
A convolutional neural network machine vision system uses layers of convolutional filters to interpret images and video, learning to recognize patterns like edges or faces. Much like the human visual system, this ai-powered approach processes visual information in stages. While ai vision systems can match human recognition accuracy with clear images, they struggle with noisy visuals. Today, ai drives computer vision in healthcare, automotive, and security, powering tasks from disease detection to facial recognition.
- Healthcare: ai assists doctors with medical image recognition and diagnosis.
- Automotive: ai vision enables vehicle recognition and safe navigation.
- Security: ai supports real-time recognition in surveillance and identification.
Key Takeaways
- Convolutional neural networks (CNNs) use layers of filters to find patterns in images, helping machines recognize objects like humans do.
- CNNs learn features automatically from data, making them flexible and accurate for tasks like medical diagnosis, self-driving cars, and security.
- The CNN architecture includes convolutional, activation, pooling, and fully connected layers that work together to extract and analyze image features.
- Training CNNs requires large, well-labeled datasets and powerful hardware like GPUs to achieve high accuracy and fast learning.
- Open-source tools like TensorFlow and PyTorch make it easier to build and deploy CNN machine vision systems, even for beginners.
Core Concepts
What Is a Convolutional Neural Network?
A convolutional neural network is a type of deep learning algorithm designed for image tasks. It works by using layers of convolutional filters that scan across an image, searching for patterns like edges, shapes, or colors. Each filter acts like a small window, looking at different parts of the image and applying the same function everywhere. This process is called parameter sharing. The network treats the image as a collection of small patches, analyzing each one in the same way. This divide-and-conquer approach helps the system find important features, even in complex images.
Convolutional neural networks use several key layers:
- Convolutional layers: These layers use filters to scan for features and create feature maps.
- Activation functions: These add non-linearity, helping the network learn complex patterns.
- Pooling layers: These reduce the size of the feature maps, making the network faster and less likely to overfit.
- Fully connected layers: These layers combine all the features to make a final decision, such as classifying an image.
Deep learning allows convolutional neural networks to learn features automatically, without manual programming. The network starts by finding simple patterns, like lines or corners, and then builds up to more complex shapes and objects. This layered approach makes convolutional neural networks powerful tools for ai vision tasks.
Why Use CNNs in Machine Vision?
Convolutional neural networks have become the backbone of modern ai vision systems. They offer several advantages over traditional machine learning models. First, they can learn features directly from data, so engineers do not need to handcraft rules for every possible pattern. This makes convolutional neural networks more flexible and accurate.
- Convolutional neural networks handle changes in scale, orientation, and lighting better than older methods.
- They keep the spatial relationships in images, which helps with tasks like object detection.
- Deep learning with convolutional neural networks outperforms classic algorithms in recognizing complex patterns.
- Pooling layers and parameter sharing make these networks efficient, reducing the number of parameters compared to fully connected networks.
Machine learning and deep learning have changed how ai systems process images. Convolutional neural networks combine feature extraction and decision-making in one model. This unified approach simplifies deployment and improves performance in real-world ai applications.
Architecture
Layers in CNNs
Convolutional neural networks use several types of layers to process images and video. Each layer has a special job in the cnn architecture. The table below shows the main layers and their roles in feature extraction:
| Layer Type | Role in Feature Extraction and CNN Architecture |
|---|---|
| Convolutional (CONV) | Applies learnable filters to input data to extract local features like edges, textures, and shapes. Produces feature maps. |
| Activation (RELU) | Adds non-linearity, helping the network learn complex patterns. |
| Pooling (POOL) | Reduces the size of feature maps, making the model faster and less likely to overfit. |
| Fully Connected (FC) | Combines all features for final classification or detection tasks. |
| Batch Normalization (BN) | Helps with training stability and normalization. |
| Dropout (DO) | Prevents overfitting by randomly turning off some neurons during training. |
These layers work together to help deep ai systems find important patterns in images. Convolutional layers focus on local features. Pooling layers make the network more efficient. Activation layers allow deep ai models to learn complex shapes. Fully connected layers help with final decisions, such as detection or classification.
Convolution Operation
The convolution operation is the heart of deep ai vision systems. It helps convolutional neural networks find patterns in images. The process works as follows:
- The network defines a small matrix called a kernel or filter.
- The filter slides across the image.
- At each spot, the filter multiplies its values with the overlapping part of the image.
- The network adds up these numbers to get a single value.
- This value goes into a new map called a feature map.
This process repeats across the whole image. The filters in deep ai models learn to spot important features, such as edges or corners. Stacking many convolutional layers lets the network find both simple and complex patterns. This helps ai systems with tasks like detection and recognition.
