
A decoder machine vision system uses advanced image processing and language algorithms to interpret visual data and automate decision-making in industrial environments. This system relies on two key parts: a vision encoder that captures and processes images, and a decoder that translates visual information into actionable language or commands. Modern manufacturing depends on these systems for efficiency and accuracy. Many automotive factories use a decoder machine vision system to read barcodes and labels, ensuring every part receives correct identification.
The adoption of decoder machine vision systems continues to rise, especially in automotive manufacturing and pattern recognition.
Aspect Statistic / Trend Explanation Automotive Manufacturing Market Share (2025) 48.75% Dominates industrial machine vision adoption due to automation and quality control needs in production lines. Pattern Recognition Application Share (2025) 50.62% Leading application segment, critical for defect detection and quality control, enhanced by AI and deep learning. AI and 3D Vision Integration Increasing trend Enhances real-time decision-making, defect detection, and volumetric analysis, boosting adoption.
Key Takeaways
- Decoder machine vision systems turn images into useful information, helping factories automate tasks and improve quality.
- The system has two main parts: a vision encoder that captures images and a decoder that interprets them into actions or reports.
- These systems boost efficiency by increasing accuracy, speeding up inspections, and reducing labor costs in industries like automotive and manufacturing.
- A clear workflow—from image capture to decoding and post-processing—ensures fast and reliable results for tasks like barcode reading and defect detection.
- Using advanced models and good data setup helps these systems handle complex visual and language tasks, making them adaptable and powerful for modern factories.
Decoder Machine Vision System Components
Vision Encoder
The vision encoder acts as the system’s eyes. It captures images or video streams from the environment and converts them into digital data. Industrial applications demand high resolution, speed, and reliability from these encoders. For example, programmable encoders can reach up to 65,536 counts per revolution, allowing precise control over image capture. In robotics, encoders achieve 18-bit resolution, which means 262,144 positions per revolution. This level of detail ensures that every movement or object gets recorded accurately.
| Industry | Performance Indicators | Example Metrics and Features |
|---|---|---|
| Industrial Robotics | High resolution, fast data transmission, precise positioning | 18-bit resolution (262,144 positions/rev), interpolation up to 16,384-fold, data rates up to 8 MHz |
| Spaceflight | Extreme precision in angular measurement, robustness in harsh environments | Scale lines up to 247,800, accuracy down to 0.03 arc seconds, baseline error <0.175 µm over 5 mm |
| Medical | Precise linear and rotary positioning for patient and device movement | Absolute linear encoders for patient positioning, rotary encoders for treatment apparatus drives |
| Optical/Semiconductor | High interpolation and line counts for lens grinding and semiconductor production | 24,000 lines on encoder, 16,384-fold interpolation, pulsation-free torque motors |
| Machine Tool Building | Micron-level accuracy for multi-axis movement and high acceleration | Positioning accuracy ±3 µm, acceleration up to 3 g, large linear scales with micron accuracy |
Vision encoders also support the vision encoder decoder model by providing the foundational data needed for further processing. In recent studies, modular camera portals have captured over 17,000 labeled images for machine vision tasks, enabling accurate classification and defect detection. These encoders ensure that the system receives clear, high-quality input for downstream analysis.
Vision Decoder
The vision decoder interprets the encoded data and transforms it into meaningful outputs. This component often uses artificial neural networks (ANNs) to reconstruct images or classify objects based on compressed data. For instance, decoder ANNs can rebuild images from just 10 spectral class scores, recreating visuals with over 780 pixels. This process demonstrates the efficiency and power of the vision encoder decoder model.
