
Feature engineering in a machine vision system plays a vital role in transforming raw visual data into meaningful representations that machine learning models can effectively interpret. This process is a critical step in computer vision tasks, bridging the gap between unstructured data and structured inputs for the models. Research underscores the importance of feature engineering in a machine vision system, showing its ability to enhance model accuracy significantly. For example, systematic feature engineering within a machine vision system improved classification performance, boosting AUROC from 0.62 to 0.82 in predicting patient falls. By ensuring that machine learning models analyze images more effectively, this approach leads to more accurate predictions and better decision-making.
Key Takeaways
- Feature engineering changes raw image data into useful inputs. This helps machine learning models work better in computer vision tasks.
- Important steps include creating, choosing, and resizing features. These steps make complex images easier to understand for the model.
- Tools like OpenCV and Featuretools can help beginners by automating feature engineering.
- Good feature extraction and changes make models predict better. Techniques like finding edges and reducing dimensions are very important.
- Fixing unusual data and resizing features helps models read data correctly. This leads to more accurate results.
Features in Machine Vision Systems
What Are Features in Machine Vision?
Features in machine vision represent the measurable attributes or patterns extracted from visual data. These attributes help you describe an image in a way that machine learning models can understand. For example, features might include edges, textures, shapes, or colors within an image. These elements act as the building blocks for computer vision tasks, enabling systems to interpret and analyze visual information effectively.
In feature engineering, you focus on identifying and refining these attributes to improve the performance of machine learning models. For instance, extracting edges from an image can help a model detect objects, while analyzing textures might assist in distinguishing between different materials. By transforming raw visual data into structured features, you make it easier for models to learn and make predictions.
Why Are Features Critical for Machine Vision Systems?
Features are the foundation of any successful machine vision system. Without them, machine learning models would struggle to process and understand visual data. Features simplify complex images into manageable components, allowing models to focus on the most relevant information.
Research highlights the importance of features in ensuring effective machine vision processing. For example:
| Feature/Method | Description | Impact |
|---|---|---|
| Shape-based matching | Determines position and orientation of 3D objects using CAD models. | Boosts speed, robustness, and accuracy in matching methods. |
| Deep 3D Matching | Utilizes deep learning networks trained on CAD models. | Enhances performance in industrial applications. |
| Extended Parameter Estimation | Automates parameter estimation for matching applications. | Simplifies complex tasks for newcomers in machine vision. |
Additionally:
- Feature selection optimizes model performance by identifying relevant features.
- Systems like FeatureEnVi enhance predictive performance while minimizing computational costs.
- Real-world datasets show that fewer, well-tuned features lead to faster training and improved results.
By focusing on feature engineering, you ensure that computer vision systems operate efficiently and deliver accurate results. Whether you’re working on object detection or image classification, well-designed features are essential for success.
Processes in Feature Engineering for Machine Vision
Feature Creation
Feature creation involves generating new features from raw visual data to enhance the predictive power of machine learning models. This process allows you to uncover hidden patterns or relationships that might not be immediately apparent in the original data. For example, you can combine existing features, such as color and texture, to create a new feature that better represents the image’s content.
In machine vision systems, feature creation often relies on domain knowledge. For instance, when analyzing small metal objects, combining Histogram of Oriented Gradients (HOG) and Local Binary Patterns (LBP) can improve classification results. Studies show that HOG outperforms LBP individually, but their combination yields even better accuracy. This highlights the importance of thoughtful feature creation in improving model performance and robustness.
To get started with feature creation, consider the following approaches:
- Combining Features: Merge related features to create more meaningful representations.
- Deriving New Features: Use mathematical operations, such as ratios or differences, to generate additional insights.
- Domain-Specific Features: Leverage knowledge of the problem domain to design features tailored to your task.
By focusing on feature creation, you can provide machine learning models with richer inputs, leading to better predictive outcomes.
Feature Transformation
Feature transformation modifies existing features to make them more suitable for machine learning models. This process often involves data preprocessing techniques, such as scaling, normalization, or encoding, to ensure that features are in a format that models can interpret effectively. Transformation enhances the robustness of your system by reducing noise and improving consistency across datasets.
Empirical studies demonstrate the benefits of feature transformation. For example, a comparison of two machine learning architectures for vision tasks revealed that shared-type systems consumed less energy and responded faster than parallel-type systems. However, parallel-type systems offered higher throughput and fault tolerance. These findings suggest that transforming features can optimize performance metrics like energy efficiency and reliability.
