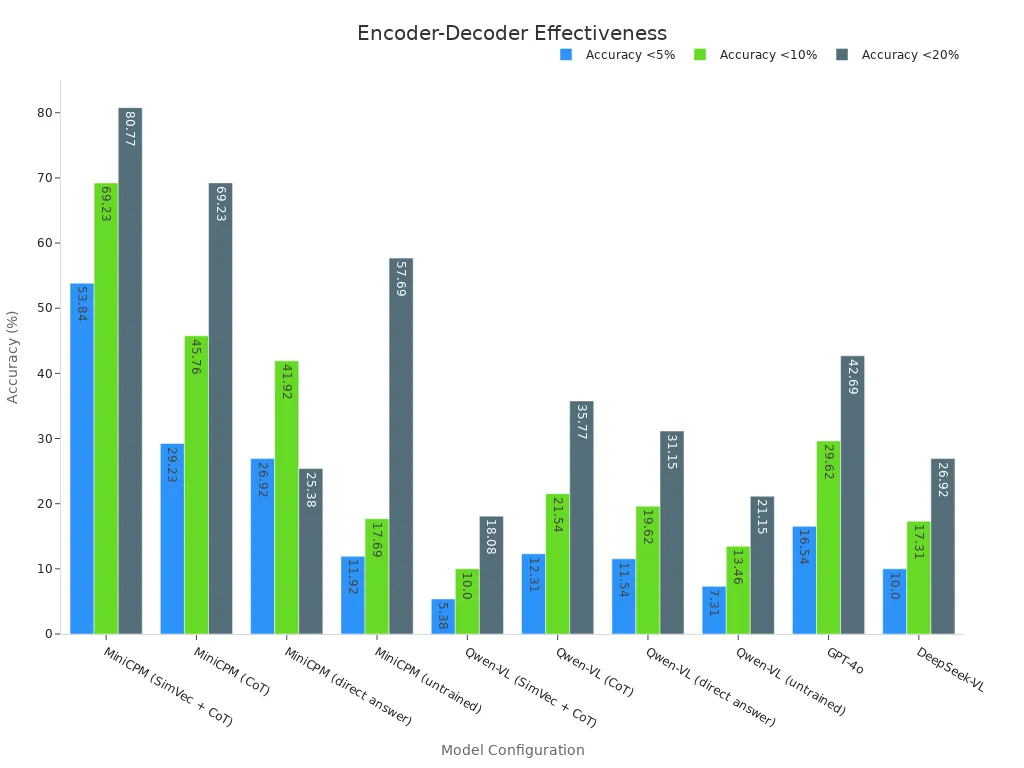
Encoder-decoder models have changed how computers see and understand the world. Recent studies show that these models, when used in a (Encoder-Decoder Model) machine vision system, help machines extract and compress important details from an image. They then reconstruct the image using advanced machine learning techniques. This process improves accuracy and performance, even with less data. The numbers below show how different models perform in extracting and reconstructing visual information:
| Model Configuration | Accuracy <5% | Accuracy <10% | Accuracy <20% |
|---|---|---|---|
| MiniCPM (SimVec + CoT) | 53.84% | 69.23% | 80.77% |
| MiniCPM (CoT) | 29.23% | 45.76% | 69.23% |
| MiniCPM (direct answer) | 26.92% | 41.92% | 25.38% |
| MiniCPM (untrained) | 11.92% | 17.69% | 57.69% |
| Qwen-VL (SimVec + CoT) | 5.38% | 10.00% | 18.08% |
| Qwen-VL (CoT) | 12.31% | 21.54% | 35.77% |
| Qwen-VL (direct answer) | 11.54% | 19.62% | 31.15% |
| Qwen-VL (untrained) | 7.31% | 13.46% | 21.15% |
| GPT-4o | 16.54% | 29.62% | 42.69% |
| DeepSeek-VL | 10.00% | 17.31% | 26.92% |
People use encoder-decoder models in many machine learning tools that power things like photo editing and self-driving cars.