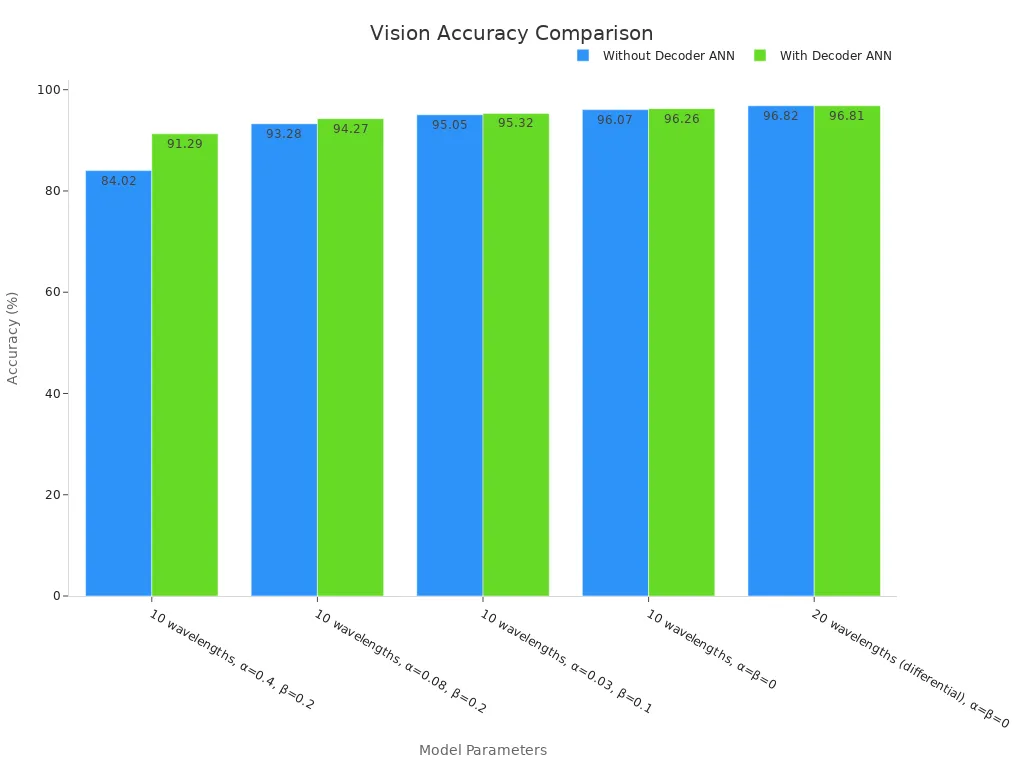
Quantitative results highlight the decoder’s impact on system accuracy. When paired with diffractive optical networks, decoder ANNs can boost classification accuracy by up to 7.27%. For example, accuracy can rise from 84.02% to 91.29% with the addition of a decoder ANN. Even shallow decoder architectures deliver strong results, with deeper networks offering only minor improvements.
| Diffractive Network Model Parameters | Diffractive Power Efficiency at Output Detector (%) | Blind Testing Accuracy Without Decoder ANN (%) | Blind Testing Accuracy With Decoder ANN (%) |
|---|---|---|---|
| 10 wavelengths, α=0.4, β=0.2 | 0.966 ± 0.465 | 84.02 | 91.29 |
| 10 wavelengths, α=0.08, β=0.2 | 0.125 ± 0.065 | 93.28 | 94.27 |
| 10 wavelengths, α=0.03, β=0.1 | 0.048 ± 0.027 | 95.05 | 95.32 |
| 10 wavelengths, α=β=0 | 0.006 ± 0.004 | 96.07 | 96.26 |
| 20 wavelengths (differential), α=β=0 | 0.004 ± 0.002 | 96.82 | 96.81 |
The decoder’s role extends beyond classification. It enables the system to make decisions, trigger actions, or communicate results to other machines. This capability is essential for automated inspection, barcode reading, and quality control in manufacturing.