Common feature transformation techniques include:
- Scaling: Adjust feature values to a specific range, such as 0 to 1, to prevent large values from dominating the model.
- Normalization: Rescale data to have a mean of 0 and a standard deviation of 1, improving model convergence during training.
- Encoding: Convert categorical data into numerical formats, such as one-hot encoding, for better compatibility with machine learning algorithms.
Feature transformation ensures that your data is well-prepared for analysis, ultimately boosting the effectiveness of your machine vision system.
Feature Extraction
Feature extraction focuses on identifying and isolating the most relevant attributes from raw data. This step reduces the dimensionality of the dataset while retaining the critical information needed for accurate predictions. In machine vision, feature extraction often involves techniques like edge detection, texture analysis, or shape recognition.
Research highlights the impact of feature extraction on accuracy. For instance, a study achieved a highest accuracy of 0.89 by combining Hamming-windowed streamline feature extraction with a Decision Tree algorithm. This demonstrates how effective feature extraction can significantly enhance predictive performance.
Key methods for feature extraction in machine vision include:
- Edge Detection: Identify boundaries within an image to highlight shapes and objects.
- Texture Analysis: Examine patterns in pixel intensity to differentiate between materials or surfaces.
- Dimensionality Reduction: Use techniques like Principal Component Analysis (PCA) to simplify data while preserving essential features.
By applying feature extraction, you can streamline your data and improve the robustness of your machine learning models. This step is crucial for achieving high accuracy in computer vision tasks.
Feature Selection
Feature selection is the process of identifying the most relevant features in your dataset to improve the performance of machine learning models. By focusing on the most important attributes, you reduce the complexity of your data, which speeds up training and enhances predictive accuracy. This step is essential in machine vision systems, where datasets often contain thousands of features extracted from images.
When you apply feature selection, you eliminate redundant or irrelevant features that may negatively impact model performance. For example, selecting only the most informative features can prevent overfitting, where a model performs well on training data but poorly on unseen data. This ensures your machine learning models generalize better to new inputs.
Several methods exist for feature selection, ranging from statistical techniques to advanced algorithms. These include:
- Filter Methods: Use statistical tests to rank features based on their correlation with the target variable.
- Wrapper Methods: Evaluate subsets of features by training and testing machine learning models to find the optimal combination.
- Embedded Methods: Integrate feature selection into the model training process, such as using regularization techniques like Lasso regression.
Quantitative analysis highlights the benefits of feature selection in machine vision systems. For instance:
- The hybrid V-WSP-PSO method reduced the number of features from 27,620 to just 114, significantly lowering dimensionality.
- This method achieved a root mean square error of cross-validation (RMSECV) of 0.4013 MJ/kg and a determination coefficient (RCV2) of 0.9908, demonstrating high predictive performance.
By implementing feature selection, you streamline data preparation and improve the efficiency of your machine learning models. This step is particularly valuable in applications like image classification and object detection, where large datasets can overwhelm computational resources.
Feature Scaling
Feature scaling ensures that the numerical values of your features are consistent and comparable across the dataset. In machine vision systems, images often contain pixel intensity values or measurements that vary widely in scale. Without scaling, these differences can distort the learning process of machine learning models, leading to suboptimal results.
Scaling methods adjust feature values to a specific range or distribution, making them more suitable for machine learning algorithms. For example, scaling prevents features with larger numerical ranges from dominating the model’s predictions. This step is crucial for algorithms like Support Vector Machines (SVMs) and k-Nearest Neighbors (k-NN), which rely on distance calculations.
Common feature scaling techniques include:
- Min-Max Scaling: Rescales feature values to a range between 0 and 1.
- Standardization: Adjusts data to have a mean of 0 and a standard deviation of 1.
- Robust Scaling: Uses the median and interquartile range to scale features, reducing the impact of outliers.
Feature scaling plays a vital role in data preparation for machine learning models. For instance, when training a neural network for image classification, scaling pixel values to a range of 0 to 1 ensures faster convergence and better accuracy. Similarly, scaling features in object detection tasks improves the model’s ability to identify objects across varying scales.
By incorporating feature scaling into your workflow, you enhance the consistency and reliability of your machine learning models. This step ensures that your models interpret features effectively, leading to improved predictions and overall performance.
