
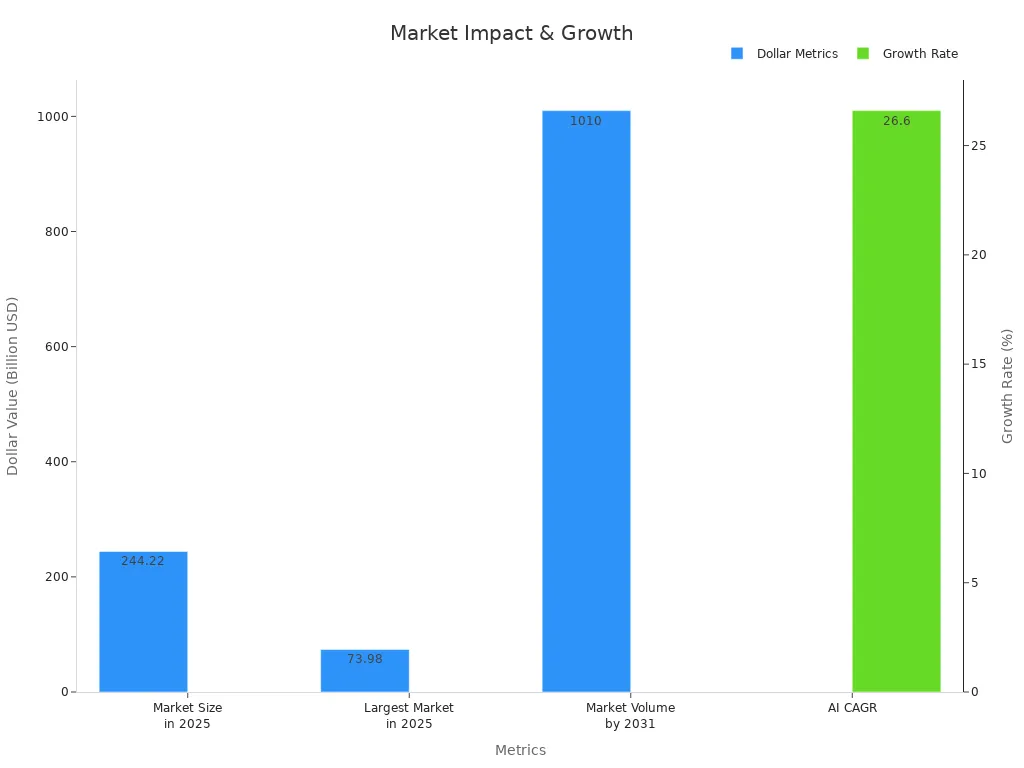
A Neural language model machine vision system combines neural networks that process vision and language to create advanced artificial intelligence. These systems help computers see images, understand text, and connect information. In 2025, the market for AI and natural language processing will reach over $244 billion and $53 billion, showing rapid growth.
| Metric | Value | Notes |
|---|---|---|
| AI Market Size in 2025 | US$244.22 billion | Projected market size |
| NLP Market Size in 2025 | US$53.42 billion | Projected market size |
| Untapped Data Volume | 120 zettabytes | Data available for AI models |
These systems allow industries to use vision and language AI for real-time decisions, smarter robots, and better services. Neural models now help process huge amounts of data and support a wide range of uses. Readers can expect these advances to shape daily life and business in new ways.
Key Takeaways
- Neural language model machine vision systems combine image and text understanding to help computers see and read like humans.
- These systems use powerful neural networks and transformers to process visual and language data together for tasks like image captioning and question answering.
- Industries such as healthcare, manufacturing, and enterprise use these models to improve accuracy, speed, and decision-making.
- Everyday technologies like smartphones, security cameras, and robots benefit from vision language models to make life easier and safer.
- Challenges remain in making these systems robust and fair, but ongoing research and ethical efforts aim to improve their reliability and reduce bias.
Vision Language Models

Definition
Vision language models combine the power of visual and language understanding. These models use machine learning to connect what they see in an image with what they read or hear in text. A vision language model can look at a picture and describe it using words. It can also answer questions about an image or find objects in a scene. This type of model uses both computer vision and language processing to solve problems that need both skills. Many AI systems in 2025 use these models to help computers understand the world more like humans do.