System Integration
System integration brings together the vision encoder and decoder, creating a seamless workflow. This integration ensures that data flows smoothly from image capture to actionable output. Companies have reported significant improvements after integrating these components. For example, vision-guided robots can handle up to 10,000 parts per hour, and AI-powered barcode reading achieves up to 30% higher accuracy than traditional scanners.
| Metric / Case Study | Description / Value |
|---|---|
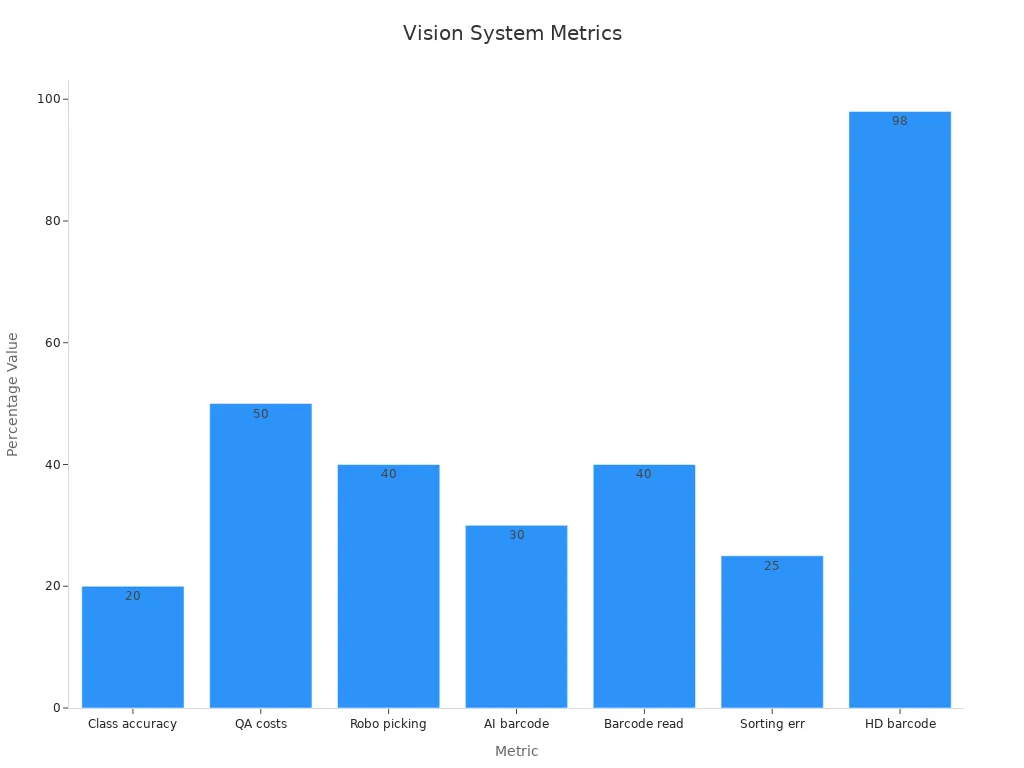
| Increase in classification accuracy | 20% improvement over traditional algorithms |
| Parts handled per hour by vision-guided robots | Up to 10,000 parts per hour |
| Reduction in quality assurance labor costs | Approximately 50% reduction |
| Improvement in robotic part-picking efficiency | Over 40% increase |
| AI-powered barcode reading accuracy | Up to 30% higher accuracy than traditional scanners |
| Barcode readability improvement | 40% increase |
| Sorting error reduction | 25% fewer errors |
| High-density barcode reading accuracy | 98% accuracy rate |
| Real-world company examples | Siemens: IoT sensors + barcode scanning for real-time equipment monitoring reducing downtime Tyson Foods: Barcode + IoT for enhanced traceability and food safety Toyota: 25% production speed increase using AI barcode scanners Walmart: 25%+ scanning efficiency improvement at self-checkouts Amazon: 30% reduction in inventory scanning time Pfizer: Compliance ensured with low-quality barcodes |
| Environmental solutions | Use of glare-resistant cameras and specialized lighting to improve reliability in challenging conditions |
System integration also supports resource efficiency. Studies show that quantization techniques in deep learning models maintain accuracy while reducing storage size and energy consumption. This balance between performance and efficiency makes the vision encoder decoder model a preferred choice for modern industrial automation.