Key Takeaways
- Encoder-decoder models help computers understand and recreate images by compressing important details and then rebuilding the image accurately.
- These models improve machine vision tasks like image captioning, object detection, and autonomous driving by extracting key features and reducing noise.
- The encoder compresses images into a compact form, the latent space stores essential information, and the decoder reconstructs the image with fine details.
- Using skip connections and attention mechanisms boosts accuracy, especially in tasks like image segmentation and multimodal systems combining images and text.
- Encoder-decoder models offer faster training, better performance, and can handle multiple tasks, making them vital for modern and future machine vision applications.
Encoder-Decoder Model Machine Vision System
What Is an Encoder-Decoder Model?
An encoder-decoder model forms the backbone of many modern machine vision systems. These models belong to a group called sequence-to-sequence models. They process input data, such as images or text, and convert it into a different format or sequence. The encoder takes the input and compresses it into a compact form called a context vector. This vector holds the most important information from the input. The decoder then uses this vector to generate the output, which could be a translated sentence, a caption, or a reconstructed image.
Researchers have designed encoder-decoder models with three main parts: the encoder, the context vector, and the decoder. The encoder uses self-attention to understand relationships within the input. The context vector summarizes the input. The decoder creates the output step by step, using information from the context vector. Sequence-to-sequence models like these work well for tasks such as machine translation, image captioning, and summarization. They can handle inputs and outputs of different lengths, which makes them flexible for many machine learning applications.
Why Use Encoder-Decoder Models in Vision?
Encoder-decoder models offer several advantages for machine vision. They excel at feature extraction, which means they can find and use the most important parts of an image. This ability helps them perform well on tasks like machine translation, where the input and output may differ in length and structure. In a (encoder-decoder model) machine vision system, these models can compress high-dimensional image data into a powerful latent representation. This process reduces noise and improves generalization.
Empirical studies show that encoder-decoder models outperform decoder-only models in vision-language tasks. The table below compares their accuracy and efficiency:
