
A mixture of experts MoE machine vision system uses several specialized models, called experts, to solve complex visual tasks in ai. A gating network chooses the best expert for each input, making this machine learning technique both efficient and modular. This machine learning approach lets ai systems handle large and varied data by dividing work among experts. In deep learning, mixture of experts brings flexibility and speed. Studies show that ai models like Google’s V-MoE achieve top computer vision results with about half the computational cost. The gating system only activates the needed experts, saving resources and boosting learning performance.
Key Takeaways
- Mixture of Experts (MoE) uses multiple specialized models and a gating network to solve complex vision tasks efficiently by activating only the needed experts.
- The system divides tasks into smaller parts, routes inputs dynamically, and combines expert outputs to improve accuracy while saving computation.
- MoE models offer strong benefits like faster processing, better scalability, and flexible adaptation to new data and tasks in computer vision.
- Applications of MoE include image classification, object detection, and vision transformers, where they boost accuracy and reduce resource use.
- Challenges such as training complexity, inference efficiency, and large model size require careful design and optimization for real-world deployment.
Architecture

A mixture of experts system in machine vision uses a modular neural network architecture. This design follows a divide-and-conquer principle, where the system splits complex visual tasks into smaller, manageable parts. Each part is handled by a specialized expert model. The architecture includes three main components: the experts, the gating network, and their interaction.
Experts
Expert models act as specialists within the mixture of experts framework. Each expert focuses on a specific aspect of the input data, such as recognizing shapes, colors, or textures. Research shows that these expert models can specialize further when the system uses sequential routing and inner connections. For example, the Chain-of-Experts model demonstrates that step-wise routing helps each expert refine its skills, leading to better performance and efficient use of resources. DeepSeek’s approach also highlights that activating only the needed expert models for each task saves computation and improves speed. This specialization allows the mixture of experts algorithm to handle large and diverse datasets with fewer resources.
Gating Network
The gating network serves as the decision-maker in the mixture of experts system. It examines each input and selects which expert models should process it. Studies highlight several gating strategies, such as TopK and Top-P, which choose the most suitable experts based on the input. Adding noise to the gating process encourages the system to explore different experts, preventing overload and improving balance. The gating network’s design ensures that the mixture of experts algorithm remains efficient and scalable, even as the number of expert models grows.
Note: The gating network not only routes inputs but also helps each expert model specialize, which boosts the overall performance of the system.
Interaction
The interaction between the gating network and expert models forms the core of the mixture of experts architecture. The gating network dynamically routes each input to one or more expert models, depending on the task. This dynamic routing enables the system to use only the necessary parts of the network, reducing computational cost. Experimental studies confirm that this interaction leads to faster training, better load balancing, and improved accuracy. As the number of expert models increases, the mixture of experts system can scale efficiently without sacrificing performance.
- Key architectural studies supporting this modular design include:
- The 1991 "Adaptive Mixtures of Local Experts" paper, which introduced modular expert networks and gating.
- Shazeer et al.’s 2017 work on sparse expert blocks and conditional computation.
- Fedus et al.’s 2021 Switch Transformers, which use hard routing for efficiency at scale.
- Real-world models like Mixtral 8x7B, which show independent expert blocks and dynamic routing.
This modular and dynamic approach makes the mixture of experts algorithm a powerful tool for modern machine vision systems.
How It Works
A mixture of experts moe machine vision system follows a clear and structured process to solve complex visual tasks. This process uses dynamic routing, sparse gating, and efficient output combination to deliver accurate results while saving computational resources. The following steps outline how the system operates in real-world ai and vision applications.
Input Routing
The system begins by receiving an input, such as an image or a sequence of image patches. The gating network examines the input and determines which expert models should process it. In many vision tasks, the algorithm divides the image into smaller patches. Each patch is then routed to the most suitable expert models. This routing process uses a learned index structure, as seen in advanced architectures like PEER, which can handle routing to over a million experts. The gating network selects only a few experts for each patch, which keeps the system efficient and prevents unnecessary computation.