Tip: Successful system integration not only improves accuracy and speed but also reduces labor costs and errors, making it a smart investment for manufacturers.
How Decoder Machine Vision Systems Work
Workflow Steps
Decoder machine vision systems follow a structured workflow to process and interpret visual data. Each step in the workflow plays a critical role in ensuring accurate and efficient operation. The process begins with image acquisition, where cameras or sensors capture raw visual input. Next, the system preprocesses the data, resizing and normalizing images to prepare them for analysis. The vision encoder then converts these images into digital representations, which the decoder interprets to produce actionable results.
A typical workflow includes the following steps:
- Image acquisition: Cameras or sensors capture visual data from the environment.
- Preprocessing: The system resizes, normalizes, and formats input data for consistency.
- Feature extraction: The vision encoder identifies key features within the images.
- Decoding: The decoder translates encoded data into meaningful outputs, such as object classifications or commands.
- Post-processing: The system refines results, drawing bounding boxes or generating text-image retrieval outputs for further action.
Process flow analysis helps organizations monitor and improve each workflow step. Teams examine time taken, resources used, and any inconsistencies that arise. They identify bottlenecks and inefficiencies that slow down the process. Metrics and key performance indicators (KPIs) provide benchmarks for workflow improvements.
| Workflow Step | Description of Efficiency Metric |
|---|---|
| Preprocessing Time | Time spent resizing, normalizing, and formatting input data. |
| Computation Time | Duration of model inference including layer-wise computations. |
| Post-processing Time | Time to convert raw outputs into actionable results (e.g., bounding boxes). |
These time-based statistics reflect how efficiently each step processes visual data, directly impacting overall system performance. In many industrial settings, teams use these metrics to optimize vision systems for multimodal tasks, such as text-image retrieval and barcode decoding. By streamlining each step, companies achieve faster throughput and higher accuracy.
Note: Regular workflow analysis ensures that decoder machine vision systems remain efficient and reliable, especially when handling large-scale multimodal data.
Encoder Feedback and Image Capture
Precise encoder feedback is essential for synchronized image capture in decoder machine vision systems. High-precision optical encoders, such as the Baumer EFL580, deliver accurate position feedback with resolutions up to 21 bits. These encoders generate sine and cosine signals from a patterned disc, which photodetectors amplify and sample. The system’s motor controller queries the encoder position every PWM cycle, enabling exact timing for image capture.
This design ensures low latency and high resolution in position feedback. The encoder’s Opto-ASIC technology provides strong interference immunity, combining position feedback, signal processing, and communication in one component. As a result, the system captures images at the precise moment needed for analysis, which is critical for applications like multimodal text-image retrieval and automated inspection.
Encoder performance data shows that electronic interpolation can increase counts per revolution from 1,250 to over 5,000, allowing for finer position measurement. Accuracy measures the difference between the target and actual position, with typical optical encoders achieving about 0.18 degrees. Precision refers to the repeatability of measurements. For example, if an encoder consistently reports a -0.75° error, calibration can adjust readings to within 0.05° of the actual position. This compensation technique is common in high-accuracy vision systems.
The overall precision of the system depends on both the encoder and other mechanical components. Reliable encoder feedback ensures that the vision system captures images at the right time, supporting complex multimodal tasks and improving the accuracy of text-image retrieval. This synchronization is vital for industrial automation, where even small timing errors can lead to missed detections or incorrect classifications.
Tip: High-precision encoder feedback not only improves image capture timing but also enhances the reliability of multimodal vision applications in demanding environments.
