
Feature maps act as the core mechanism in modern machine learning, allowing artificial intelligence to interpret complex visual data with precision. Each feature map, produced by a convolutional layer, highlights patterns such as edges or curves that a computer vision system must recognize. These feature maps function as the pattern detectors or visual memory of a feature map machine vision system. Researchers observe that machine learning models generate feature maps with significant diversity and variation, supporting high accuracy in artificial intelligence tasks. Numerical metrics, including accuracy and mean Average Precision, further confirm how feature maps boost the learning and recognition abilities of machine vision. In machine learning, these maps enable stepwise learning, helping artificial intelligence understand images from simple lines to complex shapes.
Key Takeaways
- Feature maps help AI systems find and highlight important patterns in images, like edges and textures, making object recognition more accurate.
- Convolutional neural networks create feature maps by scanning images with filters, capturing simple to complex features step-by-step.
- Pooling and optimization techniques reduce feature map size and complexity, speeding up learning and saving memory without losing accuracy.
- Combining multiple feature maps from different sources improves detection and classification, boosting performance in tasks like EEG analysis and image recognition.
- Feature maps power real-world AI applications such as facial recognition, medical imaging, and autonomous vehicles, enabling safer and smarter technology.
Feature Maps in Machine Vision
What Is a Feature Map?
A feature map serves as the primary output of convolutional layers in convolutional neural networks. This output feature map represents patterns that the network learns from an image during machine learning. Each feature map takes the form of a two-dimensional matrix, where each value indicates the presence or strength of a specific visual feature, such as an edge or a texture, at a particular location in the image.
Convolutional neural networks use small filters to scan across the input image. At every position, the filter performs a dot product operation with the underlying patch of the image. The result of this operation fills one cell in the output feature map. By repeating this process across the entire image, the network creates a complete feature map that highlights where certain patterns appear.
Feature maps act as the visual memory of a machine vision system. They allow the neural network to remember and recognize important patterns in images, supporting accurate detection and classification.
Multiple filters operate in parallel within a convolutional neural network. Each filter produces its own output feature map, capturing different aspects of the image. For example, one filter may detect horizontal edges, while another identifies curves or textures. These output feature maps stack together, forming a rich representation of the image’s features.
Recent experimental studies show that feature maps generated through optical convolution significantly improve machine vision accuracy. For instance, a meta-optic classifier achieved up to 99.3% theoretical accuracy and 98.6% measured accuracy on the MNIST dataset. In comparison, a model without convolutional layers only reached 80.3% accuracy. This result highlights the critical role of feature maps in boosting classification performance in machine learning.
The structure of a feature map enables the network to focus on regions of interest within an image. By isolating important features and reducing noise, feature maps help the system detect and classify objects more reliably, even in complex environments. This targeted approach benefits applications such as defect detection, face recognition, and quality control.
Activation Maps and Filters
Activation maps, often called feature maps, reveal which parts of an image activate specific filters in a convolutional neural network. Each filter acts as a pattern detector, searching for unique visual cues in the input image. When a filter finds a match, it produces high values in the corresponding output feature map.
Convolutional neural networks rely on these activation maps to understand images at multiple levels. Early layers in the network detect simple features, such as lines or corners. Deeper layers combine these simple patterns to recognize more complex shapes and objects. This process, known as hierarchical learning, allows the network to build a detailed understanding of the image.
Extensive experiments on Class Activation Mapping methods confirm that activation maps effectively highlight relevant visual features. Metrics like Insertion, Deletion, and Increase in Confidence show that advanced CAM methods outperform random baselines. These results demonstrate that activation maps capture important semantic concepts and explain neural network predictions more comprehensively.
Activation maps also support efficient machine learning by identifying which filters contribute most to detection and classification. For example, pruning less important filters in a network can reduce computational costs with minimal loss in accuracy. In one experiment, pruning VGG-16 on CIFAR-10 reduced computations by 50% with only a 0.86% drop in accuracy. This efficiency makes convolutional neural networks practical for real-world computer vision tasks.
The combination of filters and activation maps forms the foundation of modern machine vision. By extracting, representing, and understanding features in images, these components enable neural networks to perform complex detection and classification tasks with high accuracy.
