
Zero-shot learning lets a machine recognize objects it has never seen before by using descriptions or features learned from other objects. In computer vision, this means a model can spot a new animal by understanding how it looks compared to animals it already knows. For example, if a system knows what a horse looks like, it can identify a zebra by learning that a zebra is like a horse with stripes. This Zero-shot Learning machine vision system works because it transfers knowledge between classes and uses semantic information.
Zero-shot methods help AI save time and resources, as they do not need labeled examples for every new object. This leads to better data efficiency and makes AI seem more human-like in learning.
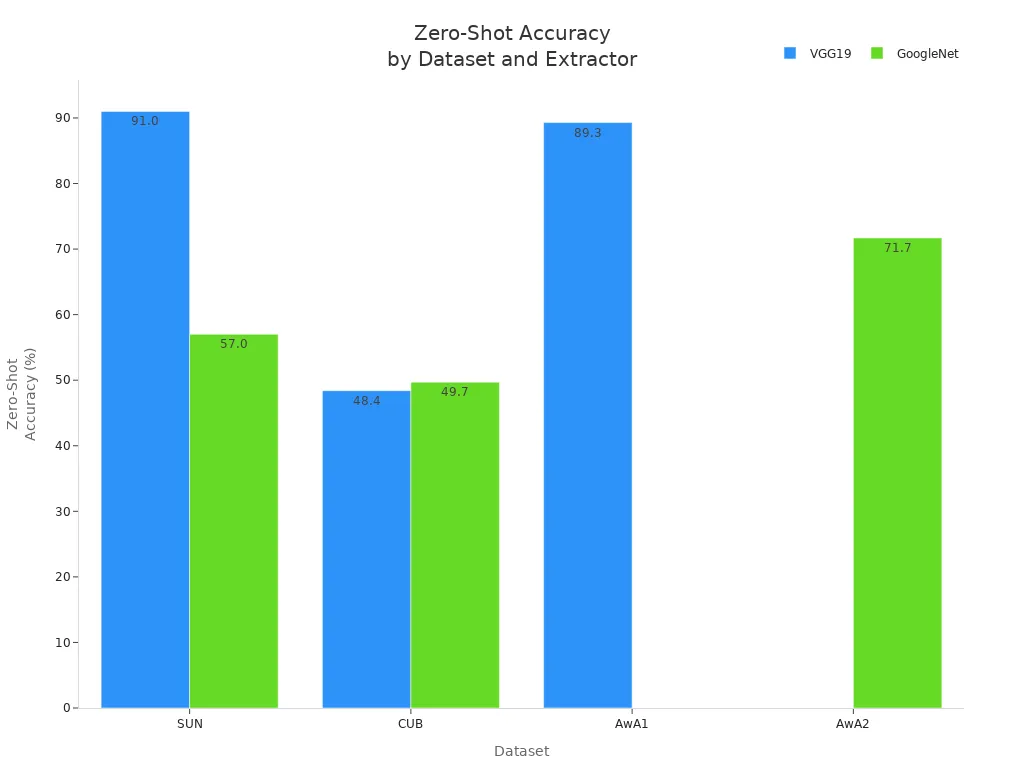
The results show that zero-shot learning can achieve high accuracy without extra labeled data, making it a breakthrough for machine vision.
Key Takeaways
- Zero-shot learning lets machines recognize new objects without needing labeled examples for each one, saving time and resources.
- This approach uses semantic information like descriptions and features to connect known and unknown classes, enabling better generalization.
- Methods such as attribute-based classification, semantic embeddings, and generative models help machines identify unseen objects effectively.
- Zero-shot learning improves real-world tasks like image classification, object detection, medical imaging, and industrial applications by adapting quickly to new data.
- Despite its strengths, zero-shot learning faces challenges like accuracy gaps and reliance on quality semantic data, but ongoing research continues to enhance its performance.
Zero-shot Learning in Machine Vision
What Is Zero-shot Learning?
Zero-shot learning is a machine learning technique that helps computers recognize objects or actions they have never seen before. In a zero-shot learning machine vision system, the model learns from examples it already knows and uses descriptions or features to identify novel classes. This approach stands out in computer vision because it does not require labeled images for every possible object. Instead, it uses semantic information, such as attributes or text descriptions, to connect what it knows with what it has not seen.
