
Pooling in machine vision refers to a process that condenses information from images by summarizing important feature details, making image data smaller and easier for computers to handle. Pooling helps a pooling machine vision system select key parts of an image, much like someone picking the clearest piece of a puzzle to understand the whole picture. In computer vision, pooling increases speed and accuracy, which is critical for deep machine learning tasks. For example, pooling methods in high-performance deep machine learning systems have achieved accuracy rates as high as 97.59% in object detection, while reducing spatial complexity for faster processing. These benefits make pooling essential for computer vision and every modern pooling machine vision system.
Key Takeaways
- Pooling reduces image data size by keeping important features, making computer vision models faster and more efficient.
- Max pooling and average pooling are common methods that help models focus on key details and reduce noise for better accuracy.
- Pooling layers improve model robustness by ignoring small changes or noise, which helps in tasks like object detection and classification.
- Advanced pooling techniques adapt to different image sizes and combine methods to boost performance and flexibility.
- Pooling is essential in real-world applications like medical imaging, autonomous vehicles, and industrial quality control for faster and more accurate results.
Pooling in Machine Vision
What Is Pooling?
Pooling in machine vision describes a process where a system condenses information from images by summarizing the most important details. A pooling layer acts as a filter that scans across an image, selecting key values from small regions. This operation reduces the size of the data, making it easier for deep learning models to process images efficiently. In a pooling machine vision system, spatial pooling plays a central role by shrinking the spatial dimensions of feature maps while retaining essential features.
Pooling layers in deep learning models downsample and aggregate information from feature maps. They reduce redundancy and computational load, which helps the system focus on the most relevant parts of an image. In convolutional neural networks, pooling reduces the height and width of feature maps but keeps the number of channels the same. This process increases the system’s robustness to small changes in the input and allows deeper layers to see a larger part of the image.
Spatial pooling comes in several forms, such as max pooling, average pooling, and sum pooling. Each method uses a different rule to summarize the information in each region. Max pooling selects the highest value, while average pooling calculates the mean. These pooling techniques help deep learning models reduce overfitting and computational complexity, especially when working with large images.
Some classic deep learning models, like VGG-16 and AlexNet, use max pooling layers to progressively reduce the spatial dimensions of images. Advanced models, such as ResNet, use global average pooling to shrink each feature map to a single value. Adaptive pooling allows networks to handle images of different sizes by adjusting the pooling window. These strategies show how pooling in machine vision helps systems manage data size and maintain accuracy.
- Spatial pooling reduces the spatial dimensions of feature maps by applying fixed operations like max or average pooling, which downsample the data and lower computational complexity.
- Classic deep learning models, including VGG-16 and AlexNet, use max pooling layers to reduce spatial dimensions step by step.
- Advanced models like ResNet use global average pooling to condense each feature map to a single value, showing pooling’s power in dimension reduction.
- Adaptive pooling lets networks handle images of different sizes by changing pooling windows, offering flexible spatial dimension reduction.
- These examples prove that pooling in machine vision effectively reduces spatial dimensions, preserves important features, improves translation invariance, and cuts computational costs.
Why Use Pooling?
Pooling layers offer several advantages for deep learning models in computer vision. By reducing the size of images, pooling layers make it possible for a pooling machine vision system to process data faster and use less memory. This efficiency is crucial for real-time applications, such as object detection and image classification, where speed and accuracy matter.
Pooling also improves the robustness of deep learning models. When a pooling layer summarizes information, it helps the system ignore small changes or noise in the input image. This makes the model more reliable, even when images are not perfect or have slight variations.
