
A learning-to-rank machine vision system helps computers decide the order of images or objects by their importance or relevance. In many cases, a machine vision system must not just find items but also rank them, such as sorting photos by quality or matching faces. Today, learning-to-rank machine vision system technology appears in search engines, shopping apps, and even medical tools. Unlike a regular machine vision system that only classifies or detects, this approach focuses on ranking results. What makes ranking different from basic sorting or labeling? The answer can surprise many readers.
Key Takeaways
- Learning-to-rank machine vision systems sort images by importance, helping computers show the most relevant results for tasks like facial recognition and image search.
- Feature engineering is crucial; it extracts, selects, scales, and transforms image details to improve ranking accuracy and system speed.
- Three main ranking methods—pointwise, pairwise, and listwise—help the system learn how to order images based on different approaches.
- Strong data flow and model selection ensure fast, accurate object detection and ranking, using tools like convolutional neural networks and decision trees.
- Learning-to-rank systems boost applications like image classification, retrieval, and vision-language models, but require ongoing updates to handle new images and avoid errors.
Core Concepts
Learning-to-Rank Overview
A learning-to-rank machine vision system helps computers decide the best order for images or objects. This process goes beyond simple sorting. It uses learning-to-rank methods to understand which items should come first based on their importance. In many cases, the system must handle large sets of images. It uses query understanding to figure out what the user wants. For example, if someone searches for "smiling faces," the system uses query understanding to find and rank the most relevant images.
Learning-to-rank works by teaching the computer to look at many features in each image. These features might include color, shape, or texture. The system uses feature extraction to pull out these details. Then, it uses feature selection to pick the most important ones. Feature scaling helps the system compare features that have different ranges. Dimensionality reduction makes the data smaller and easier to handle. Feature transformation changes the features into new forms that help the system learn better. All these steps help the learning-to-rank machine vision system make smart choices about candidate ordering.
Pointwise, Pairwise, Listwise Methods
Learning-to-rank uses three main methods: pointwise, pairwise, and listwise. Each method helps the system learn how to rank images or objects.
-
Pointwise: The system looks at each item by itself. It gives each image a score. The system uses feature engineering to decide which features matter most. Feature scaling and feature selection help the system compare scores fairly. Dimensionality reduction keeps the data simple.
-
Pairwise: The system compares two items at a time. It decides which one should come first. Query understanding helps the system know what the user wants. Feature extraction and feature transformation help the system see the differences between the two items. Feature selection picks the best features for making these choices.
-
Listwise: The system looks at a whole list of items together. It tries to find the best order for all of them. Feature engineering plays a big role here. The system uses feature scaling and dimensionality reduction to handle large lists. Feature transformation helps the system learn patterns in the data. Query understanding guides the system to focus on what matters most to the user.
Note: Each method uses feature engineering, feature extraction, and feature selection in different ways. The choice of method depends on the problem and the type of data.
Feature Engineering
Feature engineering is the heart of a learning-to-rank machine vision system. It helps the system find the most useful information in images. The process starts with feature extraction. The system pulls out details like edges, colors, and shapes. Feature selection then chooses the most important features. This step removes features that do not help the system learn. Feature scaling makes sure all features have the same range. This step is important because some features might have big numbers and others might have small numbers. Dimensionality reduction makes the data smaller. This step helps the system work faster and use less memory. Feature transformation changes the features into new forms. These new forms can help the system learn better.