For example, if a model has learned about horses, it can recognize a zebra by understanding that a zebra is similar to a horse but has stripes. This process relies on knowledge transfer and generalization. The model links seen and unseen classes using shared semantic spaces, such as attribute vectors or word embeddings. Generative models like GANs and VAEs can even create features for novel classes, making the system more robust.
Zero-shot learning machine vision systems use several methods to achieve this:
- Attribute-based classification
- Semantic embeddings
- Knowledge graphs
- Natural language supervision
These methods allow the model to classify objects, detect actions, and understand human-object interactions, even when it encounters novel classes.
Why It Matters
Zero-shot learning changes how machine learning systems handle new information. Traditional supervised learning needs labeled data for every class, so it struggles with novel classes. Zero-shot learning, however, enables models to generalize beyond the training data. This ability is crucial for real-world applications where new objects or categories appear often.
The fusion of computer vision and natural language processing has led to major breakthroughs. Models like OpenAI’s CLIP use both images and text to understand and describe unseen objects. This approach allows AI to perform tasks such as image search, captioning, and content recommendation without needing labeled examples for every possible class.
Key breakthroughs in zero-shot learning for visual recognition include:
- Integration of semantic embeddings and heterogeneous data, linking seen and unseen classes.
- Deep learning techniques, such as convolutional neural networks, for rich feature extraction.
- Models like DeViSE, which map visual features to semantic word embeddings.
- Generative models that synthesize features for novel classes.
- Graph-based methods that use knowledge graphs to improve classification.
- Emerging trends like cross-modal learning and attention mechanisms, which help with real-world tasks such as medical imaging and wildlife tracking.
Zero-shot learning machine vision systems have achieved impressive results. For instance, the SNB method reached over 72% accuracy on unseen classes in the AWA2 benchmark. Research milestones like CLIP and GPT-3 show that zero-shot models can transfer knowledge from seen to unseen classes using shared semantic spaces.
Zero-shot learning makes AI more flexible and efficient. It saves time and resources by reducing the need for labeled data. It also brings AI closer to human-like learning, where understanding and generalization matter more than memorizing examples.
How Zero-shot Learning Works
Learning from Seen to Unseen
Zero-shot learning helps a computer recognize things it has never seen before. This process works by teaching the model about objects it already knows, then using descriptions to identify new ones. Imagine a student who has learned about horses and now needs to recognize a zebra. The student reads that a zebra is like a horse but has black and white stripes. The student can now spot a zebra, even without seeing one before. A zero-shot learning machine vision system works in a similar way.
The main steps in zero-shot learning for machine vision systems include:
-
Attribute-Based Methods
The model learns to spot features, such as color or shape, from images of known objects. When it sees a new object, it predicts its features and matches them to descriptions of novel classes. -
Semantic Embedding-Based Approaches
The system creates a shared space where both images and class labels live as vectors. It aligns features from known objects with their semantic embeddings. When a new image appears, the model maps it into this space and finds the closest class label. -
Generative Models
The model uses data and descriptions from known classes to train a generator. It then creates fake images or features for new classes based on their descriptions. The system combines real and synthetic data to classify both seen and unseen objects.
OpenAI’s CLIP model shows how zero-shot learning works in practice. CLIP learns from many image-text pairs. It can match a picture of a zebra to the phrase "an animal with black and white stripes," even if it has never seen a zebra before. This ability lets the model generalize from seen to unseen classes without extra training.
Semantic Representations
Semantic representations play a key role in zero-shot learning. These representations help the model understand and connect different objects. They can take many forms:
- Semantic embeddings, such as word vectors, represent classes and images in a shared space.
- Attribute-based models use lists of features, like "has stripes" or "four legs," to describe objects.
- Transfer learning uses pre-trained models to help the system generalize to novel classes.
A table below shows common types of semantic representations and their effectiveness:
| Semantic Representation Type | Description | Effectiveness / Notes |
|---|---|---|
| Textual Descriptions | Sentences describing actions or objects | Often outperform traditional attributes and word vectors |
| Deep Features from Images | Features taken from images using deep learning | Work well even with few images per class |
| Traditional Attributes | Manually chosen features, like color or shape | Less effective than text or image-based features |
| Word Vectors | Embeddings showing relationships between words | Not as strong as textual descriptions or deep image features |
Some systems use documents, like Wikipedia pages, to create rich semantic representations. These documents provide detailed descriptions that help the model recognize new objects. Using such data can boost zero-shot learning performance, especially on large datasets.
