
Imagine teaching a machine to recognize objects, understand their boundaries, and classify them simultaneously. That’s the power of a multi-task learning machine vision system. It enables a single model to handle multiple tasks at once, mimicking how humans multitask effortlessly.
This approach transforms machine vision systems by enhancing their capabilities. For example:
- Models using multi-task learning achieved up to 98% accuracy in caliber detection, reducing classification errors by as much as 10%.
- Advanced systems like LUMEN-PRO improved accuracy by 49.58% on challenging datasets while being 4× more cost-efficient than traditional methods.
With such improvements, multi-task learning not only boosts accuracy but also reduces resource consumption, making it a game-changer in technology.
Key Takeaways
- Multi-task learning lets one model do many jobs at once. It makes machine vision systems work faster and more accurately.
- This method uses fewer resources, saving money and working well for healthcare, self-driving cars, and security cameras.
- Sharing knowledge between tasks helps the model learn better and handle new problems more easily.
- Tools like dynamic loss weighting and GradNorm keep tasks balanced so no task takes over during training.
- Multi-task learning works best when tasks are connected, improving results and needing less data.
What is Multi-task Learning?
Definition and core concept of multitask learning
Multi-task learning is a method in which a single model learns to perform multiple tasks simultaneously. Instead of training separate models for each task, multitask learning combines them into one system. This approach allows the model to share knowledge across tasks, improving its overall performance. For example, a deep learning model can detect objects in an image while also identifying their boundaries and classifying them. This shared learning process helps the model understand patterns and relationships more effectively.
Researchers have demonstrated the benefits of multitask learning through various experiments. For instance, a study compared single-task and multi-task models on datasets like PPI and PPI_extendedSFD. The results showed that multi-task models consistently outperformed single-task models, especially when trained on extended datasets. Here’s a summary of the findings:
| Model Type | Training Dataset | Performance (AUC ROC) |
|---|---|---|
| Single-task (IF) | Part of PPI dataset | Lower performance |
| Multi-task (IFBUS3SA) | Part of PPI dataset | Higher performance |
| Multi-task (IFBUS3SA) | PPI_extendedSFD dataset | Significantly higher performance |
| Single-task (IF) | All available PPI data | Equal performance to Multi-task (IFBUS3SA) on limited data |
This table highlights how multitask learning leverages shared knowledge to achieve better results, especially when dealing with complex datasets.
Everyday analogies to simplify the concept
Think of multitask learning as training a chef to prepare multiple dishes at once. Instead of focusing on one recipe, the chef learns to chop vegetables, boil pasta, and grill meat simultaneously. By doing so, the chef becomes more efficient and gains a deeper understanding of cooking techniques. Similarly, a multi-task learning machine vision system learns to handle multiple tasks, such as recognizing objects and analyzing their features, all at the same time.
Another analogy is learning to drive. When you drive, you don’t just focus on steering. You also monitor traffic, adjust your speed, and follow road signs. These tasks happen simultaneously, and your brain processes them together. Multitask learning mimics this human ability, enabling machines to perform multiple related tasks efficiently.
Why multi-task learning is essential in machine learning
Multi-task learning plays a crucial role in advancing machine learning. It improves performance by leveraging similarities between tasks. For example, training a model to recognize gestures and actions together enhances its ability to generalize across tasks. This shared learning reduces the need for separate models, saving time and computational resources.
In addition, multitask learning enhances efficiency in real-world applications. Studies have shown that multitask models can reduce data requirements while maintaining performance. For instance, a study on biomedical natural language processing achieved a 26.6% reduction in data usage without compromising accuracy. Another study on reinforcement learning demonstrated improved sample efficiency through behavior sharing. These findings highlight the practical benefits of multitask learning in various domains.
By adopting multitask learning, you can create systems that are not only more efficient but also more accurate. This approach is particularly valuable in fields like machine vision, where tasks like object detection and segmentation often overlap. Jointly training these tasks allows the model to learn shared features, resulting in better overall performance.
How Multi-task Learning Works in Machine Vision
Task sharing and optimization in machine vision systems
In a multi-task learning machine vision system, task sharing plays a central role. Instead of training separate models for each task, a shared model architecture allows multiple tasks to benefit from common features. For example, the initial layers of a deep learning model often extract basic patterns like edges or textures. These patterns are useful for tasks such as object detection and segmentation. By sharing these layers, the system optimizes resource usage and reduces redundancy.
Optimization techniques further enhance this process. Hard parameter sharing is one common approach. It involves using the same parameters for multiple tasks in the early layers of the model. This method helps the system learn general features that apply to all tasks. On the other hand, soft parameter sharing assigns separate parameters to each task but uses regularization to ensure they remain similar. Both methods promote knowledge sharing, improving the overall performance of the system.