Feature Engineering Techniques for Machine Vision
One-Hot Encoding
One-hot encoding is a popular technique for converting categorical data into numerical formats that machine learning algorithms can process. In computer vision tasks, this method is often used to encode labels or metadata associated with images. For example, if you have three categories—cat, dog, and bird—one-hot encoding represents them as [1, 0, 0], [0, 1, 0], and [0, 0, 1], respectively.
This technique ensures that machine learning models treat categories as distinct entities rather than ordinal values. However, one-hot encoding can increase computational complexity, especially when dealing with large datasets or higher k-mer sizes. Case studies comparing one-hot encoding with frequency-based tokenization highlight these trade-offs:
| Encoding Method | k-mer Size | Training Time | Testing Accuracy |
|---|---|---|---|
| One-hot Encoding | 1-mer | Higher | 95% |
| One-hot Encoding | 2-mer | Higher | 96% |
| Frequency-based Tokenization | 1-mer | Lower | 97% |
| Frequency-based Tokenization | 2-mer | Lower | 96% |
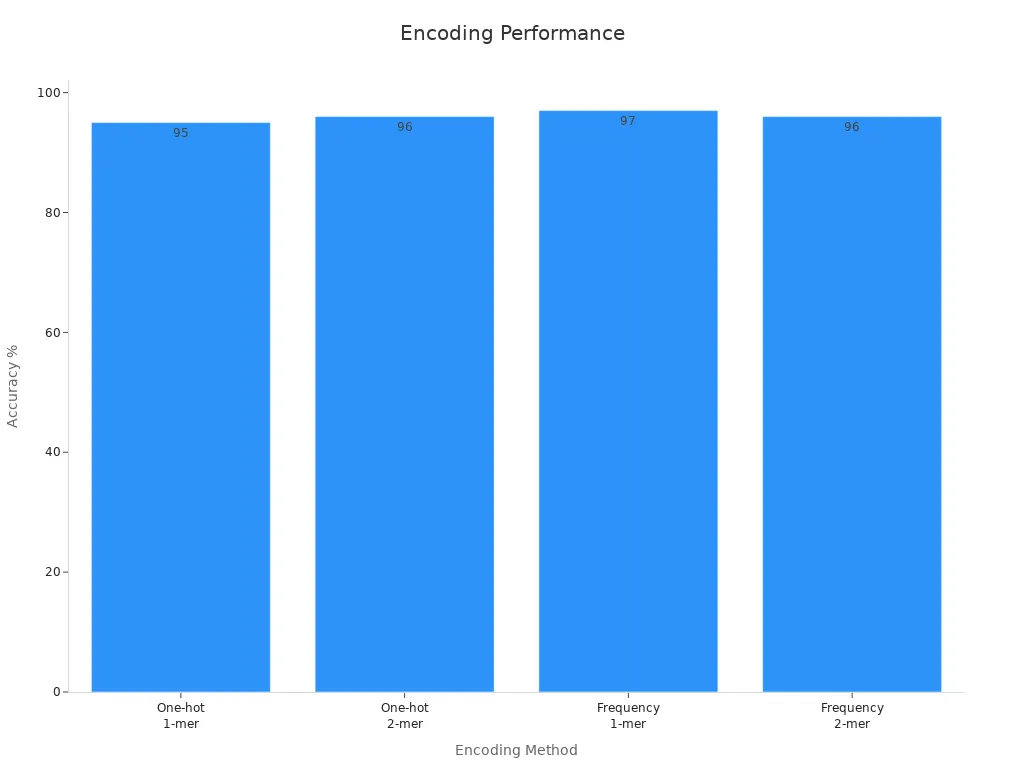
While one-hot encoding achieves comparable accuracy, it demands more computational resources. You should consider the size of your dataset and the complexity of your machine vision task when choosing an encoding method.
Binning
Binning is a technique used to group continuous data into discrete intervals or "bins." In machine vision, binning can improve feature robustness by reducing noise and ensuring consistency across datasets. For example, when analyzing pixel intensity values, binning helps standardize variations caused by differences in lighting or camera settings.