Knowledge Transfer
Knowledge transfer allows a zero-shot learning machine vision system to use what it knows about seen classes to recognize novel classes. The model embeds both images and class descriptions into a shared semantic space. This space lets the model relate known and unknown objects by comparing their semantic similarities.
For example, the model projects features from an image into the same space as word embeddings for class names. It then matches the image to the closest class, even if that class was not part of the training data. This process relies on the quality of the semantic data. Combining different sources, such as text and images, can improve the system’s ability to generalize.
Zero-shot learning uses mid-level semantic knowledge, like attributes, which are less tied to specific examples. Some systems use federated zero-shot learning, where models share semantic knowledge across many users without sharing raw data. This approach helps build a more generalized zero-shot learning machine vision system.
Semantic representations form the bridge between seen and unseen classes. They let the model transfer knowledge and recognize new objects without direct training. This mechanism makes zero-shot learning a powerful machine learning technique for real-world tasks.
Methods in Zero-shot Learning Machine Vision Systems
Attribute-based Methods
Attribute-based methods help zero-shot learning models recognize new objects by focusing on features like color, shape, or texture. These models do not need labeled images for every class. Instead, they learn from labeled attributes. For example, a model that knows "stripes" from tigers and zebras, and "yellow" from canaries, can identify a bee as a "yellow, striped flying insect" without seeing a bee before. Recent research has improved these methods by using local embedding subspaces, which make the models better at telling objects apart.
| Method Type | Description | Effectiveness and Limitations |
|---|---|---|
| Embedding-based | Maps visual features into semantic space; classification via nearest-neighbor search of semantic prototypes. | Widely used and interpretable; effective in knowledge transfer but limited by attribute annotation effort. |
| Generative | Learns semantic-conditioned generators to synthesize samples for unseen classes, converting ZSL into supervised classification. | Improves performance by augmenting data; effective but depends on quality of generated features. |
| Common-space learning | Maps visual and semantic features into a shared space for classification by nearest neighbor. | Enhances visual-semantic alignment; effective but challenged by scalability and attribute annotation costs. |
Attribute-based zero-shot learning remains popular and effective, especially when combined with other techniques, but it can be limited by the need for detailed attribute labels.
Embedding-based Approaches
Embedding-based approaches create a shared space where both images and class descriptions become vectors. The model compares these vectors to classify new objects. These methods show strong performance in zero-shot tasks because they allow the model to measure how close an image is to a class description. Researchers found that the structure of these embeddings predicts how well the model will improve with more training. However, these methods can forget what they learned about old tasks when they focus on new ones. Careful design helps keep the model accurate for both seen and unseen classes.
- Embedding-based methods help models transfer knowledge and select the best approach for new tasks.
- They can lose accuracy on old tasks if not managed well.
- The structure of the embedding space is important for both learning and generalization.
Generative Models
Generative models play a big role in zero-shot learning by creating new examples for classes the model has never seen. These models use text-to-image tools or vision-language models to generate images or descriptions. For example, models like DALL-E 3 and Stable Diffusion 2 can make pictures from text, helping the system learn about new classes. Advanced models combine these generated images with real data to improve accuracy.
| Aspect | Description | Supporting Evidence |
|---|---|---|
| Generative Models Used | Vision-language and text-to-image models generate knowledge and images for new classes | Bridges language and visual understanding |
| Model Architecture | Combines encoders and transformers for rich cross-modal learning | Improves accuracy and handles class differences |
| Experimental Validation | Tested on several datasets, showing better results than older methods | Proves the value of generative knowledge |
| Advantages | Avoids manual data search and improves generalization | Leads to higher accuracy in zero-shot recognition |
Hybrid Techniques
Hybrid techniques mix zero-shot, one-shot, and few-shot learning with generative models. These methods help the model adapt quickly to new tasks, even with little or no labeled data. Hybrid approaches also use synthetic data to make learning faster and more accurate. They handle changes in data and help the model learn in new situations. By combining different learning styles, hybrid methods boost accuracy and make zero-shot learning more useful in real-world machine vision.
- Hybrid models speed up learning when data is scarce.
- They improve accuracy and help the model handle new domains.
- These techniques lower development costs and support innovation in machine vision.