Examples of tasks like object detection and segmentation
Object detection and segmentation are two key tasks in computer vision. Object detection identifies and locates objects within an image, while segmentation divides the image into meaningful regions. These tasks often overlap, making them ideal candidates for multitask learning.
For instance, a model trained for both tasks can detect a car in an image and simultaneously outline its shape. This dual capability enhances accuracy and efficiency. Performance metrics like IoU (Intersection over Union) and mIoU (mean Intersection over Union) measure how well the model performs these tasks. Here’s a table summarizing improvements in these metrics:
| Metric | Improvement |
|---|---|
| NDS | 0.3% |
| IoU | 0.6% |
| mIoU | 0.4% |
Additionally, different models like UNet, FPN, and BiFPN have been evaluated for their effectiveness in multitask learning. The following table shows their mAP (mean Average Precision) scores:
| Model | mAP |
|---|---|
| UNet | 0.83 |
| FPN | 0.88 |
| BiFPN | 0.88 |
| PFPN | 0.88 |
| TRN | 0.88 |
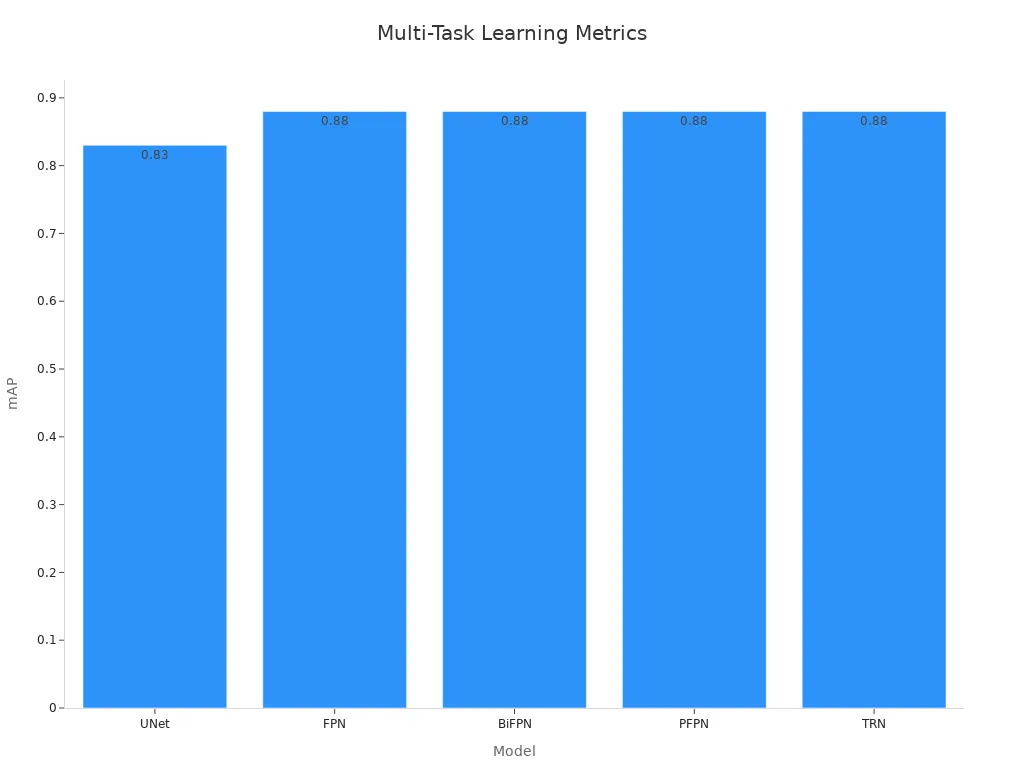
These results highlight how multitask learning improves performance across tasks like object detection and segmentation.
How models balance and learn multiple tasks simultaneously
Balancing multiple tasks in a multitask learning system requires careful design. Models use techniques like uncertainty-based weighting to adjust the importance of each task. This method assigns higher weights to tasks with lower uncertainty, ensuring the model focuses on confident predictions. GradNorm is another technique that balances learning by controlling gradient magnitudes during backpropagation. It prevents any single task from dominating the training process.
For example, in a shared model architecture, the system might prioritize object detection over segmentation if the former has more confident predictions. As training progresses, the model adjusts these priorities dynamically, ensuring balanced learning. This approach allows the system to handle multiple tasks effectively, improving its overall performance.
