
A learning-to-learn machine vision system acts like a student who not only learns from books but also figures out how to learn better each time. This system uses deep learning, adapts to new tasks, and gains practical skills through experience. When people learn computer vision, they see that machine vision systems depend on both smart software and strong hardware. For example, in a factory, a learning-to-learn machine vision system can spot tiny defects on products faster and more accurately than older systems. In a recent study, combining advanced software, smart cameras, and adaptive lighting improved defect detection from 93.5% to 97.2%. The table below shows how these systems can make roads safer and save money.
| Metric Description | Value/Improvement | Context/Comparison |
|---|---|---|
| Autonomous Vehicle Disengagement Rate | 0.02 per 1,000 miles | Reduced from 0.8 per 1,000 miles |
| Fatal Crashes (Waymo) | 0 over 20 million miles | Compared to human-driven vehicles |
| Economic Savings from Crash Reduction | $800 billion annually | Estimated annual savings |
People who learn computer vision help build machine vision systems that can adapt and improve. These systems make cars safer, factories smarter, and daily life easier.
Key Takeaways
- Learning-to-learn machine vision systems improve themselves by learning from experience, making them smarter and more adaptable to new tasks.
- Deep learning boosts machine vision accuracy and speed, helping systems detect objects and defects better than traditional methods.
- Advanced hardware like high-resolution cameras and fast processors enable real-time image processing and reliable results.
- These systems find real-world use in industries like manufacturing, healthcare, agriculture, and autonomous vehicles, improving safety and efficiency.
- Building skills in programming, deep learning, and computer vision tools empowers people to create and improve these powerful systems.
Core Ideas
What Is a Learning-to-Learn Machine Vision System
A learning-to-learn machine vision system uses advanced technology to help computers see and understand the world. These systems combine cameras, sensors, and powerful processors to capture images and process visual information. Machine vision systems often work with ai, machine learning, and deep learning to make decisions quickly and accurately. For example, in a factory, a machine vision system checks products on an assembly line to find defects. Robots in supermarkets use these systems to navigate aisles, manage inventory, and work safely with people.
A learning-to-learn machine vision system does more than just follow instructions. It learns from experience and improves over time. Reinforcement learning helps these systems make better choices by rewarding correct actions. For instance, a robot learns to avoid obstacles by trying different paths and receiving feedback. This process allows the system to adapt to new situations, making it smarter and more flexible.
Hardware improvements, such as faster GPUs and TPUs, help these systems process images quickly. Edge devices allow machine vision systems to make decisions in real time, which is important for tasks like driving autonomous vehicles or guiding robots in busy environments. These advancements support the learning-to-learn approach, making machine vision systems more efficient and reliable.
Researchers have found that active learning can reduce data labeling costs by up to 60% on large datasets like KITTI and Waymo without losing accuracy. Machine vision systems use statistical tools to find difficult or mislabeled images, which speeds up training and improves results. The active learning process involves picking the most useful images, getting human help to label them, retraining the system, and repeating the steps. This cycle helps the system learn faster and perform better, especially in challenging areas like medical imaging and autonomous vehicles.
Machine vision systems that learn how to learn can handle new tasks, adapt to changes, and solve problems that older systems cannot. This ability makes them valuable in many fields, from healthcare to industry.
Deep Learning in Machine Vision
Deep learning has changed the way machine vision systems work. Deep learning models use neural networks to process images and learn from large amounts of data. These models can recognize patterns, shapes, and objects with high accuracy. Unlike older methods, deep learning systems do not need people to tell them what features to look for. They learn directly from raw images, which makes them powerful and flexible.
The table below shows how deep learning improves accuracy in machine vision tasks compared to traditional methods:
| Task Type | Deep Learning Accuracy (%) | Traditional Methods Accuracy (%) |
|---|---|---|
| Binary Classification | 94.05 – 98.13 | 85.65 – 89.32 |
| Eight-Class Classification | 76.77 – 88.95 | 63.55 – 69.69 |
Deep learning machine vision systems use deep learning algorithms like convolutional neural networks (CNNs) to perform tasks such as image classification, object detection, and semantic segmentation. These deep learning approaches help the system learn features at different levels, from simple edges to complex shapes. For example, in image classification, deep learning models can sort images into categories such as cats, dogs, or cars. In semantic segmentation, the system labels each pixel in an image, which is useful for tasks like medical imaging or self-driving cars.
