
Computer vision systems rely on logit functions to help ai understand images and videos. In many ai applications, the Logit Function machine vision system takes raw outputs from a model and uses mathematical tools to create probabilities. For example, the softmax function changes numbers like [1.0, 2.0, 3.0] into a set of probabilities that add up to one. This step is important because it lets computer vision ai make decisions in real-world applications, such as sorting objects or detecting faces. By using these methods, computer vision ai can turn complex data into clear choices for many applications.
Key Takeaways
- Logit functions convert raw model outputs into probabilities, helping AI make clear decisions in image recognition and detection tasks.
- The sigmoid function transforms logits into probabilities between 0 and 1 for binary classification, while softmax handles multiple classes by creating probability distributions.
- Using probabilities improves AI confidence and accuracy in real-world applications like object detection, safety monitoring, and quality control.
- Vision transformers combined with logit-based methods boost AI performance and interpretability, enabling better understanding and accuracy in complex image tasks.
- Logit functions support automation and scalability in computer vision but require careful data handling to avoid challenges like overfitting and bias.
Logit Function Machine Vision System
Model Outputs
The logit function machine vision system forms the backbone of many computer vision models. In these systems, the model receives an image and processes it through several layers. Each layer extracts features, such as edges or colors, from the image. After this processing, the model produces raw outputs called logits. These logits are real numbers that do not represent probabilities yet. Instead, they show how strongly the model believes an image belongs to a certain class.
For example, a computer vision model might analyze a photo to decide if it shows a cat or a dog. The logit function machine vision system will output a logit for each class. If the logit for "cat" is higher than for "dog," the model leans toward predicting "cat." However, these logits need further transformation to become useful probabilities for ai applications.
Deep learning models, especially those using transformers, rely on logits to summarize the information learned during training. These models can handle complex images and large datasets, making them ideal for modern computer vision tasks. The logit function machine vision system allows ai to process images quickly and accurately, which is essential for real-time applications like self-driving cars or security cameras.
Comparative studies show that deep learning models with logit-based classifiers, such as those found in MobileNetV2 or transformers, outperform traditional image processing methods. These models achieve high accuracy and fast processing speeds, even in challenging environments. They also benefit from advanced optimization techniques and data preprocessing, which help the model learn better and make more reliable predictions.
The logit function machine vision system transforms raw data into meaningful outputs, making it a key part of computer vision and ai applications.
Logistic Function
The logistic function, also known as the sigmoid function, plays a crucial role in the logit function machine vision system. This function takes the raw logit values from the model and converts them into probabilities between 0 and 1. This step is important because probabilities are easier to interpret and use in real-world applications.
- The sigmoid function maps any real number (logit) to a value between 0 and 1, making it perfect for probability estimation.
- It acts as the inverse of the logit function, giving a clear link between logits and probabilities.
- The S-shaped curve of the sigmoid means that outputs close to 0 or 1 show strong confidence in a class, while values near 0.5 show uncertainty.
- The function is smooth and differentiable, which helps the model learn during training using gradient descent.
- By setting a threshold (often 0.5), the model can make binary decisions, such as "cat" or "not cat."
- For tasks with more than two classes, the sigmoid can be used in a one-vs-rest approach, or the softmax function can be applied for multiclass problems.
- Many industries, including healthcare and manufacturing, use the sigmoid function to turn model outputs into clear, actionable probabilities.
Logistic regression uses the logistic function to solve classification problems in computer vision. For example, a model might use logistic regression to decide if an image contains a specific object. The logit function machine vision system, combined with logistic regression, helps ai make decisions based on visual data.
| Aspect | Traditional ML | Deep Learning with Logit-based Methods |
|---|---|---|
| Training Time | Shorter | Longer, needs powerful hardware |
| Computational Resources | Standard CPUs | GPUs or specialized hardware |
| Dataset Size | Small datasets | Large labeled datasets |
| Model Complexity | Simple models | Complex, multi-layer architectures |
| Scalability | Limited | Highly scalable |
| Interpretability | Easy to understand | Often a "black box" |
| Processing Time | Very fast inference | Slower inference |
This table shows that while traditional methods work well for simple tasks, deep learning models with logit-based systems and transformers offer better performance for complex computer vision applications. The logit function machine vision system, powered by the logistic function, enables ai to process images efficiently and make accurate predictions.