By combining task sharing, optimization techniques, and balancing strategies, multitask learning creates efficient and accurate machine vision systems. These systems excel in handling complex tasks, making them invaluable in fields like autonomous vehicles and medical imaging.
Benefits of Multi-task Learning in Machine Vision
Efficiency and resource optimization
Multi-task learning optimizes how you use resources in machine vision systems. Instead of training separate models for each task, it allows you to train a single shared model for multiple tasks. This approach reduces redundancy and improves efficiency. For example, when you fine-tune a 4-bit quantized model, memory usage drops by one-third compared to a 32-bit model. Training time also decreases by the same proportion, yet performance remains consistent across tasks.
Efficient resource utilization stems from knowledge sharing among tasks. A multi-task learning machine vision system identifies shared features, such as edges or textures, and uses them across tasks like object detection and segmentation. This parallel learning accelerates the training process and enhances performance. Studies show that multi-task learning outperforms traditional methods on real-world datasets, proving its effectiveness in optimizing computational resources.
Improved generalization across tasks
Multi-task learning improves how well your model generalizes across tasks. By sharing knowledge, the model learns patterns that apply to multiple tasks, making it more adaptable. Research highlights the role of task-specific neurons in this process. For instance, the study "Towards Understanding Multi-Task Learning (Generalization) of LLMs via Detecting and Exploring Task-Specific Neurons" found that overlapping task-specific neurons correlate with better generalization. Controlling these neurons enhances outcomes across tasks.
Another study, "Can Small Heads Help? Understanding and Improving Multi-Task Generalization," explored task conflicts in multi-task learning. It showed that strategies like under-parameterized self-auxiliaries reduce conflicts and improve generalization. These findings emphasize how multitask learning helps your model handle diverse tasks effectively.
Reduced computational costs compared to single-task models
Multi-task learning minimizes computational costs. Training separate models for each task requires more memory and processing power. In contrast, a shared model architecture reduces these demands. For example, fine-tuning a quantized model cuts memory usage and training time significantly. This cost-saving approach makes multitask learning ideal for resource-constrained environments.
By combining tasks into one system, you avoid duplicating efforts. Shared features reduce the need for extensive task-specific data, further lowering costs. Whether you’re working with deep learning or machine learning, multitask learning offers a more efficient and cost-effective solution.
Comparison Between Multi-task and Single-task Learning
Key differences in approach and outcomes
Multi-task learning and single-task learning differ significantly in how they approach problems and the results they achieve. Single-task learning focuses on solving one task at a time, using a dedicated model for each task. In contrast, multi-task learning combines multiple tasks into a single model, allowing it to share knowledge across tasks. This shared learning often leads to better performance and efficiency.
To illustrate these differences, consider the following table:
| Task | Performance Improvement (%) | Transfer Type |
|---|---|---|
| SA | 3.26 | Positive Transfer |
| FND | 6.57 | Positive Transfer |
| TD | 0.62 | Positive Transfer |
| SD | N/A | No Significant Improvement |
The table shows that multi-task learning enables positive transfer between tasks, improving performance. Single-task models, on the other hand, lack this ability to leverage relationships between tasks, which limits their effectiveness.
Scenarios where multi-task learning excels
Multi-task learning shines in scenarios where tasks are related or share common features. For example:
- In healthcare:
- Detecting and classifying diseases from medical imaging.
- Predicting patient recovery outcomes.
- Recommending treatments based on patient history.
- In finance:
- Assessing risks for credit and investments.
- Detecting fraudulent activities.
- Analyzing customer behavior for personalized solutions.
Additionally, models like MTSpark demonstrate the advantages of multi-task learning. They achieve high accuracy across multiple tasks, maintain smooth learning curves, and outperform traditional deep neural networks on complex datasets. These capabilities make multi-task learning ideal for applications requiring efficiency and adaptability.
Limitations of single-task learning in complex systems
Single-task learning struggles in complex systems because it treats each task in isolation. This approach prevents it from leveraging relationships between tasks, which reduces its ability to handle dynamic environments. For instance, research shows that multi-task learning significantly improves forecasting accuracy by utilizing inter-task relationships. Single-task models fail to achieve similar results due to their isolated nature.
Another study highlights how multi-task learning optimizes prediction tasks across various energy loads simultaneously. Single-task models, in comparison, lack the flexibility to manage such complexity. Artificial neural networks using multi-task learning consistently outperform single-task counterparts, further emphasizing the limitations of single-task learning in handling interconnected tasks.