- In manufacturing, deep learning increases defect detection rates by 25% and reduces downtime by 30%. This leads to better quality control and smoother operations.
- In healthcare, deep learning models analyze X-rays and MRIs, helping doctors find diseases early and make better decisions.
- Autonomous vehicles use deep learning for object detection, lane recognition, and pedestrian tracking. These features improve safety and allow cars to make decisions in real time.
- Retail stores and smart surveillance systems use deep learning to prevent theft, study customer behavior, and improve security. These systems reduce false alarms and make stores safer.
- Neural networks like ResNet and Faster R-CNN set new standards in image classification and object detection, making real-time applications possible in many industries.
Deep learning systems adapt over time by learning from new data. This ability helps them stay accurate and reliable, even when the environment changes. Deep learning algorithms use large datasets to train, but active learning strategies help reduce the amount of labeled data needed. For example, pool-based sampling and uncertainty sampling help the system focus on the most important images, saving time and effort.
Deep learning approaches also use policy gradient methods, which help the system learn from rewards and improve actions. These methods work well in complex environments, such as robotics and industrial inspection. Advanced deep learning algorithms like PPO and SAC show high success rates and sample efficiency in vision tasks. These deep learning systems can handle continuous and high-dimensional action spaces, making them suitable for dynamic and challenging tasks.
Deep learning has made machine vision systems smarter, faster, and more adaptable. These systems now play a key role in ai, helping solve problems in many fields, from industry to healthcare.
Key Components
Hardware and Sensors
Machine vision systems rely on advanced hardware to achieve high-quality results. Cameras, sensors, lenses, lighting, and filters all play a role in capturing clear images for deep learning. High-resolution cameras and precise sensors help detect small defects during automated defect detection. Lighting and filters improve image contrast, making it easier for deep learning models to spot defects and ensure quality.
- International standards like EMVA 1288 and VDI/VDE/VDMA 2632 define how to measure camera performance and validate hardware.
- Hardware interface standards such as Camera Link, CoaXPress, and GigE Vision specify data transfer speed, cable length, and connector strength.
- Performance metrics include data throughput, latency, and signal stability. For example, CLHS speed grade S25 allows up to 100 Gbps over a single cable.
- Software standards like GenICam provide a common way to control cameras and transfer data.
Machine vision systems use these standards to achieve over 99% defect detection accuracy. They reduce human error, increase production speed, and improve worker safety. Automated optical inspection systems in electronics and automotive industries use these technologies to find defects and maintain high quality.
Software and Libraries
Software tools power deep learning in machine vision systems. OpenCV helps with image processing and feature extraction, while TensorFlow and PyTorch support building and training deep learning models for object detection and defect detection. PyTorch offers a dynamic computation graph, making it easy to experiment and debug. TensorFlow provides scalability and supports deployment on many platforms. Combining OpenCV with TensorFlow or PyTorch lets developers use fast image processing with advanced deep learning technologies.
People who want to learn python for computer vision or learn c++ for computer vision can use these libraries to build quality machine vision systems. OpenCV works well with both languages, making it a popular choice for automated defect detection and automated optical inspection. Deep learning models trained with these tools improve defect detection and object detection accuracy, leading to better quality control.
Adaptation Mechanisms
Adaptation mechanisms help machine vision systems adjust to new tasks and changing environments. Deep learning technologies allow these systems to learn from new data and improve over time. Studies show that adaptation is key for good performance in complex settings. For example, in patient safety simulations, teams that adapt quickly to unexpected events achieve better outcomes. In education, students with high adaptability set goals, manage time, and adjust strategies, leading to higher quality learning.
Machine vision systems use adaptation to handle new types of defects and maintain high defect detection rates. Deep learning models update themselves as they see more data, which helps them stay accurate. This adaptability supports quality control in industries where defects change often. Deep learning makes it possible for machine vision systems to keep up with new challenges and deliver reliable results.
How Learning-to-Learn Works

Training and Adaptation
A learning-to-learn machine vision system follows a clear workflow. The process starts with data acquisition. Cameras and sensors collect images from the environment. The system then uses preprocessing to improve image quality. This step removes noise and adjusts lighting, making the images easier to analyze.
