
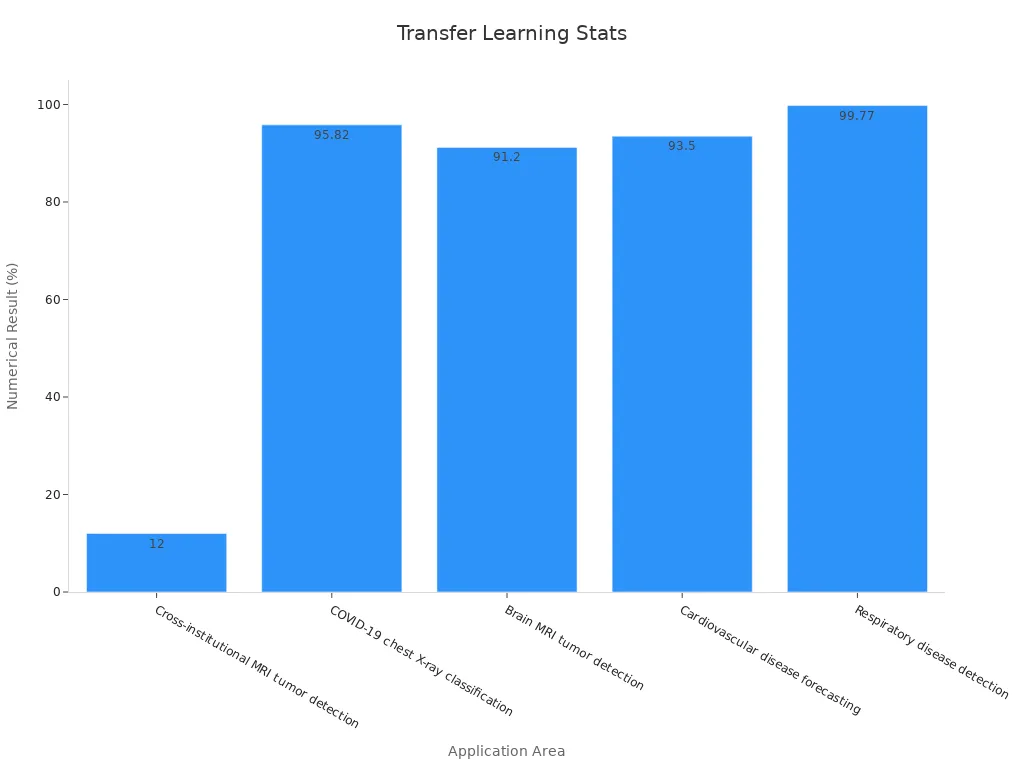
Transfer learning lets you use knowledge from one task to solve new computer vision problems faster and with less data. Imagine you learn to ride a bicycle, then you find it easier to learn to ride a motorcycle. In the same way, a transfer learning machine vision system can apply what it learns from big datasets to new tasks, even if you have only a few images. Recent studies prove its power. For example, in healthcare, transfer learning models have boosted accuracy for detecting diseases in medical images by up to 12% and reached over 99% accuracy in some cases.
You can see more researchers using transfer learning machine vision system models each year, with the number of published studies doubling annually. This growth shows how important transfer learning has become in both machine learning and computer vision.
Key Takeaways
- Transfer learning uses knowledge from pre-trained models to solve new vision tasks faster and with less data.
- The workflow includes using pre-trained models, extracting important features, and fine-tuning the model for your specific task.
- Transfer learning improves accuracy, reduces training time, and lowers computational costs compared to training from scratch.
- It works well in many fields like healthcare, autonomous vehicles, retail, and manufacturing for tasks such as image classification and object detection.
- Challenges like domain shift and task mismatch can affect performance, but following best practices like fine-tuning and domain adaptation helps overcome them.
What Is Transfer Learning?
