
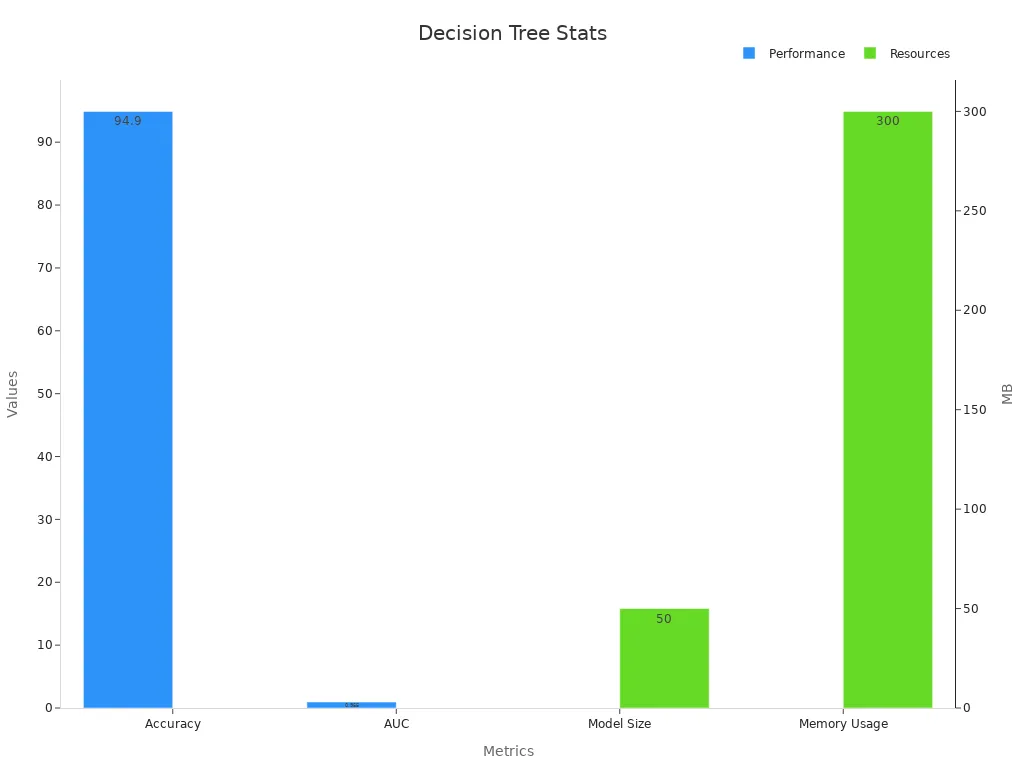
A decision tree machine vision system uses branching logic to analyze images, making it clear and interpretable for users. In 2025, decision tree learning delivers high accuracy and speed, with optimized models reaching up to 94.9% accuracy and minimal prediction latency compared to other methods.
| Metric | Optimized Decision Tree | SVM | CNN | XGBoost | LightGBM | CatBoost |
|---|---|---|---|---|---|---|
| Accuracy (%) | 94.9 | 87.0 | 92.0 | 94.6 | 94.7 | 94.5 |
| Model Size (MB) | 50 | 45 | 200 | N/A | 48 | N/A |
| Memory Usage (MB) | 300 | N/A | 800 | N/A | N/A | N/A |
Decision tree learning matters now because deeper trees can achieve flawless predictions in vision tasks, showing clear improvement over past approaches. What defines a decision tree machine vision system? How does decision tree learning work in 2025, and where does it excel or face limits?
Key Takeaways
- Decision tree machine vision systems use clear branching logic to analyze images, making their decisions easy to understand and trust.
- These systems deliver high accuracy and fast processing, making them suitable for real-time tasks in industries like manufacturing, healthcare, and autonomous vehicles.
- Recent improvements in feature extraction and training speed have boosted model performance and reduced resource use.
- Combining decision trees with deep learning and ensemble methods creates hybrid models that improve accuracy and handle complex visual data better.
- While decision trees excel with clear features and limited data, they face challenges like overfitting and difficulty with complex images, so choosing the right method depends on the task.