Real-world Applications of Multi-task Learning in Machine Vision

Autonomous vehicles and multitask learning for navigation
Autonomous vehicles rely on multi-task learning to navigate complex environments efficiently. These systems perform tasks like lane detection, object recognition, and traffic sign interpretation simultaneously. By sharing knowledge across tasks, they achieve faster and more accurate decision-making. For example, the YOLO-ODL model demonstrated state-of-the-art performance on the BDD100K dataset, showcasing its ability to handle multiple tasks with high accuracy and computational efficiency.
Key performance metrics highlight the advantages of multi-task learning in this domain:
| Model | mAP (%) | Latency (ms) | Frame Rate (FPS) |
|---|---|---|---|
| Proposed Model | 74.85 | 15.6 | 102 |
| MultNet | 60.2 | 27.2 | 42 |
| YOLOv9+SAM | N/A | 67.4 | 26 |
| YolTrack | 81.23 | N/A | N/A |
| B-YOLOM | 81.27 | N/A | N/A |
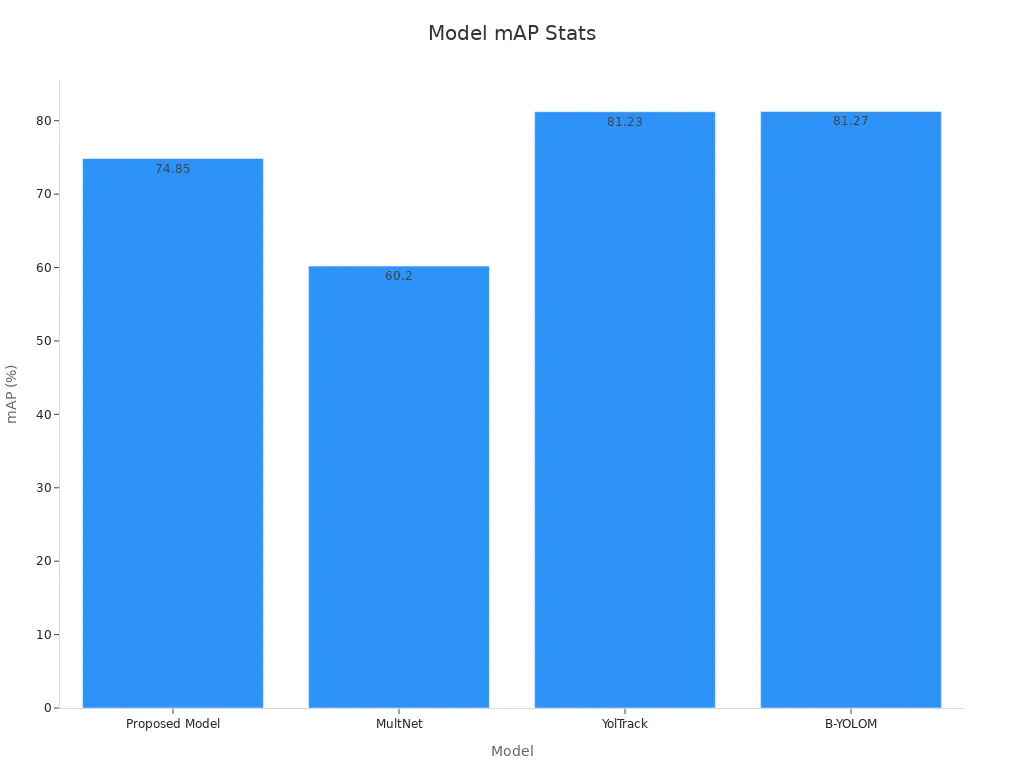
These results demonstrate how multi-task learning enhances both accuracy and speed, making it indispensable for autonomous vehicle navigation.
Medical imaging for diagnosis and segmentation
In medical imaging, multi-task learning improves diagnostic accuracy and efficiency. Models trained to perform lesion segmentation and disease classification simultaneously can identify abnormalities while categorizing their severity. For instance, encoder-decoder networks have been developed for organ segmentation and multi-label classification in CT images. Another example includes a two-stage framework that uses class activation maps from a polyp classification model to enhance segmentation performance.
A study on vision-language models further highlights the benefits of multi-task learning. Fine-tuning these models for object detection and counting tasks led to better performance compared to single-task models. This approach not only saves time but also reduces the need for extensive datasets, making it highly effective in healthcare applications.
Surveillance systems for multi-object tracking and recognition
Surveillance systems benefit significantly from multi-task learning, especially in multi-object tracking and recognition. These systems must detect, track, and identify multiple objects in real-time. Multi-task learning enables them to handle these tasks efficiently by sharing features like object appearance and motion patterns.
