
A modern feature extraction machine vision system helps machines understand the world by identifying important details in every image or video. In 2024, nearly half of retailers already use computer vision, showing how quickly this technology spreads. The global computer vision market, valued at $22 billion in 2023, could reach $50 billion by 2030. Feature extraction serves as the backbone for real-time video analysis, accurate image recognition, and advanced applications in healthcare, manufacturing, and security. Recent advances, such as deep learning-based feature extraction and vision transformers, allow computers to process complex visual data faster and more accurately than ever before.
| Metric / Sector | Statistic / Projection | Timeframe / CAGR | Significance to Feature Extraction Adoption in Machine Vision |
|---|---|---|---|
| Computer Vision Market Size | $22 billion (2023) to $50 billion | 2023 to 2030, 21.4% CAGR | Indicates rapid growth and adoption of computer vision tech, which relies heavily on feature extraction |
| Retail Sector Adoption | 44% of retailers currently use CV | As of 2024 | Demonstrates practical deployment of feature extraction in real-world applications |
Key Takeaways
- Feature extraction helps machines find important details in images and videos, making computer vision faster and more accurate.
- Traditional methods like SIFT and ORB work well for simple tasks, while deep learning models like CNNs handle complex images automatically.
- Hybrid approaches combine traditional and deep learning techniques to improve accuracy and robustness in image recognition.
- Real-time feature extraction powers applications like autonomous vehicles, healthcare imaging, manufacturing quality control, and security surveillance.
- Future trends include vision transformers, synthetic data, and better hardware, which will make machine vision systems more efficient and reliable.
Feature Extraction Basics
What Is Feature Extraction?
Feature extraction in computer vision and machine vision systems transforms raw image data into a set of structured numerical features. This process creates feature vectors that capture the most important characteristics of the original image while removing noise and unnecessary information. By doing this, feature extraction makes image processing more efficient and manageable for computer vision algorithms. Traditional feature extraction techniques use algorithms to detect edges, corners, textures, and shapes. Modern deep learning models, such as convolutional neural networks, automatically learn to extract complex patterns from images through multiple processing layers.
The feature extraction process includes several key steps:
- Feature creation: Identifying important visual elements in the image.
- Feature transformation: Changing the data into a more useful format.
- Feature extraction: Selecting the most relevant features for the task.
- Feature selection: Choosing which features to keep.
- Feature scaling: Adjusting the values for better processing.
- Handling outliers: Managing unusual data points.
- Dimensionality reduction: Making the data smaller and easier to process.
Common dimensionality reduction methods, like Principal Component Analysis (PCA) and autoencoders, help reduce the size of image data while keeping important information. These steps support many computer vision algorithms and improve the speed and accuracy of image processing.
Why It Matters in Computer Vision
Feature extraction plays a foundational role in helping machines understand images and videos. It allows computer vision systems to identify patterns, objects, and shapes, much like how humans recognize things in their environment. Extracted features are essential for tasks such as object detection, image recognition, and facial recognition. In real-world applications, feature extraction powers autonomous vehicles, medical imaging, manufacturing quality control, and security systems.
Note: Robust feature extraction techniques improve accuracy by handling changes in lighting, viewpoint, and occlusions. They also make image processing faster and more reliable, which is critical for real-time computer vision applications.
Efficient feature extraction supports real-time processing, which is important for augmented reality, healthcare, and security. Deep learning models automate the process, learning complex features directly from raw images. This automation reduces manual effort and increases the accuracy of computer vision algorithms. By reducing the size of the data, feature extraction also helps prevent overfitting and speeds up model training. Overall, feature extraction forms the backbone of modern image processing and computer vision systems, enabling machines to interpret and act on visual information.
