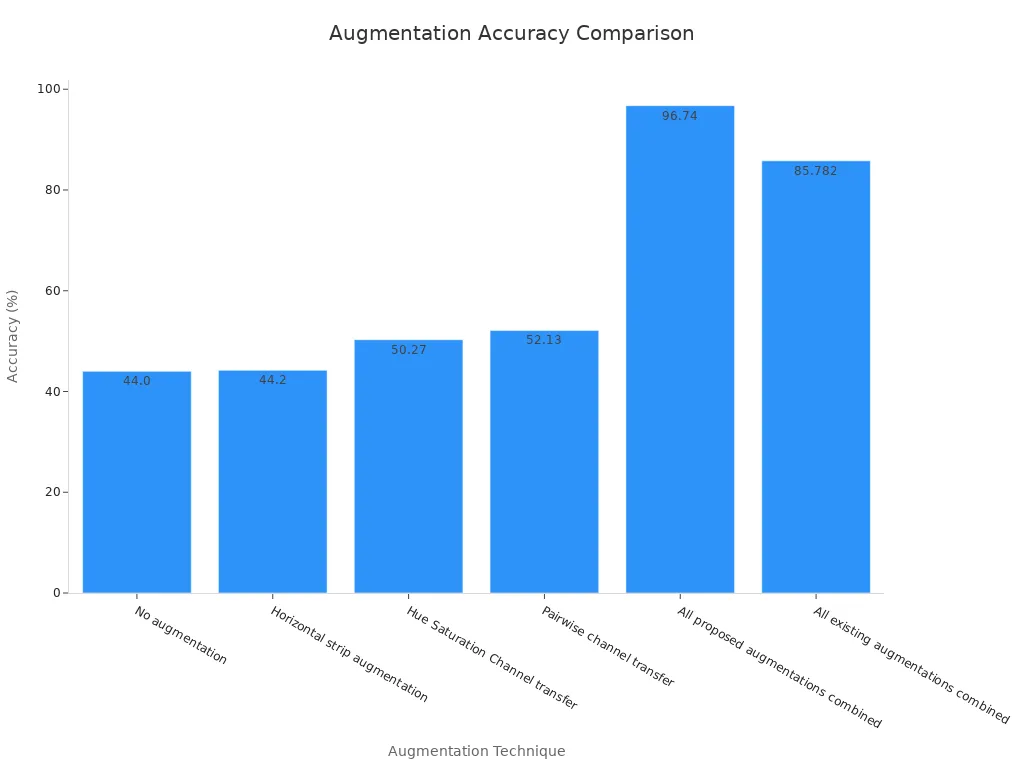
Role of Image Data Augmentation in a Computer Vision Pipeline
Image data augmentation plays a crucial role in enhancing the performance of a computer vision pipeline. It addresses challenges like data scarcity, class imbalance, and overfitting. For example, in a case study on object detection, applying transformations like resizing, cropping, and inverse adjustments improved accuracy by over 50%. Precision increased by 14%, and recall improved by 1%.
By integrating augmentation into preprocessing and feature extraction stages, you ensure your model encounters diverse scenarios during training. This not only boosts accuracy but also enhances the model’s ability to handle complex tasks like semantic segmentation and object recognition. Ultimately, a well-designed augmentation strategy strengthens the entire pipeline, from image acquisition to classification.
Steps to Build a Data Augmentation Pipeline
Step 1: Define Objectives for the Pipeline
Before building a data augmentation pipeline, you need to define clear objectives. These objectives guide the design and implementation of the pipeline, ensuring it aligns with your machine vision system’s requirements.
To set effective objectives, consider using methodologies supported by quantitative data:
-
Service Level Agreements (SLAs): Establish formal commitments regarding data quality, availability, and reliability.
-
Service Level Indicators (SLIs): Measure data quality with metrics like the time difference between data entry and current time.
-
Service Level Objectives (SLOs): Set target values for SLIs, such as ensuring 95% of data updates occur within a specific timeframe.
For example, if your goal is to improve object detection accuracy, your pipeline should focus on generating augmented images that simulate real-world conditions. This ensures your deep learning models learn to recognize objects in diverse scenarios.
Tip: Clearly defined objectives help you prioritize the right transformations and avoid unnecessary complexity in your pipeline.
Step 2: Select Appropriate Data Augmentation Techniques
Choosing the right data augmentation techniques is crucial for achieving your pipeline’s objectives. Different techniques impact model performance in unique ways, depending on the dataset and task.
