
Success in a machine vision system depends on structured planning, reliable data, and effective machine learning lifecycle management machine vision system. Teams see better results when they use real-time monitoring and strong pipelines. For example, selecting features with Information Value above 0.1 and evaluating models with metrics like 82.7% accuracy and 84.0% precision helps guide improvements in a machine vision system. Machine learning lifecycle management machine vision system enables a machine vision system to adapt and scale while using synthetic data and edge analytics for faster, real-time decisions. These steps ensure each machine vision system stays accurate and reliable as new data arrives.
Key Takeaways
- Set clear, specific goals early using frameworks like SMART to guide machine vision projects and improve focus and efficiency.
- Use high-quality data with proper labeling and include synthetic data to fill gaps, reduce bias, and boost model accuracy.
- Build strong machine learning pipelines that automate data handling, training, and evaluation to achieve faster, more accurate results.
- Collaborate with domain experts to improve feature selection, model relevance, and overall system performance.
- Implement real-time monitoring and regular lifecycle updates to keep machine vision systems accurate, reliable, and scalable.
Planning & Objectives
Defining Goals
Teams in machine vision projects start by setting clear goals. They use structured planning frameworks to guide their work. The SMART framework helps teams make goals specific, measurable, achievable, relevant, and time-bound. For example, a team might set a goal to reach 95% accuracy in object detection within three months. This goal gives everyone a clear target. Deep learning models need these targets to focus their training and testing. Teams also use the Goal-Question-Metric approach. They ask questions like, "How accurate is the model?" and "How fast does it process images?" Then, they pick metrics that answer these questions. Teams avoid vague goals. Instead, they define exactly how to measure success. For instance, they might use MAPE to measure accuracy or track the average response time for a vision system. These steps help teams align their deep learning work with business needs. Clear goals improve communication and keep everyone focused. Teams collect data and use it to check progress. This process boosts efficiency and helps teams adjust quickly if they see problems.
Tip: Setting precise goals early makes deep learning projects more efficient and easier to manage.
Metrics & Feasibility
Teams use metrics to check if their goals are possible and to plan their next steps. They pick metrics that match the type of deep learning task. For classification, they use precision, recall, F1-score, and confusion matrix. For regression, they use MAE, RMSE, and R² score. Business impact metrics show how much the system improves efficiency and saves costs. Teams track these numbers to see if their deep learning models work well with real data. The table below shows common metrics for machine vision projects:
| Metric Category | Metrics & Description |
|---|---|
| Classification Metrics | Precision: Ensures resources aren’t wasted on false alarms. Recall: Minimizes missed actual failures. F1-Score: Balances precision and recall. Confusion Matrix: Details true/false positives and negatives. |
| Regression Metrics | MAE & RMSE: Measure prediction accuracy for remaining useful life (RUL). R² Score: Indicates prediction quality for future outcomes. |
| Business Impact Metrics | Reduction in Unplanned Downtime: Measures % decrease in downtime and cost savings. Maintenance Cost Savings: Tracks expenses on emergency repairs, labor, and parts shipping. Improvement in Equipment Lifespan: Monitors operational period before replacement and capital expenditure deferral. |
Teams use these metrics to test deep learning models with real and synthetic data. They check if the models meet the set goals. If not, they adjust the data pipeline or model settings. This cycle keeps the project efficient and focused on results. Teams always look for ways to improve efficiency by using better data and smarter deep learning methods.
Data Pipeline & Management
Data Collection & Labeling
A machine vision system depends on high-quality data. Teams start with data collection and labeling. They gather images or video from cameras, sensors, or public datasets. Each image needs a label. Labels tell the deep learning model what to look for, such as objects, defects, or features. Good data labeling improves detection and recognition. Teams use manual labeling, automation, or a mix of both. Manual labeling gives precise results, but it takes time. Automated tools speed up the process, but sometimes miss details. Data preparation includes cleaning, organizing, and checking for errors. This step ensures the data is ready for the pipeline.