Vision Applications in Industry

Factory Automation
Factory automation relies on decoder machine vision systems to boost efficiency and accuracy. These systems enable equipment to learn and optimize tasks on their own. Robots and production lines use vision to communicate and adapt, making it easier to manufacture different products quickly. Big data and cloud computing help turn raw manufacturing data into useful insights. This allows remote monitoring and maintenance, which reduces downtime and improves throughput.
| Metric | Statistic/Impact | Description/Effect |
|---|---|---|
| Defect Recognition Rate | > 99% | AI-driven vision systems catch almost all product defects. |
| Production Line Efficiency | Up to 20% improvement | Robotics and vision increase speed and output. |
| Sorting Time Reduction | 50% reduction | Vision accelerates sorting, saving time and money. |
Vision systems also support real-time quality checks and process verification. They help detect defects early, reducing waste and improving product quality. Robots use vision for material handling, assembly, and packaging, which lowers labor costs. Predictive maintenance becomes possible by spotting equipment wear before it causes problems.
Barcode and Watermark Decoding
Barcode and digital watermark decoding play a key role in modern manufacturing. Decoder machine vision systems read barcodes and watermarks on products and parts at high speed. Manufacturing case studies show that these systems deliver both accuracy and speed. For example, new watermarking methods do not need the original model for extraction and work well even when products face tough conditions. Improved algorithms make barcode decoding faster and more reliable, even when labels are small or damaged.
A sophisticated decoding algorithm can handle errors like insertions or deletions, ensuring that barcode identities remain accurate. The system provides a confidence score for each read, helping balance speed and accuracy. These advances in barcode and watermark decoding support traceability and compliance in industries where every part must be tracked.
Automated Inspection
Automated inspection uses decoder machine vision systems to check products for defects and ensure quality. These systems identify cracks, missing parts, or color issues in real time. They monitor tolerances, such as temperature or part position, to keep processes under control. Automated inspection also measures components to confirm they meet size and quality standards.
- Defect detection finds both cosmetic and functional flaws.
- Tolerance monitoring gives instant feedback for process control.
- Component measurement ensures every part meets specifications.
- Barcode traceability and print verification confirm correct labeling and compliance.
Automated inspection increases the speed of label reading and improves accuracy, even on fast-moving lines. The system works without fatigue, providing consistent results over time. Companies benefit from reduced waste, lower labor costs, and better return on investment. Automated inspection also supports image captioning tasks, where the system describes product features or defects for further analysis. In addition, image captioning helps document inspection results, making it easier to track quality over time. Vision systems use image captioning to generate reports and support decision-making in quality control. As a result, image captioning has become a vital part of automated inspection in many industries.
Tip: Automated inspection with image captioning ensures every product meets strict quality standards, helping companies avoid costly recalls and maintain customer trust.
Building and Training the System
Setup and Initialization
Setting up a decoder machine vision system starts with selecting the right hardware and software. Teams choose industrial cameras, lighting, and a pretrained transformer-based vision model to capture and process images. They connect the system to automation protocols, ensuring smooth data flow between machines. High-quality data is essential. Companies gather image-text pairs from production lines, including images for image captioning and text-image retrieval. Data preparation involves removing duplicates, cleansing, and formatting. Skilled personnel check the data to ensure it fits the requirements for multimodal tasks.
Key setup steps include:
- Choosing a pretrained transformer-based vision model or building a custom configuration.
- Integrating hardware like GPUs or FPGAs for fast processing.
- Connecting to internal data sources and automation systems.
- Preparing curated datasets for image captioning, text-image retrieval, and image-text retrieval tasks.
Note: High-quality, well-formatted data improves the accuracy of vision-language models and supports reliable inference.
Training and Inference
Training the system involves tuning hyperparameters such as learning rate, batch size, and optimizer type. Teams use methods like grid search, random search, or Bayesian optimization to find the best settings. Automated tools such as Optuna and Ray Tune help speed up this process. Cross-validation techniques, like K-fold validation, ensure the model does not overfit and performs well on new data. Dataset characteristics, such as class imbalance, influence tuning strategies.
- Fine-tuning a pretrained transformer-based vision model often leads to better results than training from scratch.
- Automated pruning and early stopping focus resources on the most promising configurations.