Here’s a comparison of popular techniques and their effectiveness:
|
Data Augmentation Method |
Impact on Model Performance |
Dataset Characteristics |
|---|---|---|
|
MLS |
Positive influence on F1-Scores |
Varies by dataset |
|
Gaussian noise |
Enhances generalization capabilities |
Effective for imbalanced datasets |
|
Random rotating |
Performance varies significantly |
Dependent on defect sizes |
|
Image transpose |
Consistent performance improvement |
Effective across various datasets |
|
Random perspective |
Shows versatility in performance |
Adaptable to dataset properties |
|
Salt & pepper noise |
Limited impact on performance |
Less effective for complex datasets |
|
Affine transformation |
Strong performance boost |
Effective for diverse datasets |
|
Perspective transformation |
Robust across different tasks |
Tailored to specific dataset needs |
For tasks like object detection, geometric transformations such as random rotating and affine transformations often yield significant improvements. On the other hand, color-based techniques like Gaussian noise can enhance generalization, especially for datasets with class imbalances.
Note: Always test multiple techniques to identify the ones that work best for your training dataset.
Step 3: Implement Image Data Augmentation
Once you’ve selected the techniques, it’s time to implement image data augmentation. This step involves applying transformations to your dataset using tools or libraries designed for data augmentation for images.
Start by loading your dataset and applying basic transformations like rotation, scaling, and flipping. These techniques create augmented images that mimic real-world variations. For example, flipping an image horizontally can simulate different viewing angles, while scaling adjusts the size of objects to reflect varying distances.
Here’s a simple Python code snippet to implement image data augmentation using a popular library:
from torchvision import transforms
# Define augmentation transformations
augmentation_pipeline = transforms.Compose([
transforms.RandomRotation(30),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
])
# Apply transformations to an image
augmented_image = augmentation_pipeline(original_image)
Advanced techniques like random perspective and affine transformations can further enhance your dataset. These methods generate augmented images that challenge your deep learning models to adapt to diverse scenarios.
Tip: Automate the augmentation process to save time and ensure consistency across your training dataset.
Step 4: Integrate the Pipeline into a Computer Vision Workflow
Once you’ve implemented your data augmentation pipeline, the next step is to integrate it into your computer vision workflow. This ensures that the augmented data flows seamlessly into your training and evaluation processes, enhancing the overall performance of your machine vision system.
Here’s how you can approach this integration:
-
Connect the Augmentation Pipeline to Data Loading
Use a data loader to feed your augmented images directly into the training process. Libraries like PyTorch and TensorFlow provide tools to combine augmentation with data loading. This step ensures that transformations are applied dynamically during training, saving storage space and time.from torch.utils.data import DataLoader from torchvision import datasets, transforms # Define augmentation transformations augmentation_pipeline = transforms.Compose([ transforms.RandomRotation(20), transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.3, contrast=0.3), ]) # Load dataset with augmentation dataset = datasets.ImageFolder("path_to_images", transform=augmentation_pipeline) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) -
Integrate with Preprocessing Stages
Ensure that the augmented images align with the preprocessing steps in your computer vision pipeline. For example, if your model requires images of a specific size, resize the augmented images before feeding them into the pipeline. -
Incorporate Augmentation into Model Training
Augmented data should be part of your training loop. This step improves model generalization by exposing the model to diverse scenarios. For tasks like object detection or classification, this approach helps the model adapt to real-world variations. -
Test the Integration
Validate the pipeline by running a small batch of augmented images through the workflow. Check for errors in transformations, data loading, and preprocessing. This step ensures that the pipeline functions smoothly without disrupting the training process.
Tip: Automate the integration process using scripts or configuration files. This reduces manual errors and ensures consistency across experiments.
Step 5: Evaluate and Optimize the Pipeline
After integrating the data augmentation pipeline, you need to evaluate its impact on your model’s performance. This step helps you identify areas for improvement and fine-tune the pipeline for better results.
Steps to Evaluate the Pipeline:
-
Measure Model Performance
Train your model using the augmented dataset and compare its performance against a baseline model trained on the original dataset. Metrics like accuracy, precision, and recall can help you assess the effectiveness of the pipeline. -
Analyze the Impact of Transformations
Evaluate how individual transformations affect your model. For example, you might find that random rotations improve accuracy for classification tasks, while color jittering has minimal impact. -
Check for Overfitting
Monitor your model’s performance on validation data. If the model performs well on training data but poorly on validation data, it might be overfitting. Adjust the augmentation techniques to address this issue.