Note: Enhanced data management practices in the machine vision pipeline have led to impressive results. For example, AI-driven systems now achieve error rates below 1%, compared to about 10% for manual inspections. Inspection speed can reach one part every two seconds, showing how robust data collection and preprocessing boost both speed and accuracy.
| Case Study / Metric | Sector / Context | Quantitative Evidence | Key Outcome / Impact |
|---|---|---|---|
| Walmart | Retail | 25% improvement in inventory turnover | Increased operational efficiency |
| General Electric | Industrial Inspection | 75% reduction in inspection time | Faster quality control |
| Crowe and Delwiche | Food & Agriculture | Improved sorting accuracy | More consistent results than manual methods |
| Zhang and Deng | Fruit Bruise Detection | Defect detection errors within 10% | High precision in identifying defects |
| Kanali et al. | Produce Inspection | Labor savings | Increased objectivity and reduced manual work |
| ASME Systems Sales | Commercial Adoption | $65 million in sales | Strong market trust and commercial success |
| Coors Ceramics Co. | Manufacturing Inspection | One part inspected every 2 seconds | High throughput inspection speed |
| AI-driven systems | Machine Vision Accuracy | Error rates below 1% vs ~10% manual | Significantly improved reliability |
Synthetic Data
Synthetic data plays a key role in modern machine vision. Teams use computer-generated images to fill gaps in real-world data. This approach helps when rare objects or events are hard to capture. Deep learning models need lots of examples for training and validation. Synthetic data provides these examples quickly and at lower cost. It also helps balance datasets, reducing bias and improving fairness.
A case study by Orbital Insight showed that adding synthetic data to the machine learning pipeline improved average precision scores for detecting rare objects in satellite images. The combination of synthetic and real images outperformed using real images alone. This method solved difficult detection tasks and boosted algorithm performance.
- Synthetic data improves diagnostic AI accuracy for rare diseases by up to 20%. This makes models more robust for rare or minority cases.
- Synthetic data generation reduces data collection costs by about 40% and increases model accuracy by around 10%. This makes AI development more scalable and cost-effective.
- Synthetic data helps reduce biases in AI models by up to 15%. Balanced and diverse datasets improve fairness and performance.
- Scalable synthetic datasets can speed up AI development timelines by up to 40%. Teams can iterate faster and adapt to complex models.
- Applications in computer vision include better object detection, facial recognition, and medical imaging augmentation.
Tip: Teams should use synthetic data to improve detection, recognition, and overall model accuracy, especially when real-world data is limited.
Machine Learning Pipeline
A robust machine learning pipeline supports every step from data preparation to model deployment. The pipeline manages data flow, model training, and evaluation. Deep learning models need structured pipelines to handle large datasets, automate training, and track results. Each stage in the pipeline adds value.
The pipeline starts with data ingestion. It moves to data cleaning, augmentation, and splitting into training and test sets. Deep learning models use this data for training and validation. The pipeline then automates model selection, hyperparameter tuning, and evaluation. Teams use metrics like accuracy, F1-score, and precision-recall curves to check performance. Advanced pipelines use k-fold cross-validation and stratified sampling to prevent overfitting and ensure generalization.