Applications of Zero-shot Learning

Image Classification
Zero-shot learning has changed how computer vision systems handle image classification. These systems can now recognize new categories without needing labeled examples. Many real-world tasks benefit from this approach:
- Content moderation adapts to new types of objectionable content.
- E-commerce platforms improve product search and flexible classification.
- Medical imaging systems identify rare diseases or new diagnostic categories.
- Wildlife monitoring tracks and classifies animal species.
- Robotics uses object tracking to identify unseen objects for various tasks.
This flexibility allows models to keep up with changing environments and new challenges.
Object Detection
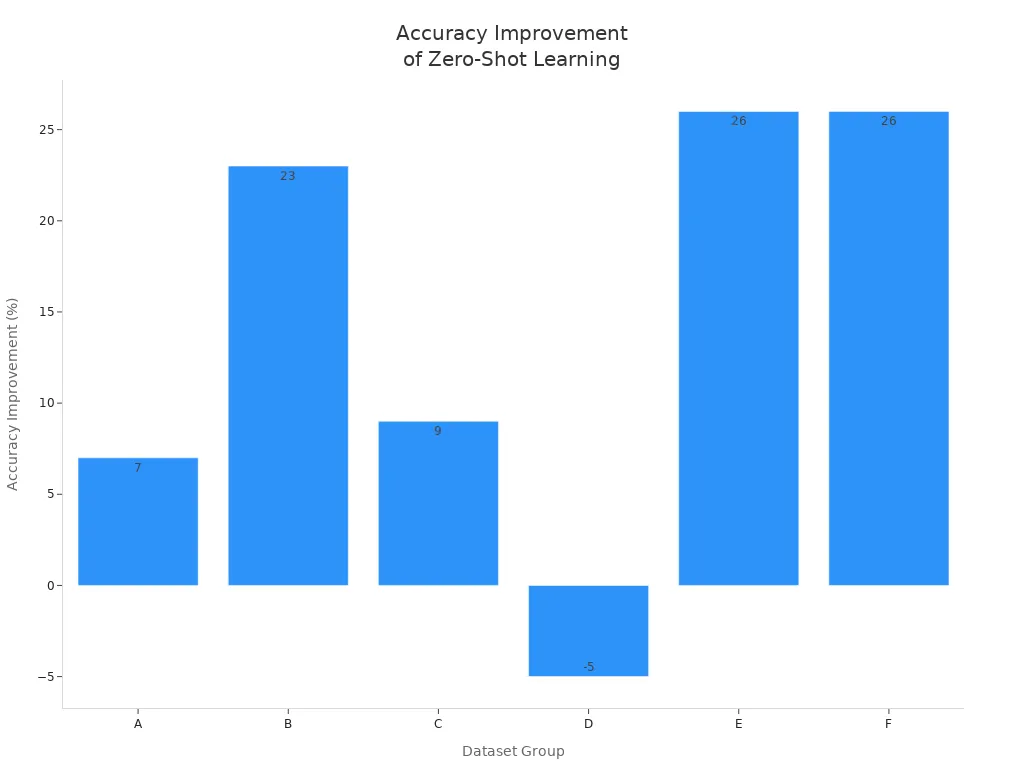
Zero-shot learning improves object detection by allowing models to find and classify objects they have never seen before. Traditional methods need many labeled samples, but zero-shot models generalize to unseen categories. This helps in situations where labeled data is scarce or expensive. Models like CLIP use cross-modal learning to map images and text into a shared space, making object tracking and object detection more flexible and accurate. The chart below shows how a stacking ensemble zero-shot learning model outperforms traditional methods in accuracy across several datasets:
Medical Imaging
Medical imaging has seen major advances with zero-shot learning. Models like the Segment Anything Model (SAM) use a Vision Transformer to perform semantic segmentation on X-ray, ultrasound, dermatoscopy, and colonoscopy images. These models do not need task-specific training and require minimal user interaction. They achieve results that match or even surpass specialized models. Other systems, such as ETHOS and GPT-4o, predict health outcomes and perform clinical phenotyping from electronic health records. These models show high recall and accuracy, reduce bias, and work well with noisy or inconsistent data.
Industrial Use
Industrial machine vision systems use zero-shot learning to recognize objects or patterns without prior training on specific data. Wildlife monitoring benefits by identifying rare species without labeled images, making object tracking more efficient. Medical imaging uses zero-shot learning to diagnose rare diseases. These applications save time and resources, expand the ability to handle unseen classes, and improve adaptability across different domains. Semantic segmentation and object detection tasks in industry now require less retraining, helping companies respond quickly to new challenges.