Steps to Optimize the Pipeline:
-
Experiment with Different Techniques
Test various transformations to find the optimal combination for your dataset. For instance, affine transformations might work better for object detection, while color-based techniques could enhance classification tasks. -
Adjust Parameters
Fine-tune the parameters of your transformations. For example, you can modify the rotation angle or brightness range to better suit your dataset. -
Automate Evaluation
Use tools like grid search or automated machine learning (AutoML) to test multiple configurations of the pipeline. This approach saves time and ensures a thorough evaluation. -
Iterate and Refine
Continuously refine your pipeline based on evaluation results. Incorporate feedback from model performance metrics to make data-driven improvements.
Note: Regularly update your pipeline to incorporate new augmentation techniques and adapt to changes in your dataset or task requirements.
By evaluating and optimizing your data augmentation pipeline, you ensure that it consistently improves model generalization and enhances the overall performance of your computer vision pipeline.
Tools and Libraries for Data Augmentation in 2025

Overview of Tools for Building a Data Augmentation Pipeline
Building a data augmentation pipeline requires tools that simplify the process while offering flexibility and scalability. In 2025, advancements in automation and machine learning have made these tools more accessible and efficient. You can choose from a variety of options, ranging from open-source libraries to enterprise-grade platforms.
Modern tools focus on automating augmentation operations, reducing the need for manual intervention. For instance, methods like AutoAugment and FastAA optimize augmentation operations by learning transformation-dependent attributes directly from the data. This approach eliminates the tedious process of manually selecting augmentations and ensures superior performance.
-
Why Automation Matters:
-
Manual methods demand significant domain expertise.
-
The vast space of possible augmentations makes manual incorporation impractical.
-
Automated tools learn augmentations from data, often outperforming fixed methods.
-
Recent reviews and case studies highlight the effectiveness of automated tools. AutoAugment simplifies the search space by associating magnitudes to each operation, while DDAS reduces computational demand by treating different magnitudes as unique augmentations. These innovations make it easier for you to build robust pipelines without extensive computational resources.
|
Method |
Description |
|---|---|
|
AutoAugment |
Associates magnitudes to operations, simplifying the search space. |
|
FastAA |
Optimizes augmentation operations for better performance. |
|
DDAS |
Reduces computational demand by treating magnitudes as unique augmentations. |
Features of Leading Libraries for Image Data Augmentation
Libraries for image data augmentation have evolved significantly, offering features tailored to diverse machine vision tasks. Whether you’re working on image segmentation, classification, or object detection, these libraries provide tools to enhance your datasets effectively.
Some of the most popular libraries include TensorFlow, PyTorch, and Albumentations. Each offers unique features that cater to specific needs:
-
TensorFlow:
TensorFlow’stf.imagemodule provides a wide range of augmentation techniques, including random cropping, flipping, and brightness adjustments. It integrates seamlessly into your computer vision pipeline, allowing dynamic augmentation during training. -
PyTorch:
PyTorch’storchvision.transformsmodule is highly versatile. It supports geometric and color-based transformations, making it ideal for tasks like image acquisition and preprocessing. Its integration with data loaders ensures efficient handling of augmented datasets. -
Albumentations:
Albumentations is known for its speed and flexibility. It offers advanced transformations like random perspective and affine adjustments, which are particularly useful for deep learning models. Its user-friendly API makes it easy to implement complex augmentation strategies.
These libraries also support automation, enabling you to focus on model development rather than manual data preparation. By leveraging their features, you can create diverse datasets that improve the generalization of your computer vision models.
Comparison of Tools for Different Machine Vision Use Cases
Choosing the right tool depends on your specific use case. Some platforms excel in object detection, while others are better suited for classification or image segmentation. Here’s a comparison of popular tools based on their features and advantages:
|
Platform |
Key Features |
Use Cases |
Advantages |
|---|---|---|---|
|
Roboflow |
Access to 90,000 public datasets |
Aerospace, Automotive |
Cost-effective, rapid deployment |
|
Amazon SageMaker |
Comprehensive machine learning tools |
Various industries |
Scalable, flexible, AWS integration |
|
Google Cloud Vertex AI |
AI model training and deployment |
Retail, Healthcare |
User-friendly, strong Google integration |
|
Microsoft Azure Machine Learning |
End-to-end machine learning lifecycle |
Finance, Manufacturing |
Robust security, enterprise-ready solutions |
Roboflow stands out for its extensive dataset library, featuring 60 million images and 805 labels across seven domains. It’s optimized for object detection and offers benchmarks to evaluate performance across different datasets. Competitors like Amazon SageMaker and Google Cloud Vertex AI provide scalable solutions for training and deploying deep learning models, while Microsoft Azure focuses on enterprise-grade security and lifecycle management.
When selecting a tool, consider the nature of your task and the resources available. For example, Roboflow’s rapid deployment capabilities make it ideal for aerospace applications, while Google Cloud Vertex AI’s user-friendly interface suits retail and healthcare projects.