Technical benchmarks show the impact of a strong machine learning pipeline. The table below compares different models on key metrics:
| Model | mAP (%) | Latency (ms) | Frame Rate (FPS) |
|---|---|---|---|
| Proposed Model | 74.85 | 15.6 | 102 |
| MultNet | 60.2 | 27.2 | 42 |
| YOLOv9+SAM | N/A | 67.4 | 26 |
| YolTrack | 81.23 | N/A | N/A |
| B-YOLOM | 81.27 | N/A | N/A |
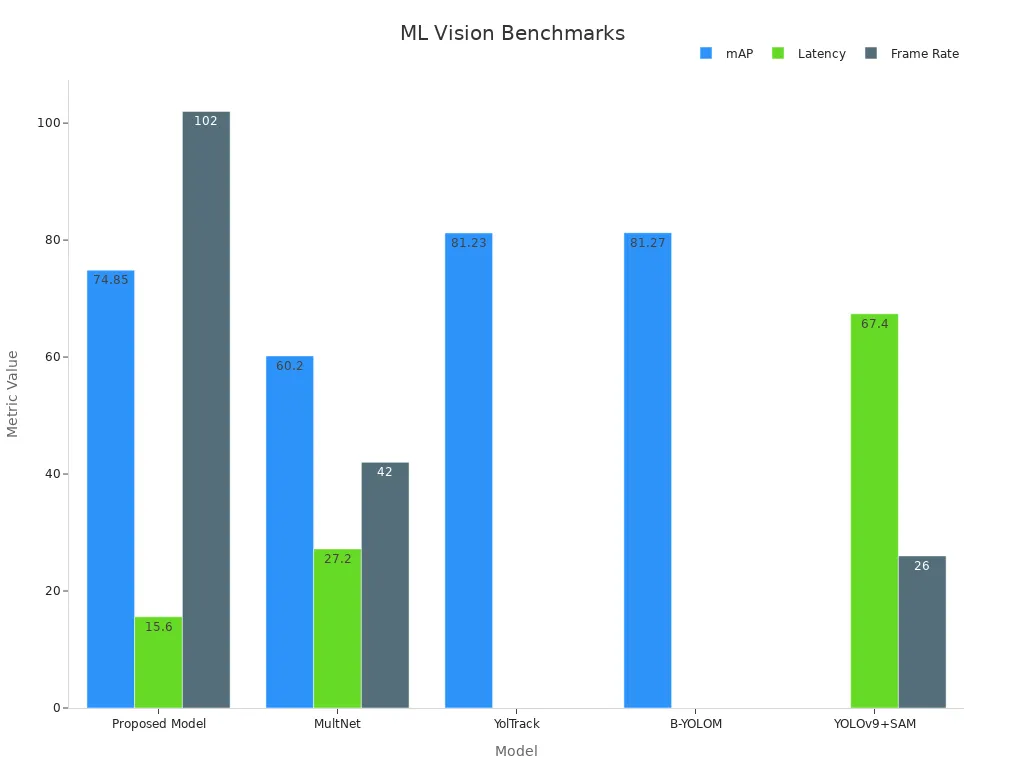
These results highlight how advanced pipelines reduce latency and increase frame rates. Real-time processing and higher accuracy become possible in machine vision tasks. Deep learning models benefit from automated data flow, faster training, and reliable evaluation. Teams can adapt quickly to new data and changing requirements.
Teams that invest in a strong machine learning pipeline see better detection, recognition, and accuracy. They also achieve faster deployment and more reliable results in their machine vision system.
Model Engineering
Deep Learning for Object Detection
Deep learning has transformed object detection in machine vision. Teams use advanced neural networks to identify and locate objects in images and video streams. These models rely on feature extraction to learn patterns from large datasets. Feature extraction helps the model focus on important details, such as edges, shapes, and textures. During training, the model learns to distinguish between different objects by analyzing these features.
Object detection models like YOLOv3 and X-Profiler deliver high accuracy and speed. For example, X-Profiler achieves 0.867 accuracy, 0.892 precision, 0.871 recall, and 0.881 F1 score. These numbers show strong performance in real-world detection tasks. The table below compares several models:
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| X-Profiler | 0.867 | 0.892 | 0.871 | 0.881 |
| DeepProfiler | 4.45 ± 4.84 | N/A | N/A | N/A |
| CellProfiler | 3.48 ± 3.56 | N/A | N/A | N/A |
Deep learning models such as YOLOR have improved mean Average Precision (mAP) by 3.8% over PP-YOLOv2 at the same inference speed. YOLOR also increases inference speed by 88% compared to Scaled-YOLOv4. These improvements make real-time object detection possible in demanding environments. AlexNet set a milestone by reducing image classification error rates from 26.2% to 15.3%. This leap in accuracy changed the landscape of machine vision.