- Combining curated data, advanced algorithms, and human oversight leads to successful training and inference.
| Model | Dataset | Pretrained Accuracy | Scratch-trained Accuracy | Notes on Performance and Efficiency |
|---|---|---|---|---|
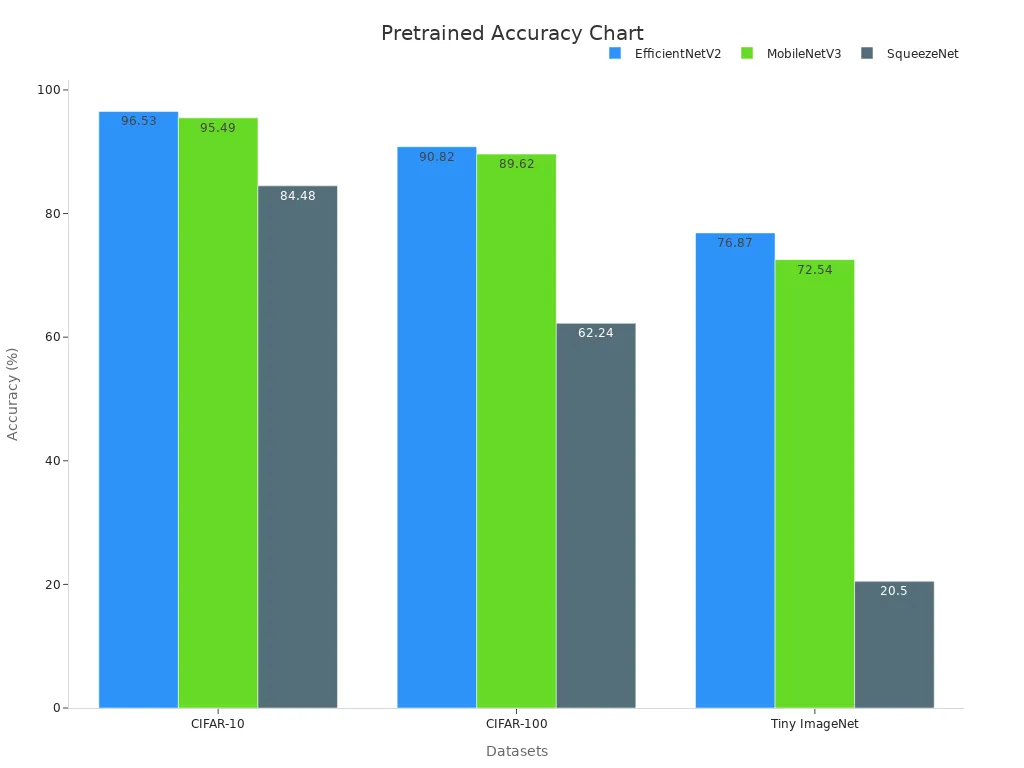
| EfficientNetV2 | CIFAR-10 | 96.53% | 92.51% | Highest accuracy, larger model size |
| MobileNetV3 | CIFAR-10 | 95.49% | N/A | Good balance of accuracy and efficiency, small size |
| SqueezeNet | CIFAR-10 | 84.48% | N/A | Very lightweight but lower accuracy |
The system uses language algorithms to generate image captioning outputs and perform text-image retrieval. Human input, such as self-assessments and manager reviews, helps validate the results. The system supports multimodal tasks, including image-to-text model applications and image-text retrieval tasks. This approach ensures the system can handle complex language and visual data, making it suitable for industrial automation.
Comparison with Other Vision Systems
Encoder-Only vs. Encoder-Decoder
Encoder-only and encoder-decoder systems differ in both architecture and performance. Encoder-only models, such as BERT and RoBERTa, use a bi-directional encoder stack. These models access all tokens in the input at once. They work well for tasks like text classification and named entity recognition. Decoder-only models, like GPT-3.5-turbo, use an autoregressive decoder stack. These models attend only to preceding tokens, making them strong at text generation and question answering.