| Metric | Encoder-Decoder Model | Decoder-Only Model | Improvement (%) |
|---|---|---|---|
| VQAv2 (Visual Reasoning) | +11.21% accuracy | Baseline | Encoder-decoder superior |
| TextVQA (Cross-modal) | +8.17% accuracy | Baseline | Encoder-decoder superior |
| ChartQA (Structured Visual Analysis) | +7.28% accuracy | Baseline | Encoder-decoder superior |
| First Token Latency (GPU) | 86 ms | 149 ms | 42% reduction |
| First Token Latency (CPU) | 1591 ms | 2242 ms | 29% reduction |
| First Token Latency (NPU) | 189 ms | 358 ms | 47% reduction |
| Throughput (GPU) | 37.4 tokens/sec | 9.7 tokens/sec | 3.9× increase |
| Throughput (CPU) | 15.3 tokens/sec | 4.0 tokens/sec | 3.8× increase |
| Throughput (NPU) | 123.8 tokens/sec | 26.5 tokens/sec | 4.7× increase |
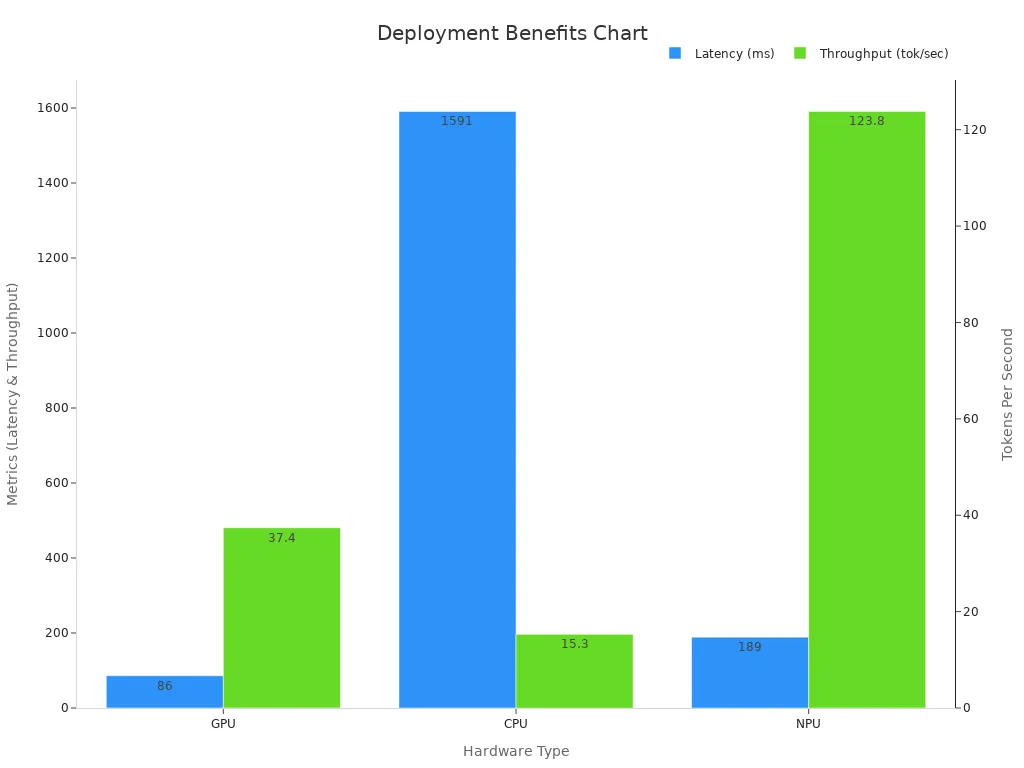
A (encoder-decoder model) machine vision system also benefits from faster training and inference. These models process the input only once, which saves time and resources. They support modern advances in machine learning, such as Vision Transformers. Studies show that loading all pre-trained encoder-decoder weights during fine-tuning leads to better results and faster convergence. This approach achieves the same performance with fewer training steps, making it ideal for real-world machine vision tasks like machine translation and image captioning.
Note: Encoder-decoder models can handle multiple tasks at once, such as classification and segmentation, much like the human visual system. This multi-task ability makes them a strong choice for building advanced vision systems.
Architecture Overview
Encoder
The encoder stands as the first stage in encoder-decoder models. It takes the raw image and transforms it into a set of meaningful features. In many systems, the encoder uses a convolutional neural network. This network scans the image with small filters, capturing patterns like edges, shapes, and textures. Each layer in the encoder extracts more complex features, moving from simple lines to detailed objects. Transformers also serve as encoders in some models. They use self-attention to find relationships between different parts of the image, which helps the model understand the whole scene.
Researchers have tested different encoder types, such as recurrent neural networks and transformers. Transformers often show better or equal performance compared to recurrent models. The encoder can even use advanced hardware, like silicon photonics, to compress images at high speed and low power. For example, a silicon photonics-based encoder processes images using optical signals, reducing energy use by 100 times compared to GPUs. This approach keeps the image structure intact and works well for large images.
