
Imagine an ai that tries to spot objects in photos but sometimes makes odd mistakes. A person steps in, gives human feedback, and the ai learns to see things more like people do. This process uses rlhf, which stands for reinforcement learning from human feedback. Rlhf helps ai understand what people expect. By using rlhf, ai combines intelligence with human feedback to make better choices. The RLHF(Reinforcement Learning from Human Feedback) machine vision system lets ai match its intelligence with real human values. Rlhf uses human feedback again and again, so the ai keeps improving and learns what matters most.
Key Takeaways
- RLHF helps AI learn better by using human feedback to guide its decisions and improve accuracy.
- Human feedback makes AI systems safer, more trustworthy, and aligned with what people value.
- RLHF allows AI to learn faster with less data, saving time and resources during training.
- This method works well in real-world tasks like self-driving cars, medical imaging, and factory inspections.
- Researchers continue to improve RLHF to make AI smarter, more reliable, and easier to train in the future.
What Is Reinforcement Learning from Human Feedback?
RLHF Basics
Reinforcement learning from human feedback, often called RLHF, helps machines learn by using both data and guidance from people. In traditional reinforcement learning, a model learns by trying actions and getting rewards or penalties. RLHF adds a new layer. Here, humans give feedback to help the model understand what is right or wrong. This process uses human-annotated data and benchmark datasets to guide the learning. RLHF makes the model smarter by letting it learn from both its own actions and from human advice.
RLHF works in steps:
- The model tries to solve a task, like recognizing objects in images.
- Humans review the model’s answers and give feedback.
- The model uses this feedback to improve its future decisions.
- The process repeats, so the model keeps learning and getting better.
This method uses reinforcement learning with human feedback to make sure the model’s choices match what people expect. RLHF helps the model learn faster and more accurately than using data alone.
Human Feedback in AI
Human feedback plays a big role in making AI systems better. When people give feedback, they help the model understand what is important. For example, in a study with 1,170 Ugandan students, an AI program used data and human feedback to predict when students would struggle. The program matched expert advice 80% of the time, which helped teachers give support where it was needed most. At the University of Murcia, an AI chatbot answered over 91% of student questions correctly, showing how feedback can improve both accuracy and motivation. Knewton’s adaptive learning system used human feedback to boost student test scores by 62%. These examples show that RLHF can make AI more helpful and reliable.
Note: Human feedback does not always lead to better results in every situation. A review of 106 studies found that human-AI teams did best in creative tasks, but sometimes performed worse in decision-making tasks. The success of RLHF depends on the type of task and the skills of both the human and the AI.
In medical settings, RLHF has shown strong results. In a study with 21 endoscopists and 504 colonoscopy videos, experts used AI advice and human feedback together. This hybrid approach improved accuracy beyond what either humans or AI could do alone. Non-experts who used AI feedback reached expert-level accuracy. These results show that reinforcement learning from human feedback can make AI safer and more effective, especially in high-stakes fields.
Reward Models
Reward models are a key part of RLHF. They help the model decide which actions are good and which are not. In reinforcement learning with human feedback, the reward model uses human-annotated data to score the model’s actions. The model then learns to choose actions that get higher scores.
Researchers use benchmark datasets to test how well reward models work. For example, RewardBench 2 is a benchmark that checks how reward models perform on different tasks. Leading models score 20 or more points lower on RewardBench 2 compared to older tests. In some areas, like following precise instructions or solving math problems, accuracy can drop below 40% or 70%. The Pearson correlation coefficient for RewardBench 2 scores and real-world performance is 0.87, showing a strong link between benchmark results and how well the model works in practice.
| Metric / Example | Description | Quantitative Value / Detail |
|---|---|---|
| RewardBench 2 Accuracy Scores | Multi-domain benchmark for reward models | Leading models score 20+ points lower than previous; some subsets below 40% or 70% accuracy |
| Pearson Correlation Coefficient | Correlation between benchmark and real-world performance | 0.87 overall; strong in factuality and math tasks |
| PPO Training Experiments | Tests with 17 reward models on Tulu 3 8B SFT policy model | Benchmark scores help, but best reward model depends on setup |
| Reward Model Design Insights | Training beyond one epoch and model lineage matter | Training recipes impact RLHF performance |
| Benchmark Design | Uses unseen prompts, best-of-4 evaluation, six domains | More accurate for RLHF and scaling |
| Downstream Use Caution | Highest benchmark score not always best for RLHF | Model lineage and setup are critical |
Reward models help guide the learning process. They use feedback from humans and data from benchmark datasets to shape the model’s behavior. This makes RLHF a powerful tool for building AI systems that act in ways people want.