Techniques for 2025
Traditional Feature Extraction
Traditional feature extraction techniques remain important in computer vision and image processing. These methods use handcrafted algorithms to find key features in images, such as edges, textures, and corners. As of 2025, the most widely used traditional feature extraction techniques include:
- Histogram of Oriented Gradients (HOG)
- Local Binary Patterns (LBP)
- Scale-Invariant Feature Transform (SIFT)
- Speeded-Up Robust Features (SURF)
- Optical Character Recognition (OCR)
These techniques help with object detection, image classification, and video analysis. They work well when computational resources are limited or when there is not enough labeled data for deep learning-based feature extraction. Traditional methods often serve as the first step in image preprocessing and feature detection.
The table below compares some popular traditional feature extraction methods on speed and accuracy:
| Feature Extraction Method | Computational Efficiency (Speed to compute ~300 key-points) | Accuracy (Matched Key-Points under Illumination Change) | Accuracy (Matched Key-Points under 180° Rotation) | Robustness (Average Drift of Top 500 Matched Key-Points) |
|---|---|---|---|---|
| SIFT | Slowest (~116.2 ms) | ~95% matched key-points | ~93% matched key-points | High drift (20 pixels brightened, 91 pixels rotated) |
| SURF | Faster than SIFT (~112.8 ms) | Similar to SIFT (~94-95%) | 100% matched key-points | Low drift (<1 pixel brightened, close to ORB on rotation) |
| ORB | Fastest (~11.5 ms) | Highest (~96%) | 100% matched key-points | Lowest drift (0 brightened, <2 pixels rotated) |
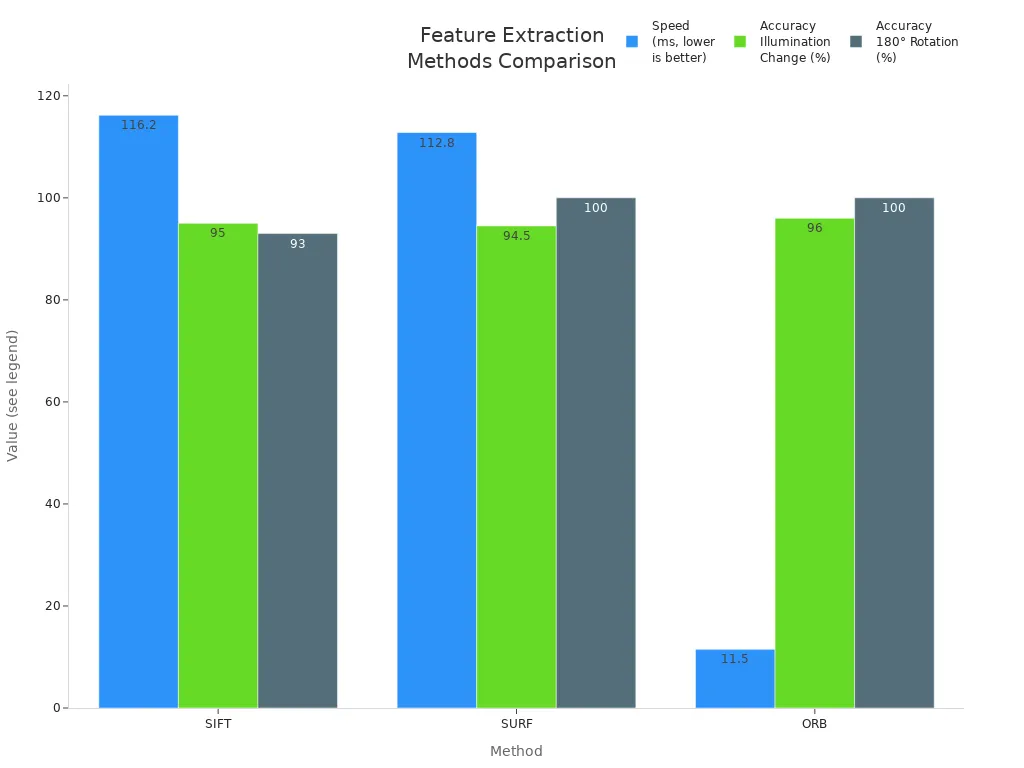
SURF and ORB offer faster processing and better robustness than SIFT. ORB stands out for its speed and accuracy, making it a strong choice for real-time video and object detection tasks.