Convolutional Neural Networks
Feature Extraction Process
Convolutional neural networks stand at the heart of modern machine learning and machine vision. These networks use convolutional layers to scan images with small kernels, often called filters. Each kernel slides across the image, performing mathematical operations that highlight specific patterns. The result of this process is a feature map, which shows where certain visual cues appear in the image.
The feature extraction process begins with the first convolutional layer. This layer detects simple patterns, such as edges or corners. As the image passes through deeper layers, the network combines these basic patterns into more complex shapes. Each convolutional layer produces its own set of feature maps, capturing different aspects of the image. These feature maps serve as the building blocks for understanding visual data in machine learning.
Researchers have studied the step-by-step feature extraction process in detail. They found that convolutional neural networks convert input images into smaller matrices using filters, often sized 3×3. These filters move across the image with a stride, creating feature maps that highlight important regions. Pooling layers then reduce the size of these feature maps, making the network more efficient and less sensitive to small changes in the image. Visualizations, such as Grad-CAM heatmaps, help experts see which parts of the image the network focuses on during learning. Radiologists and other professionals use these visualizations to confirm that the network extracts clinically relevant features.
Performance metrics validate the effectiveness of convolutional neural networks in feature extraction. The table below summarizes key metrics and their importance in real-world applications:
| Metric / Consideration | Explanation / Importance |
|---|---|
| Accuracy (Top-1, Top-5) | Standard error rates on datasets like ImageNet, critical for benchmarking CNN feature extraction. |
| Inference Time | Time per prediction, crucial for real-time applications such as autonomous driving. |
| Resource Usage | Memory footprint and computational complexity (FLOPS), important for deployment in constrained systems. |
| Data Quality | High-quality, well-annotated datasets improve CNN accuracy and robustness. |
| Model Interpretability | Techniques like Grad-CAM and LIME help understand CNN decisions, increasing trust and adoption. |
| Continuous Learning | Retraining with new data maintains model relevance in dynamic environments. |
| Cross-disciplinary Collaboration | Ensures models are both technically sound and practically relevant by involving domain experts. |
| Deployment Challenges | Includes latency, scalability, integration, and monitoring, all impacting real-world CNN effectiveness. |
Comparative studies show that convolutional neural networks consistently improve accuracy in machine learning tasks. For example, self-distillation techniques boost average accuracy by 2.65%, with a maximum of 4.07% on VGG19. Pseudo-color image preprocessing increases classification accuracy by 3.6%, while diaphragm removal preprocessing raises accuracy by 7.4%. These improvements highlight the power of feature maps in extracting meaningful information from images.
Hierarchical Representation
Convolutional neural networks excel at hierarchical feature extraction. The network learns to recognize patterns at multiple levels, starting with simple features and progressing to complex objects. Early layers focus on low-level details, such as lines and textures. Middle layers combine these details to form shapes and parts. Final layers identify entire objects or scenes.
This hierarchical structure mirrors the way human vision works. Studies using representational similarity analysis show that early network layers align with low-level visual models, while deeper layers capture domain-level distinctions and object-scene associations. The final stages of the network represent object-scene co-occurrence, which helps the system generalize and perform well in diverse environments. Statistical analysis confirms that these hierarchical stages significantly improve the network’s ability to match biological vision.
Advanced methods, such as the Hierarchical Proxy Loss, further enhance machine vision performance. By integrating class hierarchies into the learning process, these methods achieve higher accuracy in image retrieval and classification tasks. This approach sets new benchmarks for machine learning systems, demonstrating the value of hierarchical representation.
Tip: Hierarchical feature extraction allows convolutional neural networks to build a layered understanding of images, making them highly effective for complex machine vision tasks.
Feature maps play a central role in this process. Each feature map captures information at a specific level of abstraction. By stacking and combining these maps, the network creates a rich, multi-layered representation of the image. This approach enables deep learning systems to interpret visual data with remarkable accuracy and reliability.
Feature Map Machine Vision System
Pooling and Optimization
Pooling layers play a vital role in every feature map machine vision system. These layers reduce the spatial size of feature maps, making the system more efficient. By summarizing regions of the feature maps, pooling helps the machine learning model focus on the most important features. This process not only speeds up learning but also lowers memory use and energy consumption.
Optimization techniques, such as pruning and quantization, further improve the performance of feature map machine vision systems. These key methods for improving feature maps help reduce model complexity without sacrificing accuracy. As a result, the system can handle larger datasets and work well in real-world environments.
