
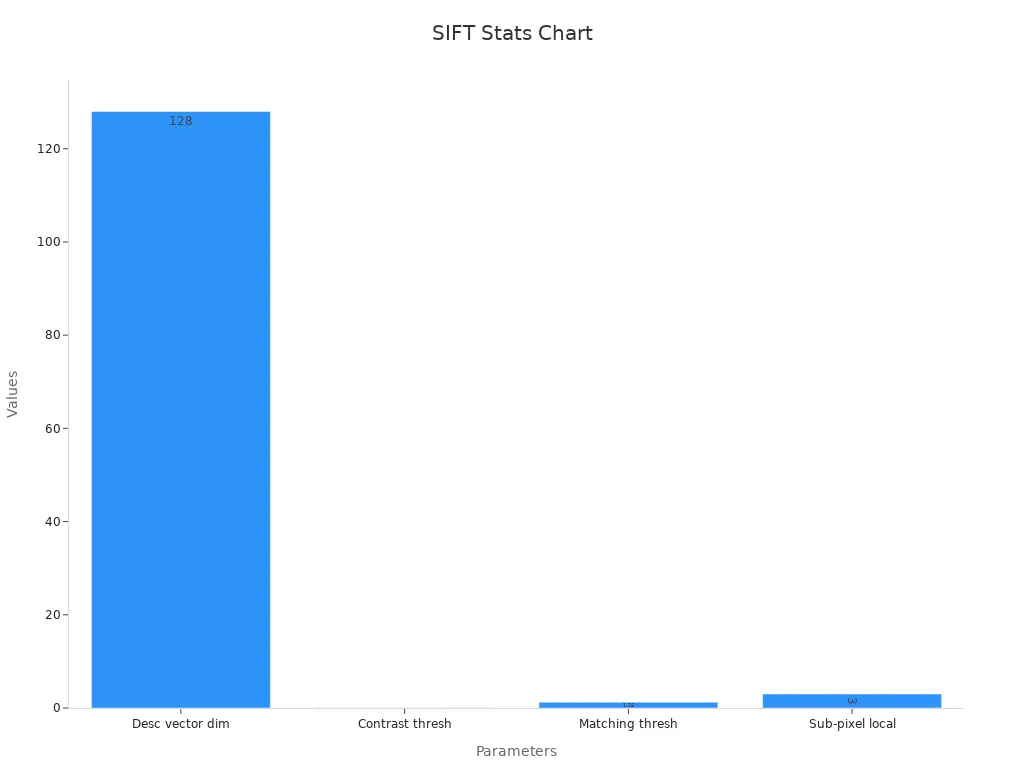
SIFT, or the scale-invariant feature transform, is a key technique in the sift scale-invariant feature transform machine vision system. This method helps computers find and describe important parts of an image, even when the image changes in size, angle, or lighting. SIFT uses a 128-dimensional descriptor vector for each keypoint, which allows for strong matching between images. The sift scale-invariant feature transform machine vision system uses a Difference-of-Gaussian approach to detect keypoints and ensures stability with a contrast threshold of 0.03.
Researchers first introduced SIFT in 1999 to address challenges in computer vision. This algorithm helped make object recognition more reliable, even before deep learning became popular. SIFT’s design allows it to perform well in different vision tasks, making it a foundation for object recognition and other applications.
Key Takeaways
- SIFT helps computers find important image features that stay the same even if the image changes size, angle, or lighting.
- The algorithm detects and describes keypoints using a step-by-step process that makes matching images reliable and accurate.
- SIFT works well in many applications like object recognition, image stitching, 3D reconstruction, and forgery detection.
- While SIFT is very accurate and robust, it requires more computing time than some newer methods like ORB or SURF.
- SIFT is now free to use and can be combined with other algorithms to improve speed or accuracy in machine vision tasks.