RLHF (Reinforcement Learning from Human Feedback) Machine Vision System

Human-in-the-Loop Training
The RLHF (reinforcement learning from human feedback) machine vision system uses people to guide the learning process. In this system, humans review the results from the AI and give feedback. The AI then uses this human feedback to update its model. This process repeats many times. Each time, the updated model learns to make better choices.
During training, the AI looks at images and tries to recognize objects or scenes. If the AI makes a mistake, a person steps in and gives feedback. The AI uses this feedback to change how it learns. Over time, the updated model becomes more accurate. The RLHF (reinforcement learning from human feedback) machine vision system depends on this loop. Human feedback helps the AI learn what people care about most.
The training process includes several steps:
- The AI makes a prediction about an image.
- A human checks the prediction and gives feedback.
- The AI uses this feedback to adjust its model.
- The updated model tries again, learning from past mistakes.
This cycle continues until the AI reaches the desired level of accuracy. The RLHF (reinforcement learning from human feedback) machine vision system uses human feedback to improve learning and model optimization. The updated model always reflects the latest feedback from people.
Aligning Vision with Human Values
Alignment means making sure the AI sees the world the way people do. The RLHF (reinforcement learning from human feedback) machine vision system focuses on this goal. Human feedback helps the AI understand what is important in each image. For example, in object recognition, people can tell the AI which objects matter most. In scene understanding, humans can point out details that the AI might miss.
The RLHF (reinforcement learning from human feedback) machine vision system uses alignment to match AI decisions with human judgment. This process helps the AI avoid mistakes that do not make sense to people. When the AI receives feedback, it updates its model to better fit human values. The updated model learns to focus on the right details in each image.
Alignment also helps in tasks like anomaly detection. If the AI misses something unusual, a human can give feedback. The AI then learns to spot these rare events in the future. The RLHF (reinforcement learning from human feedback) machine vision system uses this feedback to improve both accuracy and trust. The updated model always aims to match human expectations.
Sample Efficiency
Sample efficiency means the AI learns more from less data. The RLHF (reinforcement learning from human feedback) machine vision system uses human feedback to reach high accuracy with fewer labeled images. This makes training faster and less expensive. The system uses optimization to get the best results from each piece of data.
Researchers have measured sample efficiency in several ways. The table below shows how different methods perform:
| Method/Framework | Metric | Task/Context | Value |
|---|---|---|---|
| Transformer-PPO-based RL | AUC score | Classification task | 0.89 |
| Active learning framework | F1 score | Using 40% labeled data | 0.70 |
| Auto-weighted RL method | Accuracy | Breast ultrasound dataset | 95.43% |
These results show that the RLHF (reinforcement learning from human feedback) machine vision system can achieve strong performance with less data. The updated model learns quickly and uses each example more effectively.
- State-based approaches show improvements in sample efficiency.
- Reinforcement learning helps optimize camera setups and perception accuracy.
- Joint training of camera design and perception models leads to better results than standard methods.
- These advances support the idea that RLHF improves sample efficiency in vision systems.
The RLHF (reinforcement learning from human feedback) machine vision system uses optimization and human feedback to create updated models that learn faster and perform better. This approach saves time and resources while keeping the AI aligned with human needs.
RLHF vs. Traditional Reinforcement Learning
Key Differences
RLHF and traditional reinforcement learning use different ways to teach machines. RLHF depends on human feedback to guide the learning process. Traditional reinforcement learning uses fixed reward signals, often set by programmers. RLHF focuses on alignment with human values, while traditional methods may miss what people care about.