Core Concept
Transfer learning lets you use knowledge from one task to help solve another. In a transfer learning machine vision system, you start with a pre-trained model. This model has already learned from a huge dataset, like ImageNet, which contains 14 million images. The pre-trained model understands basic shapes, colors, and patterns. You can use this knowledge to train your machine learning model on a new task, even if you have only a small set of images.
Most deep learning models for computer vision use neural networks. These networks learn to spot features such as lines, curves, and textures. When you use a pre-trained model, you do not need to start from scratch. Instead, you build on what the model already knows. This transfer learning approach saves time and improves results.
Here is a table showing how different pre-trained models perform in machine vision tasks:
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|
| MobileNet-v2 | 96.78 | 98.66 | 96.46 |
| ResNet-18 | N/A | 98 | N/A |
| SqueezeNet | N/A | 98 | 92.9 |
| VGG-16 | 97.3 | N/A | N/A |
Why It Matters
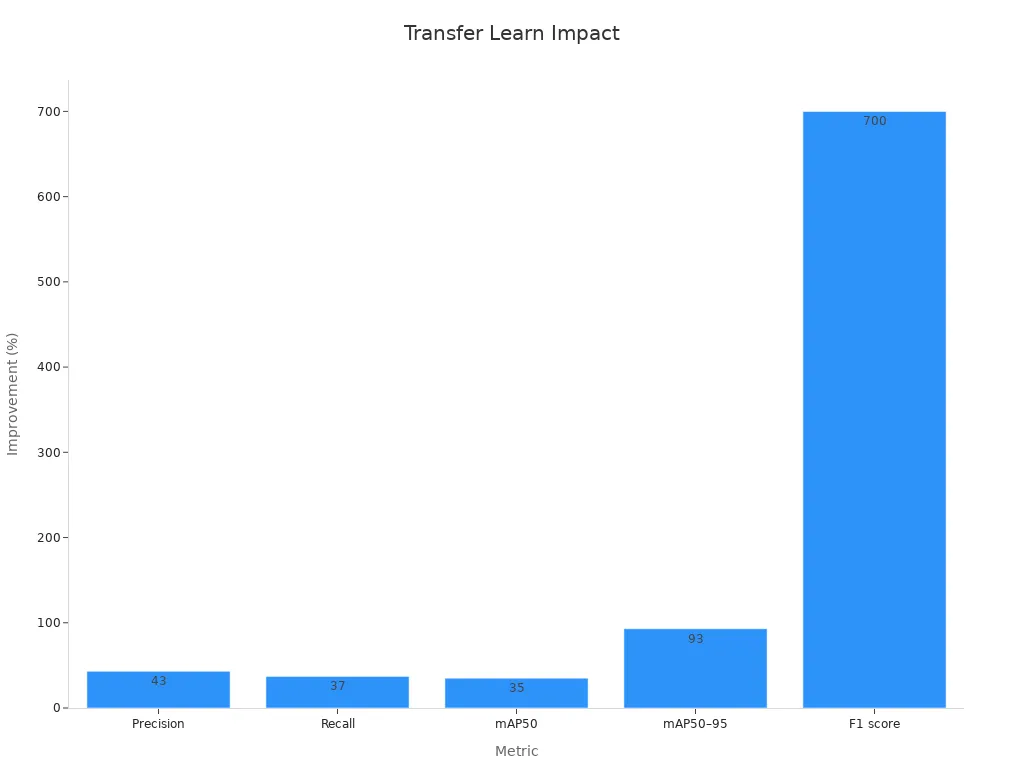
You benefit from transfer learning because it makes your machine learning model smarter and faster. The transfer learning approach uses pre-trained networks to boost accuracy and reduce training time. For example, when you use a pre-trained model, you can see accuracy improvements of up to 30% in healthcare applications. Precision can jump from 0.664 to 0.949, and the F1 score can rise from 0.1089 to 0.8968. These numbers show how much better your model can get.