SIFT Scale-Invariant Feature Transform Machine Vision System
SIFT Overview
The sift scale-invariant feature transform machine vision system uses the scale-invariant feature transform algorithm to find and describe important points in images. SIFT stands out as a powerful tool for feature detection in computer vision. It helps computers recognize objects and match images, even when the images change in size, angle, or lighting. Technical documentation shows that SIFT detects interest points and summarizes local image structures using gradient statistics. This approach gives high hit rates and strong performance in real-world vision tasks. SIFT also works well with other methods, such as Harris corner detection, to speed up object recognition while keeping high accuracy.
Scale and Rotation Invariance
The sift scale-invariant feature transform machine vision system provides strong scale and rotation invariance. SIFT achieves this by building a scale space with Gaussian filters at different sizes. The algorithm finds keypoints as local peaks in this scale space, making it possible to detect features at many scales. SIFT assigns an orientation to each keypoint based on local gradients, which allows the system to recognize objects even if they appear rotated. Studies in biomedical imaging show that SIFT’s multi-resolution approach and orientation assignment keep keypoints stable under different imaging conditions. This makes SIFT a reliable choice for feature detection in changing environments.
Robustness and Accessibility
SIFT offers robustness to noise and changes in lighting. The sift scale-invariant feature transform machine vision system uses descriptors that remain stable even when images have noise or different brightness. Peer-reviewed studies show that SIFT outperforms other algorithms like SURF and ORB in matching accuracy, especially in tough conditions. SIFT’s design also makes it accessible for many users. The algorithm works with different imaging setups and does not require special hardware. SIFT’s patent status changed in recent years, making it more available for research and commercial use. This accessibility has helped SIFT become a standard computer vision algorithm for feature detection and matching.
SIFT Algorithm Steps

The SIFT algorithm uses a stepwise process to detect keypoints and describe them for reliable image matching. Each step builds on the previous one, making the system robust to changes in scale, rotation, and lighting. Researchers have validated these steps using explainable AI techniques and empirical studies, showing that each phase plays a critical role in accurate classification and matching.
Scale-Space Extrema Detection
SIFT begins by building a scale-space representation of the input image. The algorithm applies Gaussian blur at different scales to create multiple versions of the image. By subtracting one blurred image from another, SIFT forms a Difference of Gaussian (DoG) image. The system then scans these DoG images to detect keypoints as local maxima and minima across both space and scale. This process helps SIFT detect keypoints that remain stable even when the image size changes.
Researchers found that using four octaves and five blur levels balances detection performance and computational cost. The DoG approach efficiently approximates the Laplacian of Gaussian, which is important for finding stable feature keypoints. Studies show that this method provides high repeatability and robustness, even in real-time systems that process up to 70 frames per second.
Keypoint Localization
After detecting candidate keypoints, SIFT refines their positions for greater accuracy. The algorithm uses a second-order Taylor series expansion of the DoG function to adjust each keypoint’s location in both space and scale. This step achieves sub-pixel and sub-scale accuracy, which is vital for precise matching.
SIFT then filters out unstable keypoints. The system removes points with low contrast, which are likely to be caused by noise. It also eliminates keypoints that lie on edges by analyzing the Hessian matrix. Only stable and well-localized keypoints remain, which improves the reliability of the feature keypoints used in later steps.
- Accurate localization reduces false positives and increases the repeatability of keypoints detected. This step ensures that the keypoints used for matching are both meaningful and robust to changes in the image.
Orientation Assignment
SIFT assigns an orientation to each keypoint to achieve rotation invariance. The algorithm calculates the gradient magnitude and direction around each keypoint using Gaussian-smoothed images. It then creates a histogram of gradient orientations within a window centered on the keypoint.
The highest peak in the histogram determines the main orientation. If other peaks are close in value (within 80% of the highest), SIFT assigns multiple orientations to the same keypoint. This method allows the system to recognize keypoints even if the image rotates.
Studies show that orientation assignment helps SIFT retain most keypoints detected across different scales. For example, when the image resolution is halved, SIFT still keeps major features, demonstrating the effectiveness of this step in maintaining invariance.
Keypoint Descriptor
Once SIFT assigns orientations, it builds a keypoint descriptor for each keypoint. The descriptor captures the local image gradients in a region around the keypoint, rotated to the assigned orientation. SIFT uses a 128-dimensional vector to represent each keypoint descriptor, summarizing the local structure in a way that is robust to changes in scale, rotation, and illumination.