Data segmentation experiments demonstrate the effectiveness of binning in enhancing feature robustness. Key findings include:
| Evidence Description | Details |
|---|---|
| Impact of GL Quantisation | The study shows that the choice of grey level quantisation (GLs) significantly affects the distribution of intensity values and the calculated GL matrices, which are crucial for radiomic feature extraction. |
| Optimal GL Range | Results indicate that the optimal quantisation should be in the range of 32-64 GLs, supporting the use of binning to enhance feature robustness. |
| Freedman–Diaconis Rule | The application of this statistical rule helped determine an optimal number of bins (40), which was effective in minimizing differences across heterogeneous slice thicknesses. |
By applying binning, you can create more stable and reliable features for machine learning models. This technique is particularly useful in tasks like texture analysis, where consistent feature extraction is critical for accurate predictions.
Scaling Methods
Scaling methods adjust the numerical range of features to ensure consistency across datasets. In machine vision, scaling is essential for handling pixel intensity values or measurements that vary widely. Without scaling, these differences can skew the learning process of machine learning models.
Common scaling methods include:
- Min-Max Scaling: Rescales values to a range between 0 and 1.
- Standardization: Adjusts data to have a mean of 0 and a standard deviation of 1.
- Robust Scaling: Uses the median and interquartile range to reduce the impact of outliers.
For example, when training a neural network for image classification, scaling pixel values to a range of 0 to 1 ensures faster convergence and better accuracy. Similarly, scaling features in object detection tasks improves the model’s ability to identify objects across varying scales.
Scaling methods play a vital role in feature engineering techniques. By ensuring that features are consistent and comparable, you enhance the reliability of machine learning models and improve their predictive performance.
Handling Outliers
Outliers are data points that deviate significantly from the rest of your dataset. In machine vision, these anomalies can arise due to issues like sensor errors, lighting variations, or occlusions in images. If left unaddressed, outliers can distort the learning process of machine learning models, leading to inaccurate predictions.
You can handle outliers effectively by employing techniques that identify and mitigate their impact. Common approaches include:
- Statistical Methods: Use measures like the interquartile range (IQR) to detect outliers. For example, pixel intensity values that fall outside 1.5 times the IQR can be flagged as anomalies.
- Clipping: Limit feature values to a predefined range. This method ensures that extreme values do not dominate the model’s learning process.
- Transformation: Apply logarithmic or square root transformations to reduce the influence of outliers.
Machine vision tasks often benefit from robust outlier handling. For instance, when analyzing medical images, removing outliers can improve the accuracy of disease detection models. Similarly, in object detection, addressing outliers ensures that models focus on relevant features rather than noise.
Tip: Always visualize your data before handling outliers. Techniques like box plots or scatter plots can help you identify anomalies and decide on the best approach for mitigation.
By addressing outliers, you enhance the reliability of your machine learning models and ensure that your feature engineering process produces consistent results.
Dimensionality Reduction
Dimensionality reduction simplifies complex datasets by reducing the number of features while retaining essential information. In machine vision, this process is crucial for managing high-dimensional data, such as images with thousands of pixels. Reducing dimensionality not only speeds up model training but also minimizes the risk of overfitting.
Several techniques can help you reduce dimensionality effectively:
- Principal Component Analysis (PCA): This method identifies the most significant features in your dataset and projects them onto a lower-dimensional space. PCA is widely used as a preprocessing step in machine vision tasks, enhancing performance by eliminating redundant features.
- t-SNE: This technique excels at visualizing high-dimensional data, making it ideal for exploratory analysis. However, its computational intensity may limit its use in large-scale applications.
- Linear Discriminant Analysis (LDA): LDA works well for supervised learning tasks by maximizing the separation between classes. It requires labeled data to function effectively.
- Autoencoders: These neural networks learn complex representations of data and can reduce dimensionality while preserving important features. Careful tuning of the architecture is essential for optimal results.
| Method | Advantages | Limitations |
|---|---|---|
| PCA | Reduces dimensionality effectively | Assumes linear relationships |
| t-SNE | Excellent for visualizing high-dimensional data | Computationally intensive |
| LDA | Works well for supervised learning | Requires class labels |
| Autoencoders | Can learn complex representations | Requires careful tuning of architecture |
Sequential applications of dimensionality reduction techniques can lead to marked improvements in machine vision tasks. For example, using PCA before applying classifiers often enhances performance. These techniques are vital for simplifying complex data, ensuring that your machine learning models focus on the most relevant features.
Note: Dimensionality reduction is not just about removing features. It’s about retaining the features that matter most for your task. Always evaluate the impact of reduced dimensions on model accuracy.
By incorporating dimensionality reduction into your feature engineering workflow, you streamline data preparation and improve the efficiency of your machine learning models.
