
A bounding box machine vision system uses computer vision and ai to locate and highlight objects of interest in images or video streams. A bounding box marks the edges around an object, helping ai systems focus on areas that matter. These bounding boxes play a central role in object detection and recognition tasks, guiding machines to learn what to identify. In 2025, ai-driven recognition has become more accurate, making bounding boxes essential for industries with growing interest in automation and real-time analysis. The global market for bounding box machine vision system solutions continues to expand, reflecting the rising demand for advanced ai and computer vision tools.
| Metric/Region/Segment | Value (USD Billion) | Year/Period | CAGR (%) |
|---|---|---|---|
| Global Multi-camera Vision Inspection Market Size | 3.40 | 2024 | |
| Projected Global Market Size | 7.58 | 2032 | 10.62 (2025-2032) |
| U.S. Market Size | 0.62 | 2024 | |
| Projected U.S. Market Size | 1.26 | 2032 | 8.25 (2025-2032) |
| North America Revenue Share | 34.14% | 2024 | |
| Asia Pacific Market Growth Rate | N/A | 2025-2032 | 11.74 |
| AI-based Vision Systems Growth Rate | N/A | 2025-2032 | 11.82 |
| Broader Machine Vision Market Size | 11.8 | 2022 | |
| Projected Broader Market Size | 21.0 | 2030 | 7.5 |
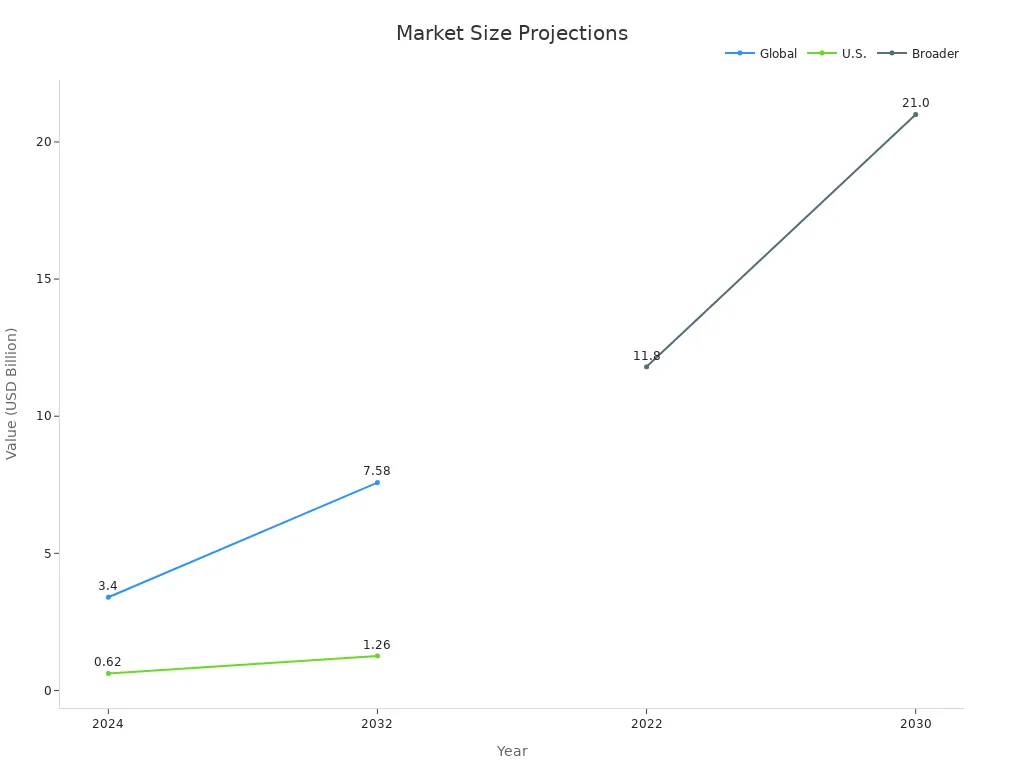
The machine vision market reached $11.8 billion in 2022 and could grow to $21.0 billion by 2030. Ai-based vision systems, which rely on bounding boxes for recognition, are projected to grow even faster, driven by advancements in ai and computer vision that boost recognition accuracy and efficiency.
