
A single-stage detector machine vision system uses one network pass to perform object detection quickly and directly. These systems skip the region proposal step and predict objects and their locations in images at high speed. Recent models such as YOLOv7 reach 120 frames per second while maintaining reliable accuracy, as shown below.
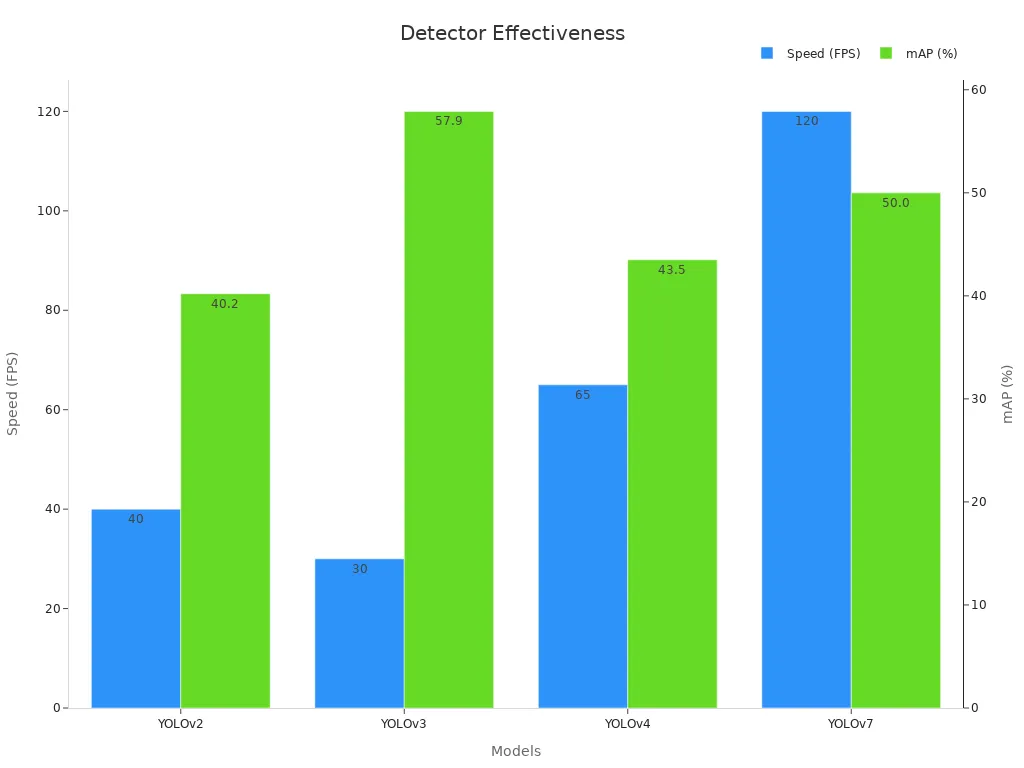
Industries use single-stage detector machine vision system technology in areas like robotics, traffic monitoring, and manufacturing because real-time detection helps increase safety and productivity.
Key Takeaways
- Single-stage detectors perform object detection in one step, making them much faster than two-stage detectors.
- These systems predict object locations and classes directly, skipping extra steps to boost speed and efficiency.
- Models like YOLO and SSD offer real-time detection with good accuracy, suitable for robotics, surveillance, and mobile devices.
- Single-stage detectors handle different object sizes using grids, anchor boxes, or anchor-free methods for flexible detection.
- Choosing between single-stage and two-stage detectors depends on the need for speed or higher accuracy in your application.
Single-Stage Detector Machine Vision System
Core Concept
A single-stage detector machine vision system performs object detection by processing an image in one pass through a convolutional neural network. This approach skips the region proposal stage found in two-stage detectors. Instead, the system predicts bounding boxes and class labels directly from the input image. The pipeline begins with feature extraction using a backbone network, often pre-trained on a large dataset. The backbone removes classification layers and outputs feature maps with reduced spatial size but increased channel depth. These feature maps allow the detector to make object detection predictions for every region of the image at once.