Object detection models now process images within milliseconds. This speed is vital for applications like autonomous vehicles, where rapid detection and recognition prevent accidents. Teams use feature extraction to boost detection accuracy and reduce false positives. Deep learning enables models to adapt to new data, improving detection and recognition over time.
Tip: Teams should monitor accuracy, precision, recall, and F1 score during model training to ensure reliable object detection.
Object Recognition
Object recognition builds on object detection by identifying and classifying detected items. Deep learning models use feature extraction to analyze object characteristics. These models learn to recognize objects by comparing features from training data to new images. Object recognition supports tasks like defect detection, quality control, and inventory management.
Teams use several metrics to measure object recognition performance:
- Intersection over Union (IoU): Measures overlap between predicted and actual bounding boxes.
- Precision: Shows how well the model avoids false positives.
- Recall: Indicates the model’s ability to find all relevant objects.
- F1-Score: Balances precision and recall.
- Average Precision (AP): Summarizes the precision-recall curve.
- Mean Average Precision (mAP): Averages AP across confidence thresholds.
Feature extraction plays a key role in improving recognition accuracy. For example, a ResNet-50 model reached 96.1% accuracy in welding defect detection. This high accuracy ensures reliable performance in industrial settings. Teams use object recognition to automate inspection, reduce errors, and improve consistency.
| Task Type | Common Metrics | Purpose/Description |
|---|---|---|
| Object Detection | Intersection over Union (IoU), mean Average Precision (mAP) | Evaluate localization accuracy and detection precision across classes |
| Image Classification | Accuracy, Precision, Recall, F1 Score | Measure classification correctness and balance between precision and recall |
Deep learning models support real-time recognition, which is essential for automated production lines. Feature extraction and robust training pipelines help models adapt to new types of objects and defects. Teams use object recognition to enhance safety, efficiency, and reliability in machine vision systems.
Collaboration with Domain Experts
Collaboration with domain experts strengthens model engineering in machine vision. Domain experts provide insights that guide feature extraction, model selection, and training strategies. Their knowledge helps teams set realistic goals and avoid non-viable approaches. Early involvement of experts sparks productive discussions and leads to better model specifications.
A case study in diabetes prediction showed that involving 174 healthcare experts improved model steering and collaboration. The studies found that expert input led to more effective explanations and better data configuration. The table below highlights the impact of expert collaboration:
| Metric | Baseline AUROC | AUROC with Domain Expert Collaboration | Statistical Significance |
|---|---|---|---|
| P1 | 0.62 | 0.82 | p << 0.001 |
| P2 | 0.61 | 0.89 | p << 0.001 |
These results show that domain expert collaboration boosts classification performance. Teams benefit from expert feedback during the machine learning development cycle. This feedback improves model relevance, acceptance, and accuracy.
- Early expert involvement helps identify non-viable modeling goals.
- Experts guide feature extraction for better detection and recognition.
- Collaboration leads to more useful and relevant model specifications.
- Ongoing feedback improves model training and deployment.
Scientific machine learning combines domain knowledge with deep learning. This approach improves interpretability, explainability, and adherence to physical principles. Teams use physics-informed models to enhance detection accuracy and reliability. Feature extraction and multi-modal data fusion further improve model robustness. These strategies support safety-critical applications, such as defect detection and predictive maintenance.
Machine vision systems in Industry 4.0 rely on deep learning, object detection, and object recognition. These systems enable rapid detection of faulty goods, improve quality assurance, and support dynamic production lines. Teams achieve higher accuracy and reliability by integrating domain expertise, advanced feature extraction, and robust training pipelines.