Tools for Feature Engineering in Machine Vision Systems
Featuretools
Featuretools simplifies feature engineering by automating the creation of new features from raw data. It uses a technique called "deep feature synthesis" to generate features based on relationships between datasets. This tool works well for machine vision tasks where structured data accompanies images, such as metadata or annotations.
You can use Featuretools to create features like counts, averages, or trends from related datasets. For example, if you’re analyzing images of products, Featuretools can calculate the average price of items in a category or count the number of items sold. These features help machine learning models understand patterns and improve predictions.
Featuretools integrates seamlessly with Python, making it accessible for beginners. Its ability to automate feature creation saves time and reduces manual effort. By using this tool, you can focus on building better models instead of spending hours crafting features.
TPOT
TPOT, or Tree-based Pipeline Optimization Tool, automates the process of selecting and optimizing features for machine learning models. It uses genetic algorithms to test different combinations of features and preprocessing steps, ensuring the best configuration for your task.
This tool excels in machine vision applications where feature selection plays a critical role. For example, TPOT evaluates features like pixel intensity or texture patterns to determine their importance. It assigns predictive ranks to features, helping you identify which ones contribute most to model accuracy.
| Feature Evaluation | Methodology | Outcome |
|---|---|---|
| Predictive Ranks | TPOT models generated predictive ranks for feature importance | Evaluated model performance using R², indicating accuracy |
| Confounding Features | Evaluated features like BMI and batch effects using TPOT classification | Assigned predictive ranks and measured feature importance |
| Metabolite Analysis | Classification TPOT analysis on reduced-feature dataset | Reported training and testing set accuracy for various feature sets |
TPOT’s ability to optimize feature selection reduces the risk of overfitting and improves model reliability. By automating this process, you can achieve better results without extensive manual tuning.
H2O.ai
H2O.ai provides a suite of tools for machine learning, including feature engineering capabilities. Its AutoML platform automates tasks like feature selection, transformation, and scaling, making it ideal for machine vision projects.
You can use H2O.ai to preprocess image data efficiently. For instance, it can scale pixel values, handle missing data, and select the most relevant features for your model. These automated processes save time and ensure consistency across datasets.
H2O.ai supports large-scale applications, making it suitable for projects with extensive image datasets. Its integration with popular programming languages like Python and R allows you to customize workflows while leveraging its powerful automation features.
By incorporating H2O.ai into your machine vision pipeline, you can streamline feature engineering and focus on building accurate models.
OpenCV
OpenCV, or Open Source Computer Vision Library, is one of the most popular tools for feature engineering in machine vision systems. It provides a wide range of functions to process and analyze images, making it an essential resource for beginners and experts alike. You can use OpenCV to extract features, transform data, and prepare images for machine learning models.
Why Choose OpenCV?
OpenCV stands out because of its versatility and ease of use. It supports multiple programming languages, including Python, C++, and Java, allowing you to integrate it into your preferred workflow. Its extensive library includes tools for tasks like edge detection, object tracking, and image segmentation. These features help you simplify complex visual data into meaningful components.
Tip: OpenCV is open-source and free to use. You can download it from OpenCV.org and start experimenting with its features right away.
Key Features for Machine Vision
Here are some of the most useful OpenCV functions for feature engineering:
- Edge Detection: Use the
cv2.Canny()function to identify edges in an image. This helps you highlight shapes and boundaries. - Histogram Analysis: Apply
cv2.calcHist()to analyze pixel intensity distributions. This is useful for tasks like texture analysis. - Feature Matching: Utilize
cv2.BFMatcher()to compare features between images, which is essential for object recognition. - Image Transformation: Use functions like
cv2.resize()andcv2.warpAffine()to scale or rotate images for better model compatibility.
Example Code
Here’s a simple example of edge detection using OpenCV in Python:
import cv2
import matplotlib.pyplot as plt
# Load an image
image = cv2.imread('example.jpg', cv2.IMREAD_GRAYSCALE)
# Apply Canny edge detection
edges = cv2.Canny(image, threshold1=100, threshold2=200)
# Display the result
plt.imshow(edges, cmap='gray')
plt.title('Edge Detection')
plt.show()
This code demonstrates how you can extract edges from an image, a crucial step in feature engineering for tasks like object detection.