Popular object detection models such as YOLO, SSD, RetinaNet, and FCOS use this single stage approach. Each model adapts the backbone and prediction heads to improve detection and classification. For example, YOLO divides the image into grid cells, with each cell responsible for predicting objects whose centers fall within it. SSD uses multiple grids at different scales, while RetinaNet introduces Focal Loss to address class imbalance. FCOS represents a fully convolutional one-stage object detection method that does not rely on anchor boxes.
Single-stage detectors excel in real-time applications because they combine feature extraction, classification, and bounding box regression into a unified network. This integration leads to high speed and efficiency, making them ideal for dynamic environments.
Empirical studies show that single-stage detector machine vision systems outperform traditional methods in both speed and accuracy. On benchmark datasets, one-stage detectors like YOLO and SSD achieve higher frames per second (FPS) and maintain strong accuracy compared to two-stage detectors. For example, YOLO achieves about 45 FPS with a mean average precision (mAP) of 63.4%, while SSD reaches 59 FPS with a mAP of 79.8% on the VOC2007 dataset. RetinaNet improves average precision by 6-9% over earlier models on the COCO dataset. These results highlight the practical advantages of single-stage detectors for real-time object detection.
Key Features
Single-stage detector machine vision systems offer several key features that set them apart from other object detection models:
- Direct Detection and Classification: The detector predicts bounding boxes and class probabilities in a single forward pass. This fully convolutional one-stage object detection process eliminates the need for a separate region proposal step.
- Grid Cells and Prediction Heads: Models like YOLO and SSD divide the image into grid cells. Each cell contains multiple prediction heads, each specialized for different object sizes and shapes. The detector assigns each ground-truth object to the prediction head with the highest IOU (Intersection over Union) to the ground-truth box. This strategy improves learning and accuracy.
- Anchor Boxes and Multi-Scale Detection: SSD uses multiple grids and anchor boxes at different scales and aspect ratios. This design allows the detector to handle objects of various sizes. YOLO uses anchor boxes derived from k-means clustering on the training dataset, while SSD uses a formula-based approach.
- Confidence Scores and Non-Maximum Suppression: Each prediction head outputs a confidence score indicating the likelihood of an object’s presence. Non-maximum suppression removes overlapping bounding boxes, ensuring only the most confident predictions remain.
- Efficient Training and Robustness: The single-stage approach reduces the need for pixel-level annotation, making it easier to scale to large datasets. Fully convolutional one-stage object detection models like YOLOv5 have demonstrated high precision and recall in medical imaging, with balanced F1 scores and low false positives for certain lesion types.
- Real-Time Performance: Single-stage detectors require fewer computational resources, enabling deployment on edge and mobile devices. This efficiency supports real-time detection in applications such as robotics, surveillance, and manufacturing.
| Model | Backbone | Grid/Anchor Strategy | FPS (VOC2007) | mAP (%) | Notable Feature |
|---|---|---|---|---|---|
| YOLO | Darknet/ResNet | Single grid, anchor boxes | ~45 | 63.4 | Fast, grid-based predictions |
| SSD | VGG-16 | Multi-grid, anchor boxes | ~59 | 79.8 | Multi-scale detection |
| RetinaNet | ResNet + FPN | Anchor boxes, Focal Loss | ~30 | 80+ | Handles class imbalance |
| FCOS | ResNet | Anchor-free, fully conv. | ~35 | 80+ | Anchor-free, dense prediction |
- One-stage detectors like YOLOv5 have achieved high precision (up to 0.927) and recall (around 0.796) in medical object detection tasks, with balanced F1 scores and low mean false positives. These results show that fully convolutional one-stage object detection models can match or exceed the performance of two-stage detectors in many scenarios.