Feature Maps
Feature maps show what the convolutional neural networks have learned from an image. Each feature map highlights a different pattern, such as a line or a curve. The network creates these maps by sliding filters over the image and recording where it finds certain features. Multiple filters create many feature maps, each showing a different part of the image.
Feature maps help deep ai models move from simple shapes to complex objects. Early layers might find edges, while deeper layers find faces or other objects. This step-by-step process lets convolutional neural networks learn about the world in a way that supports accurate detection and recognition. Feature maps make it possible for ai to understand images without manual programming.
Image Processing
Step-by-Step Flow
A convolutional neural network uses a clear sequence to handle image processing and analysis. This process helps the system move from raw pixels to a final prediction. The steps below show how deep models work with images:
- Input Layer: The network receives the raw image as a matrix of pixel values. For example, a color photo might have three channels for red, green, and blue.
- Convolutional Layer: Filters slide over the image to find features like edges or textures. Each filter creates a feature map that highlights certain patterns.
- Activation Layer (ReLU): The network applies a function that keeps positive values and sets negative ones to zero. This step helps the deep model learn complex shapes.
- Pooling Layer: The system reduces the size of the feature maps by keeping only the most important information. This makes the network faster and helps it focus on key details.
- Fully Connected Layer: The network flattens the feature maps and connects every neuron. This layer combines all the learned features for the final decision.
- Output Layer: The system uses a function to turn the results into probabilities. It then predicts the class or label for the image.
This step-by-step flow allows deep models to perform image processing and analysis with high accuracy. Each stage builds on the last, helping the network learn from simple lines to complex objects.
Training Process
The training process for a convolutional neural network uses supervised machine learning. The system starts by preparing a large set of labeled images. Each image has a correct answer, such as the object it shows. The network compares its predictions to these labels and measures the difference using a loss function. An optimizer then updates the network’s weights to reduce this difference. The process repeats many times, with the network learning a little more each round.
Deep models need large and high-quality datasets for the best results in image processing and analysis. Studies show that increasing the number of training images can boost accuracy in detection tasks. However, after a certain point, adding more data gives smaller gains. The quality of the data also matters. Well-labeled and diverse images help the network learn better. Data with errors or bias can hurt performance. Using synthetic images and smart labeling methods can improve results and lower costs. These steps make the training process more effective for deep machine learning systems.
Convolutional Neural Network Machine Vision System

Applications
A convolutional neural network machine vision system powers many real-world computer vision tasks. These systems help machines see and understand images and video, just like people do. They play a key role in image classification, object recognition, and detection. Many industries use these systems to solve complex problems.
- Automated inspection and quality control in manufacturing help factories find defects and improve product quality.
- Object recognition in driverless cars supports safe navigation by identifying pedestrians, vehicles, and road signs.
- Cancer cell detection in pathology slides assists doctors in healthcare with early diagnosis.
- Face recognition in security systems improves safety and access control.
- Traffic monitoring and congestion detection in smart cities help manage roads and reduce delays.
- Retail customer segmentation uses behavior analysis to improve shopping experiences.
- Land use mapping for environmental monitoring and agriculture supports better resource management.
Convolutional neural network machine vision systems also excel in image segmentation. For example, U-Net helps doctors find tumors in medical images. Mask R-CNN allows cars to separate objects like people and traffic signs in real time. In manufacturing, segmentation finds tiny defects on circuit boards. Farmers use segmentation to monitor plant health and count crops from drone images. These applications show how computer vision technologies improve accuracy and efficiency in many fields.
Advantages
A convolutional neural network machine vision system offers many benefits over older computer vision technologies. These systems use deep learning to find important features in images, such as edges, textures, and shapes. They do not need engineers to program every rule. Instead, they learn from data, which makes them flexible and powerful.
- CNNs capture local image features, building a strong foundation for object recognition and detection.
- Parameter sharing reduces model complexity, making training easier and faster.
- Convolution operations run efficiently on GPUs, speeding up computer vision tasks.
- These systems excel in feature extraction, image classification, and object recognition.
- Transfer learning lets engineers use pre-trained models, saving time and improving results when data is limited.
- CNNs have shown high accuracy in real-world applications, such as medical image analysis, self-driving cars, retail, and agriculture.
- Their design, inspired by the human visual system, makes them especially good at processing visual data.