Core Features
Vision language models have several important features:
- Multimodal Input: The model can take both image and text as input. It learns from visual data and language at the same time.
- Visual Reasoning: The model can look at an image and make sense of what is happening. It can connect visual clues with language to answer questions or give explanations.
- Image Captioning: The model can create a sentence that describes what it sees in an image. This helps AI systems talk about pictures in a way people understand.
- Visual Question Answering: The model can answer questions about an image. For example, it can look at a photo and tell what color a car is or how many people are present.
- Cross-Modal Search: The model can find images based on a text query or find text based on an image. This helps in searching large databases quickly.
Note: Vision language models use machine learning to improve over time. They learn from millions of images and text samples. This makes them better at understanding both visual and language information.
Vision language models play a key role in AI. They help computers see, read, and understand at the same time. These models support many tasks in computer vision, such as object detection and image classification. They also help with language tasks like translation and summarization. In 2025, vision language models continue to shape how AI systems interact with the world.
Neural Language Model Machine Vision System
Architecture
A neural language model machine vision system uses a special architecture that brings together vision and language. At the core, these systems use neural networks called transformers. Transformers help the model handle both images and text. The system starts with a vision encoder. This encoder, such as CLIP or EVA, takes an image and turns it into a set of visual representations. These visual representations capture important details from the image, like shapes, colors, and objects.
Next, the system uses a large language model. The large language model works with the information from the vision encoder. It connects the visual data with words and sentences. This process helps the model understand what is happening in the image and how it relates to language. The transformer model acts as a bridge between the visual and language parts. It allows the system to process visual and textual data together.
Researchers have found that using strong vision encoders, like CLIP-ViT-L-336px, improves the performance of these systems. When the vision encoder provides better visual and semantic details, the large language model can make more accurate connections between images and text. The EVE model shows that adding supervision for visual representation and aligning it with language concepts helps the system learn faster and perform better. Even though large vision encoders can be hard to deploy, they give the neural language model machine vision system better visual recognition and understanding.
Note: Neural networks and transformer models work together in these systems. They allow the model to learn from both images and language at the same time.
Multimodal Processing
Multimodal processing means the system can handle more than one type of data. In a neural language model machine vision system, the model takes both images and text as input. The vision encoder processes the image, while the large language model handles the text. The transformer model combines these two streams of information. This lets the system solve complex tasks that need both visual and language skills.
For example, the model can look at an image and answer questions about it. It can also generate a caption for an image or find an image that matches a text description. These tasks use multimodal AI techniques. The system learns from visual and textual data, making it smarter and more flexible.
Researchers use many benchmarks to test how well these systems work. The table below shows some common categories and datasets:
| Category | Description | Example Datasets |
|---|---|---|
| Visual text understanding | Evaluates models’ ability to extract and understand texts within visual components | TextVQA, DocVQA |
| Robotics interaction | Uses simulator-based evaluation to assess VLM-powered agents in robotics and human-robot interaction | Habitat, Gibson, iGibson |
| Human-robot interaction | Assesses cognition, adaptation, and intention understanding in multimodal human-robot collaboration | MUTEX, LaMI, vlm-Social-Nav |
| Autonomous driving | Benchmarks for object recognition, navigation, planning, and decision-making in driving scenarios | VLPD, MotionLM, DiLU, DriveGPT4 |
These benchmarks help researchers check if the neural language model machine vision system can understand both images and text. They use automatic metrics to see if the model gives correct answers. In robotics, simulator-based benchmarks help create training data when real-world data is hard to get. While these tests focus on the design and scope of the tasks, they show that multimodal AI systems can handle many real-world challenges.
Multimodal AI brings together vision, language, and machine learning. This combination helps the system understand the world in a deeper way. Neural networks and transformer models make it possible for the system to learn from both images and text. As a result, neural language model machine vision systems play a key role in modern AI. They support tasks in natural language processing, computer vision, and robotics. These systems continue to grow in importance as machine vision models and multimodal AI become more advanced.