Logits to Probabilities
Sigmoid and Softmax
In computer vision, a model often produces raw outputs called logits. These logits do not represent probabilities. To make sense of these outputs, the model uses special mathematical functions. The sigmoid function helps in binary classification tasks. It takes a logit and transforms it into a value between 0 and 1. This value shows the probability that an image belongs to a certain class. For example, in an image recognition task, the sigmoid function can help the model decide if a picture contains a cat or not.
The softmax function works when the model needs to choose between more than two classes. It takes a list of logits and turns them into a set of probabilities that add up to one. This is important for tasks like image classification, where the model must pick the correct label from many options. In a computer vision application, the softmax function helps the model decide if an image shows a dog, a car, or a tree.
Researchers use Python libraries like PyTorch to apply these functions in real-world ai applications. For example, a model might use softmax to turn logits into confidence scores for each possible label in an image classification model. This process allows the model to make probabilistic predictions, which are easier to understand and use in practice.
The sigmoid function, written as ( sigma(z) = frac{1}{1 + e^{-z}} ), is common in logistic regression for binary classification. The softmax function, written as ( text{softmax}(z_i) = frac{e^{z_i}}{sum_{j=1}^K e^{z_j}} ), is used for multiclass classification. Both functions help the model provide clear, interpretable probabilities.
A statistical study found that using optimized activation functions like sigmoid and softmax improved classification accuracy by 92.8% over older methods. The choice between sigmoid and softmax depends on the type of recognition task. Sigmoid works best for binary detection, while softmax is better for multiclass recognition. In mixture of experts models, sigmoid gating functions often lead to better performance and faster learning than softmax gating functions. The table below compares these two functions in machine vision systems:
| Aspect | Sigmoid Gating Function | Softmax Gating Function |
|---|---|---|
| Performance | Superior performance demonstrated empirically | Commonly used but can cause representation collapse |
| Convergence Rate | Faster convergence rates | Slower convergence rates |
| Sample Efficiency | Needs fewer samples for same error level | Needs more samples for equivalent accuracy |
| Impact on Representation | Avoids representation collapse | Can cause representation collapse |
Importance in Detection
Probability outputs play a key role in detection and recognition tasks in computer vision. When a model analyzes an image, it must decide if certain objects are present. The model uses probabilities to show how confident it is in its predictions. For example, in object detection, the model assigns a probability to each detected object. This helps the ai system decide which objects to highlight or track.
Detection systems rely on these probabilities to make safe and reliable decisions. In safety-critical applications, such as self-driving cars or medical imaging, the model must provide trustworthy predictions. Probability calibration metrics help measure how well the model’s confidence matches real-world outcomes. These metrics include calibration plots, which compare predicted probabilities to actual results, and object detection metrics like precision, recall, and mean average precision (mAP). These metrics depend on the confidence scores produced by the model.
| Metric Type | Metric Name | Description & Role in Validating Probability Outputs |
|---|---|---|
| Calibration Metrics | Calibration Plot | Assesses how well predicted probabilities match true outcome frequencies; crucial for trustworthy probability outputs in detection. |
| Segmentation Metrics | Dice Similarity Coefficient | Measures overlap between predicted and true segmentation; supports evaluation of pixel-level classification accuracy. |
| Segmentation Metrics | Hausdorff Distance | Measures distance between predicted and true object edges; important for spatial accuracy in segmentation tasks. |
| Object Detection | Precision, Recall | Evaluate detection correctness and completeness, dependent on confidence thresholds derived from probability outputs. |
| Object Detection | Average Precision (AP) | Area under precision-recall curve, relies on confidence scores to rank detections across thresholds. |
| Object Detection | Mean Average Precision (mAP) | Mean of APs across classes and IoU thresholds; highlights the importance of calibrated confidence scores for ranking and decision-making. |
In computer vision, ai models use these metrics to improve detection and recognition performance. Well-calibrated probabilities help the model avoid false alarms and missed detections. This is especially important in applications like security cameras, where the model must detect unusual activity with high accuracy.