Key Takeaways
- Bounding box machine vision systems use AI to detect and highlight objects in images, improving accuracy and speed in object recognition.
- These systems rely on drawing rectangles around objects, helping AI focus on important areas and supporting tasks like product inspection and autonomous driving.
- Key performance metrics like Intersection over Union (IoU), precision, recall, and mean average precision (mAP) measure how well bounding boxes detect and classify objects.
- New AI models like YOLOv10 and YOLOv11 improve bounding box detection with faster speeds and higher accuracy, enabling real-time applications in industries.
- Combining automated annotation with human review and using proper IoU thresholds ensures high-quality bounding boxes, which leads to better AI performance.
Bounding Box Machine Vision System
Definition and Purpose
A bounding box machine vision system uses computer vision and ai to detect and highlight objects in digital images or video. The system draws bounding boxes around objects, showing their position and size. These bounding boxes help deep learning models focus on important areas, making object detection and image recognition more accurate.
The main purpose of a bounding box machine vision system is to detect and localize objects in a scene. The system uses bounding boxes to mark the edges of each object, which helps ai models learn what to look for. In many industries, these systems support tasks like product inspection, medical diagnosis, and autonomous driving. For example, in dental radiographic image analysis, experts use bounding boxes to label regions of interest. Deep learning models, such as YOLO, then use these labeled images to classify treatment outcomes. This process improves the accuracy of recognition and classification, even when images contain noise or artifacts.
Bounding box detection relies on precise parameters, including position, width, and height. The system measures how much predicted bounding boxes overlap with ground truth boxes using Intersection over Union (IoU). IoU helps track objects across frames and filters out low-confidence detections. These steps ensure that the bounding box machine vision system can reliably detect and classify objects over time.
Comparative studies show that bounding boxes improve object localization. When users receive images with perfect bounding boxes, their mean error drops compared to clean images. The table below shows how different localization methods affect accuracy and response time:
| Localization Method | Mean Error (± SD) | Response Time (± SD) |
|---|---|---|
| Clean Images | 3.7 ± 3.6 | 18.6s ± 17.4s |
| Perfect Bounding Box | 1.5 ± 2.7 | 17.0s ± 15.8s |
| Shifted Bounding Box (IoU=0.5) | 1.3 ± 2.0 | 29.7s ± 7.3s |
| Perfect Dot | 0.7 ± 1.8 | 15.8s ± 11.7s |
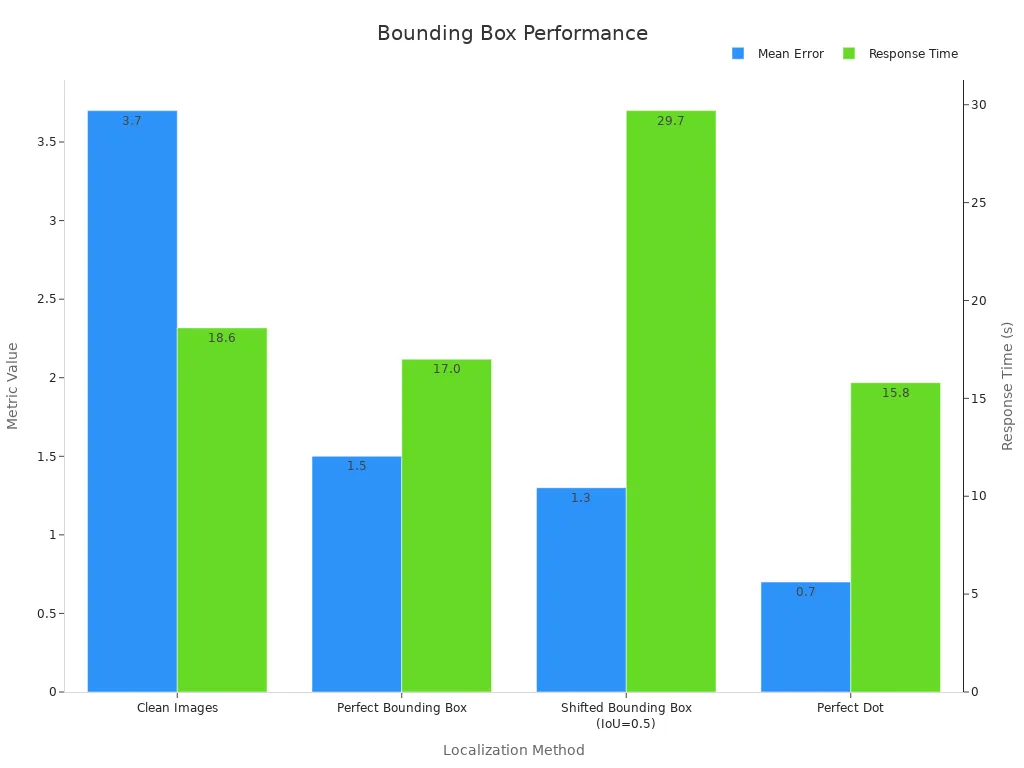
These results show that bounding boxes help both humans and ai systems detect and localize objects faster and more accurately.
Key Components
A bounding box machine vision system includes several important parts. Each part works together to help ai and deep learning models detect and classify objects in images or video.