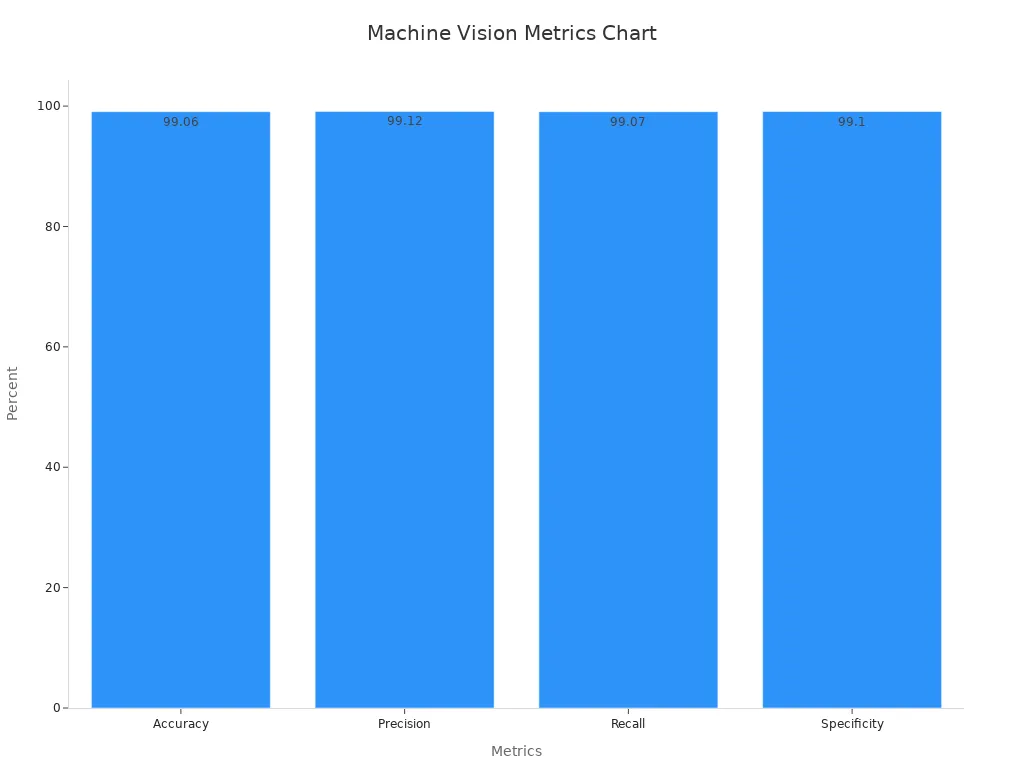
A strong feature engineering process can make a big difference. For example, one image classification system reached 96.4% accuracy by using advanced feature engineering techniques. Another study used a hybrid V-WSP-PSO feature selection method. This method reduced the number of features from 27,620 to just 114. The system achieved a root mean square error of cross-validation (RMSECV) of 0.4013 MJ/kg. The determination coefficient (RCV2) was 0.9908, showing high predictive performance.
The impact of feature engineering can be seen in facial recognition systems. The table below shows results from a study that tested decision tree, KNN, and SVM algorithms:
| Study Type | Algorithms Tested | Accuracy | Precision | Recall | Specificity |
|---|---|---|---|---|---|
| Facial Recognition | Decision Tree, KNN, SVM | 99.06% | 99.12% | 99.07% | 99.10% |
Feature engineering, feature extraction, feature selection, feature scaling, dimensionality reduction, and feature transformation all work together. They help the learning-to-rank machine vision system understand images and make better decisions. Query understanding also plays a key role. It helps the system know what the user wants, so it can rank images in the best way.
System Architecture

Data Flow
A machine vision system uses a clear data flow to process images and videos. The system starts with raw visual data. It moves through several steps, including feature extraction and feature engineering. These steps help the system prepare for object detection and candidate selection. The data flow must stay efficient to avoid delays and bottlenecks. Teams often measure efficiency using these metrics:
- Flow Time: Measures the total time from start to finish, including both active work and waiting.
- Flow Efficiency: Shows the percentage of time spent actively working compared to waiting.
- Flow Load: Counts the number of tasks being handled at once.
- Flow Velocity: Tracks how many tasks the system completes over a set period.
These metrics help teams find problems and improve the machine vision system. A smooth data flow supports fast object detection and better candidate selection.
Model Selection
Model selection plays a key role in building a strong machine vision system. Researchers use large datasets like ImageNet to test different models. They look for models that work well with feature engineering and feature extraction. Empirical studies show that transferability metrics can predict how well a model will perform without needing to retrain every option. This saves time and resources. Public repositories like Tensorflow and Pytorch make it easier to compare models. Recent conferences share new ways to rank models for object detection and candidate selection. These methods help teams choose the best model for their needs, improving both accuracy and speed.