Practical Applications
OpenCV is widely used in applications such as facial recognition, autonomous vehicles, and industrial inspection. Its ability to process images efficiently makes it a go-to tool for feature engineering in machine vision projects. By mastering OpenCV, you can unlock the full potential of your visual data and build more accurate machine learning models.
Practical Applications of Feature Engineering in Machine Vision

Object Detection
Feature engineering plays a pivotal role in object detection by enabling models to identify and locate objects within images accurately. Through techniques like feature extraction, you can isolate critical attributes such as edges, textures, and shapes, which help the model distinguish between objects and their backgrounds. For instance, combining Histogram of Oriented Gradients (HOG) with color histograms can enhance the detection of objects in cluttered environments.
Real-world datasets demonstrate the effectiveness of feature engineering in challenging scenarios. The SBU Shadow Dataset, containing 100,000 images with shadows and noisy labels, has been instrumental in training models for object detection under difficult lighting conditions. This dataset highlights how engineered features can improve robustness and adaptability in computer vision tasks.
| Dataset Name | Description | Applications in Object Detection |
|---|---|---|
| SBU Shadow Dataset | A large-scale dataset with 100,000 images containing shadows and noisy labels. | Used to train models for object detection in challenging conditions. |
By leveraging feature engineering, you can optimize object detection systems for diverse applications, from autonomous vehicles to industrial inspection.
Facial Recognition
Facial recognition systems rely heavily on advanced feature engineering to achieve high accuracy. Techniques like dimensionality reduction and feature selection help isolate unique facial attributes, such as the distance between eyes or the shape of the jawline. These refined features enable models to differentiate between individuals effectively.
Comparative studies underline the impact of feature engineering on facial recognition accuracy. For example, a study published in PLOS One tested algorithms like Decision Tree, k-Nearest Neighbors (KNN), and Support Vector Machines (SVM). The results showed an impressive accuracy of 99.06%, with precision, recall, and specificity all exceeding 99%.
| Study | Algorithms Tested | Accuracy | Precision | Recall | Specificity |
|---|---|---|---|---|---|
| PLOS One | Decision Tree, KNN, SVM | 99.06% | 99.12% | 99.07% | 99.10% |
These findings emphasize the importance of well-engineered features in enhancing the reliability of facial recognition systems, particularly in security and authentication applications.
Image Classification
In image classification, feature engineering simplifies complex visual data into meaningful representations that models can process efficiently. Techniques like feature scaling and extraction ensure that the most relevant attributes, such as color gradients or texture patterns, are highlighted. This refinement improves the model’s ability to classify images accurately.
Statistical evaluations reveal the performance boost achieved through engineered features. For instance, a system using advanced feature engineering achieved an accuracy of 96.4% for classifying images. The chart below illustrates the system’s performance across different metrics, including its ability to identify the top 1 to top 5 objects in an image.
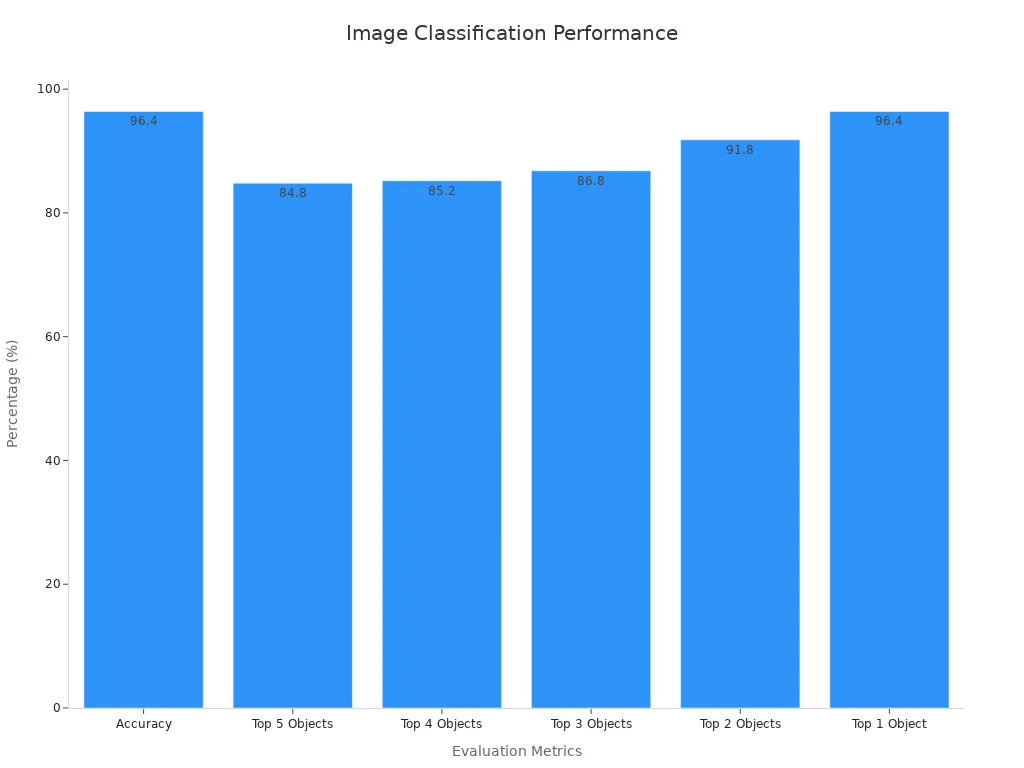
By focusing on feature engineering, you can enhance the precision and efficiency of image classification systems, making them suitable for applications like medical imaging and e-commerce.