Next, the system performs feature extraction. Deep learning models identify important shapes, edges, and colors in the images. These features help the system recognize objects and patterns. For example, in image classification, the system learns to tell the difference between cats, dogs, and cars by focusing on unique features.
After feature extraction, the system uses object detection and recognition. Deep learning models compare the features from new images to those in large, pretrained datasets. This comparison helps the system identify objects quickly and with high accuracy. The system then classifies these objects into categories, which is important for tasks like automated defect detection or real-time quality control.
The training phase uses large amounts of labeled data. Deep learning models learn from this data by adjusting their internal settings to improve accuracy. Pretrained models make this process faster. They allow the system to skip some early steps and focus on fine-tuning for specific tasks. Transfer learning helps by using knowledge from one task and applying it to another. For example, a model trained for image classification in cars can adapt to detect defects in electronics.
Adaptation happens when the system faces new tasks or changing environments. The system updates its deep learning models with new data. This process helps maintain high accuracy and real-time performance. Automated machine learning tools handle data ingestion, preprocessing, anomaly detection, and model tuning. These tools reduce manual work and speed up adaptation. The system can learn from mistakes, improve over time, and handle new challenges without starting from scratch.
Tip: Pretrained models and transfer learning save time and improve accuracy. They help machine vision systems adapt to new problems quickly.
Evaluation Process
After training and adaptation, the system needs to check its performance. The evaluation process uses several steps to measure how well the deep learning models work. The system splits data into training, validation, and test sets. This method ensures that the model does not just memorize the data but learns to generalize.
Cross-validation helps test the model’s reliability. K-Fold and Stratified K-Fold methods divide the data into parts, train the model on some parts, and test it on others. This process checks if the model performs well on different samples. Time Series K-Fold keeps the order of data for tasks that depend on time, like video analysis.
The system uses many metrics to measure accuracy and performance. These metrics include precision, recall, F1 score, and execution time. The table below explains each metric:
| Metric | Description |
|---|---|
| Accuracy | Reflects the overall success rate in correctly identifying objects or patterns. |
| Precision | Measures how often positive predictions are correct, reducing false positives. |
| Recall | Assesses the system’s ability to detect all relevant instances, minimizing false negatives. |
| Gauge R&R | Ensures measurement consistency across different operators and times. |
| Execution Time | Evaluates how quickly the system processes images and identifies workpieces. |
- Cross-validation metrics like R² score, mean absolute error (MAE), and mean squared error (MSE) give more details about model accuracy and reliability.
- Best practices include grouping related data points in the same fold to avoid data leakage.
- Reporting multiple metrics gives a complete view of the system’s performance.
A learning-to-learn machine vision system uses these evaluation steps to improve over time. The system updates its deep learning models based on feedback. This cycle of training, adaptation, and evaluation helps the system reach higher accuracy and better real-time results. In real-world applications, these steps ensure that the system can handle new tasks, maintain high performance, and deliver reliable results.
Note: Regular evaluation and feedback keep deep learning models accurate and ready for real-time challenges.
Advantages and Applications

Deep Learning Machine Vision Benefits
Deep learning brings many benefits to machine vision systems. These systems adapt quickly to new tasks and environments. Deep learning models improve accuracy in object detection and recognition. They learn from large datasets and adjust to changes in real-time. This ability helps them handle new challenges without starting over.
A comparison of models shows how deep learning outperforms traditional methods in accuracy, precision, recall, and F1 score:
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| X-Profiler | 0.867 | 0.892 | 0.871 | 0.881 |
| DeepProfiler | 4.45 ± 4.84 | N/A | N/A | N/A |
| CellProfiler | 3.48 ± 3.56 | N/A | N/A | N/A |
For example, AlexNet, a deep learning model, reduced error rates in image classification from 26.2% to 15.3%. This improvement shows how deep learning increases accuracy and reliability in computer vision applications. Deep learning models also process images faster. Benchmarks like the Procyon AI Computer Vision Benchmark show that deep learning systems make real-time decisions, which is important for video monitoring and autonomous vehicles.
Data quality plays a big role in deep learning performance. Data-centric approaches, such as data augmentation and noise correction, boost accuracy by at least 3% compared to model-centric methods. This leads to more robust and reliable deep learning machine vision systems.