Researchers have developed benchmarks to test the performance of SIFT descriptors. These benchmarks use tasks like keypoint verification, image matching, and keypoint retrieval to measure how well the descriptors perform under different conditions. The results show that SIFT descriptors provide high accuracy and repeatability, even when images undergo geometric or lighting changes.
- The keypoint descriptor step is crucial for distinguishing between different keypoints and ensuring reliable matching across images.
Keypoint Matching
In the final step, SIFT uses the keypoint descriptors to perform keypoint matching between images. The algorithm compares each descriptor from one image to those in another, usually by finding the nearest neighbor in descriptor space. This process identifies pairs of matching keypoints that likely correspond to the same physical feature in both images.
Experimental comparisons show that SIFT’s keypoint matching remains robust in many real-world scenarios. While newer learning-based methods can outperform SIFT in some benchmarks, SIFT still provides strong generalizability, especially when the data comes from different domains or when training data is limited. SIFT’s matching strategies, such as nearest neighbor and mutual nearest neighbor, help maintain high accuracy even in challenging conditions.
SIFT’s stepwise approach, from detecting keypoints to matching them, has proven effective in diverse applications, including cybersecurity, remote sensing, and real-time video analysis. Each step contributes to the overall robustness and reliability of the sift algorithm.
Applications of SIFT

Object Recognition
SIFT plays a major role in object recognition. The algorithm detects keypoints that remain stable even when objects change in size, angle, or lighting. These keypoints help computers identify objects in different scenes. Researchers have tested SIFT in many object recognition tasks. They found that SIFT provides high accuracy and repeatability. Some important studies include:
- Lowe’s 2004 paper in the International Journal of Computer Vision, which gives detailed performance data on SIFT.
- Ke and Sukthankar’s 2004 work on PCA-SIFT, which compares numerical results.
- Mikolajczyk and Schmid’s 2005 evaluation of local descriptors, including SIFT, with quantitative metrics.
- The 2016 IEEE conference paper on SIFT and color histograms, which shows SIFT’s effectiveness in object recognition.
- The 2018 arXiv preprint that combines deep learning with SIFT for image classification.
These studies show that SIFT’s keypoints support strong object recognition and image matching, even in tough conditions.
Image Stitching
SIFT is widely used for image stitching. The algorithm finds keypoints in overlapping images and matches them to align and blend the images together. This process creates seamless panoramas or mosaics. SIFT’s robustness to scale, rotation, and viewpoint changes makes it ideal for stitching tasks, such as in medical imaging or landscape photography.
- SIFT handles viewpoint and scale changes better than many other algorithms, which is important for accurate stitching.
- Combining SIFT with nearest neighbor matching and RANSAC improves feature point matching accuracy.
- SIFT-based algorithms can produce natural stitching results, but they depend on the quality of detected keypoints.