Tip: Evaluate tools based on their compatibility with your existing workflow and the specific requirements of your machine vision system.
Best Practices for a Data Augmentation Pipeline
Balancing Augmentation Diversity and Computational Efficiency
Balancing diversity in data augmentation with computational efficiency is essential for building an effective pipeline. You can achieve this by adopting adaptive modulation techniques. These methods adjust augmentation magnitudes dynamically based on real-time feedback from your model. This approach enhances generalization capabilities without overloading computational resources.
To start, focus on minimal and carefully selected transformations. Gradually add layers of augmentation while systematically assessing your model’s performance. Tailor the techniques to your specific problem domain. For example, object detection tasks may benefit from geometric transformations, while classification tasks might require color-based adjustments.
Tracking validation accuracy and monitoring generalization performance are critical. Compare results across different augmentation intensities to identify the optimal balance. This iterative process ensures your pipeline remains efficient while enhancing robustness.
Avoiding Overfitting with Data Augmentation
Data augmentation reduces overfitting by increasing the size and diversity of your dataset. Transformations like rotations, flips, and scaling expose your model to a wider variety of scenarios. This process enhances robustness against variations in input data and improves generalization.
For image processing tasks, diverse training examples play a key role. By simulating real-world conditions, augmentation helps your model adapt to unseen data. For instance, flipping an image horizontally can mimic different viewing angles, while random rotations simulate varied orientations. These techniques ensure your model learns patterns rather than memorizing specific examples.
To avoid overfitting, monitor your model’s performance on validation data. If overfitting persists, experiment with additional transformations or adjust augmentation parameters. Regular evaluation helps maintain a balance between diversity and model accuracy.
Ensuring Data Quality in a Machine Vision System
Maintaining data quality is crucial for a successful machine vision system. Augmented datasets must meet high standards of accuracy and consistency. Use quality metrics to ensure data integrity throughout the pipeline.
|
Metric/Indicator |
Description |
|---|---|
|
Error detection rate |
Tracks the percentage of mislabeled, missing, or inconsistent annotations detected by the system. |
|
Annotation consistency score |
Measures alignment of annotations with predefined guidelines, comparing automatic and human verification. |
|
Reduced manual verification time |
Assesses efficiency gains by comparing time spent on manual reviews before and after automation. |
|
Rework rate |
Tracks how often annotations need correction after automated checks; a decrease indicates improved quality. |
By monitoring these metrics, you can identify and address issues early. Reduced manual verification time and a lower rework rate indicate a well-optimized pipeline. Regular audits and automated checks further enhance data quality, ensuring your system performs reliably.
A well-structured data augmentation pipeline is essential for building high-performing machine vision systems in 2025. It helps you overcome data limitations, improve model accuracy, and enhance generalization. By following the outlined steps—defining objectives, selecting techniques, implementing transformations, integrating the pipeline, and optimizing it—you can create a robust system. Tools like TensorFlow, PyTorch, and Albumentations simplify this process, while best practices ensure efficiency and quality. Stay informed about new techniques and tools to keep your pipeline effective and competitive.
FAQ
What is the main purpose of a data augmentation pipeline?
A data augmentation pipeline helps you expand your dataset by creating variations of existing images. This process improves your model’s ability to generalize and perform well on unseen data, especially when your original dataset is limited.
How do you choose the right augmentation techniques?
You should select techniques based on your task and dataset. For example, geometric transformations like rotation work well for object detection, while color adjustments suit classification tasks. Testing multiple techniques helps you identify the most effective ones.
Can data augmentation prevent overfitting?
Yes, it can. By exposing your model to diverse scenarios, augmentation reduces the risk of overfitting. It ensures your model learns patterns instead of memorizing specific examples, improving its performance on new data.
What tools are best for implementing data augmentation?
Popular tools include TensorFlow, PyTorch, and Albumentations. These libraries offer a wide range of transformations and integrate seamlessly into machine vision workflows. They simplify the process and save you time.
How do you evaluate the effectiveness of a data augmentation pipeline?
You can evaluate it by comparing your model’s performance metrics, like accuracy and precision, before and after applying augmentation. Regular testing ensures your pipeline remains effective and aligned with your goals.
See Also
Essential Insights on Synthetic Data for AI Inspection Models
Exploring New Opportunities in Machine Vision with Synthetic Data
The Evolution of Segmentation in Machine Vision Systems
How AI-Driven Machine Vision Systems Are Changing Industries Now
Anticipating the Future of Component Counting Vision Technologies