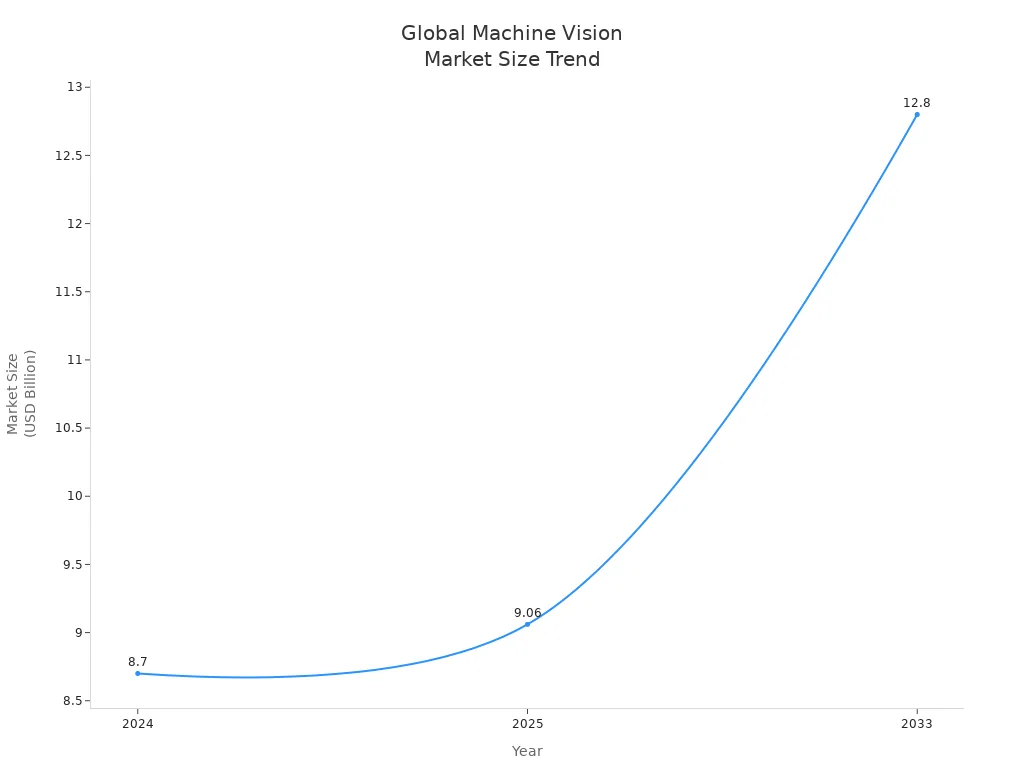
The table below shows how different CNN architectures perform on the ImageNet benchmark, a popular test for image recognition tasks:
| CNN Architecture | ImageNet Accuracy (%) |
|---|---|
| ResNet-18 | 69.82 |
| ResNet-50 | 73.24 |
| ResNet-101 | 77.45 |
| ResNet-152 | 78.36 |
In manufacturing, a convolutional neural network machine vision system can inspect thousands of products per minute. These systems reduce manual labor and increase reliability. They find defects like scratches or dents with high precision, often reaching accuracy rates above 99%. This level of performance is hard for humans to match, especially over long periods.
Recent advancements in deep learning have made these systems even better. New architectures, such as MobileNet and ResNet, use special layers to improve speed and accuracy. Hardware accelerators like TPUs and GPUs help process high-resolution images quickly. These improvements allow ai to handle more complex computer vision tasks in real time.
Limitations
Despite their strengths, a convolutional neural network machine vision system faces several challenges. These systems need large, high-quality datasets to work well. Poor data, such as images with noise or bias, can lower accuracy in detection and classification. Training these systems requires powerful computers, which can be expensive and use a lot of energy.
CNNs often act as "black boxes." People cannot always see how the system makes decisions. This lack of transparency can be a problem in fields like healthcare or self-driving cars, where trust and safety matter.
Other limitations include:
- Difficulty handling small or imbalanced datasets, which can lead to poor performance.
- High computational demands, needing GPUs or other accelerators for training and inference.
- Ethical concerns, such as bias in training data and privacy issues when using personal images.
- Challenges in adapting to new environments or changing conditions, which can affect robustness.
- Limited feedback mechanisms, making it hard for the system to learn from mistakes after deployment.
In security and surveillance, privacy and fairness become major concerns. Systems must protect personal data and avoid unfair outcomes. Regulations and ethical guidelines help address these issues, but challenges remain as ai becomes more common in daily life.
Getting Started
Tools and Frameworks
Many open-source tools help users build convolutional neural network machine vision systems. These tools make it easier to process images, train models, and deploy solutions. Some of the most popular options include:
- OpenCV: This library supports over 2,500 computer vision algorithms. It works on many platforms and languages. OpenCV handles tasks like object tracking, facial recognition, and real-time video analysis. It also integrates with deep learning frameworks.