Tip: Dynamic input routing allows the mixture of experts to scale up to large datasets and complex tasks without increasing computational cost.
Expert Selection
Once the gating network has routed the input patches, it selects the best expert models for each one. The selection process relies on the gating algorithm, which evaluates the input features and assigns each patch to the experts most likely to provide accurate results. This step uses sparse gating, meaning only a small subset of all available experts become active for any given input. For example, Google’s V-MoE model demonstrates how this approach improves both accuracy and efficiency in vision transformers. The gating network can also add noise to its decisions, which helps balance the workload among experts and encourages learning across the entire system.
- The expert selection process typically follows these steps:
- The gating network analyzes the input patch.
- It scores each expert model based on relevance.
- Only the top-scoring experts receive the input for processing.
- The system can adjust the number of active experts per patch to balance accuracy and efficiency.
This method allows the mixture of experts moe machine vision system to adapt to new data and tasks, supporting lifelong learning by adding new experts as needed.
Output Combination
After the selected expert models process their assigned patches, the system must combine their outputs into a single, unified prediction. The output combination step uses weighted averaging, where the gating network assigns probabilities to each expert’s output. The final result reflects the contributions of all active experts, weighted by their confidence and relevance.
| Step | Description | Example in Practice |
|---|---|---|
| Output Collection | Gather results from all active experts | Each expert returns a prediction |
| Weight Assignment | Gating network assigns weights based on expert confidence | Higher weight for more relevant experts |
| Output Aggregation | Combine outputs using weighted averaging or other integration methods | Final prediction blends expert outputs |
| Decision Making | System produces a single, accurate result for the input | Unified label or detection for the image |
This approach draws on mixed-method synthesis designs, which integrate different types of evidence to improve decision-making. By combining outputs from multiple experts, the system achieves higher accuracy and robustness. The mixture of experts algorithm ensures that both quantitative and qualitative strengths of each expert contribute to the final prediction, making the system reliable for a wide range of vision tasks.
Note: The ability to merge outputs from diverse expert models supports complex decision-making and helps the system adapt to new challenges in ai and machine vision.
Benefits
Efficiency
Mixture of experts models bring high efficiency to ai systems in computer vision. The gating network activates only a few expert models for each input. This selective process reduces the total number of computations. As a result, the system uses less energy and hardware resources. MoE models often achieve faster performance than traditional dense models. For example, studies show that MoE models can save up to 40 times more compute at large scales. Wall-clock time measurements confirm that these models train faster to reach the same accuracy as dense models. This efficiency makes MoE a strong choice for large-scale ai learning tasks.
Scalability
MoE architectures scale well as the size of data and tasks increases. Researchers have introduced new hyperparameters, such as granularity, to help MoE models grow with more experts and larger datasets. Empirical results show that MoE models outperform dense transformers when trained with the right settings. The efficiency gains become even greater as the model size grows. MoE models remain efficient even when handling very large vision datasets. The Mod-Squad model in multi-task learning demonstrates that MoE can match experts to specific tasks, allowing the system to adapt and scale as new tasks appear. This adaptability supports a wide range of computer vision applications.
Flexibility
MoE systems offer strong flexibility for ai and learning. Each expert can specialize in different types of data or tasks. The gating network can assign new inputs to the most suitable experts. This design allows the system to handle many types of vision problems without retraining the entire model. MoE models also support parameter sharing among related tasks, which helps the system learn faster and adapt to new challenges. In real-world applications, this flexibility means that MoE can support both simple and complex computer vision tasks, making it a valuable tool for modern ai solutions.
MoE models help ai systems achieve faster performance, lower costs, and better adaptability in computer vision.
Applications in Computer Vision

Image Classification
Mixture of experts models have transformed image classification applications. These models allow systems to handle large and complex datasets with high accuracy and efficiency. Sparse V-MoE models scale up to 1.5 billion parameters and match or exceed dense networks in accuracy on large-scale datasets. The LIMO architecture, designed for low-shot image classification, achieves remarkable accuracy compared to other methods. Meta-learning-based mixture of experts models reduce training complexity and improve accuracy in multi-class image classification. Transfer learning-based MoE models also boost classification accuracy for small-sample remote sensing images by combining global and local features. These advances help applications in healthcare, agriculture, and security, where accurate image classification is critical.