Deep Learning-Based Feature Extraction
Deep learning-based feature extraction has transformed computer vision and image processing. Convolutional neural networks (CNNs) now lead in extracting features from images and video. CNNs learn to recognize patterns, shapes, and textures directly from raw data. This approach removes the need for manual feature engineering.
Pre-trained CNNs, such as VGG, ResNet, and EfficientNet, allow developers to use models trained on large datasets. These pre-trained CNNs can extract features for new tasks with less data and training time. They support applications like object detection, image classification, and video analysis.
Deep learning-based feature extraction works well for complex tasks, such as facial recognition and autonomous driving. CNNs can process large amounts of image and video data quickly. They also adapt to new types of objects and scenes. Pre-trained CNNs help improve accuracy and reduce the need for labeled data.
Deep learning-based feature extraction now powers most advanced computer vision algorithms. It supports real-time processing for video, object detection, and image classification. CNNs continue to evolve, making image processing faster and more accurate.
Hybrid and Emerging Methods
Hybrid approaches combine traditional feature extraction techniques with deep learning models. This strategy uses the strengths of both methods. For example, the BioDeepFuse framework blends handcrafted features with CNNs and BiLSTM networks. It uses multiple encoding methods to represent input data, then processes these through convolutional and recurrent layers. This combination captures both spatial and temporal patterns in images and video.
Hybrid models often concatenate handcrafted features with features learned by deep learning. This improves classification accuracy and robustness. Dropout layers help prevent overfitting. Comparative studies show that hybrid methods outperform traditional machine learning models like SVM and XGBoost in tasks such as image classification and object detection.
Emerging methods also focus on improving feature extraction with new architectures and training strategies. Vision transformers and self-supervised learning now play a role in extracting features from images and video. These methods help computer vision systems handle more complex tasks and larger datasets.
Note: Preprocessing and dimensionality reduction play a key role in feature extraction. Dimensionality reduction transforms high-dimensional data into a lower-dimensional space, keeping important information. This reduces complexity, speeds up model training, and helps prevent overfitting. Techniques like PCA and LDA remove redundant features, making image processing and computer vision algorithms more efficient.
Hybrid and emerging methods continue to push the boundaries of what feature extraction can achieve. They help machine learning models generalize better and reveal hidden patterns in image and video data.
Applications in Feature Extraction Machine Vision System

Real-Time Video Analysis
Feature extraction machine vision systems play a key role in real-time video analysis. These systems process video frames quickly to detect and recognize objects, people, and activities. They use methods like approximate median filtering, component labeling, and background subtraction to isolate important features from each video frame. Deep learning models improve object detection and tracking, making the system more accurate and reliable.
- Real-time video analysis depends on efficient image processing and feature extraction to handle large amounts of video data.
- Systems use Python and C# for fast processing and easy integration.
- Advanced models like YOLO help manage complex scenes and crowded environments.
- Quantization and mixed-precision inference boost speed and reduce energy use, which is important for real-time processing on edge devices.
These improvements allow security teams to monitor public spaces, traffic, and events as they happen. Real-time video analysis supports quick decision-making and helps prevent incidents before they escalate.
Autonomous Vehicles
Autonomous vehicles rely on feature extraction machine vision systems for safe navigation. These systems process video from cameras to detect road signs, pedestrians, and other vehicles. Real-time object detection and recognition help the vehicle understand its surroundings.
Image processing techniques identify lane markings, traffic lights, and obstacles. Deep learning models support image classification and object recognition, allowing the vehicle to react to changes in the environment.
Real-time processing ensures the vehicle can make split-second decisions, improving safety and reliability.