Decision Tree Machine Vision System Overview
What Is a Decision Tree?
A decision tree is a type of algorithm that helps computers make choices by following a series of questions and answers. Each question splits the data into smaller groups, leading to a final answer at the end of each branch. This structure looks like a tree, with branches representing decisions and leaves showing the outcomes. In machine learning, a decision tree can solve both classification and regression problems. A classification tree sorts data into categories, while a regression tree predicts numbers.
Decision tree algorithms use supervised learning, which means they learn from labeled data. The algorithm examines the data, finds patterns, and builds a model that can make predictions on new data. The classification and regression tree method, often called CART, is a popular approach. CART creates both classification trees and regression trees, making it flexible for many tasks.
A decision tree stands out because it is easy to understand. Each step in the tree shows how the model makes decisions. This transparency helps users trust the results. The model can handle different types of data, such as numbers, text, or images. Decision tree algorithms also work well with missing data, making them reliable in real-world situations.
Decision Tree Learning in Machine Vision
Decision tree learning has become a key part of modern machine vision systems. These systems use decision trees to analyze images and videos, breaking down complex visual data into simple, logical steps. The decision tree machine vision system processes each image by asking a series of questions about features like color, shape, or texture. Each answer leads the system closer to identifying objects or patterns.
Feature engineering plays a crucial role in improving machine vision tasks such as image classification. Techniques like feature scaling and extraction help highlight relevant visual attributes, such as color gradients and texture patterns, which improve model accuracy. For example, a recent study reported a decision tree algorithm achieving 99.06% accuracy in facial recognition. Another system using advanced feature engineering reached 96.4% accuracy in image classification, supported by statistical evaluations across multiple performance metrics. These results show that decision tree learning can deliver high accuracy and effectiveness in vision tasks.
A decision tree machine vision system uses several metrics to measure performance. These include accuracy, precision, recall, and F1 score. Accuracy shows how often the model makes correct predictions. Precision measures how many of the identified objects are correct. Recall checks if the model finds all the objects it should. The F1 score balances precision and recall for a complete view of performance. Other important metrics include latency, throughput, memory use, and energy efficiency. These metrics help teams assess how well a decision tree machine vision system works in real-world settings.
| Metric / Benchmarking Tool | Description | Application in Decision Tree Machine Vision Systems |
|---|---|---|
| Accuracy | Proportion of correct predictions over total predictions | Measures overall correctness of defect detection and object counting tasks |
| Precision | Ratio of true positives to all predicted positives | Evaluates reliability in identifying true defects without false alarms |
| Recall | Ratio of true positives to all actual positives | Assesses ability to detect all relevant defects or objects |
| F1 Score | Harmonic mean of precision and recall | Balances precision and recall for comprehensive performance evaluation |
| ROC Curve & AUC | Graphical and scalar measures of classification performance | Used to analyze trade-offs between true positive and false positive rates |
| Latency | Time delay in processing | Benchmarked to ensure real-time responsiveness in machine vision systems |
| Throughput | Number of processed items per unit time | Measures system efficiency in high-volume scenarios |
| Memory Use | Amount of memory consumed during operation | Important for deployment on resource-constrained hardware |
| Energy Efficiency | Power consumption during processing | Critical for sustainable and cost-effective system operation |
| Industry Benchmarks (MLPerf, DAWNBench, TensorFlow suites) | Standardized tests for performance and cost | Provide comparative numerical data to select and optimize models |
A decision tree machine vision system often combines classification and regression tree methods to handle both object detection and measurement tasks. The model can quickly adapt to new data, making it suitable for changing environments. Decision tree learning supports automation in industries like manufacturing, healthcare, and transportation. Teams use these models to improve quality control, automate inspections, and support diagnostics.
Note: Decision tree machine vision systems rely on supervised learning to build accurate models. They use both classification tree and regression tree techniques to solve a wide range of vision problems.