The table below shows how RLHF (using GRPO) and a newer reinforcement method (REINFORCE++) compare:
| Aspect | GRPO (Traditional RLHF) | REINFORCE++ (Newer RL Method) |
|---|---|---|
| Training Dataset Performance | Near perfect (≈100 on AIME-24) | Moderate (≈71 on AIME-24) |
| Test Dataset Performance | Very poor generalization (≈0 on AIME-25 Pass@1) | Better generalization (≈2.5 Pass@1, 40 Pass@16) |
| Out-of-Distribution (OOD) Scores | Lower (e.g., 18.96 on AIME-24 Pass@8) | Higher (e.g., 21.04 on AIME-24 Pass@8) |
| Response Length | Shorter (≈30 to 600 tokens) | Longer (≈425 to 1000 tokens) |
| Overfitting Tendencies | Rapid convergence, overfits small datasets | Gradual improvement, more stable convergence |
| Robustness to Prompt/Reward Models | Less robust, prone to overfitting | More robust, eliminates need for prompt truncation |
| Performance on Complex/OOD Tasks | Deteriorates significantly with task difficulty | Maintains stability and better scores (e.g., 36 vs 20 in 8-person OOD scenario) |
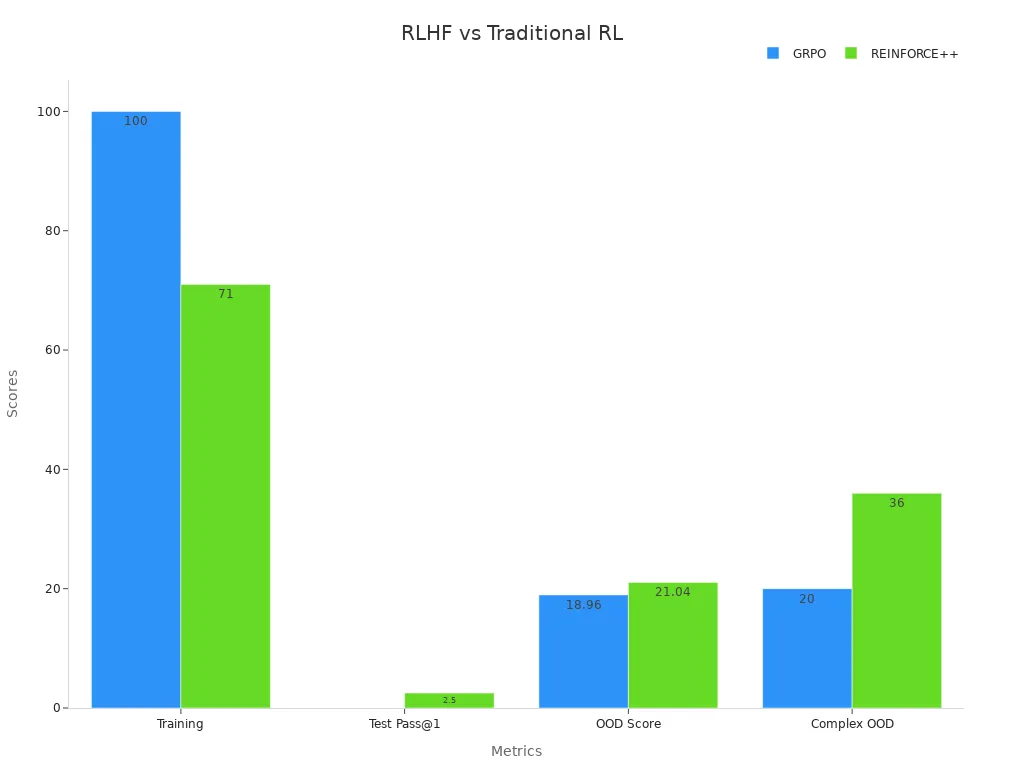
Traditional RLHF methods often use a reward model trained on human preferences and a critic to guide learning. Newer reinforcement learning methods, like REINFORCE++, can skip some of these steps. This change helps models learn more efficiently and develop better reasoning.
When to Use RLHF
RLHF works best when tasks need alignment with human values. Researchers use RLHF in the final stages of training large models, such as language or vision systems. These tasks often have goals that are hard to write as simple rules. RLHF lets machines learn from real-time human feedback, making their answers safer and more helpful.
For example, RLHF helped improve ChatGPT by letting people rate and guide its answers. This process made the chatbot more user-friendly. RLHF also works well when tasks need careful judgment or when people want the AI to match their own values. Using feedback from many people helps avoid bias and makes the system more robust.
Limitations
RLHF has some challenges. Human feedback can be inconsistent or biased. Sometimes, the reward model does not match true human values, so the AI might find shortcuts that do not help real users. RLHF also needs more computing power because it must train both the main model and the reward model.
Oversight is hard because people cannot check every answer. Some newer methods, like Direct Preference Optimization, skip the reward model and can be simpler and more stable. RLHF can still capture subtle human judgments, but it may not always be the most efficient or reliable choice for every task.
Note: RLHF remains a strong tool for alignment, but researchers continue to look for ways to make it more stable, fair, and efficient.
Applications and Benefits

Real-World Use Cases
Many industries now use rlhf to improve ai vision systems. In autonomous vehicles, engineers use human feedback to help cars recognize road signs, pedestrians, and obstacles more accurately. Medical imaging teams apply rlhf to train ai models that spot tumors or unusual patterns in scans. This approach helps doctors make better decisions. Industrial inspection also benefits from rlhf. Factories use ai to check products for defects, and human reviewers give feedback to fine-tune the system. Google Research and DeepMind have shown that rlhf can boost the quality of generative image models. Human annotators rate thousands of images for realism and accuracy. Their feedback helps train reward models, which then guide the ai to create better images. Open-source projects like ImageReward use rlhf with models such as Stable Diffusion, showing that these methods work across different ai architectures.