You do not need a huge dataset to get good results. The pre-trained networks already know a lot about images. You only need to fine-tune the model for your specific task. This makes deep learning and computer vision more accessible for everyone. You can use transfer learning in many fields, from healthcare to manufacturing, and see real improvements in speed and accuracy.
How Transfer Learning Machine Vision System Works

Understanding the transfer learning workflow helps you see how a transfer learning machine vision system can solve new problems quickly. You do not need to start from scratch. Instead, you use knowledge from existing models and adapt it to your needs. This process involves three main steps: using pre-trained models, extracting features, and fine-tuning.
Pre-Trained Models
You begin with a pre-trained model. These models, such as ResNet, VGG, YOLO, and U-Net, have already learned from millions of images. They know how to spot shapes, colors, and patterns. You can use these models for many tasks, including image classification, object detection, and segmentation. Pre-trained models save you time and resources because they have already done the hard work of learning basic image features.
- Pre-trained models work well in many industries:
- Medical imaging: Detecting diseases in X-rays or MRIs.
- Autonomous vehicles: Recognizing objects on the road.
- Retail: Classifying products on shelves.
- Finance: Spotting fraud in transaction images.
- Speech recognition: Understanding spoken words in images or videos.
You can measure how well a pre-trained model works by looking at accuracy, processing speed, and resource usage. These metrics show the technical and business value of your solution. Pre-trained models also scale well. They handle large datasets, process many images at once, and work with different image qualities. You can run them on standard hardware, which keeps costs low.
Tip: Pre-trained models help you avoid the need for huge amounts of training data. You can get good results with smaller, high-quality datasets.
Feature Extraction
Feature extraction is the next step in the transfer learning workflow. Here, you use the pre-trained model to pull out important details from your images. The model acts like a smart filter. It finds lines, textures, and shapes that matter for your task. You do not need to label every image by hand. The model already knows what to look for.
| Evidence Aspect | Quantitative Details |
|---|---|
| Facial Recognition Accuracy | Feature engineering techniques enabled facial recognition systems to achieve 99.06% accuracy, with precision, recall, and specificity all above 99%. |
| Image Classification Accuracy | Advanced feature engineering methods resulted in 96.4% accuracy in image classification tasks, enhancing model precision and efficiency. |
| Feature Extraction with Decision Tree | Combining Hamming-windowed streamline feature extraction with Decision Tree algorithms reached an accuracy of 0.89, demonstrating improved predictive performance. |
Feature extraction makes your model more accurate and efficient. You can use fewer features and still get high accuracy. For example, using hybrid feature selection, you can reduce features from over 27,000 to just 114 and still keep high predictive performance. This step also helps you avoid overfitting, especially when you have limited training data.

Fine-Tuning
Fine-tuning is the last step in the transfer learning workflow. You take the pre-trained model and adjust it for your specific task. You change some layers or retrain parts of the model using your own data. This step helps the model learn the unique patterns in your images.
Fine-tuning a model brings big benefits:
| Metric | Traditional Methods | Fine-Tuning (LoRA/QLoRA) |
|---|---|---|
| Memory Usage | Up to 780GB | Reduced to 24GB (97% reduction) |
| Hardware Cost | $40,000+ for data center GPUs | $2,000 consumer-grade GPUs |
| Training Time | Days to months | Comparable to full-precision methods (days/weeks) |
| Model Size Supported | Limited by hardware (multiple GPUs) | Up to 65B parameters on a single GPU |
| Data Requirements | Large datasets (millions of examples) | Smaller, high-quality datasets (e.g., 50,000 examples) outperform larger noisy datasets |
| Training Infrastructure | Specialized cooling, data centers | Standard office cooling, consumer hardware |
| Real-world Impact | Months of training, high costs | Enables weekly or daily model updates on existing hardware |
You can see that fine-tuning reduces memory and hardware needs by up to 97%. You do not need expensive data centers. You can train large models on a single GPU. You also need less training data. Smaller, high-quality datasets often work better than huge, noisy ones. Fine-tuning lets you update your models quickly and keep your data secure.