3D Reconstruction
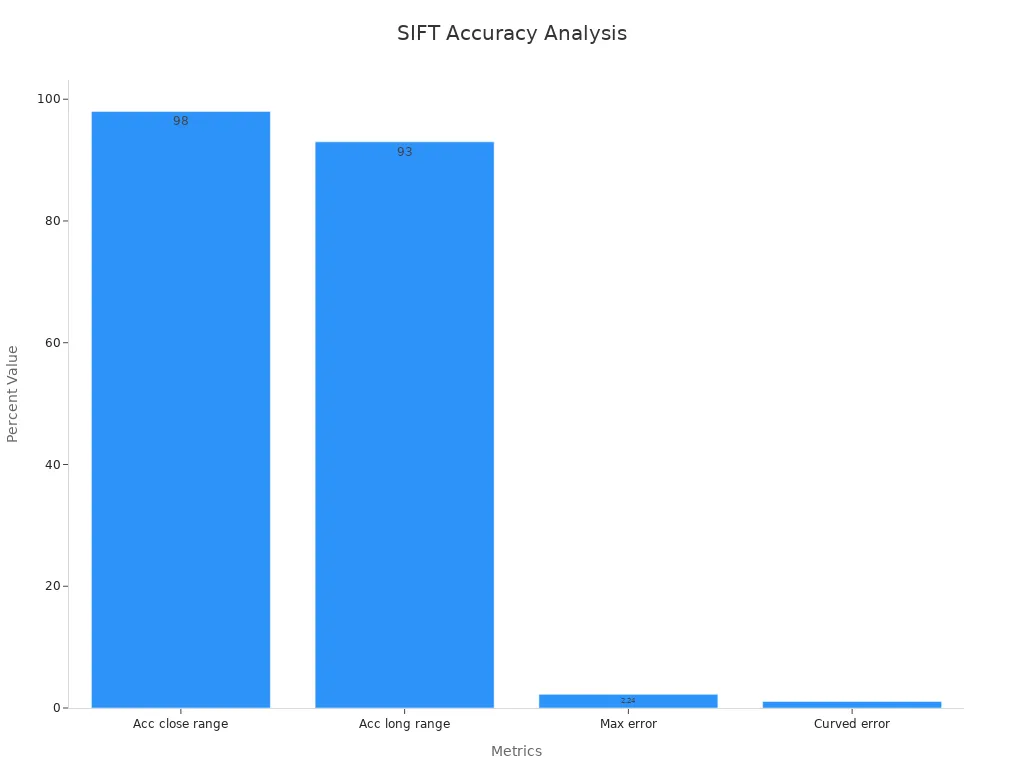
SIFT supports 3D reconstruction by providing reliable keypoints across multiple images. These keypoints allow computers to match features from different views and build 3D models of objects or scenes. Researchers have improved SIFT by combining it with RANSAC and binocular vision. This combination increases matching accuracy and reduces errors in 3D reconstruction tasks.
| Metric | Result with Improved SIFT + RANSAC + BV | Notes/Context |
|---|---|---|
| Matching accuracy (close range) | Up to 98% | Increased from 97% (SIFT alone) |
| Matching accuracy (long range) | Increased from 83% to 93% | After integrating binocular vision (BV) |
| Number of mismatches | As low as 1 | After RANSAC filtering |
| Matching time | Reduced to 1.8 seconds | Decreased by 0.5 seconds compared to baseline |
| Feature points reduced | From 31 to 24 | After BV integration |
| Maximum distance measurement error | 2.24% (planar target at 650 mm) | Error of -14.57 mm |
| Distance measurement error (curved target) | 1.08% (at 700 mm) | Error of 7.58 mm |
These results show that SIFT improves both the accuracy and speed of 3D reconstruction.
Forgery Detection
SIFT helps detect image forgery by finding and matching keypoints in suspicious regions. When someone copies and pastes parts of an image, SIFT can spot repeated keypoints and reveal tampering. Researchers have combined SIFT with optimization algorithms to boost detection rates, even when images have noise or rotation.
| Forgery Condition | Precision (%) | Recall (%) | F1-score (%) | Specificity (%) | Sensitivity (%) |
|---|---|---|---|---|---|
| Original images | 100 | 100 | 100 | 100 | 99.82 |
| Simple forgery images | 100 | 95.6 | 97.75 | 99.02 | 97.36 |
| Forgery with 5° rotation | 94.8 | 94.9 | 94.84 | 92.10 | 89.86 |
| Forgery with 10° rotation | 90.7 | 91.1 | 90.89 | 89.11 | 86.79 |
| Forgery with 15° rotation | 90.1 | 90.5 | 90.29 | 88.33 | 82.56 |
| Forgery with noise | 93.6 | 89.0 | 91.24 | 91.66 | 89.43 |
| Average | 94.86 | 93.51 | 94.16 | 93.37 | 90.97 |
SIFT-based methods achieve high F1-scores, showing strong performance in forgery detection, even under challenging conditions.