- Image Acquisition: The system captures images or video using cameras or sensors. High-quality image acquisition is the first step in computer vision.
- Data Delivery: The system sends the captured data to processing units. Fast and reliable data delivery supports real-time object detection.
- Information Extraction: Deep learning models, especially convolutional neural networks, analyze the images. These models use bounding boxes to find and classify objects. They extract features such as shape, color, and texture.
- Decision Making: The system uses the extracted information to make decisions. For example, it can sort products, trigger alarms, or guide robots.
Bounding box detection uses several technical metrics to measure performance. Precision and recall are two key metrics. Precision shows how many detected objects are correct. Recall shows how many real objects the system finds. Mean Average Precision (mAP) combines both metrics to give an overall score. The table below shows the performance of a recent YOLO-based model:
| Metric | YOLO-MECD Value | Improvement / Comparison |
|---|---|---|
| Precision (P) | 84.4% | +0.2 percentage points vs baseline |
| Recall (R) | 73.3% | +4.1 percentage points vs baseline |
| Mean Average Precision (mAP) | 81.6% | +3.9 percentage points vs baseline |
| Model Parameters | 2,297,334 | Reduced by 75.6% from 9,413,574 |
| Model Size | 4.66 MB | Reduced by 74.4% from 18.2 MB |
| mAP Improvement vs YOLOv8s | +3.8% | – |
| mAP Improvement vs YOLOv9s | +3.2% | – |
| mAP Improvement vs YOLOv10s | +5.5% | – |
The evolution of bounding box systems in computer vision has seen major changes. Early methods used handcrafted features, like the Viola-Jones algorithm. These methods worked but had limits. The rise of deep learning models brought new approaches. Two-stage detectors, such as R-CNN, first propose regions and then classify them. One-stage detectors, like YOLO and SSD, predict bounding boxes and classes in a single step. YOLO models have become popular for their speed and accuracy. Each new version adds improvements, such as deeper networks and better feature extraction.
Note: Benchmark datasets, such as Pascal VOC, provide structured annotations for bounding boxes. These datasets help train and test deep learning models, supporting advances in object detection and classification.
Today, bounding box machine vision systems play a key role in ai-powered computer vision. They help industries detect and localize objects, improve image recognition, and support accurate classification. As deep learning models and ai continue to advance, these systems will become even more important for real-time applications.
Bounding Boxes
Coordinate Systems
Bounding boxes help machine vision systems find and mark objects in images. Each bounding box uses a coordinate system to show its position and size. The most common method starts at the top-left corner of the region of interest. It uses four values: the x and y coordinates for the top-left point, plus the width and height. This bounding box representation makes it easy for computers to locate and compare objects.