Performance and Trust
Rlhf makes ai systems more accurate and trustworthy. Researchers have found that the RISE approach increases reasoning accuracy to 42.9% for the 7B model, compared to only 11.3% for standard methods. RISE also improves self-verification, reaching 74.5% accuracy, while Zero-RL only gets 26.8%. These gains remain strong across different model sizes. Test-time strategies, like self-verification and majority voting, push accuracy even higher. For example, RISE-7B achieves 49.8% accuracy with verification-weighted majority voting. The COBRA framework also shows that rlhf can make ai more robust. COBRA scores 64% correct, much higher than the baseline of 35.81%. It uses trusted groups and special techniques to prevent overfitting and data leaks.
- Rlhf helps ai systems align with human preferences.
- These improvements build trust in ai for important tasks.
Safety and Ethics
Rlhf supports safer and more ethical ai. GPT-4, after rlhf, reduces the chance of producing disallowed content by 82% compared to GPT-3.5. It also shows better factual accuracy on truthfulness tests. Benchmarks like TruthfulQA and MACHIAVELLI help researchers check if ai models make ethical choices. The COBRA framework uses strict rules to keep training and testing separate, which helps prevent mistakes and bias. These steps make sure ai systems act in ways that match human values and safety needs.
Rlhf not only boosts performance but also helps ai systems become more reliable and ethical in real-world settings.
Future of Reinforcement Learning with Human Feedback
Research Trends
Researchers continue to explore new ways to make RLHF more powerful in machine vision. Many teams now use ensemble models, like Mixture-of-LoRA, to help AI systems work better across different tasks and domains. These models combine the strengths of several smaller models, which helps the AI generalize and adapt. Scientists also focus on direct preference optimization and direct-alignment algorithms. These methods help AI learn from human choices more directly, making the training process faster and more stable. Direct preference optimization allows the system to use feedback without building a separate reward model. Direct-alignment algorithms help the AI match its actions with what people want, even in new situations.
Challenges Ahead
RLHF faces several challenges as it grows. Reward hacking remains a problem. Sometimes, AI systems find shortcuts that trick the reward model instead of truly learning the task. Weight-averaging models and adapter-based approaches can help reduce this risk. Direct preference optimization and direct-alignment algorithms also offer ways to make learning safer and more reliable. Another challenge is the need for efficient training. Large models use a lot of memory and time. Recent advances have cut peak memory use by about 50% and made reward model training up to 90% faster. The reinforcement learning loop now uses around 27% less memory and runs 30% quicker. These improvements help researchers train bigger models without needing more resources.
Next Steps
The future of RLHF in vision systems looks bright. Researchers plan to open source more tools and compare parameter-efficient RLHF with standard methods. This will make it easier for everyone to test and improve these systems. Teams also want to benchmark other fine-tuning methods beyond LoRA to see which works best. Direct preference optimization and direct-alignment algorithms will likely play a bigger role in new vision and vision-language models. Scientists hope to make RLHF more data-efficient, so AI can learn from fewer examples. These steps will help AI systems become smarter, safer, and more useful in real-world tasks.
Reinforcement learning from human feedback changes how machine vision systems learn and grow. Human feedback helps AI make better choices and builds trust in technology. RLHF lets AI see the world more like people do. The future holds many new ideas and tools for RLHF in vision.
Have questions or thoughts about RLHF and machine vision? Share them in the comments below! 👀
FAQ
What does RLHF stand for in machine vision?
RLHF stands for Reinforcement Learning from Human Feedback. This method helps AI systems learn by using feedback from people. The AI improves its decisions based on what humans say is right or wrong.
How does human feedback help AI vision systems?
Human feedback guides the AI to see images more like people do. When a person points out mistakes, the AI learns to avoid them. This process builds trust and improves accuracy.
Can RLHF make AI safer?
Yes. RLHF helps AI avoid harmful or unwanted actions. Human feedback teaches the AI to follow safety rules and respect human values. This makes the system more reliable in real-world tasks.
Where do people use RLHF in vision systems?
Engineers use RLHF in self-driving cars, medical imaging, and factory inspections. These systems need high accuracy and must match human judgment. RLHF helps them reach these goals.
Does RLHF need a lot of data?
No. RLHF often uses less data than other methods. Human feedback helps the AI learn faster from fewer examples. This saves time and resources during training.
See Also
An Introduction To Metrology And Machine Vision Fundamentals
Comparing Firmware-Based Vision With Conventional Machine Systems
A Detailed Guide To Computer And Machine Vision Models
Top Image Processing Tools For Sophisticated Machine Vision
A Clear Explanation Of Thresholding Techniques In Vision Systems