How It Works
Core Principles
A decision tree machine vision system processes image and video data by asking a series of hierarchical questions. The system uses branching logic to split data into smaller groups, making predictions at each step. This approach allows the model to handle both classification and regression tasks with high transparency. The decision tree structure starts with a root node that represents the entire dataset. Each internal node asks a question about a specific feature, such as color or shape. The answer determines which branch the data follows. The process continues until the data reaches a leaf node, which provides the final classification or regression result.
Decision tree algorithms follow a structured process to build effective models. The steps include:
- Feature selection uses criteria like information gain, gain ratio, or Gini index to choose the best feature at each node.
- Tree generation splits the data recursively based on selected features until reaching terminal nodes.
- Tree pruning removes branches that do not improve classification accuracy, reducing overfitting.
- Hierarchical structures combine decision trees with other classifiers, such as one-class SVMs, to create multi-level models.
- Ensemble methods, including random forest and boosting, aggregate multiple decision trees trained on different data or feature subsets.
- In some systems, datasets are split into disjoint subsets, and separate models are trained on each subset, forming a layered approach.
- These steps create a robust decision tree system that can process complex visual data efficiently.
The decision tree model excels in interpretability. Each decision path shows how the system arrives at its predictions. This clarity helps users understand and trust the results. The model can handle missing data and adapt to new information quickly. Decision tree machine vision systems often use both classification and regression tree methods to solve a wide range of vision problems.
Advancements in 2025
Recent advancements in decision tree machine vision systems have improved feature extraction and training speed. Engineers have optimized data preparation and feature engineering, leading to better model performance. Enhanced algorithms now extract features such as color gradients and texture patterns more efficiently. These improvements allow the model to make faster and more accurate predictions.
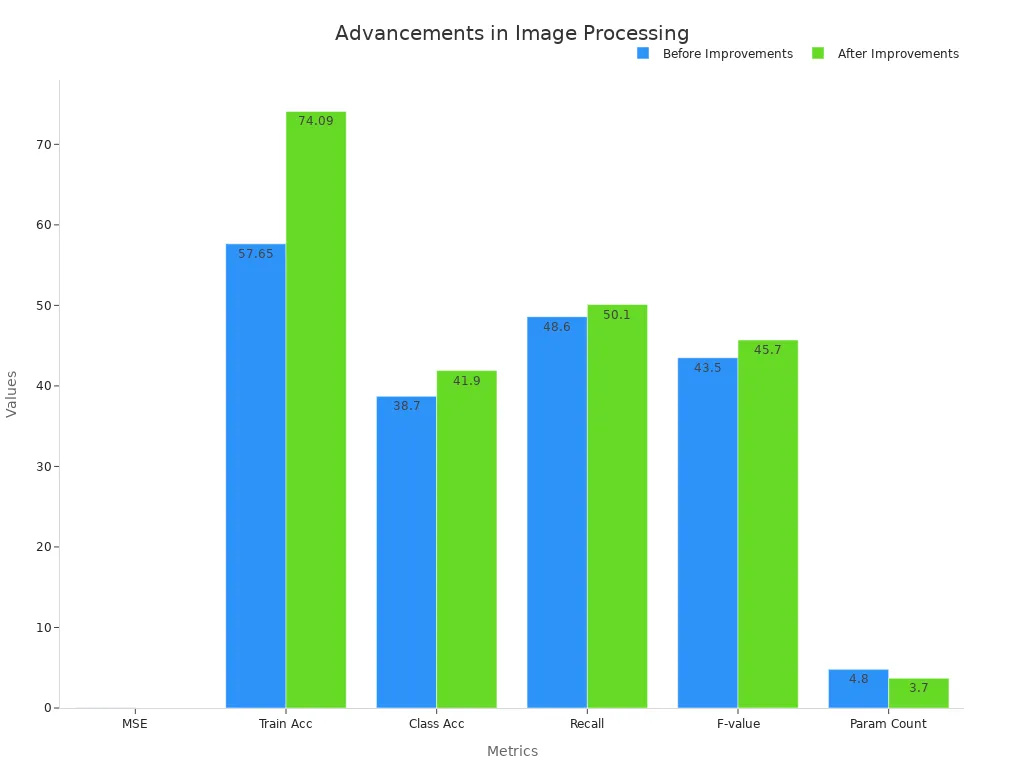
The following table highlights key metrics before and after recent improvements:
| Metric Description | Before Improvement | After Improvement | Improvement Detail |
|---|---|---|---|
| Mean Square Error (MSE) | 0.02 | 0.005 | Better image quality and feature extraction efficiency |
| Training Accuracy (batch size increase 16→72) | 57.65% | 74.09% | Faster and more effective training |
| Classification Accuracy (vs. baseline) | 38.7% | 41.9% | Accuracy uplift due to improved feature extraction |
| Recall | 48.6% | 50.1% | Better model performance |
| F-value | 43.5% | 45.7% | Balanced precision and recall improvements |
| Parameter Count | 4.8 million | 3.7 million | 23% reduction, speeding training |
| Average Classification Accuracy (post-optimization) | N/A | +5% | Overall accuracy improvement |
| Training Time and Calculation Speed | N/A | Faster | Reduced time consumption |
These advancements have made decision tree machine vision systems more scalable and adaptable. The use of ensemble methods, such as random forest, has further increased accuracy and robustness. By combining multiple decision trees, the model can handle larger datasets and more complex visual tasks. The regression tree approach also supports precise measurement and analysis in vision applications.