The following table shows how different pooling methods affect accuracy and efficiency across standard datasets:
| Dataset | Pool Size | Compared Methods | Improvement by T-Max-Avg over Avg-TopK | Improvement by T-Max-Avg over Max Pooling | Improvement by T-Max-Avg over Average Pooling |
|---|---|---|---|---|---|
| CIFAR-10 | 3 | Avg-TopK | +1.23% | +3.43% | +8.83% |
| CIFAR-10 | 3 | Avg-TopK (optimal acc.) | +0.28% | +4.32% | +10.42% |
| CIFAR-100 | 3 | Avg-TopK | -0.3% | +1.6% | +5.1% |
| CIFAR-100 | 3 | Avg-TopK (optimal acc.) | +0.53% | +4.11% | +6.96% |
| MNIST | 3 | Avg-TopK | +0.24% | +1.05% | +1.35% |
| MNIST | 3 | Avg-TopK (optimal acc.) | +0.01% | +0.43% | +0.44% |
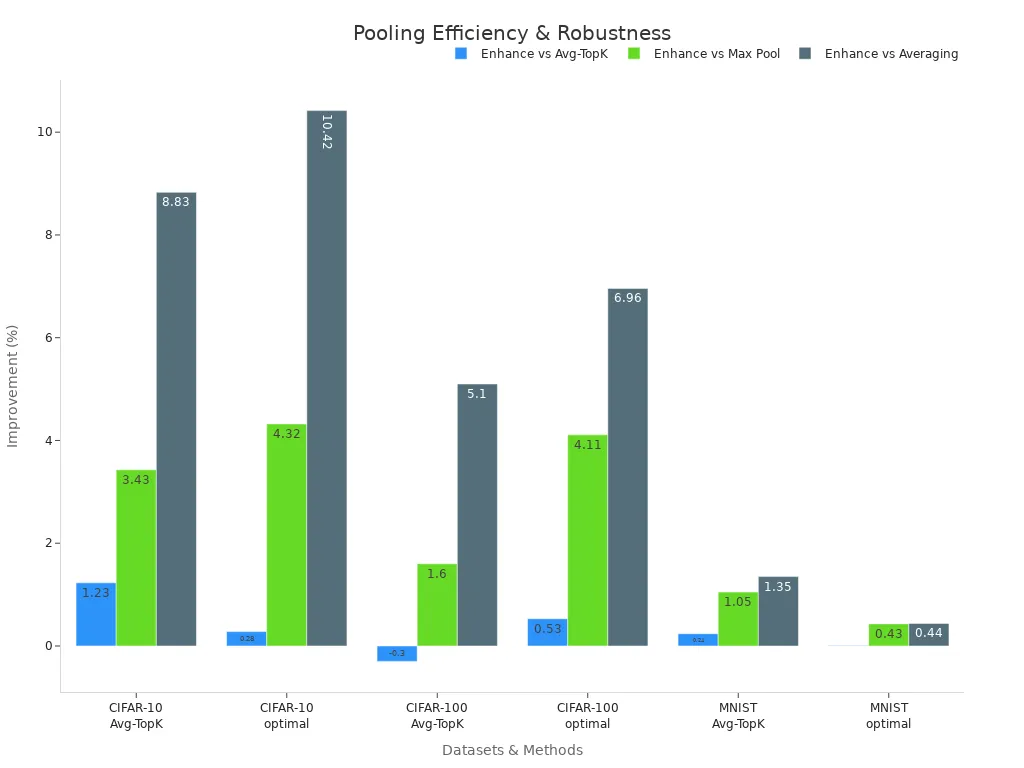
This chart highlights that max pooling usually outperforms average pooling on datasets like CIFAR-10, CIFAR-100, and MNIST. The T-Max-Avg pooling method, a newer approach, consistently achieves higher accuracy than traditional pooling methods. Pool size and parameter settings can further boost performance, showing that careful tuning of pooling layers leads to better results in deep learning models.
Pooling in machine vision not only speeds up processing but also helps deep learning models become more accurate and robust. By reducing the spatial dimensions of images, pooling layers allow deep learning models to focus on the most important features. This makes pooling essential for any modern pooling machine vision system that aims to deliver high accuracy and efficiency in computer vision tasks.