Researchers use several metrics to check how well bounding boxes work. Intersection over Union (IoU) measures how much the predicted box overlaps with the ground truth. IoU values range from 0 (no overlap) to 1 (perfect overlap). A detection counts as correct if the IoU is above a set threshold, often 0.5. Precision and recall scores depend on how many true positives and false positives the system finds. Mean Average Precision (mAP) combines these results to give a single score for bounding box accuracy.
- IoU measures overlap between predicted and ground-truth bounding boxes.
- True Positive: IoU above the threshold.
- False Positive: IoU below the threshold.
- Precision: Correct detections out of all detections.
- Recall: Correct detections out of all real objects.
- mAP: Overall performance across classes and IoU levels.
Bounding boxes use these metrics to compare different coordinate systems and improve detection methods. Studies show that drawing bounding boxes with accurate coordinates leads to better results in object detection.
Annotation and Regression
Bounding box annotation marks the region of interest in an image for training and testing. Drawing bounding boxes tightly around objects helps models learn to detect them. High-quality bounding box annotations improve the performance of deep learning models. Poor annotation, especially for small objects, lowers detection accuracy.
| Object Size | Human Annotation Performance | EfficientDet-D7 Performance | Key Observation |
|---|---|---|---|
| Small | Poor precision and recall | Matches human-level performance | Low annotation quality limits detection accuracy |
| Medium | Superior to EfficientDet-D7 | Inferior to human annotator | Human annotation outperforms detector |
| Large | Superior to EfficientDet-D7 | Inferior to human annotator | Human annotation outperforms detector |
Bounding box regression predicts the best coordinates for each object. Some models use anchor-free methods, focusing on the object center. Others use anchor boxes of different shapes and sizes. Recent research shows that combining regression with optimization techniques, like Gaussian process regression and particle swarm optimization, reduces errors in bounding box coordinates.
Bounding boxes can use different annotation styles. For natural images, scribbles with foundation models often work best. In medical images, coarse contours or polygons may be more effective. Noisy annotations, when processed by advanced models, can still provide good results. Drawing bounding boxes with interest in tightness and correctness leads to better object detection. Automated tools now help review and improve bounding box annotations, raising the quality and accuracy of the region of interest.
Note: The choice of annotation method and bounding box regression technique depends on the application and the type of objects. High-quality bounding boxes remain a key interest for anyone working with machine vision in 2025.
Types and Use Cases

2D and 3D Bounding Boxes
Bounding boxes come in two main types: 2D and 3D. 2D bounding boxes mark objects in flat images using four values—x, y, width, and height. 3D bounding boxes add depth, showing the position, size, and orientation of objects in space. Both types help with object detection, image recognition, and object classification.
Researchers have compared 2D and 3D bounding boxes in real-world tasks. The table below shows how they perform in medical image annotation and autonomous driving:
| Aspect | 2D Bounding Box Annotation | 3D Bounding Box Annotation | Detailed Annotation (Tumor Boundaries) |
|---|---|---|---|
| Predictive Performance | Comparable to 3D and detailed annotations | Comparable to 2D and detailed annotations | No significant improvement over bounding boxes |
| Time Required for Annotation | Less than 10 seconds | Less than 10 seconds | 30 to 60 seconds |
| Stability and Repeatability | Comparable or higher than 3D annotations | Comparable to 2D annotations | Not specifically quantified |
| Practical Recommendation | Preferred for accuracy and efficiency | Comparable but more complex | More time-consuming, no major gain |
In autonomous driving, 2D bounding boxes often achieve higher Intersection over Union (IoU) scores. 3D bounding boxes provide more spatial detail but are harder to estimate, especially at long distances. Orientation errors and dimension regression become important for 3D tasks, such as tracking vehicles or pedestrians.
Object Detection Applications
Bounding boxes power many object detection applications in 2025. AI systems use bounding boxes to process thousands of images or video frames per second. This speed enables real-time decision-making in factories, warehouses, and autonomous driving.
- Modern deep learning models like YOLO, Faster R-CNN, and EfficientDet use bounding boxes for fast and accurate image recognition.