In real-world projects, you might use a pre-trained network like ResNet or MobileNet, extract features, and then fine-tune the model for your task. This transfer learning machine vision system workflow helps you get high accuracy, save time, and lower costs. You can handle challenges like data mismatch and overfitting by following best practices, such as using active learning and human-in-the-loop feedback.
Note: You can validate your fine-tuned model using metrics like accuracy, precision, recall, F1-score, and mean Average Precision (mAP). Testing your model on different datasets and under various conditions ensures it works well in real life.
If you want to know how to apply transfer learning, start by choosing a pre-trained model that fits your task. Use it to extract features from your images. Then, fine-tune the model with your own data. This transfer learning workflow makes deep learning models more accessible and powerful for everyone.
Applications

Image Classification
You can use transfer learning in image classification to quickly sort and label images. Pre-trained models already know how to spot shapes and colors, so you do not need to start from scratch. This approach helps you reach high accuracy, even with small datasets. For example, in medical imaging, transfer learning in action boosts the detection of diseases like cancer and pneumonia. Fine-tuning with domain-specific data can increase diagnostic accuracy by up to 30%. You can trust these models to handle complex classification tasks in healthcare, retail, and more.
Object Detection
Object detection lets you find and locate items in images or videos. Transfer learning makes this process faster and more accurate. You can use models like YOLO or Faster R-CNN to detect objects in real time. In autonomous vehicles, transfer learning improves object detection and scene understanding, which helps cars recognize road signs and obstacles. Benchmarks show that using transfer learning increases detection accuracy by up to 8% in tough conditions like rain or fog. You can rely on these models for safety and precision in computer vision projects.
| Dataset | Metric | Relative Gain (%) |
|---|---|---|
| Rainy-KITTI | mAP@0.5 | +8.1 |
| Foggy-KITTI | mAP@[0.5:0.95] | +4.6 to 5.7 |
| Raw-KITTI | mAP@[0.5:0.95] | Performance gap reduced to 1.3% |
Tip: Transfer learning helps you achieve better object detection results, even when you have limited data or face challenging environments.
Anomaly Detection
You can use transfer learning for anomaly detection to spot unusual patterns or defects in images. In the retail industry, computer vision systems powered by transfer learning identify product anomalies and counterfeit items. This improves quality control and reduces losses. You do not need thousands of labeled images. The model learns from a few examples and still finds rare defects. This method also works well in manufacturing, where you need to catch faults early.
Industry Use Cases
Transfer learning supports many industry applications:
- Healthcare: You can detect diseases in medical images faster and with higher accuracy.
- Autonomous vehicles: Your car can recognize objects and scenes for safer driving.
- Retail: You can analyze customer behavior and spot product anomalies to improve shopping experiences.
- Image recognition: You can use pre-trained models for real-time detection and classification.
| Application Area | Accuracy Improvement |
|---|---|
| Image Recognition | 27% |
| Medical Imaging Diagnosis | 30% |
| Autonomous Driving | Significant boost |
You can also use transfer learning for semantic segmentation, which helps you label each pixel in an image. This is useful in medical imaging and self-driving cars. By combining classification, object detection, and segmentation, you can solve many computer vision challenges across industries.