Feature Extraction
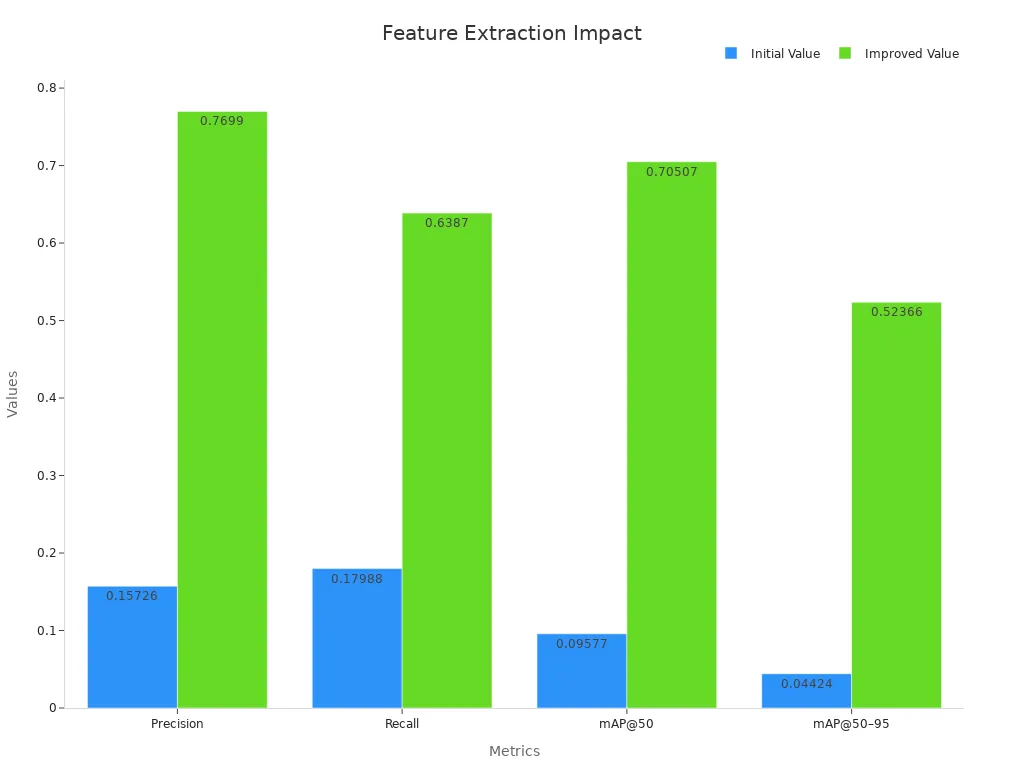
Feature extraction stands at the center of every machine vision system. It works closely with feature engineering and feature selection to find the most important details in images. Advanced algorithms now boost the system’s ability to handle object detection and candidate selection. Research shows big jumps in performance when using better feature extraction methods. The table below highlights these improvements:
| Metric | Initial Value | Improved Value | Description |
|---|---|---|---|
| Precision | 0.15726 | 0.7699 | Shows how often the system correctly identifies objects. |
| Recall | 0.17988 | 0.6387 | Measures how many real objects the system finds. |
| mAP@50 | 0.09577 | 0.70507 | Tracks accuracy in object detection at a set threshold. |
| mAP@50–95 | 0.04424 | 0.52366 | Checks accuracy across different thresholds for complex scenes. |
Modern machine vision systems use convolutional neural networks (CNNs), decision trees, and reinforcement learning. These models rely on strong feature engineering and feature extraction to improve object detection and candidate selection. Feature selection and dimensionality reduction help the system focus on the most useful information. This teamwork leads to faster and more accurate results.
Applications

Image Classification
Image classification helps computers recognize what appears in a picture. Learning-to-rank methods improve this process by teaching systems to sort images by importance or relevance. These systems use object detection to find items in each image, then decide which ones matter most. Facial recognition often relies on image classification to identify people in photos. When engineers use ensemble learning, they combine several models to boost accuracy. For example, a baseline model like xresnet18 reaches 68.1% accuracy after four training rounds. When teams use an ensemble of pretrained models, accuracy jumps to between 92% and 96%. Boosting and data augmentation can push results even higher, sometimes up to 100%. These improvements show how learning-to-rank approaches make image classification much stronger. Competence-based active learning also helps by picking the best samples for training, which saves time and resources.
| Method | Accuracy Range | Notes |
|---|---|---|
| Baseline (xresnet18) | 68.1% | Trained from scratch, 4 epochs |
| Ensemble of multiple pretrained models | 92% – 96% | Averaging predictions improves accuracy |
Image Retrieval
Image retrieval lets users search for pictures that match a query. Learning-to-rank systems use object detection to find relevant images and sort them by how well they fit the search. Information retrieval plays a big role here. The system uses features from each image to compare and rank results. Facial recognition helps when users want to find photos of specific people. Embedding-based retrieval methods allow the system to match images even if they look different but show the same object. Information retrieval techniques help the system handle large databases and return the best matches quickly.
Vision-Language Models
Vision-language models connect pictures with words. These systems use object detection and image classification to understand what appears in an image. They then use information retrieval to match images with the right text. Facial recognition helps the system link names to faces in photos. Information retrieval methods help the model answer questions about images or find pictures that match a sentence. Vision-language models use learning-to-rank to sort results, making sure the most relevant answers come first. These models support many real-world uses, such as smart assistants and search engines.
Tip: Learning-to-rank systems help vision-language models give better answers by sorting results based on both image and text features.
Benefits and Challenges
Advantages
Learning-to-rank machine vision systems offer many benefits. Feature engineering helps these systems find the most important parts of an image. With strong feature engineering, the system can sort images by relevance or quality. Teams use feature engineering to improve accuracy in tasks like facial recognition and object detection. Feature engineering also makes it easier to handle large sets of images. When engineers use feature engineering, they can reduce the number of features, which saves memory and speeds up the system. Feature engineering supports better model selection because it highlights the most useful data. In many cases, feature engineering leads to higher precision and recall. Feature engineering also helps with data flow, making the system more efficient. By using feature engineering, teams can build systems that work well in real-world settings. Feature engineering allows for better adaptation to new types of images. Feature engineering also supports transfer learning, which lets models learn from other tasks. Feature engineering improves the results of ensemble learning, where several models work together. Feature engineering helps vision-language models connect images and text more accurately.