Performance indicators such as MOTA (Multiple Object Tracking Accuracy) and IDF1 (Identity F1 Score) measure the effectiveness of these systems. For example:
| Indicator | Description | Formula |
|---|---|---|
| MOTA | Measures overall tracking effectiveness by accounting for false negatives, false positives, and identity switches. | MOTA = 1 — (FN + FP + IDS)/GT |
| IDF1 | Evaluates association accuracy by comparing true positives, false positives, and false negatives. | IDF1 = 2IDTP/ (2IDTP + IDFP + IDFN) |
These metrics highlight how multi-task learning improves both detection and tracking accuracy, making it a critical technology for modern surveillance systems.
Challenges and Limitations of Multi-task Learning
Task interference and its impact on performance
Multi-task learning systems often face a challenge called task interference. This occurs when tasks compete for the same resources, leading to reduced performance. For example, research shows that performing two tasks simultaneously, such as the Wisconsin Card Sorting Task and a verbal shadowing task, increases errors. It also decreases activity in the prefrontal cortex, which is crucial for decision-making. This highlights how task interference can negatively affect multi-task learning systems.
Interestingly, predictability in tasks can help reduce interference. When tasks are predictable, you can allocate resources more effectively, improving overall performance. This means that designing systems with predictable task patterns can enhance the efficiency of multi-task learning models.
Balancing task priorities during training
Balancing task priorities is essential for effective multi-task learning. If one task dominates the training process, it can hinder the performance of other tasks. Researchers have developed several methods to address this issue. These include:
| Methodology | Description |
|---|---|
| Gradient-based meta-learning | Updates gradients at the task level to balance their influence during training. |
| Dynamic loss weighting | Adjusts loss weights dynamically to prevent any single task from dominating. |
| Multi-objective optimization | Uses Pareto optimization to handle competing tasks without relying on simple weighted sums. |
These techniques ensure that all tasks receive appropriate attention during training. For instance, dynamic loss weighting automatically adjusts the importance of tasks, eliminating the need for manual tuning. This makes the training process more efficient and balanced.
- Gradient-based approaches train shared and task-specific layers separately.
- Multi-objective optimization is particularly useful when tasks conflict, as it avoids oversimplified solutions.
Advances in research to address these challenges
Recent advancements in multi-task learning research aim to overcome these limitations. Researchers are exploring ways to reduce task interference by improving task predictability. For example, adaptive scheduling algorithms dynamically adjust the order of tasks based on their complexity. This ensures that simpler tasks do not overshadow more challenging ones.
Another promising approach involves using task-specific neurons. Studies show that identifying and controlling these neurons can improve generalization across tasks. Additionally, techniques like GradNorm help balance learning by controlling gradient magnitudes, ensuring no single task dominates the training process.
These innovations are paving the way for more robust and efficient multi-task learning systems. By addressing challenges like task interference and priority balancing, researchers are unlocking the full potential of multi-task learning in machine vision and beyond.
Multi-task learning has revolutionized how you approach machine vision systems. By enabling a single model to handle multiple tasks, it enhances efficiency and accuracy while reducing resource consumption. This innovation has already transformed industries like healthcare, autonomous vehicles, and surveillance.
You can explore its potential to solve complex problems and improve real-world applications. As research advances, multi-task learning machine vision systems will continue to unlock new possibilities. Dive deeper into this field to stay ahead in leveraging its transformative power.
FAQ
What is the main advantage of multi-task learning in machine vision?
Multi-task learning allows you to train one model for multiple tasks. This reduces redundancy, saves resources, and improves efficiency. It also enhances the model’s ability to generalize across tasks by sharing knowledge between them.
How does multi-task learning differ from single-task learning?
Single-task learning focuses on one task at a time, while multi-task learning handles several tasks simultaneously. This shared learning improves performance and reduces computational costs. Multi-task learning also excels in scenarios where tasks overlap or share features.
Can multi-task learning work with limited data?
Yes, multi-task learning can perform well with limited data. By sharing features across tasks, it reduces the need for large datasets. This makes it ideal for applications where collecting data is expensive or time-consuming.
What are some challenges in multi-task learning?
Task interference is a common challenge. It happens when tasks compete for resources, reducing performance. Balancing task priorities during training is another issue. Techniques like dynamic loss weighting and GradNorm help address these problems.
Where can you apply multi-task learning in real life?
You can use multi-task learning in autonomous vehicles for navigation, in medical imaging for diagnosis and segmentation, and in surveillance systems for tracking and recognition. These applications benefit from its efficiency and ability to handle complex tasks.
See Also
Essential Insights on Transfer Learning for Machine Vision
Understanding Few-Shot and Active Learning in Machine Vision
The Impact of Deep Learning on Machine Vision Systems