Evaluation & Compliance
Testing & Robustness
Teams must test machine vision systems to ensure high accuracy and reliable results. They use many benchmarks, including image and video datasets that focus on visual and temporal reasoning. These datasets help teams check if object detection works well in different situations. Testing strategies include unit testing, data and model testing, and integration testing. Each step checks if the system can handle real-world challenges.
Statistical tests help compare models and measure accuracy. Teams use McNemar’s test and the DeLong test to compare binary classification results. The DeLong test is helpful because it does not depend on thresholds and gives a clear view of model performance. Non-parametric tests like the Wilcoxon signed-rank test and Friedman’s test work well when teams use multiple test sets or cross-validation. Teams also use metrics such as the Dice coefficient and Intersection over Union (IoU) to measure accuracy in object detection and segmentation tasks. Repeated cross-validation and resampling methods help teams get trustworthy results and avoid overfitting.
Note: A strong testing process helps teams find weak spots in object detection and improve accuracy before deployment.
Ethical & Regulatory
Ethical and regulatory compliance is essential in machine vision. Teams must address fairness, privacy, and transparency to build trust. Bias in datasets can lower accuracy in defect detection and cause quality control problems. Companies like Cognex work to keep datasets free from bias, which improves accuracy and fairness. Teams avoid collecting personal information to protect privacy. They also use risk assessments to spot regulatory issues before deploying AI systems.
| Metric | Numerical Data / Statistic | Interpretation / Relevance to Ethical and Regulatory Adherence |
|---|---|---|
| Fairness Score | 91% of datasets score 2 or less out of 5 | Most datasets need better ethical standards |
| Regulatory Compliance Score | 89% of datasets have a compliance score of 0 or 1 | Many datasets lack strong regulatory adherence |
| Privacy Scores | Higher than fairness and compliance | Privacy rules are better followed |
| Institutional Approval | Many datasets lack review board approval | Raises concerns about consent and oversight |
| Data Correction Mechanisms | Present in some datasets | Supports ethical data management |
| Dataset Documentation | Recommended for all datasets | Improves transparency and accountability |
Teams use fairness metrics like Disparate Impact and Demographic Parity to measure bias. They apply techniques such as re-sampling and adversarial debiasing to improve accuracy and fairness. Privacy-preserving technologies, including encryption and secure federated learning, protect sensitive data. Teams also set up protocols for ethical image collection, manage metadata, and maintain strong documentation. Training operators on AI regulations and consulting legal experts help teams keep up with changing rules. These steps ensure that object detection systems meet both production and regulatory goals while maintaining high accuracy.
Deployment & Real-Time Monitoring

Real-Time Integration
Teams achieve success in machine vision system deployments by focusing on real-time integration. They use machine learning lifecycle management machine vision system practices to ensure models work smoothly in production. Real-time analysis allows the pipeline to process images and video instantly. This supports automation and boosts operational efficiency. Edge analytics play a key role. They move model deployment closer to the data source, reducing delay and improving efficiency. Teams track performance using clear metrics.
| Performance Metric | Relevance to Real-Time Integration in Production Environments |
|---|---|
| Throughput | Measures the volume of products processed per unit time, indicating system efficiency. |
| Jitter | Captures variability in data transmission timing, critical for maintaining consistent real-time responses. |
| Delay | Represents latency from data source to destination, affecting responsiveness of machine vision systems. |
| Bandwidth | Defines the maximum data transfer rate, essential for handling high-volume visual data streams. |
| Availability | Percentage of operational uptime, ensuring the system is reliably accessible during production. |
| Error Rate | Frequency of transmission errors, impacting data integrity and system accuracy. |
| Overall Equipment Effectiveness (OEE) | Composite metric assessing availability, performance, and quality, reflecting overall manufacturing efficiency and system success. |
These metrics help teams measure efficiency and operational efficiency in real-time analysis. High throughput and low delay mean the pipeline supports fast, accurate decisions.