Autonomous Vehicles
Autonomous vehicles rely heavily on feature engineering to interpret their surroundings and make safe decisions. These vehicles use cameras, LiDAR, and other sensors to collect raw visual data. Feature engineering transforms this data into meaningful inputs for machine learning models, enabling the vehicle to "see" and understand its environment.
One critical application of feature engineering in autonomous vehicles is object detection. By extracting features like edges, shapes, and textures, you help the vehicle identify objects such as pedestrians, traffic signs, and other vehicles. For example, edge detection algorithms can highlight lane markings, ensuring the car stays within its lane.
Another essential process is feature scaling. Autonomous vehicles often deal with data from multiple sensors, each with different scales. Scaling ensures that all features, such as distances from LiDAR and pixel intensities from cameras, are comparable. This step improves the accuracy of the vehicle’s decision-making systems.
Feature selection also plays a vital role. You can reduce the complexity of the data by focusing on the most relevant features, such as the speed of nearby vehicles or the color of traffic lights. This optimization speeds up processing and enhances the vehicle’s ability to react in real time.
Tip: Always test your feature engineering techniques in diverse environments. Autonomous vehicles must perform well in varying conditions, such as rain, fog, or heavy traffic.
Feature engineering ensures that autonomous vehicles operate safely and efficiently. By refining raw sensor data into actionable insights, you enable these vehicles to navigate complex environments and make split-second decisions. This technology is a cornerstone of the future of transportation.
Feature engineering in machine vision systems transforms raw visual data into structured inputs that improve model performance. It bridges the gap between computer vision tasks and machine learning models, ensuring higher accuracy in predictions. You explored processes like feature creation, selection, and scaling, along with techniques such as dimensionality reduction and handling outliers. Tools like OpenCV and Featuretools simplify these tasks, making feature engineering accessible. By applying these methods, you can enhance your machine vision projects and achieve better results. Start experimenting today to unlock the full potential of feature engineering.
FAQ
What is feature engineering in machine vision?
Feature engineering transforms raw visual data into meaningful attributes that machine learning models can process. It involves creating, selecting, and refining features like edges, textures, or shapes to improve model accuracy and efficiency.
Why is feature scaling important in machine vision?
Feature scaling ensures consistency in numerical values across datasets. It prevents large values from dominating the learning process, helping models interpret features effectively and improving predictions in tasks like image classification or object detection.
How does dimensionality reduction help in machine vision?
Dimensionality reduction simplifies datasets by removing redundant features while retaining essential information. This process speeds up model training, reduces computational costs, and minimizes overfitting, especially in high-dimensional data like images.
Which tools are best for feature engineering in machine vision?
Popular tools include OpenCV for image processing, Featuretools for automated feature creation, and H2O.ai for scaling and selection. These tools simplify workflows and enhance the efficiency of machine vision projects.
Can feature engineering improve facial recognition systems?
Yes, feature engineering isolates unique facial attributes like eye distance or jawline shape. Techniques like dimensionality reduction and feature selection enhance accuracy, making facial recognition systems more reliable for security and authentication.
See Also
The Role of Feature Extraction in Machine Vision Technology
An In-Depth Look at Machine Vision for Automation
Understanding Fundamental Concepts of Metrology in Machine Vision