SIFT Advantages and Limitations
Strengths
SIFT stands out as a powerful feature detection algorithm in machine vision. It detects keypoints that remain stable under changes in scale, rotation, and lighting. SIFT uses a 128-dimensional descriptor for each keypoint, which helps computers match images with high accuracy. Researchers have shown that SIFT-based systems achieve strong results in object recognition, image stitching, and 3D reconstruction.
A table below highlights SIFT’s accuracy and robustness in different benchmarks:
| Dataset / Benchmark | Method | Testing Accuracy (%) | Notes on Robustness and Distortions |
|---|---|---|---|
| Hand-crafted wheat dataset | DT-CapsNet | 90.86 | Highest accuracy among state-of-the-art methods |
| Stanford Cars, Stanford Dogs, CUB-200-2011 (average) | DT-CapsNet | 91.18 | Improved invariance to geometric distortions |
| CUB-200-2011, Stanford Dogs, Stanford Cars, rice dataset | CapsNetSIFT | 91.03 (testing), 93.97 (training) | High resistance to distortions; outperforms other methods |
SIFT’s keypoints show strong repeatability and distinctiveness, even when images have noise or deformation. The descriptor helps maintain high matching scores across many tasks.
Limitations
SIFT has some drawbacks. The algorithm requires more computation than many alternatives. Processing each keypoint and building its descriptor takes time, especially with large images. Studies show that SIFT runs slower than SURF and ORB. For example, SIFT takes about 116 milliseconds to process 300 keypoints, while ORB only needs 11.5 milliseconds. SIFT also detects fewer keypoints than ORB, which can limit its use in real-time systems.
Researchers note that SIFT’s computational cost makes it less suitable for applications that need fast results. While SIFT remains stable under rotation and lighting changes, its speed does not match newer algorithms.
SIFT vs. Other Algorithms
Comparisons between SIFT and other algorithms help users choose the right tool. The table below summarizes key differences:
| Algorithm | Strengths and Advantages | Trade-offs |
|---|---|---|
| SIFT | Robust to scale and rotation changes; highest matching accuracy; reliable for precise feature detection and matching | Higher computational cost compared to others |
| SURF | Balanced speed and accuracy | Moderate matching accuracy, less robust than SIFT |
| ORB | High computational efficiency; suitable for real-time applications | Moderate accuracy, less robust than SIFT |
SIFT’s keypoints and descriptors provide unmatched accuracy and robustness. However, ORB and SURF offer faster processing and detect more keypoints. SIFT remains the top choice when accuracy and reliability matter most, but speed-focused tasks may benefit from other options.
SIFT stands as a core method in vision tasks. The algorithm detects stable features in images. SIFT gives strong results in object recognition and matching. Many experts use SIFT in computer vision because of its invariance to scale and rotation. SIFT remains a foundation for vision research. The method balances accuracy with higher computational needs. SIFT continues to inspire new ideas and tools. Learners and researchers can explore SIFT to advance their understanding of vision systems.
FAQ
What does SIFT stand for in computer vision?
SIFT stands for Scale-Invariant Feature Transform. It helps computers find and describe important points in images. SIFT works well even when images change in size, angle, or lighting.
Why do machine vision systems use SIFT?
Machine vision systems use SIFT because it finds stable features in images. These features help computers recognize objects, match images, and detect changes. SIFT works well in many real-world situations.
How does SIFT handle changes in image size or rotation?
SIFT builds a scale space and assigns an orientation to each keypoint. This process lets SIFT find the same features even if the image gets bigger, smaller, or rotates.
Is SIFT free to use for research and business?
SIFT became free to use after its patent expired. Now, researchers and companies can use SIFT in their projects without paying fees.
Can SIFT work with other feature detection algorithms?
SIFT can work with other algorithms like Harris corner detection or SURF. Combining methods can improve speed or accuracy in some tasks.
See Also
A Comprehensive Guide To Dimensional Measurement Using Machine Vision
Essential Insights Into Computer Vision And Machine Vision Technologies
Exploring Machine Vision Systems And Computer Vision Model Fundamentals
Key Reasons Machine Vision Systems Are Vital For Bin Picking
Understanding How Machine Vision Systems Detect Flaws Effectively