Challenges and Limitations
Performance Gaps
Zero-shot learning in machine vision faces several performance gaps compared to traditional supervised learning.
- Models depend on the quality of semantic representations, which can introduce errors or bias.
- A gap exists between low-level visual features and high-level semantic concepts, making it hard for models to generalize to new classes.
- Zero-shot models often struggle to distinguish between classes that look similar or share attributes.
- Noisy or inaccurate semantic information can lower performance.
- Unlike supervised models, zero-shot systems do not receive direct supervision for unseen classes, which leads to lower accuracy and less robustness.
Zero-shot learning offers flexibility, but these gaps show that it still cannot match the precision of supervised methods in many real-world tasks.
Semantic Representation Issues
Semantic representations form the backbone of zero-shot learning, but they bring their own challenges.
- Models rely on auxiliary data like word embeddings or manually defined attributes to connect known and unknown classes.
- These embeddings may miss important details or domain-specific relationships, leading to mistakes.
- Manual labeling of attributes takes time and can introduce human bias.
- Automated methods, such as Word2Vec, may not capture all visual relationships.
- Some attributes, like "fast" or "timid," do not help with visual recognition and can confuse the model.
A table below summarizes common issues:
| Issue | Impact on Model |
|---|---|
| Lack of nuance in embeddings | Inaccurate predictions |
| Human bias in attributes | Reduced reliability |
| Irrelevant attributes | Poor visual alignment |
Scalability
Scalability remains a key concern for zero-shot learning systems. Large-scale deployment requires handling massive datasets, bigger models, and large batch sizes. The BASIC model, for example, scaled up to billions of image-text pairs and achieved high accuracy and robustness. Techniques like pruning, clustering, and knowledge distillation help reduce computational load and memory use. Hyperparameter tuning also boosts efficiency. These strategies make zero-shot learning more practical for industry, but managing resources and maintaining performance at scale still pose challenges.
Current Solutions
Researchers continue to develop solutions to address these limitations.
- One-shot and few-shot learning methods help models generalize from very few examples, improving adaptability.
- New benchmarks test vision-language models on fine-grained recognition and specificity, revealing areas for improvement.
- Fine-tuning, ensemble methods, and multi-agent approaches aim to boost robustness and accuracy.
- Meta-learning and domain adaptation help models learn quickly and generalize across domains.
- Prototype-based methods create class representations that capture unique features, improving generalization.
Ongoing research and new evaluation frameworks drive progress, making zero-shot learning more reliable and effective for real-world machine vision applications.
Zero-shot learning breaks barriers in machine vision by letting machines classify new data without large labeled datasets. This approach supports rapid adaptation in fields like robotics, healthcare, and autonomous systems.
- Key techniques include semantic embedding, generative models, and graph-based methods.
- Experts expect smarter attribute representation and deeper class relationships to drive progress.
- Readers can explore more through resources like Hugging Face documentation, research papers, and online courses.
The future promises intelligent systems that learn and innovate with less data, moving closer to human-like understanding.
FAQ
What makes zero-shot learning different from traditional machine learning?
Zero-shot learning does not need labeled examples for every class. Traditional machine learning needs many labeled images for each object. Zero-shot models use descriptions or features to recognize new things. This saves time and resources.
Can zero-shot learning models make mistakes with new objects?
Yes, they can. If the descriptions or features are not clear, the model may confuse similar objects. For example, it might mix up a zebra and a horse if the stripes are not visible.
Where do zero-shot learning systems get their semantic information?
These systems use sources like word embeddings, attribute lists, or text from documents. Some models use Wikipedia pages or product descriptions. This information helps the model connect known and unknown classes.
How do companies use zero-shot learning in real life?
Companies use zero-shot learning for tasks like product search, content moderation, and medical diagnosis. These systems help find new items or detect rare events without retraining the model each time.
See Also
Understanding The Role Of Cameras In Machine Vision
A Comprehensive Guide To Image Processing In Machine Vision
Exploring Computer Vision Models Within Machine Vision Systems
An Overview Of Electronics Used In Machine Vision Systems
Understanding Few-Shot And Active Learning Methods In Machine Vision