- The assignment of ground-truth objects to prediction heads using IOU ensures that each detector specializes in certain object types or sizes. This specialization, combined with confidence scoring and non-maximum suppression, leads to accurate and reliable object detection predictions.
Real-Time Object Detection
Speed and Efficiency
Single-stage detectors have become the preferred choice for real-time object detection tasks. These detectors process images quickly because they skip the region proposal step and predict all bounding boxes and classes in one network pass. This design allows the detector to analyze each dataset image in milliseconds, making it ideal for applications that require instant feedback.
Lightweight architectures, such as Mini-YOLOv4-tiny, show clear improvements in both speed and efficiency. For example, Mini-YOLOv4-tiny achieves nearly double the inference speed on mobile devices compared to YOLOv4-tiny, while also reducing parameters by 37% and FLOPs by 19%. The model also improves mean Average Precision (mAP) on the PASCAL VOC dataset by 0.3% and on the MS COCO dataset by 2.8%. The Intersection over Union (IoU) increases by 4.02%, which means the detector matches ground-truth boxes more accurately.
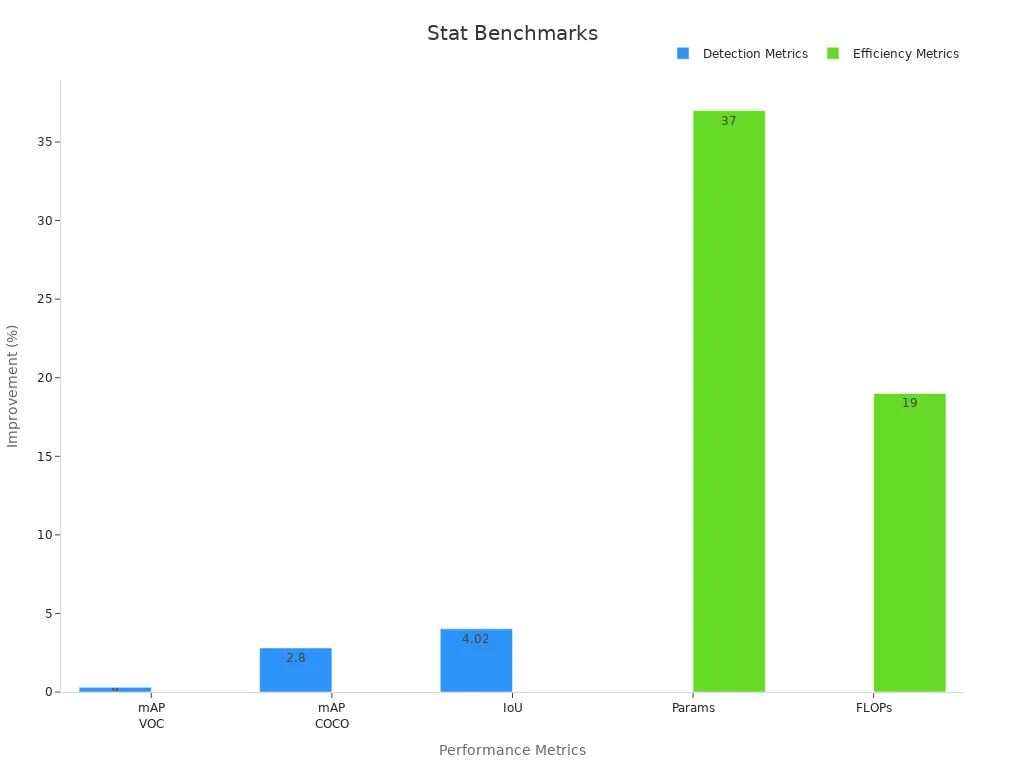
Comparing different models on the same dataset highlights the efficiency of single-stage detectors. For instance, YOLOv8 processes each image in 25 milliseconds and achieves a mAP of 55.2%. YOLOv5, another popular detector, takes 30 milliseconds per image with a mAP of 50.5%. These models use smaller architectures, which makes them easier to deploy on edge devices. In contrast, two-stage detectors like Faster R-CNN and Mask R-CNN require more time per image and use larger models, making them less practical for real-time deployment.