- TensorFlow: Developed by Google, TensorFlow offers strong support for building and deploying CNNs. It includes pre-trained models and tools for mobile or edge devices. The Keras API makes model building simple.
- PyTorch and TorchVision: PyTorch is known for its flexibility and dynamic computation. TorchVision provides pre-trained models and image processing utilities. Researchers and engineers use these tools for custom model training.
- Fastai: Built on PyTorch, Fastai simplifies CNN training with high-level APIs. It supports transfer learning and GPU-optimized modules.
- Caffe: This framework focuses on speed and modularity. It works well for image classification tasks.
- OpenVINO: This toolkit helps optimize and accelerate CNN inference, especially on edge devices.
A basic system needs both hardware and software. The table below shows the minimum requirements:
| Component | Minimum Requirement | Notes |
|---|---|---|
| CPU | Intel Core i5 or AMD Ryzen 5 | Multi-core CPU needed for data preprocessing |
| GPU | NVIDIA GTX 1650 (4 GB VRAM), CUDA-enabled | Essential for training and inference acceleration |
| RAM | 16 GB | Handles large datasets and computations |
| Storage | 256 GB SSD | SSD speeds up data loading and processing |
| OS | Windows 10/11 or Ubuntu 18.04+ | Linux preferred for deep learning |
| Frameworks | TensorFlow, PyTorch, Keras | Needed for model development and training |
| Python Libraries | NumPy, OpenCV, Pillow, Matplotlib, scikit-learn | For image processing and visualization |
| GPU Acceleration | CUDA Toolkit 11.0+ and cuDNN | Leverages NVIDIA GPU capabilities |
| IDE | VS Code, Jupyter Notebook, PyCharm | Recommended for coding and debugging |
Implementation Tips
Beginners can follow a step-by-step approach to build a successful CNN machine vision system:
- Learn the basics of CNNs, including convolutional, pooling, and fully connected layers.
- Set up a programming environment with Python and frameworks like TensorFlow or PyTorch.
- Prepare datasets such as CIFAR-10. Use normalization and data augmentation (rotation, flipping) to improve model robustness.
- Design a simple CNN architecture. Add dropout layers to prevent overfitting.
- Choose optimizers like Adam and select suitable loss functions and metrics.
- Train the model with augmented data. Tune hyperparameters for better results.
- Evaluate the model on test data. Iterate to improve accuracy.
- Try new architectures to optimize performance.
Tip: Data augmentation helps overcome small or imbalanced datasets. Techniques like rotation, scaling, and flipping increase dataset size and improve generalization.
Common challenges include the need for large datasets, high computational power, and the risk of overfitting. Beginners should start with simple models and monitor validation accuracy. Using GPU acceleration and diverse data helps the model perform well in real-world conditions.
Convolutional neural network machine vision systems have changed how technology understands images and video. These systems learn from data, making them flexible and accurate for tasks like medical imaging, traffic control, and quality inspection. Their ability to process visual information in real time improves safety and efficiency across many industries.
Anyone can start learning about these systems using open-source tools and beginner-friendly tutorials.
| Resource | Description |
|---|---|
| Introduction to CNNs (DataCamp) | Explains CNN basics and practical uses. |
| CNN with TensorFlow Tutorial | Guides users through building a simple CNN. |
Exploring these resources helps readers build their own vision projects and join the future of AI.
FAQ
What is the main job of a convolutional neural network in machine vision?
A convolutional neural network helps computers find patterns in images. It looks for shapes, colors, and objects. The network learns to recognize things like faces, cars, or animals by studying many pictures.
How much data does a CNN need to work well?
A CNN needs thousands of labeled images to learn. More data helps the network find better patterns. Small datasets can make the network less accurate.
Tip: Data augmentation, like flipping or rotating images, can help when there are not enough pictures.
Can a CNN make mistakes with new images?
Yes, a CNN can make mistakes if it sees something very different from its training data. It works best with images similar to what it has learned before.
What hardware helps train CNNs faster?
A computer with a strong GPU (graphics card) speeds up training. GPUs process many images at once. This makes learning much faster than using only a CPU.
| Hardware | Benefit |
|---|---|
| GPU | Fast training |
| CPU | Slower, but works for small tasks |
See Also
Understanding Models Behind Computer And Machine Vision Systems
A Comprehensive Guide To Image Processing In Machine Vision
The Role Of Cameras Within Machine Vision Technology
Ways Deep Learning Improves Performance Of Machine Vision
Neural Network Frameworks Transforming Modern Machine Vision Systems