The use of probabilities also supports better decision-making in image recognition and object detection. For example, a model can use a threshold to decide when to alert a human operator. If the probability is high, the system can act quickly. If the probability is low, the system can ignore the detection. This approach makes ai applications more efficient and reliable.
Detection and Logistic Function
Sub-pixel Edge Detection
Sub-pixel edge detection helps computer vision systems find edges with very high accuracy. Many applications, such as defect detection and anomaly identification, need this level of precision. Engineers use the logistic function to fit the edge profile in an image. This approach allows the system to locate the edge position even within a single pixel. The process uses several steps to improve detection:
- The edge is modeled with a modified logistic function. Parameters p1 and p2 set the curve’s limits, p3 marks the edge position, and p4 controls the slope.
- The system finds the exact edge position by fitting the logistic function using nonlinear least squares regression.
- Example values from a real detection task include p1=169.76, p2=5.21, p3=4.58, and p4=0.65.
- The edge position is rotated to match the normal direction, which increases localization accuracy.
- Noise reduction methods, such as image stacking and Gaussian filtering, help improve the signal-to-noise ratio.
- The procedure includes capturing several images, reducing noise, detecting edges at the pixel level, enhancing angles, applying logistic regression for sub-pixel detection, and mapping results to real-world coordinates.
- This method allows detection of edge positions beyond the sensor’s resolution, which is important for defect detection and anomaly analysis.
Sub-pixel edge detection using logistic function fitting gives computer vision systems the ability to find very small defects and anomalies that standard methods might miss.
Image Retrieval
Image retrieval is another important area in computer vision. Many applications, such as defect detection and anomaly search, rely on finding similar images quickly and accurately. Logistic regression helps improve detection in these tasks. Penalized logistic regression reached an AUC of 0.85 on complex datasets, which is higher than some deep learning models that scored 0.80. This shows that logistic regression can handle complex feature interactions in image retrieval tasks.
| Model Type | Performance Metric | Improvement |
|---|---|---|
| Logistic Regression | Precision | Significant |
When combined with autoencoder-based feature extraction, logistic regression increases precision in image retrieval. This improvement helps computer vision systems find images with defects or anomalies more reliably. Many industries use these methods in applications like defect detection, anomaly monitoring, and quality control.
Logistic regression supports computer vision applications by making detection and retrieval tasks more accurate and efficient.
Vision Transformers and Logit Lens

Transformers in Vision
Transformers have changed how computer vision works. These models split images into small patches and process them using self-attention. This method helps the model see both the big picture and small details at the same time. Unlike older networks, transformers do not rely only on local features. They can connect information from different parts of an image right from the start.
Vision transformers often outperform traditional deep learning models, especially when working with large datasets. For example, in medical image analysis, vision transformers achieved higher accuracy and better recall than many convolutional models. They reached accuracy rates above 65% and AUC values over 0.83, showing strong performance in tasks like disease detection. However, transformers need more data and computing power than older models. They scale well and become more powerful as the dataset grows.