AI Applications

Industry Use
Many industries now use vision language models to improve their work. Healthcare leads in adopting these systems. Hospitals use neural networks and deep learning models for disease diagnosis and imaging analysis. Doctors rely on these tools to find patterns in X-rays, MRIs, and CT scans. These models show high accuracy, precision, and recall. They help doctors detect diseases earlier and make better decisions. Radiology, cardiology, and oncology departments benefit from these advances. Clinical documentation also improves as artificial intelligence helps organize and summarize patient records.
Manufacturing companies use vision-based AI to inspect products. Cameras and sensors capture images of items on assembly lines. The system checks for defects in real time. For example, YOLOv8 detects flaws from high-resolution camera feeds. This process reduces errors and saves time. Factories also use visual and thermal data together to spot problems that are hard to see with the human eye. These systems work on edge devices, such as small computers on the factory floor. They help companies maintain quality and safety.
Enterprise AI uses vision language models to manage large amounts of data. Businesses use these models for document analysis and risk prediction. Generative AI and large language models help with health technology assessments. They assist in reviewing scientific literature and analyzing real-world evidence. Companies use these tools to make better decisions and improve their services. However, experts note that these applications need careful evaluation. Issues like scientific validity, bias, and regulatory concerns remain important.
Note: Vision language models continue to evolve. They bring new possibilities to healthcare, manufacturing, and enterprise AI. These systems help people work faster and more accurately.
Everyday Impact
Vision language models now touch many parts of daily life. People use these systems without even noticing. Smartphones use visual AI to organize photos and suggest tags. Apps use image captioning to describe pictures for people with visual impairments. This makes technology more accessible.
In transportation, dashcams with vision AI detect stolen cars. These devices work on low-cost hardware and provide real-time alerts. Security cameras use visual analysis to spot unusual activity. Retail stores use vision language models to track inventory and prevent theft.
Robots in homes and workplaces use visual and language skills to help people. A case study shows that large vision-language models help robots pick up new objects. The robot learns to handle items it has never seen before. This makes human-robot collaboration easier and safer. The system uses 6D pose estimation to understand the position and orientation of objects. Researchers tested this on the YCB dataset and found that the robot could adapt quickly.
People also benefit from AI in education and entertainment. Vision language models help students summarize complex visual data, such as charts or diagrams. They answer questions about images and generate new pictures from text prompts. These tools make learning more interactive and fun.
Some common uses of vision language models in everyday life include:
- Image captioning: Creating descriptions for photos to help with searching and organizing.
- Visual question answering: Helping users get answers from images, such as identifying landmarks or reading signs.
- Visual summarization: Making short summaries of complex images, like medical scans or business charts.
- Image text retrieval: Finding images that match a written query, even if the words are different.
- Image generation: Making new images based on what a person describes.
- Image annotation: Highlighting important parts of an image for easier understanding.
Tip: Vision language models help machines see, understand, and act on visual data. They make technology smarter and more helpful in daily life.
Vision language models continue to change how people interact with technology. They make tasks easier, faster, and more accurate. As these systems improve, they will play an even bigger role in both industry and everyday life.
Challenges
Technical Limits
Neural language model machine vision systems face several technical limits. Robustness remains a major challenge. Researchers test these systems using synthetic or shifted data, but these tests only give statistical confidence. They cannot guarantee that the system will work in every real-world situation. Formal verification methods, such as ReluPlex and FANNETT, offer some theoretical guarantees. However, these methods struggle with complex tasks because of the huge number of possible situations.
Testing for robustness covers a wide range. Some tests use small changes called adversarial perturbations. Others use natural distortions, like blurry images or different lighting. Domain-aware testing helps find where the system fails, but improvements in one area do not always help in others. Real-world input can vary in many ways, making it hard for the system to handle every case. Larger datasets help, but collecting enough data for every situation is not always possible. Human experts and continual learning can make the system more robust by adding new knowledge and fixing errors as they appear.
Generalization also presents a challenge. Studies show that the size of the model and the dataset matter more than the details of the network, such as width or depth. Neural scaling laws support this idea. However, current benchmarks do not always match real-world performance. New metrics now combine accuracy and test data diversity to better measure generalization.
Research Directions
Researchers continue to look for ways to solve these challenges. Many focus on reducing bias in ai systems. Bias often comes from incomplete data or the personal choices of engineers. Building fair and unbiased datasets helps reduce this problem. Improving transparency in algorithms also makes it easier to spot and fix bias.