| Aspect | Evidence Summary |
|---|---|
| Device Architecture | The encoder is a silicon photonics-based all-optical device with N single-mode input waveguides encoding (sqrt{N} times sqrt{N}) pixel blocks, a multimode waveguide, a random scattering layer, and M photodetectors (M < N) performing local random transforms for image compression. |
| Operational Principle | Encoding is modeled as a linear transmission matrix multiplication (O = TI), compressing image blocks optically at high speed and low power, with reconstruction done electronically. |
| Simulation Studies | Numerical simulations used standard image datasets (DIV2K, Flickr2K) and synthetic transmission matrices to evaluate compression and reconstruction quality, demonstrating the impact of kernel size on performance. |
| Experimental Validation | A prototype with 16 inputs (4×4 pixel blocks) was experimentally characterized, confirming compression quality comparable to JPEG and denoising comparable to neural networks, and robustness to fabrication imperfections after calibration. |
| Performance Metrics | The encoder can process 1 Terapixel/s at ~16 GHz with 100x less energy per multiply-accumulate operation than GPUs, enabling high-throughput, low-power image compression. |
| Encoder Role in Hybrid System | Functions as the first compression layer in a hybrid optoelectronic auto-encoder, performing local random transforms optically, while digital electronics handle reconstruction and further processing. |
| Theoretical Basis | The random encoding approach is grounded in compressive sensing theory, supporting dimensionality reduction and efficient compression after image formation. |
| Advantages of Local Kernel Size | Local transforms preserve spatial structure, reduce noise spread, allow scalable compression for large images, and avoid low-contrast speckle issues. |
| Potential Extensions | Approach applicable to RGB, hyperspectral, or time-series data and other image processing tasks like inference or classification. |
The encoder’s design affects how well the model learns. Increasing the number of encoder blocks helps the model learn complex patterns but also makes training slower. Dropout rates in the encoder, set between 0.1 and 0.2, improve performance by preventing overfitting. Smaller patch sizes, like 16×16 pixels, make the encoder more effective and reduce training time. Efficient encoders help encoder-decoder models converge faster and use less memory.
Latent Space
After the encoder processes the image, it creates a compressed version called the latent space. This space holds the most important features in a compact form. The latent space acts as a bridge between the encoder and the decoder. It reduces the size of the data, making it easier for the model to work with images.
Variational autoencoders use the latent space to turn images into short vectors. These vectors keep the main details but lose some fine features, especially small or high-frequency details. The size of the latent space matters. A smaller latent space forces the model to focus on the most important features, but it can also make it harder to reconstruct the original image perfectly. Researchers use special loss functions to make sure the latent space captures useful information. For example, some models use Kullback-Leibler divergence to keep the latent space organized and meaningful.
- VSC models activate only a few latent dimensions, making it easier to see which features control certain visual aspects.
- Fewer active dimensions help with classification and make the model more robust.
- The model aligns active latent dimensions within the same class, capturing both shared and unique features.
- Loss functions based on distance measures keep the latent space consistent for each class.