Researchers have also improved vision transformers by adding logit-based adjustments. These changes help the model generalize better and increase accuracy. In semi-supervised action recognition, vision transformers with logit-based enhancements showed up to 14.9% higher accuracy than conventional deep learning models. The chart below shows how these models improve as the label rate increases:
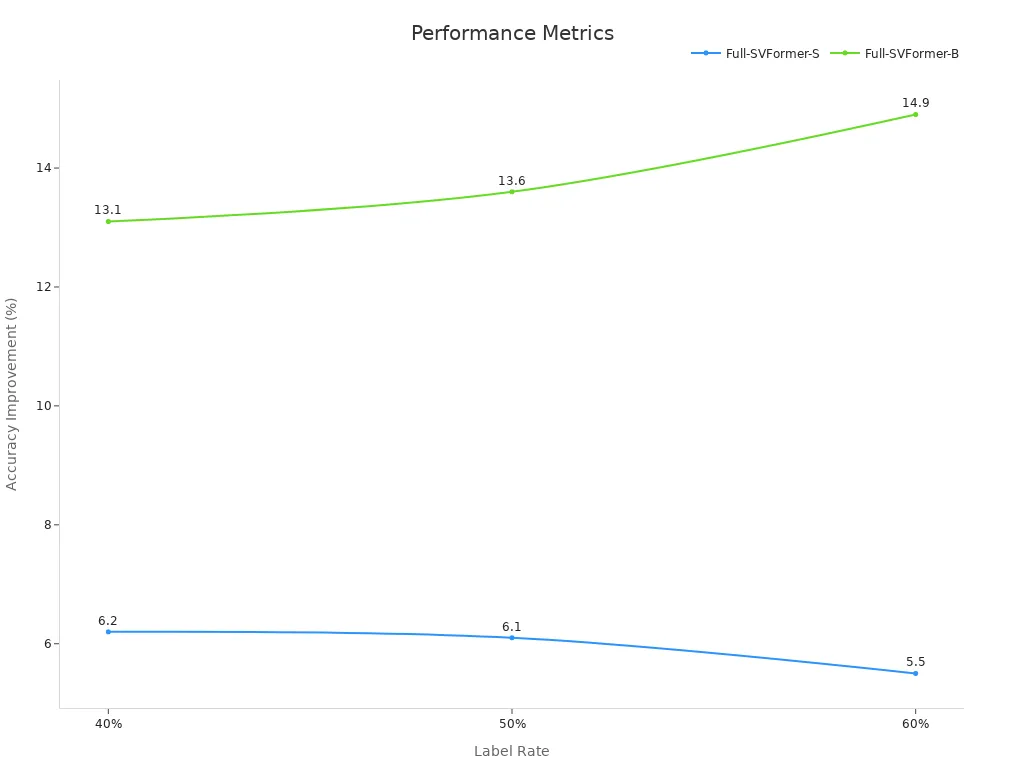
Logit Lens Approach
The logit lens approach helps people understand what happens inside transformers. This method maps the model’s internal activations to probability distributions at each layer. It lets researchers see how the model’s predictions change as the image moves through the layers. Early layers show broad guesses, while later layers focus on the right answer.
Measurements show that the logit lens improves the interpretability of transformers. For example:
- Intervention success rates reach 0.5 to 0.6, showing that changes to features can clearly affect the model’s output.
- The logit lens keeps output coherence high, even after interventions.
- Larger models show even better results, making this method useful for advanced deep learning systems.
- The logit lens also helps reduce hallucinations and improves object localization.
| Metric Description | Improvement / Result |
|---|---|
| Mean Average Precision (mAP) improvement | +22.45% and +47.17% in two Vision-Language Models for hallucination detection |
| Hallucination reduction | Up to 25.7% reduction on standard benchmarks |
| Spatial object localization performance | Comparable to state-of-the-art zero-shot segmentation methods |
Hybrid knowledge transfer and logit distillation further boost on-device vision systems. These methods combine attention and logit information, helping the model learn both global and local features. In agricultural IoT, hybrid distillation led to the highest accuracy and F1 scores, outperforming other methods:
| Distillation Method | Accuracy (%) | F1 Score (%) | Precision (%) | Recall (%) | AUC (%) | mAP (%) |
|---|---|---|---|---|---|---|
| Student-Only | 87.20 | 87.05 | 87.10 | 87.20 | 98.43 | 92.30 |
| Attention Distillation | 92.41 | 92.30 | 92.30 | 92.40 | 99.61 | 97.50 |
| Logit Distillation | 92.62 | 92.60 | 92.30 | 92.60 | 99.38 | 96.40 |
| Hybrid Distillation | 94.58 | 94.53 | 94.59 | 94.58 | 99.64 | 97.53 |
The logit lens and hybrid distillation make vision transformers more interpretable and accurate, helping ai systems perform better in real-world computer vision tasks.