Pooling Layer in Machine Vision Systems
How Pooling Layers Work
A pooling layer plays a vital role in deep learning models. This layer scans feature maps produced by convolutional layers and condenses the information. It does this by selecting or summarizing values from small regions of the image. The main goal is to reduce the spatial size of the data while keeping the most important feature details.
Pooling layers perform two main tasks: downsampling and aggregation. Downsampling means making the image data smaller. Aggregation means combining information from several pixels into a single value. This process helps deep learning models focus on the most important patterns in images.
- Pooling layers reduce the spatial size of feature maps, which helps identify key features and lowers computational complexity.
- Max pooling selects the highest value from each region, preserving the most prominent features.
- Average pooling calculates the mean value, which can help in cases where a more general summary is needed.
- By reducing the number of parameters, pooling layers help control overfitting and make deep learning models more efficient.
- Some advanced pooling methods, like dynamic pooling, adjust the number of features and combine information from different parts of the image.
Pooling layers act as a filter that keeps only the most useful information. This makes deep learning models faster and more robust. When a model uses pooling, it can process images more quickly and with less memory. This is especially important for machine learning tasks like image classification and object detection.
Think of a pooling layer like a camera zooming out to see the bigger picture. Instead of focusing on every tiny detail, the camera captures the most important parts. This helps the system understand the main idea of the image without getting lost in small, unimportant details.
Pooling and Convolutional Neural Networks
Convolutional neural networks rely on pooling layers to manage large amounts of image data. These networks use pooling to shrink the size of feature maps after each convolutional step. This process allows deep learning models to handle complex images without becoming too slow or using too much memory.
Pooling layers in convolutional neural networks help in several ways:
- They enable deep learning models to extract primary features from images, rather than every single detail.
- Pooling layers lower the computational load, making it possible to train deep learning models on large datasets.
- By summarizing information, pooling layers help deep learning models become more robust to small changes or noise in the input images.
- Advanced pooling techniques, such as learnable pooling parameters, allow deep learning models to adapt and improve accuracy. These methods can outperform traditional max pooling or average pooling by preserving more relevant information.
- Experiments show that pooling layers with adaptive or learnable parameters can reduce training errors and boost performance in image classification tasks.
Pooling layers also help deep learning models reduce overfitting. By focusing on the most important features, these layers prevent the model from memorizing every detail in the training images. This leads to better generalization when the model sees new images.
Types of Pooling

Pooling in machine vision uses several techniques for pooling to summarize information from images. The three main types of pooling include max pooling, average pooling, and advanced methods such as sum pooling and global pooling. Each type plays a unique role in computer vision tasks like image classification, image segmentation, and object detection.
Max Pooling
Max pooling stands as one of the most common types of pooling. This method scans a feature map and selects the highest value from each small region. Max pooling helps highlight the strongest features in images, making it easier for convolutional neural networks to detect important patterns. For example, in a 2×2 window, max pooling will pick the largest number, which often represents the most prominent edge or texture in that part of the image. Max pooling reduces the size of feature maps and helps models focus on key details, which improves performance in image classification and segmentation.