- This balance improves both global understanding and class-specific details.
Some studies use Shapley values to rank which parts of the latent space matter most for reconstruction. This ranking lets the model ignore less important parts, saving space and keeping the most useful features. The latent space in encoder-decoder models helps balance detail and efficiency.
Decoder
The decoder takes the compressed data from the latent space and rebuilds the image. It works in the opposite way of the encoder. The decoder uses layers like transpose convolutional layers to turn the short vector back into a full image. Each layer adds more detail, trying to match the original image as closely as possible.
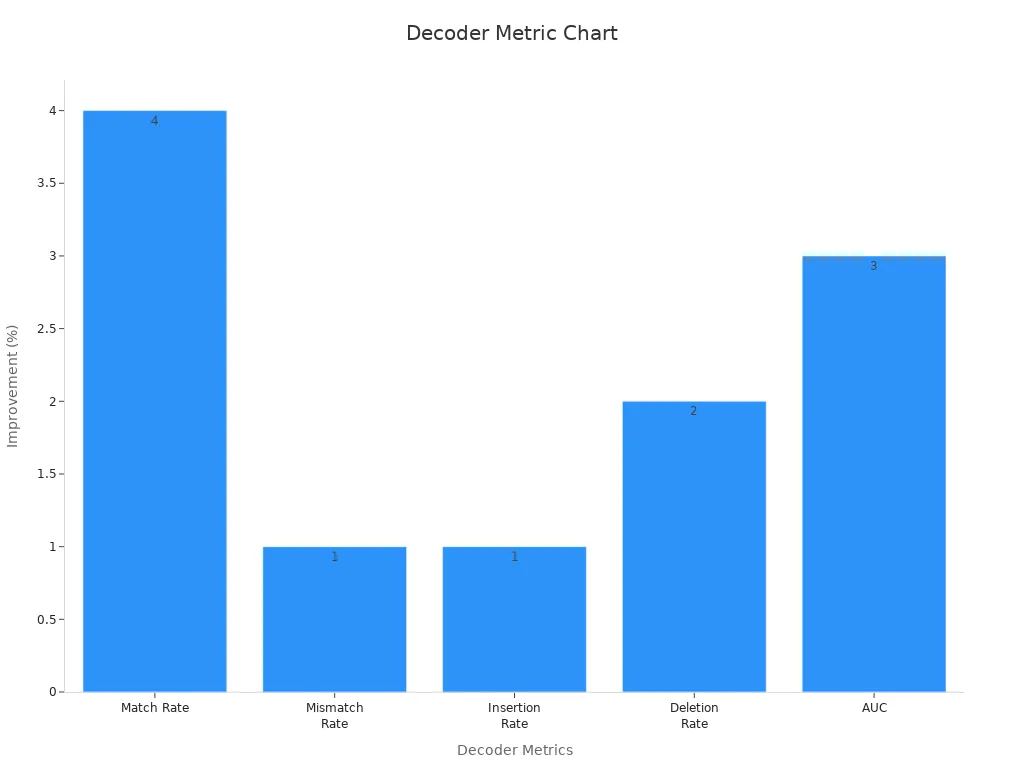
Researchers have tested different decoder types. For example, using a Conditional Random Field (CRF) decoder instead of a Connectionist Temporal Classification (CTC) decoder improves match rates by about 4%. The CRF decoder also lowers mismatch, insertion, and deletion rates. Complex convolutional decoders, such as those in Causalcall or URNano, often perform better than simple ones. However, simple convolutional decoders can still compete in some tasks.
| Architectural Component | Metric/Benchmark | Key Findings |
|---|---|---|
| Decoder Type (CRF vs CTC) | Match Rate | CRF decoder improves match rate by ~4% compared to CTC decoder |
| Mismatch, Insertion, Deletion | CRF decoder reduces mismatch (~1%), insertion (~1%), and deletion (~2%) rates | |
| AUC | Average improvement of 3% with CRF decoder | |
| Convolutional Complexity | Model Ranking | Complex convolutions (e.g., Causalcall, URNano) rank higher than simpler ones |
| Robustness | Complex convolutions generally yield better performance but simple convolutions remain competitive | |
| Encoder Type (RNN vs Transformer) | Performance Impact | Transformer encoders show competitive or improved performance over RNN encoders |
| Overall Model Evaluation | Number of Models Tested | 90 different architectures evaluated |
| Performance Limits | Improvements over top models like Bonito are small (<1% in some metrics), indicating nearing data limits |
The decoder’s job is to minimize the difference between the original and reconstructed images. Researchers use loss functions like mean squared error to measure this difference. Some decoders use a residual module and attention layers to improve image quality, especially at high compression rates. These additions help the decoder recover more details and keep important features. In human studies, neural decoders trained with perceptual loss produce images that people judge as closest to the original. This shows that the decoder plays a key role in making encoder-decoder models effective for machine vision.
The DETR model, which uses an encoder-decoder architecture, matches the performance of Faster R-CNN on the COCO dataset. DETR works especially well for large objects because its transformer-based encoder and decoder use global self-attention. This design helps the model process the whole image at once. DETR also supports tasks like panoptic segmentation, showing the flexibility of encoder-decoder models.
- Increasing the number of encoder and decoder blocks helps the model learn complex features but increases training time.
- Dropout rates of 0.1 or 0.2 in attention and convolutional layers improve performance.
- Smaller patch sizes in the encoder and decoder make training faster and more effective.
- Efficient autoencoder architectures balance speed, memory use, and reconstruction quality.
- Regularization methods like L1/L2 penalties and dropout help the model generalize better.
- Loss functions such as mean squared error and binary cross-entropy measure how well the decoder reconstructs the image.