Full encoder-decoder systems combine both stacks. This design allows the system to process input and generate output in a flexible way. In machine vision, encoder-decoder systems can handle complex tasks, such as image captioning and multimodal retrieval, that require both understanding and generation.
Researchers use the ‘mean rank score’ algorithm to compare these systems. This method normalizes performance scores and applies a one-tailed Welch’s t-test for statistical significance. Studies show that decoder models often outperform encoder-only models in natural language understanding, especially for question answering. Encoder-only models may perform better in classification tasks. The results depend on the task, language, and dataset size. For example, GPT-3.5-turbo matches or exceeds encoder-only models in zero-shot or few-shot settings, but larger encoder models can outperform decoders on some benchmarks.
| Model Type | Best For | Example Tasks | Typical Strengths |
|---|---|---|---|
| Encoder-Only | Classification | Text classification, NER | Bi-directional context, accuracy |
| Decoder-Only | Generation | Text generation, QA | Autoregressive, flexible output |
| Encoder-Decoder | Multimodal, Generation | Image captioning, translation | Versatility, complex tasks |
Note: The choice between encoder-only and encoder-decoder systems depends on the specific industrial task and data available.
Unique Benefits
Decoder machine vision systems offer several unique advantages. They can process both visual and language data, making them ideal for multimodal tasks. These systems excel at generating descriptive outputs, such as image captions or inspection reports. This ability supports traceability and quality control in manufacturing.
- Versatility: Encoder-decoder systems adapt to many tasks, from barcode reading to automated inspection.
- Accuracy: Advanced algorithms and statistical methods ensure reliable results across different datasets.
- Scalability: These systems handle large volumes of data, supporting high-speed production lines.
- Actionable Insights: The decoder translates visual data into commands or reports, enabling real-time decision-making.
Manufacturers benefit from improved efficiency and reduced errors. Decoder machine vision systems support automation, compliance, and product quality. Their flexibility and robust performance make them a preferred choice for modern industrial environments.
Tip: Companies seeking to automate complex visual tasks should consider encoder-decoder systems for their adaptability and strong performance across diverse applications.
A decoder machine vision system transforms visual data into actionable language, supporting automation across many industries. These systems use advanced language models to interpret images, generate reports, and improve traceability. Companies see higher efficiency and better quality. Studies show that tasks like pedestrian detection and image classification achieve up to 20× data compression with little or no accuracy loss. Optical innovations further boost processing speed and energy savings. Decoder machine vision systems help teams use language for real-time decisions, making them a smart choice for modern operations.
| Task | Compression Ratio | Accuracy Impact |
|---|---|---|
| Pedestrian Detection | 7.1× | No accuracy loss |
| Image Classification | Up to 8× | Minimal accuracy loss |
| Eye-Tracking | Up to 20× | Minimal accuracy loss |
Teams should explore how decoder machine vision systems and advanced language processing can improve their own workflows.
FAQ
What is the main purpose of a decoder machine vision system?
A decoder machine vision system helps machines understand images and make decisions. It turns visual data into useful information for automation, quality control, and traceability in factories.
How does a vision encoder work in these systems?
The vision encoder captures images and changes them into digital data. This data helps the system find important features, like shapes or codes, for further analysis.
Can decoder machine vision systems read damaged barcodes?
Yes, these systems use advanced algorithms to read barcodes, even if they are scratched or dirty. They provide high accuracy and help keep production lines running smoothly.
What industries use decoder machine vision systems most?
Manufacturing, automotive, food processing, and logistics companies use these systems. They help with inspection, sorting, and tracking products.
Do these systems need special training or setup?
Teams must set up cameras, lighting, and software. They often use pretrained models but can train custom models with their own data. Good setup ensures the system works well.
See Also
Understanding The Basics Of Automotive Machine Vision Systems
A Comprehensive Guide To Image Processing Vision Systems
Exploring Pattern Recognition In Machine Vision Technologies