| Model | Inference Speed (ms/image) | Accuracy (mAP@0.5) | Notes on Efficiency and Deployment |
|---|---|---|---|
| YOLOv8 | 25 | 55.2% | Fast, small model, real-time use |
| YOLOv5 | 30 | 50.5% | Baseline, slower than YOLOv8 |
| RetinaNet | N/A | Good | Slower than YOLO, good accuracy |
| Faster R-CNN | Slower than single-stage | Higher precision | Not suited for real-time tasks |
Applications
Industries rely on single-stage detectors for many real-time object detection tasks. Robotics, surveillance, and embedded systems benefit from the speed and efficiency of these detectors. In robotics, the detector must process each dataset image quickly to help machines react to their environment. Surveillance systems use detectors to scan video feeds and identify objects or people in real time. Embedded systems, such as those in smart cameras or drones, need lightweight models that can run on limited hardware.
Recent advances in detector design have improved both accuracy and efficiency. For example, YOLOv9 achieves a mean Average Precision of 72.8% on the MS COCO dataset, with an inference time of only 23 milliseconds per image. The model size drops to 58 MB, making it suitable for edge deployment. YOLOv9 also reduces parameters by 49% and computational requirements by 43% compared to YOLOv8, while increasing mAP by 0.6%. These improvements allow the detector to match ground-truth objects more closely and handle larger datasets with less hardware.
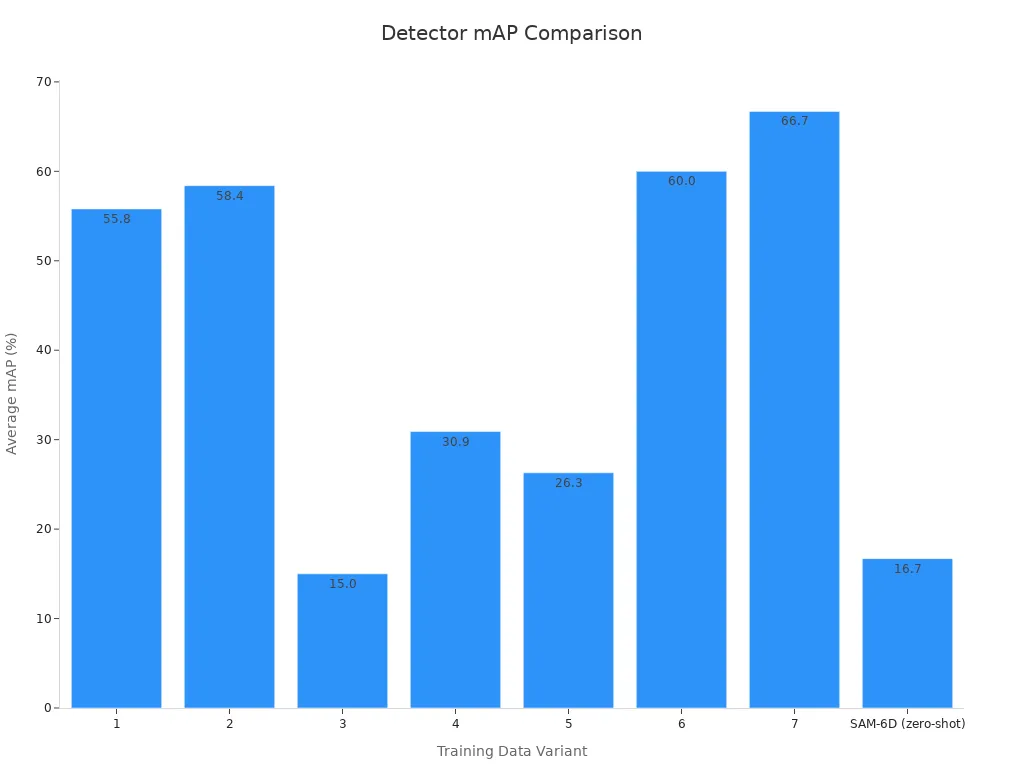
In industrial settings, combining synthetic and real dataset images with data augmentation leads to higher average mAP and better generalization. For example, a detector trained on both synthetic and real data achieves an average mAP of 66.7% and shows strong precision and recall. This approach helps the detector recognize ground-truth objects in complex environments. The ability to process large datasets and match ground-truth labels quickly makes single-stage detectors the top choice for real-time object detection in modern applications.