Average Pooling
Average pooling calculates the mean value within each pooling window. This technique for pooling produces smoother and less spatially sensitive feature maps compared to max pooling. Average pooling reduces noise and variance, which helps models generalize better. However, it may dilute strong features by averaging, sometimes losing important details. Despite this, average pooling effectively reduces feature map dimensions and lowers computational complexity. The table below shows how average pooling can improve accuracy on standard datasets:
| Dataset | Pooling Method | Accuracy Improvement (%) |
|---|---|---|
| CIFAR-10 | Max Pooling | 6.28 |
| CIFAR-10 | Average Pooling | 16.62 |
| CIFAR-100 | Max Pooling | 7.76 |
| CIFAR-100 | Average Pooling | 25.00 |
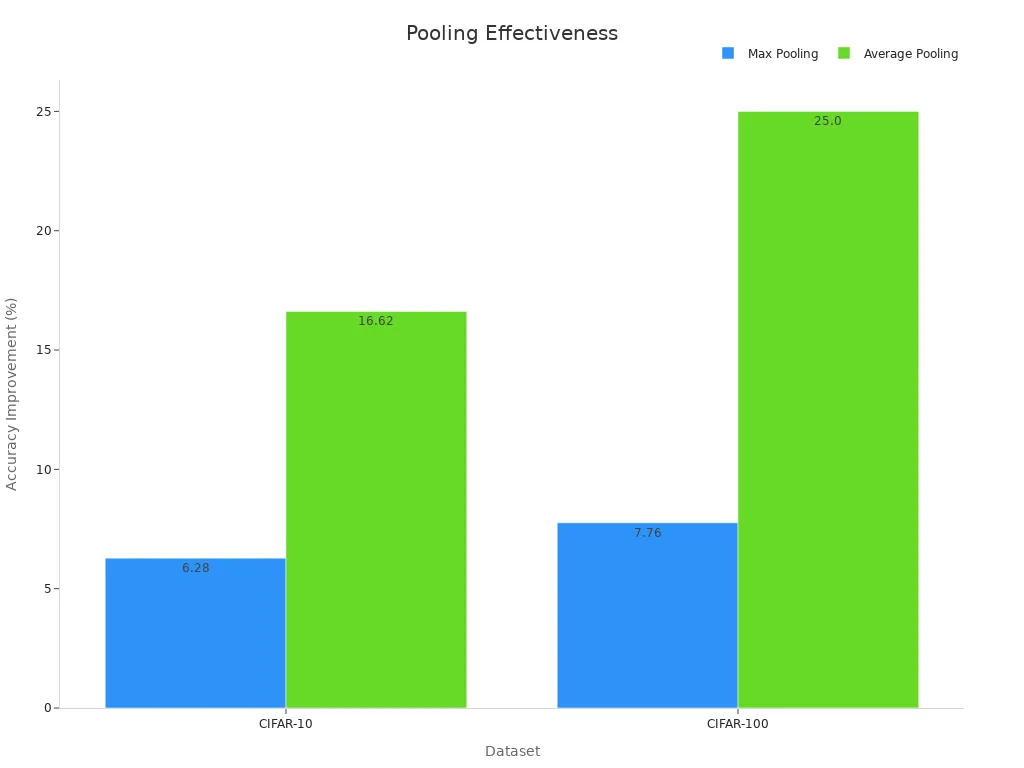
Pooling layers in convolutional neural networks use average pooling to compress data, retain useful information, and speed up training. This process supports better generalization and helps reduce overfitting.
Advanced Pooling Methods
Advanced types of pooling include sum pooling, global pooling, and adaptive pooling. Sum pooling adds all values in a pooling window, which can help in tasks where total intensity matters. Global pooling, such as global average pooling, reduces each feature map to a single value, making models more efficient. Adaptive pooling changes the pooling window size to fit different input images. Researchers have developed new methods, such as the Modified 3-Stage adaptive pooling, which balances efficiency, simplicity, and robustness. Practical examples include:
- Adaptive pooling adjusts window sizes for images of different shapes.
- Hybrid pooling combines max pooling and average pooling for better results.
- Modified 3-Stage adaptive pooling works well in real-world detection, such as pathogen detection in milk, by limiting steps and improving robustness.
These advanced techniques for pooling allow pooling machine vision systems to handle complex image analysis tasks with greater flexibility and accuracy.
Benefits and Drawbacks
Advantages
Pooling in machine vision brings several important benefits to computer vision tasks. Many researchers have found that pooling methods, such as max pooling and global pooling, help convolutional neural networks process images faster. These methods reduce the size of feature maps, which lowers the number of calculations needed. As a result, training and inference become much quicker. For example, studies by Li et al. and Yang et al. show that pooling methods improve both speed and accuracy in object detection and image classification.
- Pooling increases translation invariance, making networks less sensitive to small changes in the input image. This is crucial for tasks like object detection and image segmentation.
- By reducing the number of parameters, pooling helps deep learning models use less memory and train faster.