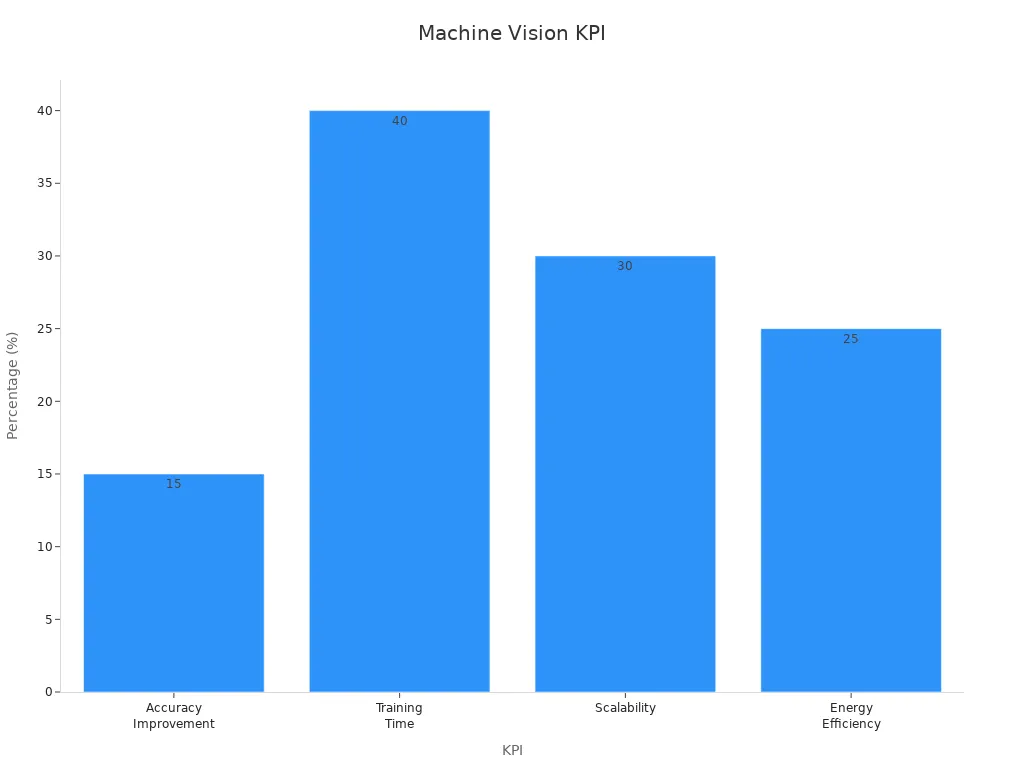
The following table highlights key performance indicators that show the benefits of pooling and optimization in machine vision:
| Key Performance Indicator | Improvement / Impact Description |
|---|---|
| Accuracy Improvement | Up to 15% increase in accuracy on benchmark datasets due to pooling and optimization techniques. |
| Training Time Reduction | Training times reduced by up to 40%, enabling faster model development and deployment. |
| Scalability | Scalability improvements of up to 30% when transitioning from lab to real-world applications. |
| Energy Efficiency | Approximately 25% improvement through optimized algorithms and hardware accelerators. |
| Detection and Classification Metrics | Metrics such as IoU, Precision, Recall, F1-Score, mAP, and MVT quantify detection and classification performance improvements. |
| Model Complexity Reduction | Techniques like pruning, quantization, and knowledge distillation reduce complexity without major accuracy loss, supporting resource efficiency. |
| Real-world Case Study Outcomes | Defect detection accuracy reaching 99.5%, reduction in warranty claims, and significant cost savings demonstrate practical benefits. |
Multi-Channel and Composite Maps
Modern feature map machine vision systems use multi-channel and composite feature maps to boost detection and classification. These key methods for improving feature maps combine information from different sources, such as 1D hand-crafted features and 2D feature maps. This approach gives the machine learning model a richer view of the data.
- Studies show that composite feature sets lead to higher accuracy than using only 1D or 2D features.
- Combining Hjorth mobility 2D feature maps with 1D features increases accuracy by 6% for EEG baseline data.
- For mental arithmetic datasets, composite features improve accuracy by 10% over 2D features alone.