Note: Feature engineering often makes the difference between a good system and a great one.
Common Challenges
Despite the benefits, teams face challenges when building these systems. Feature engineering can take a lot of time and skill. Sometimes, feature engineering does not capture all the important details in complex images. Feature engineering may also lead to overfitting if the system learns patterns that do not generalize well. Engineers must test feature engineering methods carefully to avoid this problem. Feature engineering can become difficult when working with very large datasets. In some cases, feature engineering needs to be updated as new types of images appear. Feature engineering may also require special tools or software. Teams sometimes struggle to balance feature engineering with other parts of the system. Feature engineering can also increase the cost of building and maintaining the system. When feature engineering fails, the whole system may not perform as expected. Feature engineering sometimes needs input from domain experts, which can slow down the process. Feature engineering also faces limits when images have poor quality or missing data.
Tip: Teams should review and update feature engineering methods often to keep systems accurate and reliable.
Implementation
Building a Learning-to-Rank Machine Vision System
Building a learning-to-rank machine vision system starts with clear planning. Teams begin by collecting a large set of labeled images. They use feature engineering to pull out important details from each image. Feature engineering helps the system notice edges, colors, and shapes. Engineers use feature engineering to select the best features for ranking. They apply feature engineering to scale features so that numbers match up. Feature engineering also reduces the number of features, making the system faster. Teams use feature engineering to transform features into new forms that help the model learn better. Feature engineering supports the choice of the right model, such as a convolutional neural network or a decision tree. Engineers use feature engineering to prepare data for training and testing. Feature engineering continues during model updates, helping the system adapt to new images. Teams rely on feature engineering to keep the system accurate and efficient.
A typical workflow includes:
- Data collection and labeling.
- Feature engineering for extraction, selection, scaling, reduction, and transformation.
- Model selection and training.
- System testing and deployment.
- Ongoing feature engineering for maintenance.
Tip: Strong feature engineering leads to better ranking and faster results.
Evaluation Metrics
Evaluating a learning-to-rank machine vision system requires several metrics. Accuracy, precision, and recall measure how well the system ranks images. Engineers use feature engineering to improve these scores. The confusion matrix shows true positives, false positives, true negatives, and false negatives. Precision-recall curves help visualize performance at different thresholds. Mean average precision (mAP) gives a single score for ranking quality. Teams use cross-validation to test the system on different data splits. The Machine Learning Cumulative Performance Score (MLcps) combines several metrics into one score. This helps teams see the full picture, especially when data is imbalanced. Feature engineering plays a role in boosting all these metrics by making features more useful for ranking.
| Metric | What It Measures |
|---|---|
| Accuracy | Correct rankings |
| Precision | Correct positive rankings |
| Recall | Found relevant items |
| mAP | Overall ranking quality |
| MLcps | Combined performance score |
Note: Using many metrics together gives a better view of system performance.
Learning-to-rank machine vision systems help computers sort images by importance, making them valuable in fields like healthcare and business. Studies show these systems can predict market share with 92% accuracy and improve customer satisfaction. New models use explainable AI and combine data from many sources for better results. Anyone interested in this field can start by exploring open datasets and testing simple ranking models. As technology grows, ongoing learning and adaptation will help teams stay ahead.
| Key Benefit | Impact |
|---|---|
| High prediction accuracy | Better business and medical decisions |
| Explainable results | Easier understanding and trust |
| Open science resources | More opportunities for learning and growth |
FAQ
What is the main goal of a learning-to-rank machine vision system?
The main goal is to sort images or objects by importance or relevance. The system learns which items should come first based on features in the visual data.
How does learning-to-rank differ from image classification?
Image classification assigns a label to each image. Learning-to-rank arranges images in order, showing which ones matter most for a specific task or query.
Which models work best for learning-to-rank in vision systems?
Convolutional neural networks (CNNs) often perform well. Decision trees and reinforcement learning models also help. The best choice depends on the data and the problem.
Why is feature engineering important in these systems?
Feature engineering helps the system find useful details in images. Good features improve ranking accuracy and make the system faster and more reliable.
Can learning-to-rank systems handle new types of images?
Yes. These systems adapt by updating features and retraining models. Regular updates help them stay accurate when new image types appear.
See Also
Understanding Fundamental Concepts Behind Sorting Vision Machines
The Role Of Deep Learning In Improving Vision Systems
A Clear Guide To Computer And Machine Vision Models