Ethical governance plays a key role. Companies now use both internal rules and outside oversight to make sure their systems act fairly. Studies show that ai tools can help reduce human bias, but they still sometimes show discrimination based on gender, race, or personality. Researchers suggest more studies in different cultures and more experiments to see how these systems affect people.
Future work will likely include explainable ai tools and larger, more diverse datasets. These steps will help improve both technical performance and ethical standards. Machine learning continues to evolve, and new ideas will help address the current limits of these systems.
Future Trends
2025 Advancements
In 2025, neural language model machine vision systems will reach new heights. Companies continue to improve machine learning algorithms and neural networks. These advances help computers understand both text and visual information faster and more accurately. The use of Convolutional Neural Networks (CNNs) allows systems to analyze and interpret image data in real time. This progress supports tasks like object detection and image classification, making technology more useful in daily life.
Many factors drive these advancements:
- Venture capital and corporate investments in AI research and development
- Digital transformation across businesses that see AI as essential
- Rapid growth in data generation, which gives AI more to learn from
- New technologies such as cloud computing, edge computing, and better semiconductors
- Economic benefits, including lower costs and new ways to earn revenue
The table below highlights key market data for 2025 and beyond:
| Data Point | Details |
|---|---|
| Projected Market Size (2025) | USD 23.42 billion |
| Projected Market Size (2030) | USD 63.48 billion |
| Compound Annual Growth Rate (CAGR) | 22.1% (2025 to 2030) |
| Key Market Drivers | AI hardware, machine learning, edge computing |
| Dominant Region | Asia Pacific |
| Major Companies | NVIDIA, Microsoft, Intel, Alphabet, Amazon |
| Recent Product Developments | Basler AG’s pylon AI software, Intel’s Geti 2.0.0 |
| Market Challenges | High costs, complex maintenance, system upgrades |
Adoption Steps
Organizations that want to use these systems should follow clear steps. First, they need to assess their current technology and data. They should check if they have enough image and visual data for training. Next, they must choose the right hardware, such as GPUs or TPUs, to support fast processing. Training a model requires strong computing power.
After setting up the hardware, teams should select or build a model that fits their needs. They can use pre-trained models or develop custom solutions. Testing the system with real-world image and visual tasks helps ensure accuracy. Companies must also plan for regular updates and maintenance, as technology changes quickly.
Tip: Start small with pilot projects before scaling up. This approach helps teams learn and adjust without large risks.
By following these steps, organizations can unlock the full potential of neural language model machine vision systems and stay ahead in a fast-changing world.
Neural language model machine vision systems have changed how people use technology. These systems combine vision and language to help industries and daily life. The table below shows key milestones and industry impacts:
| Category | Highlights |
|---|---|
| Historical Milestones | Backpropagation (1986), deep learning (2006), AlexNet (2012), GANs (2014) |
| Industry Impact | Healthcare, automotive, manufacturing, agriculture, education, energy |
| Current Trends | Transfer learning, ML as a Service, edge computing, federated learning |
People can learn more by exploring new research or testing these systems. Staying informed helps everyone use language and vision technology better.
FAQ
What is a neural language model machine vision system?
A neural language model machine vision system uses AI to understand both images and text. It combines computer vision and language models. This helps computers see pictures and read words at the same time.
How do these systems help in daily life?
People use these systems in phones, cars, and smart devices. For example, phones organize photos, and cars use cameras to spot dangers. These tools make tasks easier and safer.
Are these systems safe and fair?
Researchers work to make these systems safe and fair. They test for bias and errors. Companies use rules and checks to protect users and improve trust.
Can students use vision language models for learning?
Students use vision language models to study pictures, diagrams, and charts. These models answer questions and explain images. Many schools use them to help students learn faster and understand more.
See Also
Will Neural Networks Take Over Human Machine Vision Tasks?
Understanding Edge AI Applications In Real-Time Vision By 2025
A Comprehensive Guide To Machine And Computer Vision Models
How Masking Improves Safety In Machine Vision Systems 2025
Neural Network Frameworks Transforming The Future Of Machine Vision