Advantages and Challenges
Benefits
Logit functions bring many benefits to computer vision. These functions help ai systems make clear predictions in image recognition and detection tasks. The use of logit functions supports automation in monitoring, tracking, and quality control. Engineers can rely on these models for fast and accurate processing of images. Deep learning models use logit functions to improve the recognition of objects and support the tracking of objects in real time.
Long-term trends show that logistic regression forms the foundation for many machine learning and deep learning algorithms. This foundation helps computer vision applications provide reliable monitoring and automation. The interpretability of these models allows users to understand how predictions are made. Probabilistic outputs from logit functions give nuanced decision-making support, which is important for quality control and monitoring in industries like manufacturing and healthcare.
Automation powered by logit functions increases the speed and quality of image recognition, detection, and tracking. This leads to better monitoring and higher quality in many applications.
A table below summarizes the main benefits:
| Benefit | Impact on Computer Vision Applications |
|---|---|
| Interpretability | Users can understand predictions |
| Probabilistic Outcomes | Supports nuanced decision-making |
| Foundation for Automation | Enables reliable monitoring and tracking |
| Scalability | Handles large-scale image processing |
| Quality Control | Improves detection and recognition accuracy |
Limitations
Despite these strengths, logit functions face several challenges in computer vision. Traditional methods like logistic regression assume a simple, linear relationship between variables and outcomes. Real-world data in computer vision often breaks these assumptions. High-dimensional data, complex variable interactions, and data heterogeneity can reduce model quality and prediction accuracy.
Logistic regression struggles with outliers and may miss important risk factors when many variables exist. This can affect the quality of monitoring and automation in image recognition and detection. Deep learning models address some of these issues, but they also require careful data preprocessing and regularization to avoid overfitting.
Common challenges include:
- Data quality issues, such as missing values and inconsistent sources, can lower the reliability of predictions.
- Overfitting can occur, especially with high-dimensional data in deep learning applications.
- Integration with legacy systems and workflows can be difficult, slowing down automation and monitoring.
- Ethical concerns, including bias in training data and privacy risks, require ongoing attention.
Continuous monitoring, robust preprocessing, and regular audits help maintain the quality and reliability of computer vision systems that use logit functions.
Logit functions give ai systems the power to understand images and make decisions. These functions help ai models turn raw data into clear predictions. Many industries use ai for tasks like detection, tracking, and quality control. People who work with ai in machine vision need to know how logit functions shape results. New trends show that advanced vision models use logit-based techniques to improve ai performance. Researchers continue to find better ways for ai to learn from visual data.
FAQ
What is a logit in machine vision?
A logit is a number that shows how much a model believes an image belongs to a certain class. The model uses this value before turning it into a probability.
How does the sigmoid function help in image recognition?
The sigmoid function changes a logit into a probability between 0 and 1. This helps the model decide if an object is present in an image.
Why do models use softmax for multiclass problems?
Softmax takes several logits and turns them into probabilities that add up to one. This lets the model pick the most likely class from many options.
Can logistic regression work for image tasks?
Yes. Logistic regression can help find objects or patterns in images. It works well for simple tasks and sometimes matches deep learning in accuracy.
What makes logit functions important for real-world AI?
Logit functions let AI systems make clear, confident choices. They help turn complex image data into simple, useful answers for tasks like sorting, tracking, and safety checks.
See Also
Understanding Logistics And Its Role In Machine Vision
A Beginner’s Guide To Sorting Using Machine Vision
The Role Of Synthetic Data In Machine Vision Technology
Introduction To Metrology Applications In Machine Vision
Demystifying Computer Vision Models And Machine Vision Systems