AI Integration
In 2025, decision tree machine vision systems integrate seamlessly with other AI technologies. Hybrid models combine decision tree algorithms with deep learning and ensemble techniques. This integration allows the system to leverage the strengths of each approach. For example, a random forest model can work alongside a neural network to improve feature extraction and classification accuracy.
AI integration enhances the system’s ability to process unstructured data, such as images and videos. The decision tree model uses supervised learning to train on labeled data, while deep learning components handle complex feature extraction. The ensemble approach aggregates predictions from multiple models, increasing reliability and reducing false positives.
Teams use these integrated systems in various industries, including manufacturing, healthcare, and autonomous vehicles. The decision tree machine vision system supports real-time predictions, quality control, and automated inspections. The regression tree method enables precise measurement and defect detection. As AI technologies continue to evolve, decision tree models remain a core component of advanced machine vision solutions.
Tip: Combining decision tree algorithms with ensemble and deep learning methods can maximize accuracy and efficiency in machine vision tasks.
Advantages
Interpretability
Decision tree machine vision systems stand out for their interpretability. Each decision path in the tree shows how the system arrives at its predictions. Users can trace every step, which builds trust in the results. Random forest models, a type of decision tree ensemble, use tools like SHAP values and feature importance scores. These tools reveal how each feature affects the final outcome. In fields such as facial recognition and medical imaging, this transparency helps professionals understand which feature drives the model’s decisions. This clarity is especially important in healthcare and quality control, where trust and accountability matter most.
| Metric | Random Forest | Support Vector Machines | K-Nearest Neighbors | Linear Discriminant Analysis |
|---|---|---|---|---|
| Accuracy | High | Moderate | Moderate | Moderate |
| Precision | High | Moderate | Moderate | Moderate |
| Recall | High | Moderate | Moderate | Moderate |
| Feature Selection Impact | Significant | N/A | N/A | N/A |
This table shows that random forests maintain high accuracy, precision, and recall. They also offer significant feature selection benefits, which support their interpretability and scalability in machine vision applications.
Speed and Scalability
Decision tree systems process data quickly. They use parallel processing, which means multiple trees can train at the same time. Distributed computing frameworks, such as Apache Spark, split large datasets across many nodes. This approach allows the system to handle massive amounts of visual data without slowing down. Hyperparameter tuning, like limiting tree depth or reducing the number of trees, further boosts performance. In real-world cases, such as credit card fraud detection, random forests have reached 99.5% accuracy with high precision and recall. These results show that decision tree models can deliver fast, reliable predictions even in large-scale, real-time tasks.
Tip: Teams can optimize speed by adjusting tree depth and the number of features used at each split.