One-Stage Object Detection vs Two-Stage

Workflow Differences
One-stage object detection and the two-stage approach use different detection pipelines. In a one-stage system, the detector processes the image in a single pass. The detector predicts bounding boxes and class labels directly from the feature map. This pipeline skips the region proposal step. The detector uses anchors on the feature map and applies IOU to match predictions with ground-truth objects. Each prediction head calculates IOU with ground-truth boxes to assign detections. The detector then uses IOU again during non-maximum suppression to keep only the best bounding boxes.
Two-stage detectors, such as Faster R-CNN, follow a more complex pipeline. The first stage uses a Region Proposal Network (RPN) to generate candidate regions. The detector then applies ROI pooling to extract features from these proposals. The second stage classifies each region and refines the bounding box. This process uses IOU to match proposals with ground-truth objects at both stages. The table below highlights key workflow differences:
| Aspect | Two-Stage Detectors (e.g., Faster R-CNN) | One-Stage Detectors (e.g., RetinaNet) |
|---|---|---|
| Workflow | Two-step: RPN then classification | Single-pass, direct prediction |
| Region Proposal | RPN generates anchors and proposals | Anchors used directly on feature maps |
| ROI Pooling | Present, adds overhead | Absent, streamlined |
| Training Efficiency | Slower, more computationally intensive | Faster, efficient |
| Handling Non-Differentiable Components | Uses approximations for ROI pooling | Uses differentiable loss functions |
| Practical Implication | High accuracy, higher cost | Real-time, efficient |
Accuracy and Use Cases
The choice between one-stage and two-stage detectors depends on the need for speed or high accuracy. One-stage detectors, such as YOLO and RetinaNet, excel in real-time detection tasks. The detector matches predicted boxes to ground-truth objects using IOU, ensuring fast and stable detection accuracy. In scenarios like autonomous vehicles or surveillance, the detector must process images quickly. The detection pipeline uses IOU to compare each predicted box with ground-truth labels, keeping latency low.
Two-stage detectors, like Faster R-CNN, achieve high accuracy in complex environments. The detector uses IOU at each stage to match proposals and predictions with ground-truth objects. This method works well for medical image analysis, facial recognition, and satellite imagery, where detection accuracy is critical. Comparative studies show that one-stage object detection maintains stable accuracy on high and medium-quality images, while the two-stage approach performs better on low-quality images. In real-world tests, YOLOv8 achieves higher accuracy on most datasets, but Faster R-CNN outperforms it in challenging cases. The detection pipeline in both systems relies on IOU and ground-truth matching to ensure reliable results.
Tip: When choosing a detector, consider the application. For real-time tasks, one-stage detectors offer speed and efficiency. For tasks that demand high accuracy, the two-stage approach may be better.
Technical Details
Loss Functions
Single-stage detectors use loss functions to improve predictions and handle class imbalance in the dataset. Focal Loss, used in RetinaNet, helps the model focus on hard-to-detect objects by reducing the confidence given to easy negatives. This approach increases accuracy, especially when the dataset has many more background objects than target objects. Studies show that Focal Loss and related losses outperform others as the dataset becomes more imbalanced. For example, Focal Loss can boost accuracy by about 5% in object detection tasks. Researchers also use metrics like F1-score and ROC curves to compare loss functions. These metrics measure how well the model matches predictions to ground-truth objects. Technical documentation describes how loss functions combine classification and regression terms, using IOU to match predictions with ground-truth boxes. While some studies do not isolate loss function performance, they show that better loss functions lead to higher confidence in predictions and improved accuracy.