Benefits
Faster Training
You can train your machine vision system much faster with transfer learning. When you use a pre-trained model, you skip the slow process of learning basic features from scratch. The model already knows how to spot shapes, colors, and patterns. You only need to fine-tune it for your task. This approach leads to a huge speed boost. In one study, transfer learning made training 140 times faster than starting from scratch. You also get higher accuracy, reaching up to 99.9%. The table below shows how transfer learning compares to traditional training:
| Metric | Training from Scratch | Transfer Learning |
|---|---|---|
| Number of training images | 5,520 | 5,520 |
| Classification accuracy | 70.87% | 99.90% |
| Training convergence speed | Baseline | 140 times faster |
| Sparsity measure (last conv. layer) | 8.44% | 90.47% |
| Accuracy after compression | Drops nearly 5% | Drops only 0.48% |
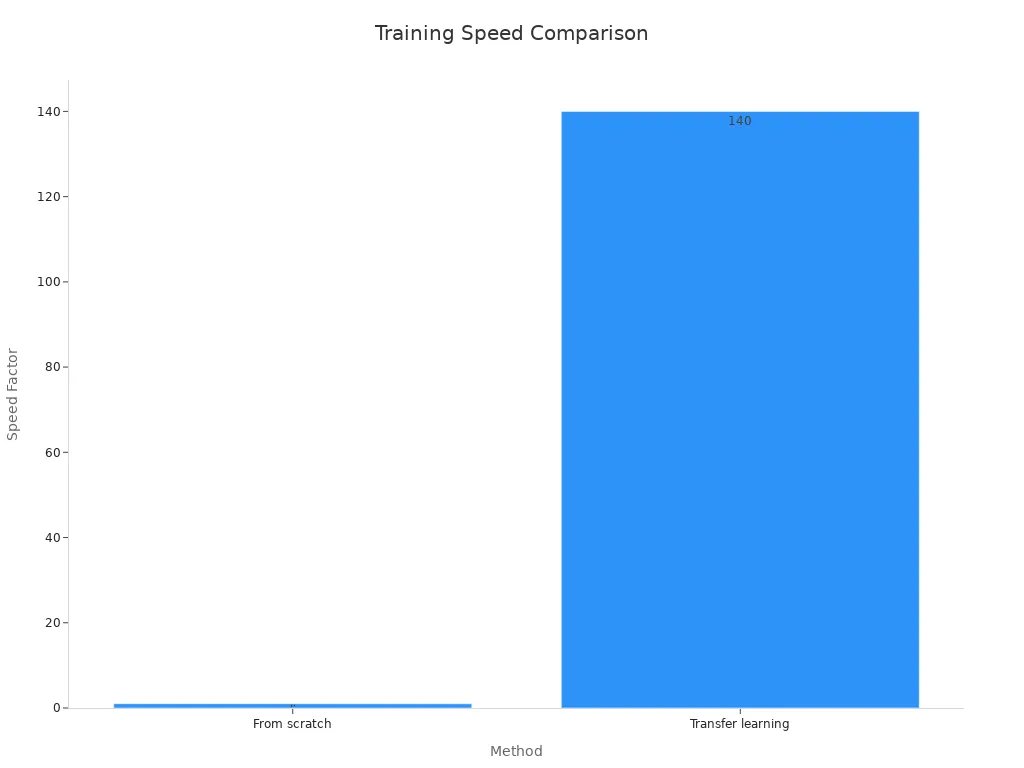
You can see that using a pre-trained model not only saves time but also boosts model performance.
Less Data Needed
Transfer learning helps you get great results with less data. You do not need thousands of images to train your model. Pre-trained models use early layers to capture general features, so you only need to fine-tune the higher layers for your specific task. This method keeps the learned weights and avoids retraining everything. You save both data and time. The similarity between your data and the original dataset affects how well this works, but you often need far fewer samples. For example:
- You can reuse features from a model trained on ImageNet, which means you need a much smaller dataset for your own project.
- By freezing layers in your model, you keep important knowledge and reduce the number of new examples needed.
- Transfer learning often reaches high predictive accuracy, precision, and recall with smaller datasets.
- If your data is noisy, transfer learning helps by starting from robust feature representations.
This approach makes machine vision projects possible even when you have limited data.