Adaptability
Decision tree machine vision systems adapt well to new data and changing environments. The model can update its structure as new features or patterns appear. This flexibility makes it suitable for industries where data changes often, such as manufacturing or autonomous vehicles. Feature engineering allows the system to focus on the most important visual cues, improving accuracy and reducing errors. Teams can retrain the model quickly when new types of images or features emerge. This adaptability ensures that decision tree systems remain effective as technology and data evolve.
Limitations and Challenges
Overfitting
Decision tree machine vision systems often face overfitting. The model can learn patterns from training data that do not generalize to new images. When the tree grows too deep, it memorizes noise and small details instead of focusing on important features. This problem affects both classification and regression tasks. Engineers use pruning techniques to remove unnecessary branches and improve performance. They also limit tree depth and require a minimum number of samples at each node. These strategies help the model handle new data more effectively.
Note: Overfitting reduces the reliability of predictions in real-world scenarios. Teams must monitor model performance on unseen data to avoid this issue.
Complex Visual Data
Decision tree models struggle with complex visual data. Images with many objects, variable lighting, or unusual textures challenge the system. Manual feature selection becomes difficult as the number of classes or object types increases. The model may miss subtle patterns or relationships in the data. In regression tasks, predicting continuous values from intricate images can lead to errors. Decision tree systems work best when the data has clear, well-defined features. For highly variable or amorphous objects, other methods may perform better.
- Manual feature engineering increases workload.
- High variability in data reduces accuracy.
- Subtle patterns may go undetected.
Comparison with Deep Learning
Deep learning models, such as convolutional neural networks (CNNs), address many challenges that decision tree systems face. The table below highlights key differences:
| Aspect | Decision Tree Learning (Traditional Methods) | Deep Learning (CNNs) |
|---|---|---|
| Feature Extraction | Requires manual feature selection and tuning by engineers, which becomes complex with many classes or variable objects. | Automatically learns hierarchical and descriptive features from raw images through end-to-end learning. |
| Suitable Applications | Tasks with rigid objects, fixed positions, and specific features such as high-precision measuring, barcode reading, and print inspection. | Tasks with high object variability, variable orientations, amorphous or unspecific objects, and unknown defects like surface inspection, texture inspection, and defect detection. |
| Data and Resources | Works well with limited data and lower computational resources. | Requires large labeled datasets and significant computational power. |
| Strengths | High transparency, interpretability, and precision in constrained scenarios. | State-of-the-art performance, scalability, and ability to handle complex vision problems. |
| Weaknesses | Prone to overfitting if not constrained, lacks automatic feature learning, and cumbersome manual tuning. | Less interpretable, higher initial false positives during training, and resource-intensive. |
Decision tree machine vision systems excel in environments with limited data and clear features. Deep learning models outperform them in large-scale, complex vision tasks. Teams must choose the right approach based on the data and application requirements.
Applications in 2025
Manufacturing
Manufacturers use decision tree machine vision systems to automate quality control. These systems inspect products on assembly lines, checking for defects in real time. Engineers program the system to recognize scratches, dents, or missing parts. The model sorts items quickly, reducing human error. In a real life use case, a car factory uses decision tree learning to spot paint flaws on vehicles before shipping. This approach improves efficiency and ensures high product standards.
Healthcare
Healthcare professionals rely on decision tree machine vision systems for diagnostics and patient monitoring. The system analyzes medical images, such as X-rays or MRIs, to detect tumors or fractures. Doctors receive clear explanations for each prediction, which helps them make informed decisions. In another real life use case, a hospital uses decision tree models to identify diabetic retinopathy in eye scans. The system highlights areas of concern, supporting early treatment and better patient outcomes.
Autonomous Vehicles
Autonomous vehicles depend on decision tree machine vision systems for object detection and navigation. The system processes camera feeds to identify pedestrians, road signs, and obstacles. Engineers design the model to react quickly, ensuring safety on the road. Decision tree learning supports real-time decision-making, which is critical for self-driving cars. The system adapts to changing environments, such as different weather or lighting conditions.