- Factories use bounding boxes for automated defect detection and product recognition.
- Warehouses rely on bounding boxes for barcode reading and inventory management.
- Autonomous driving systems use bounding boxes for tracking vehicles, pedestrians, and obstacles in real time.
- Edge AI devices use bounding boxes to reduce latency, allowing instant detection and classification without cloud delays.
Performance metrics such as Precision, Recall, F1 Score, and Mean Average Precision (mAP) help compare bounding boxes across models. Higher Order Tracking Accuracy (HOTA) and Association Accuracy (AssA) measure how well bounding boxes maintain object identity over time, which is vital for autonomous driving and surveillance.
Note: Bounding boxes remain the foundation for object detection, image recognition, and classification in 2025. Their speed and accuracy support the latest advances in AI, especially in autonomous driving and smart automation.
Latest Trends 2025
New Models and Tools
In 2025, ai and computer vision have seen rapid growth in detection models for bounding boxes. New deep learning models like YOLOv10 and YOLOv11 have set new standards for speed and accuracy. YOLOv10 removed non-maximum suppression, which increased inference speed and reduced complexity. YOLOv11 introduced attention mechanisms and multi-scale prediction heads, making detection more precise. Lightweight models such as LMWP-YOLO now help drones detect small objects with higher sensitivity and fewer false positives. These improvements come from better feature extraction and dynamic weight mechanisms.
The table below compares key detection models and their innovations:
| Model | Key Innovation | Accuracy / Performance Stats | Applications / Trends Highlighted |
|---|---|---|---|
| SSD | Multi-scale feature maps, default boxes | mAP 72.1% (VOC2007), 58 FPS | Real-time surveillance, AR/gaming |
| Faster R-CNN | Region Proposal Network (RPN) | State-of-the-art accuracy, 5 FPS (VGG-16) | Drone surveillance, medical imaging |
| Mask R-CNN | Pixel-wise segmentation masks | High-quality instance segmentation | Detailed object representation |
| FCOS | Anchor-free, direct prediction from feature maps | State-of-the-art results, efficient | Simplifies training, improves efficiency |
Recent studies show that YOLOv10 bounding boxes achieve a 1.4% boost in average precision and reduce latency by 46% compared to earlier models. Improved YOLOv5 models for industrial tasks now reach a mean average precision of 0.622, up from 0.349, and accuracy of 0.865. These advances help ai systems detect small and distant objects more reliably.
Emerging trends include self-supervised learning, edge computing for real-time ai, and the use of bounding boxes in augmented reality. Many industries now focus on ethical ai and reducing bias in detection models.
Best Practices
High-quality bounding boxes depend on strong annotation practices and careful use of IoU thresholds. Many teams use automatic labeling pipelines with state-of-the-art detectors, followed by human review to remove errors. Pixel-level accuracy is less important than ensuring that bounding boxes tightly cover objects. Selecting diverse frames for annotation helps reduce label noise.