Healthcare Imaging
Feature extraction transforms healthcare imaging by enabling early disease detection and precise medical image segmentation.
- Deep learning models, especially CNNs, extract patterns from medical images for tasks like tumor segmentation and lesion detection.
- Hybrid methods combine CNNs with LSTM networks to capture both spatial and temporal information, improving diagnosis.
- Feature extraction supports accurate image classification and object recognition in X-rays, MRIs, and CT scans.
These advancements lead to faster, more accurate interpretation of medical images and better patient outcomes. Real-time processing helps doctors make quick decisions during emergencies.
Manufacturing & Quality Control
Manufacturers use feature extraction machine vision systems to inspect products and ensure quality.
Image processing detects defects, measures dimensions, and checks for missing parts in real-time. Object detection and recognition identify faulty products on assembly lines.
Vision systems use both traditional and deep learning-based feature extraction to handle different types of products and materials.
Real-time video analysis allows factories to respond quickly to problems, reducing waste and improving efficiency.
Security & Surveillance
Security and surveillance systems depend on feature extraction for real-time detection and recognition of threats.
- Deep learning models, such as CNNs, identify features like edges and shapes to detect weapons, faces, and intruders.
- Transfer learning with pre-trained models like YOLO and SSD increases detection accuracy and reduces false alarms.
- Systems track movement, recognize license plates, and trigger alerts based on object recognition, not just motion.
These applications help protect public and private spaces by enabling quick responses to security breaches. Real-time video analysis and image processing make surveillance more effective and reliable.
Challenges and Trends
Current Limitations
Feature extraction in machine vision faces several challenges that affect performance and reliability.
- Poor data quality, such as noisy or incomplete images, reduces the accuracy of detection and recognition tasks.
- High computational cost makes real-time processing difficult, especially with large video datasets or complex image transformations.
- Scalability remains a concern as systems must handle growing amounts of image and video data without losing speed or accuracy.
These issues can slow down object detection and recognition in real-time applications. Teams must address these limitations to ensure effective image processing and object recognition in modern computer vision systems.
Future Directions in Computer Vision
The future of feature extraction in computer vision looks promising.
- Deep learning models like CNNs, R-CNNs, and GANs will continue to lead, learning features directly from raw image and video data.
- Unsupervised learning methods, such as principal component analysis and deep belief networks, will help when labeled data is limited.
- Synthetic data generation will boost model accuracy by about 10% and cut data collection costs by 40%. It will also help detect rare cases and reduce bias by up to 15%.
- Automated labeling systems powered by AI will lower error rates to below 1%, making data preparation faster and more reliable.
- Hardware advances, including new GPUs, will support real-time classification and unsupervised learning on edge devices.
These trends will make computer vision applications more accurate, efficient, and adaptable to complex real-time processing tasks.