Emerging Use Cases
New industries adopt decision tree machine vision systems for tasks like agriculture and retail. Farmers use the technology to monitor crop health by analyzing drone images. Retailers deploy the system for automated checkout, recognizing products without barcodes. These applications show the flexibility of decision tree learning. Teams continue to find creative ways to use this technology in daily operations.
Best Practices and Trends
Implementation Tips
Teams in 2025 follow several best practices to optimize decision tree machine vision systems.
- They focus on memory layout and caching behavior to reduce execution time and instruction cache misses.
- On server-class systems, optimized if-else tree realizations can cut elapsed time by up to 75%. Embedded systems see up to 70% reduction using native tree structures.
- The choice between if-else and native tree realizations depends on system resources, model size, and complexity.
- Profiling parameters such as tree depth, number of trees, and budget size helps maximize performance and reduce cache misses.
- These optimizations matter most for embedded and resource-constrained systems where memory and energy efficiency are critical.
- Automation in parameter selection and co-design between application and compiler further enhances efficiency.
A recent study compared single decision trees, AdaBoost, and random forest models. Random forest achieved the highest accuracy and F1-score, managing feature interdependencies and reducing overfitting. Teams also use thorough hyperparameter optimization and data preprocessing to improve results. Ensemble methods, especially random forest, have become a standard for robust machine vision solutions.
Tip: Regular profiling and tuning of model parameters can significantly boost system performance and reliability.
Hybrid Models
Hybrid models combine decision trees with deep learning frameworks such as GANs, CNNs, and RNNs. These models use decision trees for interpretable classification and regression, while deep learning components handle complex feature extraction and temporal dependencies. High-performance hardware supports efficient processing of large datasets, making hybrid models scalable and robust.
| Key Performance Indicator | Hybrid Model Performance | Impact on Business Metrics |
|---|---|---|
| Market Share Prediction Accuracy | 92% | Significant increase in market share |
| Profit Growth Rate Prediction Accuracy | 91% | Noticeable improvement in profit growth rate |
| Customer Satisfaction Prediction Accuracy | 89% | Customer satisfaction rose to 80% in Q4 |
| Corporate Competitiveness | Improved market ranking by 2 positions | Enhanced brand influence and innovation |
Hybrid models improve forecast reliability by combining historical, statistical, and machine learning techniques. Real-time sentiment and social media analysis further enhance adaptability. These trends show that hybrid models, including ensemble and random forest approaches, deliver higher accuracy and better business outcomes.
Future Outlook
Decision tree machine vision systems will continue to evolve. Future innovations may include multimodal data integration, improved interpretability, and real-time predictive analytics. Interdisciplinary collaboration and continuous updates will help teams leverage hybrid models more effectively. As ensemble and random forest techniques advance, organizations can expect even greater accuracy, efficiency, and adaptability in machine vision applications.
Decision tree machine vision systems use clear, branching logic to analyze images. These systems offer strong interpretability, fast processing, and adaptability. Teams face challenges with overfitting and complex data. In 2025, decision tree models remain a practical choice for many industries.
Decision tree learning will keep evolving. New advances in AI and hybrid models will shape the future of machine vision.
FAQ
What makes decision tree machine vision systems easy to interpret?
Decision tree systems show each decision step as a branch. Users can follow the path from the root to the leaf. This clear structure helps engineers and managers understand how the system makes predictions.
How do decision tree models handle missing data in images?
Decision tree algorithms can skip missing values or use surrogate splits. These methods let the model make decisions even when some image features are unavailable. This approach keeps predictions reliable.
Are decision tree machine vision systems suitable for real-time applications?
Yes. Decision tree models process data quickly. They use parallel processing and optimized algorithms. Many industries use them for real-time quality checks and fast object detection.
Can decision tree systems work with other AI models?
Teams often combine decision trees with deep learning or ensemble methods. This hybrid approach improves accuracy and handles complex visual tasks. Hybrid models use the strengths of each technique for better results.
See Also
Advancements In Machine Vision Segmentation Technologies For 2025
How Masking In Machine Vision Improves Safety In 2025
Understanding Computer Vision Models And Machine Vision Systems