Continuous Monitoring
Continuous monitoring keeps the machine learning lifecycle management machine vision system reliable. Teams use real-time monitoring to track model performance and pipeline health. They set up alerts for drops in accuracy or increases in error rates. Monitoring helps teams spot problems early and maintain operational efficiency. Research shows that monitoring after model deployment ensures ongoing safety and effectiveness. The deployed model can change the data it receives, so teams must adjust their monitoring strategies. They use different data sources and metrics to get a full picture of system health. Causal inference helps teams understand how changes in the model or pipeline affect outcomes. Not all monitoring systems work the same way, so careful design is important.
Tip: Teams should use real-time analysis and monitoring to keep the pipeline efficient and models accurate.
Lifecycle Updates
Lifecycle updates keep the machine learning lifecycle management machine vision system up to date. Teams retrain models with new data and improve the pipeline for better efficiency. They use automation to track experiments and manage version control. Model deployment strategies like A/B testing help teams compare results and pick the best model. Regular updates reduce downtime and improve operational efficiency. Teams see measurable improvements after lifecycle updates.
| Measurable Improvement | Description | Impact on Machine Vision Deployments |
|---|---|---|
| Inference Time (Latency) | Time taken by the model to process an image. Critical for real-time applications. | Reduced latency improves responsiveness and user experience. |
| Throughput (Frames Per Second) | Number of images processed per second. | Higher throughput enables handling larger data volumes efficiently. |
| Memory Footprint | Amount of RAM or GPU memory required by the model. | Lower memory usage is essential for edge and mobile deployments. |
| Model Accuracy and Robustness | Improvements through continuous learning, iterative training, and experimentation. | Leads to better detection rates and adaptability to real-world data. |
| Error Rates | Reduction in false positives and false negatives through continuous monitoring and retraining. | Enhances reliability and trustworthiness of the system. |
| Downtime | Decrease in system downtime due to early detection of performance drops. | Ensures higher availability and operational continuity. |
| Scalability and Cost-Effectiveness | Ability to scale operations without manual intervention and optimize resource usage. | Supports business growth and reduces operational expenses. |
Teams that update the pipeline and retrain models see better efficiency, higher operational efficiency, and improved real-time analysis. Automation and structured management turn static systems into evolving solutions that support business growth.
Disciplined machine learning lifecycle management helps teams build successful, real-time, and scalable machine vision systems. Each phase, from planning to monitoring, uses quality checks like data versioning and experiment tracking. These steps improve reproducibility, stability, and growth in real-world applications. Teams who follow structured practices see better model performance and fewer errors. As Industry 4.0 grows, strong lifecycle management will shape the future of machine vision.
FAQ
What is machine learning lifecycle management in machine vision?
Machine learning lifecycle management means planning, building, testing, and updating machine vision systems. Teams use this process to keep models accurate and reliable as new data arrives.
Why does synthetic data matter for machine vision?
Synthetic data helps teams train models when real images are hard to get. It fills gaps, reduces bias, and improves accuracy. Teams use it to make models work better in rare or unusual situations.
How do teams monitor machine vision systems after deployment?
Teams set up real-time monitoring tools. These tools track accuracy, speed, and errors. Alerts help teams fix problems quickly. Monitoring keeps the system working well every day.
What role do domain experts play in machine vision projects?
Domain experts share knowledge about the field. They help teams choose the right features and set good goals. Their advice improves model accuracy and makes results more useful.
How do teams keep machine vision systems up to date?
Teams retrain models with new data and update the pipeline. They use automation to test changes. Regular updates help the system stay accurate and ready for new challenges.
See Also
Understanding Predictive Maintenance Using Advanced Machine Vision
The Impact Of Deep Learning On Machine Vision Technology
Guidance Machine Vision And Its Importance In Robotics
Complete Overview Of Machine Vision For Industrial Automation
Comparing Firmware-Based Machine Vision With Conventional Systems