Real-World Use Cases
Deep learning machine vision systems work in many industries. In electronics manufacturing, they automate defect detection and improve quality control. Textile production uses deep learning for object detection and pattern recognition. Metal finishing plants rely on these systems for real-time inspection and safety.
| Improvement Aspect | Quantitative Impact |
|---|---|
| Inspection error reduction | Over 90% reduction compared to manual inspection |
| Defect rate reduction | Up to 80% reduction in defects |
| Labor cost reduction | About 50% reduction in quality assurance labor costs |
| Cycle time reduction | Up to 20% reduction in manufacturing cycle time |
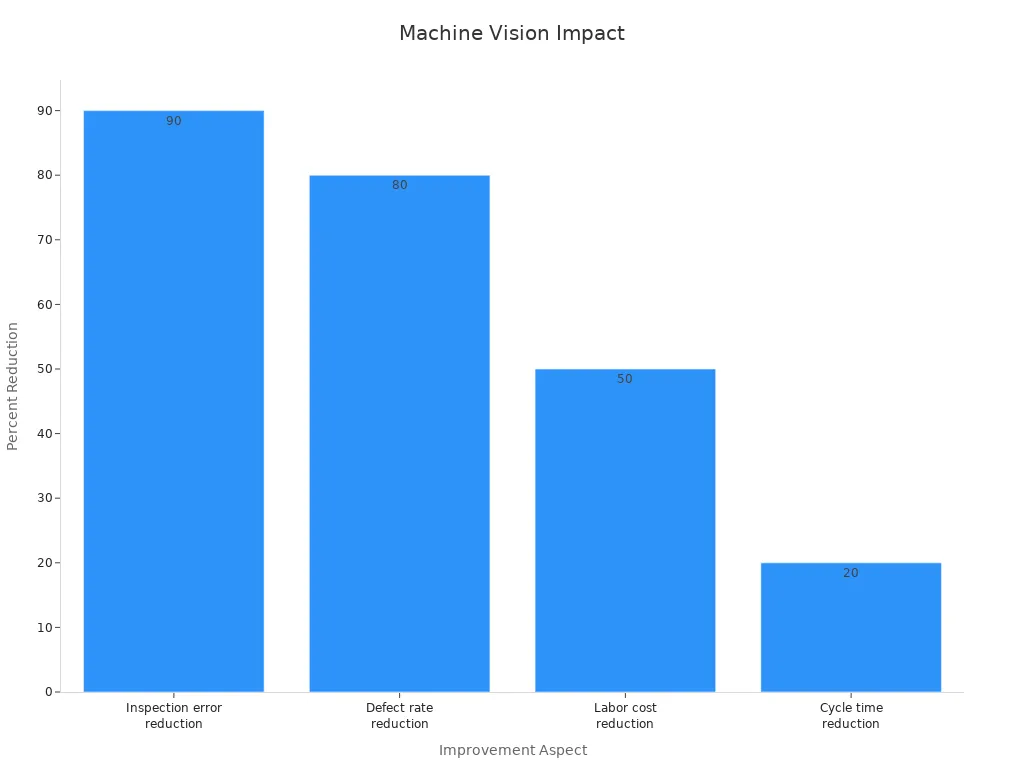
In agriculture, drones with computer vision applications detect crop diseases early. This maximizes yields and improves resource efficiency. Power line inspection uses drones with deep learning to scan 250 km of lines in five minutes. This saves millions of euros and finds 400% more unique defects than manual checks. Tesla uses deep learning for object detection and recognition in manufacturing, reducing human error and boosting production quality.
Deep learning applications also support video monitoring in security and retail. These systems recognize suspicious activity and alert staff in real-time. They help prevent theft and improve safety. Across all these fields, deep learning machine vision systems deliver high accuracy, fast adaptation, and reliable performance.
Skills and Learning Paths
Learn Computer Vision Skills
Building a learning-to-learn machine vision system requires a mix of technical and soft skills. People who want to learn computer vision need to understand programming, math, and problem-solving. Python and C++ are the most common languages for these systems. Many engineers choose to learn python for computer vision because it is easy to use and works well with popular libraries.