Implementation Tips
Successful machine vision projects use several best practices to improve feature extraction and image processing:
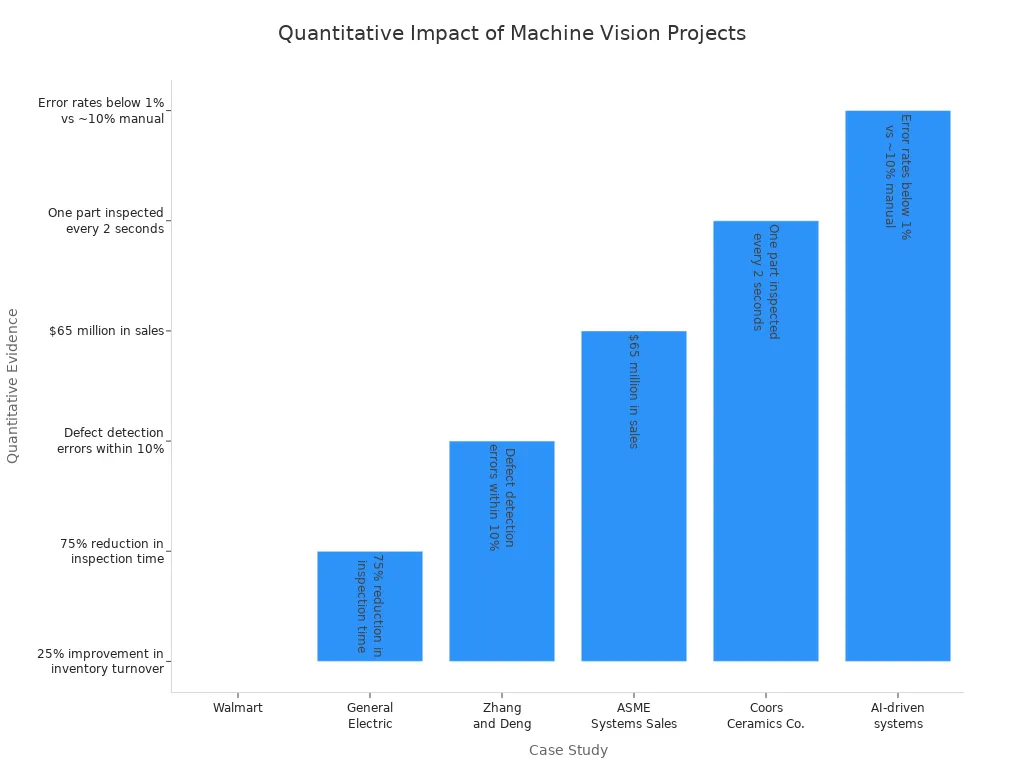
| Case Study / Metric | Sector / Context | Quantitative Evidence | Key Outcome / Impact |
|---|---|---|---|
| Walmart | Retail | 25% improvement in inventory turnover | Increased operational efficiency |
| General Electric | Industrial Inspection | 75% reduction in inspection time | Faster quality control |
| Crowe and Delwiche | Food & Agriculture | Improved sorting accuracy | More consistent results than manual methods |
| AI-driven systems | Machine Vision Accuracy | Error rates below 1% vs ~10% manual | Significantly improved reliability |
Teams that use continuous model retraining, real-time monitoring, and automated experiment tracking see lower error rates and higher system reliability. Synthetic data helps improve detection and recognition, especially when real-world image data is limited. These strategies turn static systems into evolving solutions that support business growth and real-time object detection.
Feature extraction drives the progress of machine vision systems in 2025. Modern approaches use feature maps, CNNs, and real-time optimization to boost accuracy and efficiency. Both traditional and deep learning methods help systems handle complex image data and support real-time decisions in machine learning applications.
Organizations can improve results by:
- Choosing compatible software and hardware for real-time processing.
- Applying pre-processing to enhance image quality.
- Testing performance on target platforms.
Emerging trends include vision transformers, multimodal AI, and edge devices, which will shape the future of real-time machine vision.
FAQ
What is the main goal of feature extraction in machine vision?
Feature extraction helps computers find important details in images or videos. These details make it easier for machines to recognize objects, patterns, or actions. Good feature extraction improves speed and accuracy in many computer vision tasks.
How do deep learning models improve feature extraction?
Deep learning models, like CNNs, learn to find patterns in images by themselves. They do not need people to design features by hand. This makes them better at handling complex images and new situations.
Can traditional and deep learning methods work together?
Yes! Hybrid systems use both traditional and deep learning methods. They combine the strengths of each approach. This often leads to better results in tasks like object detection and image classification.
Why does real-time processing matter in feature extraction?
Real-time processing lets systems analyze images or videos as they happen. This is important for safety, security, and fast decision-making. For example, self-driving cars and security cameras need quick and accurate feature extraction.
See Also
The Role Of Feature Extraction In Machine Vision
Advancements In Segmentation For Machine Vision In 2025
Understanding Field Of View In Vision Systems 2025