- Pooling layers support regularization, which helps reduce overfitting. This means the model can perform better on new, unseen images.
- Classic architectures, such as VGG-16 and AlexNet, use max pooling to boost performance in image analysis tasks.
- Advanced pooling techniques, like adaptive and global pooling, allow networks to handle different image sizes and improve accuracy.
Pooling layers act as a simple yet powerful tool for making machine vision systems more efficient and accurate.
Limitations
Despite its many strengths, pooling in machine vision also has some drawbacks. Pooling can sometimes remove important details from images, especially when using large pooling windows. This loss of information may lower accuracy in tasks that require fine details, such as image segmentation.
- Pooling may cause the model to lose spatial information, which can affect tasks that need precise localization.
- Some types of pooling, like average pooling, may dilute strong features, making it harder for the model to detect key patterns.
- Overuse of pooling can lead to underfitting, where the model becomes too simple and fails to capture important features.
- Pooling does not always adapt well to every type of image or task, so careful tuning is needed for best results.
While pooling helps reduce overfitting and speeds up processing, it is important to balance its use to avoid losing critical information.
Applications: Image Classification and More

Image Classification
Pooling in machine vision plays a vital role in image classification tasks. By condensing information from images, pooling layers help convolutional neural networks focus on the most important features. This process improves both speed and accuracy in image analysis. Many real-world systems rely on pooling to handle large volumes of images efficiently.
The following table highlights how pooling supports image classification across different domains:
| Application Domain | Description | Key Performance Metrics / Benefits |
|---|---|---|
| Medical Image Analysis | CNN using average pooling for early-stage tumor detection | 92% accuracy distinguishing benign vs malignant tissue; reduced computational complexity; preserved spatial context; improved generalization |
| Satellite Image Classification | Average pooling applied to land use detection in satellite images | 87.5% classification accuracy; 40% reduction in processing time; better feature preservation than traditional downsampling |
| Facial Recognition Systems | Average pooling used by companies like Apple and Google to smooth features and reduce overhead | Faster processing and matching of facial features across large databases |
| Autonomous Vehicle Perception | Pooling reduces dimensionality of sensor data for real-time decision making | Enables faster, more accurate decisions on road conditions and obstacles |