Encoder-decoder models use these design choices to achieve high accuracy and efficiency in machine vision. The encoder compresses the image, the latent space stores the key features, and the decoder rebuilds the image with as much detail as possible.
Data Flow
Input to Latent Space
Encoder-decoder models start by taking an image as input. The encoder processes this image and turns it into a set of numbers called a latent vector. This step reduces the size of the data while keeping the most important information. In many systems, the encoder uses neural networks to map the image from its original form into a compressed space. For example, in a variational autoencoder, the encoder creates a distribution with a mean and variance for each input image. The model then samples from this distribution to get the latent vector.
Researchers often use flow diagrams to show how the encoder transforms the image into the latent space. These diagrams help explain how the encoder learns to keep useful features and remove extra details. During training, the model uses a special loss function that combines two goals: making the reconstructed image look like the original and keeping the latent space organized. The model updates its weights using gradient descent, which helps it learn the best way to compress the image.
The encoder’s job is to find a balance between keeping enough detail for accurate reconstruction and making the latent space small enough for efficient processing.
Output Generation
After the encoder creates the latent vector, the decoder takes over. The decoder uses this vector to rebuild the image. It starts with the compressed data and adds layers of detail step by step. In many models, the decoder uses transposed convolutional layers and batch normalization to turn the latent vector back into an image.
Some systems add extra parts, like a privacy discriminator, to make sure the output image does not reveal sensitive information. The decoder receives feedback from both the reconstruction loss and the privacy loss. This feedback helps the model improve the quality of the output image while protecting privacy.
The entire process, from input image to latent space and back to output image, happens many times during training. Each cycle helps the model get better at compressing and reconstructing images. The data flow in encoder-decoder models shows how these systems can handle complex tasks in machine vision.
Encoder-Decoder Models in Vision Tasks
Autoencoders
Autoencoders use encoder-decoder models to learn how to compress and rebuild images. The encoder turns an image into a smaller set of numbers, and the decoder tries to recreate the original image from this compressed data. Researchers have found that autoencoders can capture important features in visual data. For example, experiments show a strong link between how well an autoencoder reconstructs an image and how memorable that image is. When autoencoders use all their learned features, they reach classification accuracy close to the original model, around 65% to 68%. If all features are removed, accuracy drops to almost zero. This shows that certain features in the model are critical for recognizing what is in an image. Even when some data is missing, autoencoders can still restore images by using special strategies that guess the missing parts. This makes them useful for many image processing tasks.
| SAE Latents Used | Classification Accuracy (%) |
|---|---|
| All | 64.82 – 68.25 |
| None (Masked) | 0.1 |
| Top Activating | Varies (drops with fewer) |
Image Segmentation
Encoder-decoder models play a key role in image segmentation, where the goal is to separate different parts of an image. In medical imaging, researchers tested 25 different encoder-decoder combinations for segmenting organs in MRI scans. The best results came from using a ResNet50 encoder with a DeepLab V3+ decoder, reaching a Dice score of 0.9082. This high score means the model can accurately outline organs. Skip connections, which link the encoder and decoder, help keep fine details. When these connections are removed, the model loses accuracy and makes more mistakes. Encoder-decoder models with skip connections work well for precise tasks in both science and medicine.
Multimodal Systems
Multimodal systems use encoder-decoder models to handle information from different sources, such as images and text. Researchers use these models in machine learning to improve tasks like translating captions or answering questions about pictures. Studies show that the decoder can help fill in gaps if the encoder misses some details. However, the benefits depend on how well the model aligns the visual and language parts. If the image and text do not match, the model’s performance drops. Metrics like BLEU and METEOR help measure how well these systems work. Multimodal encoder-decoder models can solve problems where understanding both pictures and words is important, but they need careful design to avoid mistakes.
Tip: Multimodal encoder-decoder models can help computers understand complex scenes by combining vision and language, but they work best when both types of data are well-matched.