Object Detection
Object detection applications benefit greatly from mixture of experts systems. MoE models achieve state-of-the-art results on benchmark datasets like COCO and LVIS, showing superior accuracy and efficiency. SenseTime’s AlignDet framework uses MoE to optimize resource allocation, improving efficiency in industrial big data scenarios. Mod-Squad integrates MoE layers into vision transformers, allowing lightweight sub-model extraction for specific object detection tasks without losing performance. AdaMV-MoE adaptively selects the number of experts per task, improving efficiency for multi-task visual recognition on datasets like ImageNet and COCO. These applications support industries such as manufacturing, transportation, and retail.
Note: Mixture of experts models help detect objects in real time, making them valuable for safety and automation.
Vision Transformers
Vision transformers with mixture of experts integration have advanced many applications in computer vision. Comparative studies show that MoE-augmented vision transformer models, such as V-MoE, SoViT, and LiMoE-H, perform as well as or better than dense models on large datasets like JFT-3B and ImageNet. These models improve accuracy and efficiency, especially for mid-sized models. Architectural changes, such as replacing MLP blocks with MoE layers, allow spatial distribution of experts and increase model capacity. Robustness evaluations show that these models maintain or improve accuracy under distribution shifts and adversarial conditions. This makes them suitable for applications in autonomous vehicles, robotics, and smart surveillance.
| Application Area | MoE Model Example | Key Benefit |
|---|---|---|
| Image Classification | V-MoE, LIMO | High accuracy, efficiency |
| Object Detection | AlignDet, Mod-Squad, AdaMV-MoE | Resource optimization, adaptability |
| Vision Transformers | V-MoE, SoViT, LiMoE-H | Robustness, scalability |
Challenges
Training Complexity
Training a mixture of experts system in machine vision presents several practical hurdles. These systems often require large amounts of labeled data, which can slow down the training process. Traditional approaches depend on manual labeling, creating a bottleneck for many organizations. New self-training methods, such as VisionStream AI, help reduce this dependency by allowing the system to learn from unlabeled data. This approach speeds up deployment and lessens the need for specialized engineers.
Key challenges in training include:
- Gathering enough high-quality data for robust feature extraction.
- Collaborating with domain experts to design effective models and select the right features.
- Using rigorous testing methods, such as statistical tests and benchmark metrics, to ensure reliability.
- Addressing ethical and regulatory concerns, including bias and privacy.
Continuous monitoring and lifecycle management, such as retraining and version control, also play a vital role in maintaining model performance over time.
Inference Efficiency
Inference efficiency remains a critical concern for MoE systems. Activating only a subset of experts for each input reduces computational overhead, as seen in DeepSeek’s architecture, which uses just 37 billion out of 671 billion parameters per token.
Technical improvements help boost efficiency:
- Distillation techniques transfer knowledge from larger to smaller models.
- Mixed-precision computation, like FP8, cuts computational costs.
- Sparsity methods predict which parameters are necessary, improving speed.
- Hardware optimizations, such as memory compression and better GPU control, support faster inference.
Despite these advances, real-time integration and rapid adaptation to new products still challenge deployment, especially in environments that require immediate responses.