Lower Computational Cost
You can lower your computational costs by using transfer learning. Training a model from scratch takes a lot of time and computer power. With transfer learning, you use a pre-trained model and only adjust a few layers. This reduces the training runtime and hardware needs. The table below shows how transfer learning cuts costs and improves model performance:
| Model Type | Dimensionality Reduction | Transfer Learning Sample % | Training Runtime per Iteration | Transfer Learning Runtime | Accuracy on Same Population (%) | Accuracy on Alternate Population (%) |
|---|---|---|---|---|---|---|
| CNN without DR | No | 0% | ~7.2 s | N/A | 99 | 46 |
| CNN without DR | No | 2% | ~7.2 s | 1 min | 99 | 100 |
| CNN without DR | No | 5% | ~7.8 s | 2 min | 99 | 96 |
You can also use dimensionality reduction techniques like PCA or t-SNE to cut computational time by up to five times. Even with just 2% of new data, transfer learning can raise accuracy on new tasks from 46% to nearly 100%. This means you get improved performance and save money on hardware and energy.
Tip: Transfer learning lets you update your model quickly and keep costs low, making it ideal for real-world machine vision systems.
Challenges
Domain Shift
You may notice that your machine vision model works well on one dataset but struggles on another. This problem is called domain shift. It happens when the data you use for training looks different from the data you see in real life. For example, a model trained on clear images may not perform well on blurry or noisy images. Studies show that domain shift can cause your model’s accuracy to drop. Researchers found that models trained on datasets like BP4D-4 or BP4D-10 lose performance when tested on new domains. The mean absolute error (MAE) often increases, but not always in a predictable way. This means domain shift effects are complex and hard to measure with just one metric.
Domain shift also affects feature transferability. In multi-modal tasks, your model may not recognize important patterns if the new data is too different. Some new methods, like Relative Norm Alignment (RNA), help models adapt better to new domains. You can use techniques such as data augmentation, domain adaptation, and continuous monitoring to reduce the impact of domain shift.
- Domain shift causes performance drops when training and testing data differ.
- You can use data augmentation, domain adaptation, and fine-tuning to help your model adjust.
- Special metrics and regular monitoring help you track and manage domain shift.
Task Mismatch
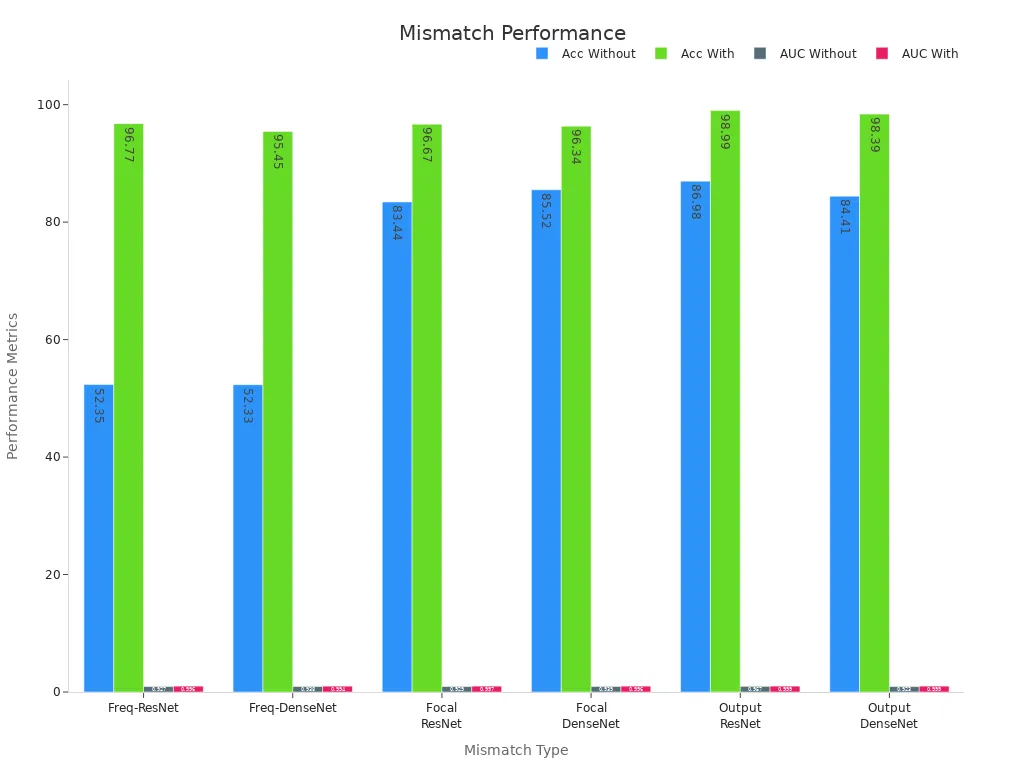
Task mismatch happens when you use a pre-trained model for a job that is too different from its original task. This can lead to big drops in accuracy. For example, if you use a model trained to spot animals to find car parts, the results may not be reliable. Studies show that without calibration, accuracy can fall to near chance levels. After calibration, accuracy improves a lot.