The table below shows the most important skills and where they are used in the job market:
| Skill Category | Specific Skills/Technologies | Relevant Job Titles/Applications | Industry Examples |
|---|---|---|---|
| Computer Vision | Image/video analysis, object detection, facial recognition | Computer Vision Engineer, AI Vision Researcher | Automotive, Manufacturing (quality control, autonomous systems) |
| Frameworks & Libraries | TensorFlow, PyTorch, OpenCV | Deep Learning Engineer, AI Research Scientist, Robotics Engineer | N/A |
| Advanced ML Techniques | Reinforcement Learning, Few-Shot Learning, Explainable AI | Reinforcement Learning Engineer, Few-Shot Learning Engineer | Autonomous systems, adaptive AI |
| Soft Skills | Problem-solving, critical thinking, communication, collaboration, adaptability, ethical considerations | AI Solution Architect, ML Product Manager, AI Ethics Consultant | N/A |
| Industry-Specific Skills | Predictive maintenance, computer vision for quality control, autonomous systems | Predictive Maintenance Engineer, Quality Control AI Engineer, Autonomous Vehicle Engineer | Automotive, Manufacturing |
| Ethical AI | Fairness, transparency, accountability in ML systems | AI Ethics Specialist, Responsible AI Engineer | N/A |
| ML Operations (MLOps) | Automating ML lifecycle in production | ML Ops Engineer, AI Infrastructure Specialist | N/A |
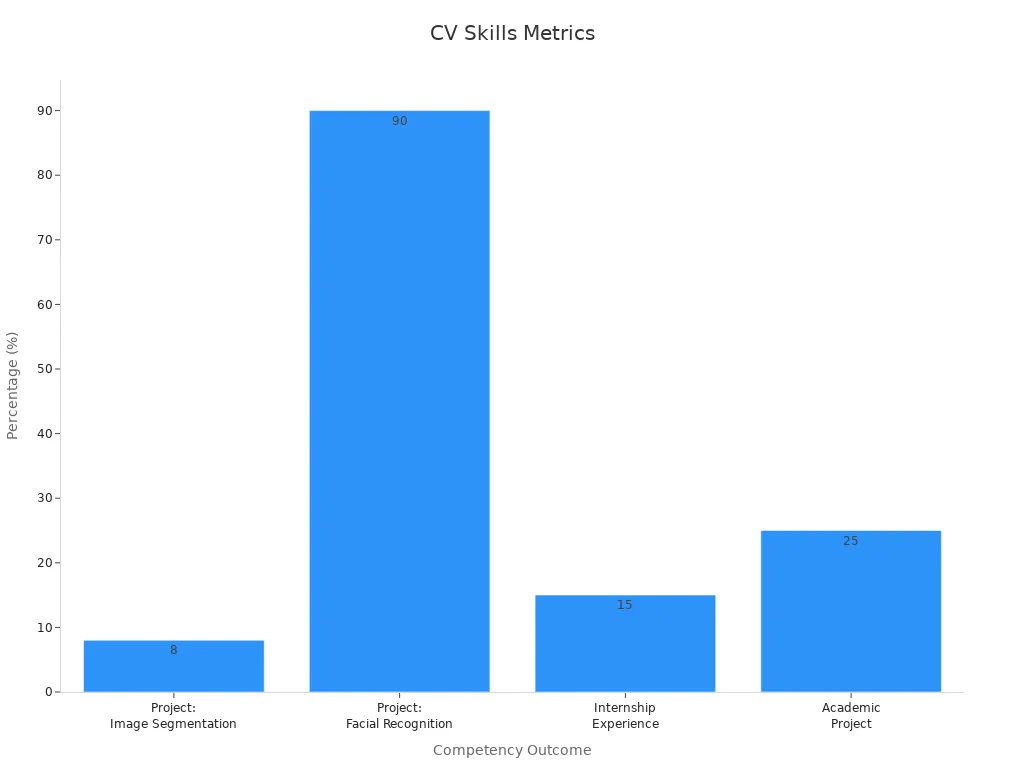
Hands-on experience with computer vision projects helps learners gain real-world skills. For example, building an image segmentation tool or a facial recognition system can improve accuracy and speed. The next table lists key competencies and the results they bring:
| Competency / Training Outcome | Description / Example | Quantifiable Result / Metric |
|---|---|---|
| Programming Languages | Proficiency in Python and C++ | N/A |
| Computer Vision Tools | Skilled use of OpenCV, TensorFlow, PyTorch | N/A |
| Deep Learning Techniques | Hands-on experience with CNNs, Transformers, GANs | N/A |
| Project: Image Segmentation | Developed custom algorithm | Improved diagnostic accuracy by 8% |
| Project: Facial Recognition System | Built hybrid system using Python, TensorFlow, ArcFace, Siamese network, MTCNN | Achieved 90% accuracy on 1,000-face dataset |
| Model Optimization | Model quantization and data augmentation | Faster inference, improved generalization |
| Internship Experience | Real-time object detection system development | 15% improvement in detection speed and accuracy |
| Academic Project | Autonomous navigation system with pathfinding algorithms | 25% increase in navigation efficiency |
| Algorithm Optimization | Parallel processing, batch normalization, code refactoring | 20-30% reduction in execution time and speed boost |
| Certifications | Completion of CVDL Master Program from OpenCV University | Covers advanced computer vision and deep learning |
| Soft Skills | Communication and teamwork | N/A |
Communication and teamwork matter as much as technical skills. Many teams use self-assessment, peer review, and expert feedback to measure skill growth. Regular practice and feedback help learners improve faster.