Model Size
MoE models often have billions of parameters, making them difficult to manage and deploy. The table below compares several large-scale MoE architectures:
| Model | Training Scheme | Activation | Total Layers | Total Parameters | Activated Parameters |
|---|---|---|---|---|---|
| Mixtral | Unknown (upcycling) | SiLU | 32 | 46.7B | 12.9B |
| Mistral | From scratch | SiLU | 32 | 7.3B | 7.3B |
| DeepSeek | From scratch | SiLU | 28 | 16.4B | 0.3B |
| Grok | From scratch | GeLU | 64 | 314B | 78.5B |
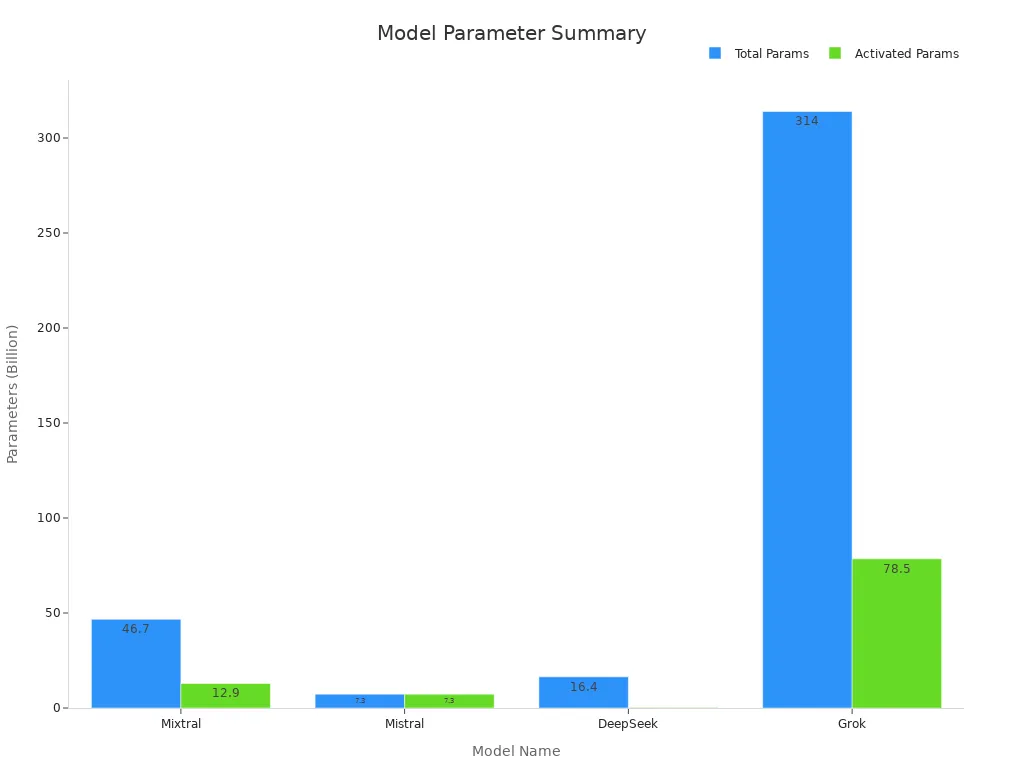
Studies show that deeper layers benefit from more experts, but the last layer often has higher similarity among experts, which can limit expressiveness. Maintaining expert diversity and effective routing becomes more difficult as model size grows. Careful architectural design and ongoing learning help address these issues, but managing large parameter counts remains a significant challenge.
A mixture of experts system in machine vision uses specialized models and a gating network to solve visual tasks with high efficiency. MoE models deliver strong benefits, such as faster processing, better scalability, and flexible adaptation to new data.
Teams should consider MoE for large, complex vision projects that need speed and resource savings.
Before choosing MoE, weigh the gains in performance against training complexity and model size. MoE works best when the project demands both accuracy and efficiency.
FAQ
What makes Mixture of Experts different from standard neural networks?
MoE systems use several specialized models and a gating network. Standard neural networks process all data with the same parameters. MoE activates only the needed experts for each input, which saves resources and improves performance.
Can MoE models work with small datasets?
MoE models perform best with large and diverse datasets. Small datasets may not provide enough variety for each expert to specialize. Teams can use data augmentation or transfer learning to help MoE models learn from limited data.
How does the gating network choose experts?
The gating network analyzes each input and scores the experts. It selects the top experts based on these scores. The process uses learned weights and sometimes adds noise to balance the workload.
Are MoE models hard to deploy in real-world applications?
| Challenge | Solution Example |
|---|---|
| Large model size | Model distillation |
| Hardware limits | Mixed-precision compute |
| Real-time needs | Sparse expert routing |
MoE models need careful design for deployment. Teams often use compression and hardware optimization.