- Parkinson’s disease and emotion datasets see improvements of 18.75% and 7.4% with composite features.
- 3D EEG video representations with CNN-RNN models reach peak mean accuracies up to 98.81%, outperforming other methods by up to 3.27%.
- Confusion matrices and error rates confirm low misclassification rates.
- Composite feature sets use both spatial information from 2D maps and changes in 1D features, leading to better performance.
Feature maps in a feature map machine vision system allow the machine to learn from complex data. By using multi-channel and composite maps, the system improves detection, classification, and overall machine learning results.
Real-World Applications
Object and Facial Recognition
Feature maps drive progress in object and facial recognition systems. These systems rely on feature maps to extract unique patterns from each image. In a typical face recognition pipeline, the process starts with data collection and face detection. Feature extraction follows, where feature maps represent facial characteristics for accurate identification. High-quality data and effective feature extraction lead to better recognition results.
Modern object detection architectures, such as Mask R-CNN, use feature pyramid networks to combine feature maps at different scales. This approach improves detection accuracy by 10-50%. Models like Faster R-CNN, YOLOv3, and YOLOv4 also depend on feature maps for object and face recognition. These models show that feature maps are essential for both detection and image segmentation tasks.
NIST reports show a dramatic drop in facial recognition error rates, from 4% in 2014 to just 0.08% in 2020. Advances in deep learning and feature extraction, especially through feature maps, made this possible.
Object detection and recognition systems now achieve high accuracy in real-world settings. Feature maps help these systems distinguish between objects, even in crowded or complex scenes. This capability supports applications in security, retail, and social media.
Medical Imaging and Autonomous Vehicles
Medical imaging and autonomous vehicles both benefit from advanced feature map techniques. In medical imaging, convolutional layers extract feature maps that capture complex patterns in scans. These deep features improve image classification and segmentation, reducing the need for manual feature selection. The result is more accurate detection of diseases and conditions.
Multimodal fusion of feature maps further boosts performance. For autonomous vehicles, combining visual features from cameras with LiDAR data increases object detection accuracy by 3.7%. In medical imaging, integrating pixel data with clinical information raises diagnostic accuracy beyond image-only models. This approach leverages complementary data for better recognition and detection.
A table below summarizes the impact of feature maps in these fields:
| Application Area | Improvement with Feature Maps |
|---|---|
| Medical Imaging | Higher accuracy, less overfitting, better generalization |
| Autonomous Vehicles | 3.7% increase in object detection accuracy, improved safety |
Feature maps enable computer vision systems to perform reliable detection, recognition, and image segmentation. These advances support safer vehicles and more effective healthcare.
Feature maps help machine vision systems interpret and understand complex visual data.
- They capture essential image properties, allowing artificial intelligence to recognize faces, detect emotions, and analyze medical images.
- Feature maps in convolutional neural networks extract features from simple edges to complex objects, improving accuracy and speed.
- Their adaptive nature supports tasks like satellite monitoring and quality control.
The future of machine vision will rely on mastering feature maps as technology continues to evolve.
FAQ
What is the main purpose of a feature map in machine vision?
A feature map helps a machine vision system find and highlight important patterns in images. It shows where edges, shapes, or textures appear, making it easier for the system to recognize objects.
How do feature maps improve image recognition accuracy?
Feature maps let neural networks focus on key details in an image. By capturing patterns at different levels, they help the system make better decisions and reduce mistakes in tasks like object or face recognition.
Can feature maps work with different types of data?
Yes. Feature maps can process data from images, videos, and even signals like EEG. Multi-channel and composite feature maps combine information from many sources, improving detection and classification results.
Why do machine vision systems use pooling layers with feature maps?
Pooling layers make feature maps smaller and more efficient. They help the system keep only the most important information, which speeds up learning and saves memory.
Are feature maps important for real-world AI applications?
Absolutely! Feature maps power many real-world AI tools, such as medical imaging, autonomous vehicles, and security systems. They help these systems understand complex visual data and make accurate decisions.
See Also
The Role Of Feature Extraction In Machine Vision
Deep Learning Techniques Improving Machine Vision Performance
Understanding The Use Of Cameras In Machine Vision
A Clear Guide To Image Processing In Machine Vision
Essential Features And Advantages Of Machine Vision In Medical Devices