Pooling techniques, especially average pooling, help preserve critical spatial information and reduce noise. These advantages lead to better generalization and improved performance in image classification and image segmentation tasks.
Object Detection
Pooling in machine vision also enhances object detection. By summarizing feature maps, pooling layers allow models to identify objects in images more accurately and quickly. Detection systems benefit from pooling because it reduces the amount of data the model must process, making real-time detection possible.
The chart below shows how pooling improves detection metrics such as mean Average Precision (mAP):
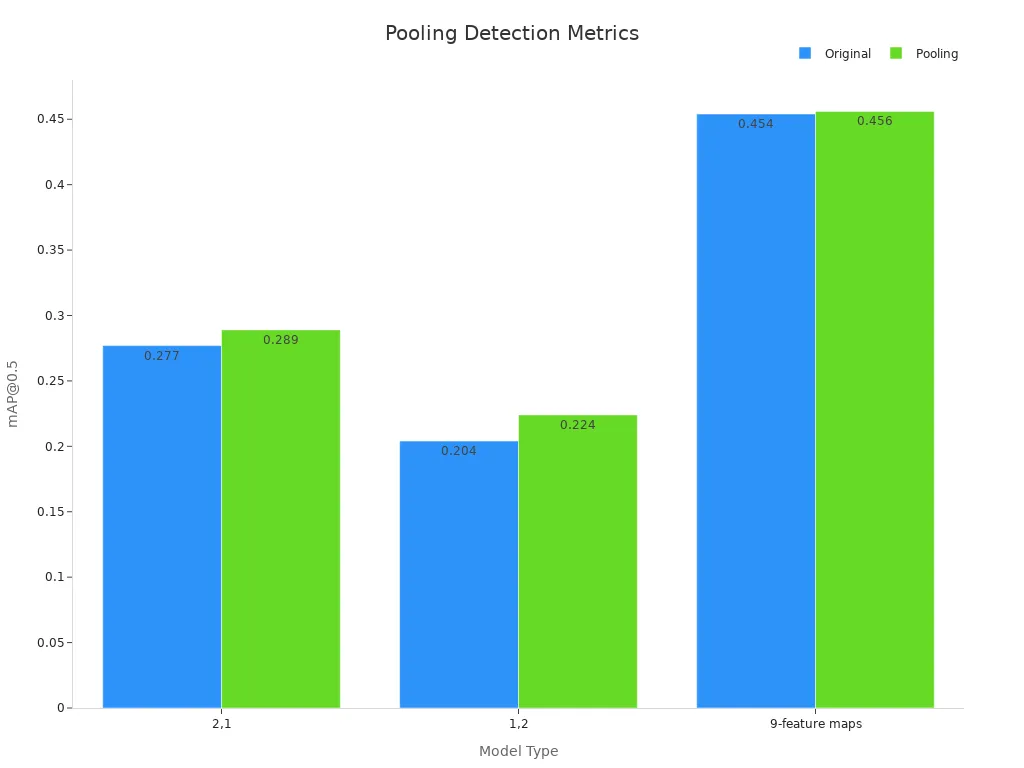
Models that use pooling layers achieve higher precision and recall compared to those without pooling. For example, the (2,1) pooling model increases mAP@0.5 from 0.227 to 0.289, which means better detection accuracy. Pooling also helps models detect more objects in challenging conditions, supporting robust image analysis in computer vision.
Key detection metrics include:
- Intersection over Union (IoU) measures bounding box quality.
- Precision shows how many detected objects are correct.
- Recall measures how many real objects the model finds.
- mAP summarizes detection performance across all classes and thresholds.
Pooling layers improve these metrics, making them essential for modern object detection systems.
Industrial Uses
Pooling in machine vision extends to many industrial applications. Companies use pooling to combine synthetic and real-world data, which boosts the performance of machine learning models. This approach increases the diversity of training data and improves accuracy in image analysis tasks.
The table below summarizes the impact of pooling in industrial machine vision systems:
| Metric / Application Area | Details / Impact |
|---|---|
| Cost Reduction | Average 47% reduction in data acquisition and preparation costs. |
| Scalability | Dataset volumes increased by 1,200% without proportional cost increases. |
| Accuracy Improvement | Combining 1,000 real images with 5,000 synthetic images improved accuracy from 94.5% to 97%. |
| Performance Metrics Improvement | Accuracy, Precision, Recall, Mean Average Precision, and F1 Score all show measurable gains. |
| Industrial Applications | Autonomous vehicles, facial recognition, and manufacturing quality control benefit from enhanced robustness, diversity, and performance. |
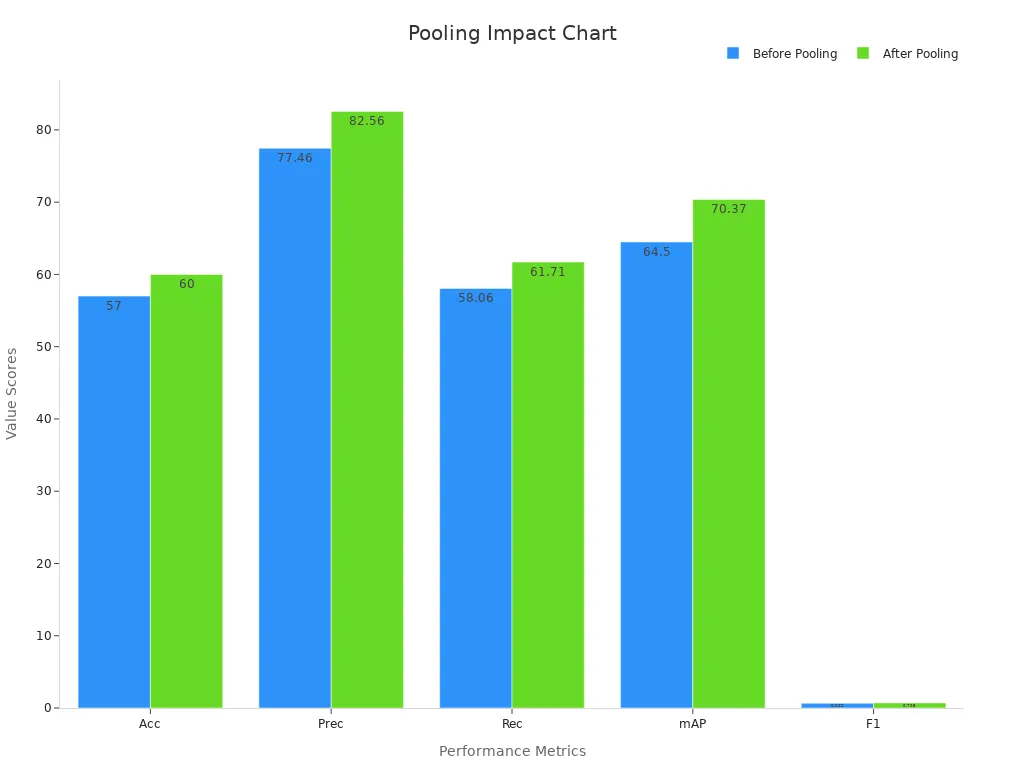
Pooling machine vision systems help industries scale up their datasets and reduce costs. They also improve the accuracy and robustness of machine learning models in real-world environments. Applications of pooling include quality control, autonomous driving, and security systems, where reliable detection and classification are critical.