The chart below shows how different IoU metrics and models perform in real-world tasks:
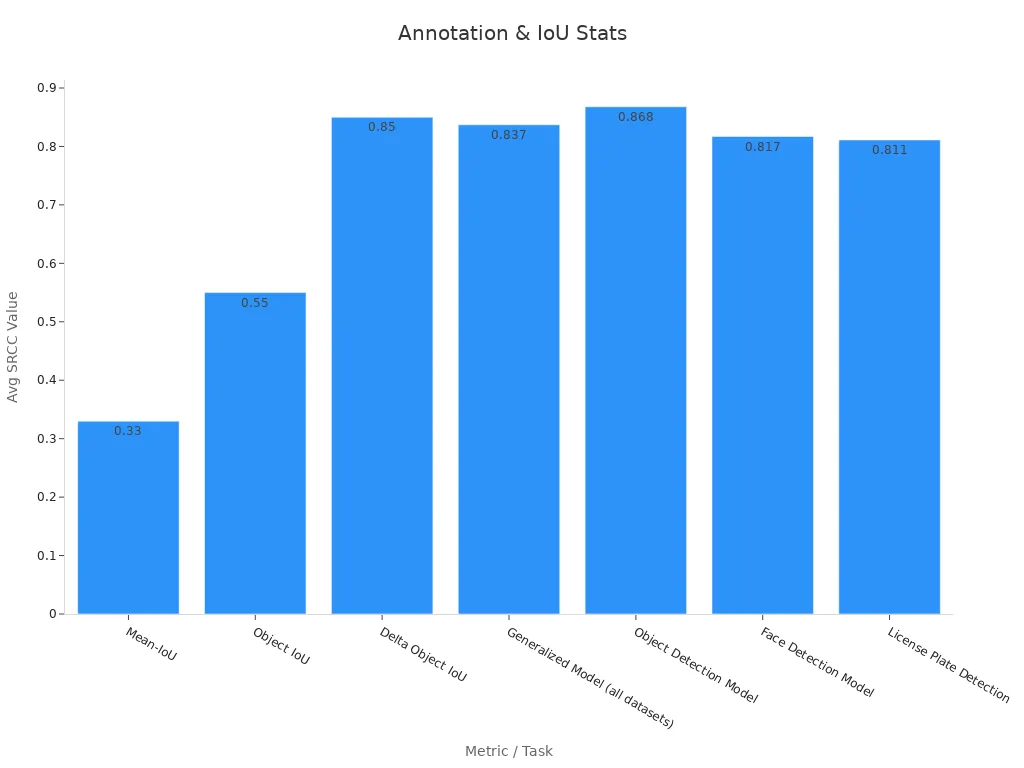
Delta Object IoU, with a correlation of 0.8 to 0.9, best reflects detection quality changes. Most detection models use an IoU threshold of 0.5 to decide if a bounding box matches the ground truth. Uncertainty-aware methods, like UL3D, improve detection accuracy for small and distant objects by focusing on high-quality pseudo labels.
Bounding box annotation tools now support automatic suggestions and error checking. These tools help ai and deep learning models learn from better data. Studies show that following best practices in annotation and IoU threshold selection leads to higher bounding box accuracy and recall, especially in challenging environments.
Tip: Teams should combine automated annotation with human review and use adaptive IoU thresholds for the best results in ai-powered computer vision.
Bounding boxes drive progress in machine vision by enabling accurate object detection across many industries.
- Object detection models depend on bounding boxes for localizing items in images.
- Training with bounding boxes improves accuracy, as seen in mean average precision scores above 82%.
- Autonomous vehicles, retail, and healthcare all benefit from bounding boxes for safety and efficiency.
- Companies like Amazon and Waymo show that precise annotation of bounding boxes leads to better results.
| Metric | Result | Note |
|---|---|---|
| Mean Average Precision | 86.54% | High accuracy with bounding boxes |
| Detection Distance | 200 meters | Small objects detected at range |
Staying updated with best practices ensures bounding boxes remain essential for future machine vision breakthroughs.
FAQ
What is a bounding box in machine vision?
A bounding box is a rectangle that marks the edges of an object in an image. It helps computer vision systems find and track objects. The box uses coordinates for its position and size.
How do bounding boxes improve object detection?
Bounding boxes help AI models focus on important parts of an image. They guide the system to learn where objects are. This focus increases accuracy and speed in object detection tasks.
What is Intersection over Union (IoU)?
Intersection over Union (IoU) measures how much a predicted bounding box overlaps with the true box. A higher IoU means better accuracy. Most systems use an IoU threshold of 0.5 to count a detection as correct.
Are 2D or 3D bounding boxes better for all tasks?
2D bounding boxes work well for most images and videos. 3D bounding boxes add depth and orientation, which helps in tasks like autonomous driving. The best choice depends on the application and the needed detail.
See Also
Advanced Segmentation Techniques For Machine Vision In 2025
Understanding Field Of View In Vision Systems By 2025
How Masking Improves Safety In Vision Systems By 2025
A Comprehensive Guide To Image Processing In Vision Systems
Industries Revolutionized By AI Driven Machine Vision Systems