Machine Learning for Computer Vision Resources
People who want to learn computer vision can start with online courses, books, and hands-on computer vision projects. Many choose to learn computer vision by joining structured programs like the CVDL Master Program from OpenCV University. This program covers advanced topics in deep learning and machine learning for computer vision.
Recommended resources include:
- Online courses: Coursera, Udacity, and edX offer courses on machine learning for computer vision.
- Books: "Deep Learning for Vision Systems" and "Programming Computer Vision with Python" help learners build strong foundations.
- Practice: Working on computer vision projects, such as object detection or image segmentation, builds real skills.
- Community: Joining forums and open-source groups helps learners solve problems and share ideas.
- Tools: Learning to use TensorFlow, PyTorch, and OpenCV is important for anyone who wants to learn computer vision.
People can assess their skills through self-assessment, peer feedback, or expert review. Tracking progress helps learners focus on areas that need improvement. Many employers look for candidates who have completed real computer vision projects and can show results.
Tip: Start with small projects and build up to more complex machine learning for computer vision tasks. Practice and feedback are key to mastering these skills.
Learning-to-learn machine vision systems shape the future of technology. These systems combine deep learning, advanced hardware, and practical skills. People who learn computer vision see real changes in many fields. They help create tools that support users with disabilities and improve safety in cars and hospitals. When students learn computer vision, they find new ways to solve problems. The following trends show the impact:
- People who learn computer vision build systems that reach 99% accuracy in healthcare.
- Real-time processing helps doctors and drivers make better decisions.
- Multimodal AI lets users interact with machines using speech, gestures, and images.
- Retailers who learn computer vision boost sales by 25% with smarter customer tools.
- Creative industries use generative AI to turn text into images, opening new ideas.
Anyone can learn computer vision and join this exciting field. These systems keep evolving, making life safer, smarter, and more inclusive.
FAQ
What does "learning-to-learn" mean in machine vision?
Learning-to-learn means the system improves its own learning process. It adapts to new tasks by using past experiences. This ability helps the system solve new problems faster and with better accuracy.
How do deep learning models help machine vision systems?
Deep learning models help machine vision systems recognize patterns and objects in images. They learn from large datasets. These models improve accuracy and adapt to new tasks without manual programming.
Can someone without a computer science background learn computer vision?
Yes! Many people start with basic programming and math skills. Online courses, tutorials, and hands-on projects make learning computer vision possible for beginners. Practice and curiosity help learners succeed.
What industries use learning-to-learn machine vision systems?
Many industries use these systems, including manufacturing, healthcare, agriculture, and transportation. For example, factories use them for quality control. Hospitals use them for medical imaging. Farms use them to monitor crops.
Tip: Start with small projects and build skills step by step. Practice helps learners gain confidence in computer vision.
See Also
Understanding Models Behind Computer And Machine Vision Systems
Essential Insights Into Computer Vision And Machine Vision
A Clear Guide To Image Processing In Machine Vision
Deep Learning Techniques Improving Machine Vision Performance