Anchor-Based and Anchor-Free
Single-stage detectors use either anchor-based or anchor-free methods to generate predictions. Anchor-based models like YOLO and SSD place preset anchor boxes on the feature map. The model then adjusts these boxes to match ground-truth objects in the dataset. However, preset anchors may not cover all object sizes, leading to lower IOU and less confidence in predictions. Anchor-free models, such as FCOS, predict object centers directly without using anchor boxes. Recent comparisons show that anchor-free methods achieve similar or better accuracy than anchor-based ones, especially for small objects. For example, an anchor-free method reached a mean average precision close to multi-stage models on a challenging dataset, with only a 0.3% difference. Anchor-free models also show higher IOU and confidence when matching predictions to ground-truth objects, making them robust for diverse datasets.
| Method | Dataset | mAP | IOU | Notes |
|---|---|---|---|---|
| YOLOv4 (anchor-based) | DIOR | 24.5% | Low | Lower accuracy for wide object sizes |
| Anchor-free | DIOR | ~Cascade-RCNN | 49.8% | Better for small object detection |
Training Considerations
Training single-stage detectors requires careful handling of the dataset, IOU thresholds, and ground-truth assignments. The model must learn to match predictions to ground-truth boxes using IOU. Setting the right IOU threshold ensures that only high-confidence predictions count as correct detections. If the threshold is too low, the model may accept poor matches, reducing accuracy. If too high, it may miss true objects. Data augmentation helps the model generalize by exposing it to varied dataset images. The model also needs balanced ground-truth labels to avoid bias. During training, the model adjusts its confidence in each prediction based on how well it matches the ground-truth object. Researchers recommend monitoring confidence scores and IOU during training to ensure the model improves accuracy and reliability across the dataset.
Single-stage detector machine vision systems deliver fast, accurate object detection for real-time applications. They suit resource-limited environments and dynamic tasks, such as robotics or agriculture, where speed matters most.
- Two-stage detectors offer high accuracy but require more computing power.
- Single-stage detectors like YOLOv10 and RetinaNet provide rapid inference and efficient models.
- Choosing the right system depends on application needs and available resources.
| Detector | Key Advantages | Performance Highlights |
|---|---|---|
| YOLOv10 | Real-time speed, end-to-end training | 1.8x faster than RT-DETR-R18, 46% lower latency |
| RetinaNet | Handles class imbalance, multi-scale detection | State-of-the-art accuracy, faster than two-stage models |
| EfficientDet | Flexible scaling, efficient backbone | Small, fast, accurate for mobile and edge devices |
Decision-makers can use multi-criteria analysis to match detection systems with specific goals, ensuring the best fit for each scenario.
FAQ
What makes a single-stage detector different from a two-stage detector?
A single-stage detector predicts object locations and classes in one step. A two-stage detector first finds possible object regions, then classifies them. Single-stage detectors work faster and suit real-time tasks.
Can single-stage detectors run on mobile devices?
Yes, many single-stage detectors use lightweight models. These models need less memory and power. Devices like smartphones and drones can use them for fast object detection.
Are single-stage detectors accurate enough for safety applications?
Single-stage detectors like YOLO and RetinaNet reach high accuracy. Many industries use them for safety tasks, such as monitoring traffic or machines. They balance speed and accuracy well.
How do single-stage detectors handle different object sizes?
Most single-stage detectors use anchor boxes or multi-scale grids. These features help the system find both small and large objects in images. Some models, like FCOS, use anchor-free methods for better flexibility.
See Also
Understanding How Electronics Power Machine Vision Systems
The Role Of Cameras Within Machine Vision Technology
How Image Processing Enhances Machine Vision Systems