| Mismatch Type | Model | Without Calibration Accuracy (%) | With Calibration Accuracy (%) | Without Calibration AUC | With Calibration AUC |
|---|---|---|---|---|---|
| Frequency | ResNet | ~52.35 | 96.77 | 0.927 | 0.996 |
| Frequency | DenseNet | ~52.33 | 95.45 | 0.938 | 0.994 |
| Focal Location | ResNet | 83.44 | 96.67 | 0.929 | 0.997 |
| Focal Location | DenseNet | 85.52 | 96.34 | 0.939 | 0.996 |
| Output Power | ResNet | 86.98 | 98.99 | 0.957 | 0.999 |
| Output Power | DenseNet | 84.41 | 98.39 | 0.923 | 0.999 |
Best Practices
You can follow several best practices to overcome these challenges:
- Use pre-trained models as fixed feature extractors. These often work better than models built for only one task.
- Fine-tune higher layers of your model while freezing lower layers. This balances general and task-specific features.
- Freeze lower layers to keep basic knowledge and fine-tune higher layers for your new task.
- Apply domain adaptation methods to handle differences between training and real-world data.
- Choose popular pre-trained models like VGG, AlexNet, or Inception for strong results with less data.
Tip: By following these steps, you can boost your model’s accuracy and make it more reliable, even when facing new data or tasks.
Transfer learning gives you powerful tools for machine vision. You can use it for image classification and object detection with less data and higher accuracy. Pretrained models like ResNet show that you only need small datasets to get strong results. You should watch for challenges when tasks or data differ.
When you match tasks and data well, transfer learning saves time and boosts performance. Try it in your next project to see real improvements.
FAQ
What is the main advantage of transfer learning in machine vision?
You can train your model faster and with less data. Pre-trained models already know basic image features. You only need to adjust them for your task. This saves you time and resources.
Can you use transfer learning if you have very little data?
Yes, you can. Transfer learning works well with small datasets. The pre-trained model already understands many patterns. You only need a few examples to fine-tune it for your needs.
Which industries use transfer learning for machine vision?
You see transfer learning in healthcare, automotive, retail, and manufacturing. It helps with tasks like disease detection, object recognition, quality control, and product classification.
Do you need special hardware for transfer learning?
You do not need expensive hardware. Many transfer learning tasks run on regular computers or consumer GPUs. This makes it easy for you to start new projects.
How do you choose the right pre-trained model?
- Look at your task type, such as classification or detection.
- Check which models work best for similar problems.
- Try popular models like ResNet, VGG, or MobileNet for strong results.
See Also
Essential Insights Into Transfer Learning For Machine Vision
Ways Deep Learning Improves The Performance Of Machine Vision
Top Features And Advantages Of Machine Vision In Medical Devices
Understanding Computer Vision Models And Their Role In Machine Vision
The Impact Of Neural Network Frameworks On Machine Vision Technology