Real-World Applications

Image Captioning
Encoder-decoder models have transformed image captioning by helping computers describe what they see. These models use an encoder to extract features from an image and a decoder to generate a sentence that matches the visual content. Researchers have tested many approaches to improve accuracy. For example, attention-based encoder-decoder models help the decoder focus on important parts of the image during caption generation. The table below highlights key studies and datasets that advanced image captioning:
| Study / Dataset | Description | Contribution to Encoder-Decoder Image Captioning |
|---|---|---|
| Kyunghyun Cho et al. (2015) | Introduced attention-based encoder-decoder networks | Improved focus on image regions, boosting caption accuracy |
| Jyoti Aneja et al. (2018) | Used convolutional networks for captioning | Outperformed traditional RNNs/LSTMs |
| Rémi Lebret et al. (2015) | Developed phrase-based models | Linked vision and language for better captions |
| COCO Dataset (2014) | Benchmark dataset | Standardized model evaluation |
| ImageNet (2009) | Large image dataset | Provided pretrained encoders |
| Bristol-Myers Squibb Dataset | Molecular images with labels | Enabled domain-specific captioning |
Researchers found that using more attention units and larger decoder dimensions improved model performance. The best models achieved low Levenshtein distances, showing they could generate accurate and coherent captions. Encoder-decoder models also reduced errors like repeated phrases, making image captioning more reliable in real-world tasks.
Object Detection
Encoder-decoder models play a major role in object detection. These models help computers find and label objects in images. Researchers use metrics like Intersection over Union (IoU) to measure how well the predicted boxes match the real objects. IoU values above 0.5 show good detection. Transformer-based encoder-decoder models, such as LR-DETR, have set new standards for accuracy and speed. LR-DETR outperformed older models like SSD and DETR, especially in tough conditions like occlusion or glare. DecoderTracker, a decoder-only model, doubled the speed of traditional encoder-decoder models while keeping high accuracy. These advances show that encoder-decoder models can handle complex scenes and deliver fast, precise results.
Autonomous Vehicles
Autonomous vehicles rely on encoder-decoder models to understand their surroundings. These models process camera and sensor data to detect objects, segment drivable areas, and identify lane lines. Multi-task encoder-decoder models use a shared encoder and several decoders to handle different tasks at once. Studies using the BD100K dataset showed that sharing features across tasks improved both speed and accuracy. New models like UF-Net and SC3D combined CNNs and transformers to boost detection and segmentation in real-world driving. On datasets like KITTI and NuScenes, these models reached high mean Average Precision scores, proving their value for safe and efficient autonomous driving.
Encoder-decoder models help machines see, describe, and act in the world, powering many modern vision systems.
Encoder-decoder models drive progress in machine vision. They help machines see, understand, and describe images. Knowing how these models work gives people a deeper appreciation for their impact.
- Future systems may use even smarter encoders and decoders.
- Researchers expect new models to handle more complex tasks and learn faster.
Curious minds can explore these models to see how they shape tomorrow’s technology.
FAQ
What is the main job of an encoder-decoder model in machine vision?
An encoder-decoder model helps a computer understand and recreate images. The encoder finds important features in the image. The decoder uses these features to rebuild or describe the image.
How do encoder-decoder models handle different types of images?
These models work with many image types, such as photos, medical scans, or drawings. The encoder learns to find patterns in each kind of image. The decoder then uses these patterns to create useful outputs.
Why do some models use skip connections?
Skip connections help the decoder keep important details from the original image. They send information directly from the encoder to the decoder. This makes the output more accurate, especially for tasks like image segmentation.
Can encoder-decoder models work with both images and text?
Yes! Multimodal encoder-decoder models can process images and text together. For example, they can look at a picture and write a caption. These models help computers understand and connect different types of information.
See Also
The Impact Of Deep Learning On Machine Vision
Neural Network Frameworks Transforming Modern Machine Vision
Understanding Computer Vision Models In Machine Systems