Pooling in machine vision condenses image data, making models faster and more accurate. Key architectures like LeNet-5 and ResNet rely on pooling to improve efficiency and accuracy in tasks such as image classification and object detection. The table below highlights findings from multiple studies:
| Aspect Evaluated | Quantified Findings / Statistics | Explanation / Implication |
|---|---|---|
| Efficiency Gains | Memory reduced from 2263.1MB to 5.1MB; query time from 11082.4ms to 9.5ms | Enables faster training and inference |
| Performance Improvements | Avg-TopK pooling improved accuracy by over 6% vs max pooling | Pooling method impacts model robustness and accuracy |
| Error Rate Inflation | Type I error rates increased from 5% to 7-11% | Pooling can increase false positives |
Pooling remains essential for computer vision, but careful design ensures reliable results. Readers interested in deep learning can explore advanced types of pooling and their applications in image segmentation and detection.
FAQ
What is the main purpose of pooling in machine vision?
Pooling in machine vision helps reduce the size of image data. This process keeps important features while making computer vision models faster and more efficient. Pooling also supports better accuracy in tasks like image classification and object detection.
How do convolutional neural networks use pooling layers?
Convolutional neural networks use pooling layers to downsample feature maps. These layers help the network focus on key patterns and reduce overfitting. Pooling also lowers memory use and speeds up training for image analysis and segmentation.
What are the main types of pooling?
The main types of pooling include max pooling, average pooling, sum pooling, and global pooling. Each method summarizes information differently. Max pooling selects the highest value, while average pooling finds the mean. Global pooling condenses entire feature maps.
Why is spatial pooling important for image segmentation?
Spatial pooling helps models keep essential features while reducing data size. This process improves segmentation by allowing the system to identify important regions in images. Spatial pooling also supports robust detection and classification in computer vision.
Can pooling machine vision systems reduce overfitting?
Pooling machine vision systems can reduce overfitting by summarizing features and lowering the number of parameters. This approach helps models generalize better to new images. Pooling also improves performance in applications of pooling like classification and detection.
See Also
Understanding Pixel-Based Machine Vision In Contemporary Uses
Essential Insights Into Region Of Interest In Vision
Fundamental Principles Behind Edge Detection In Machine Vision








