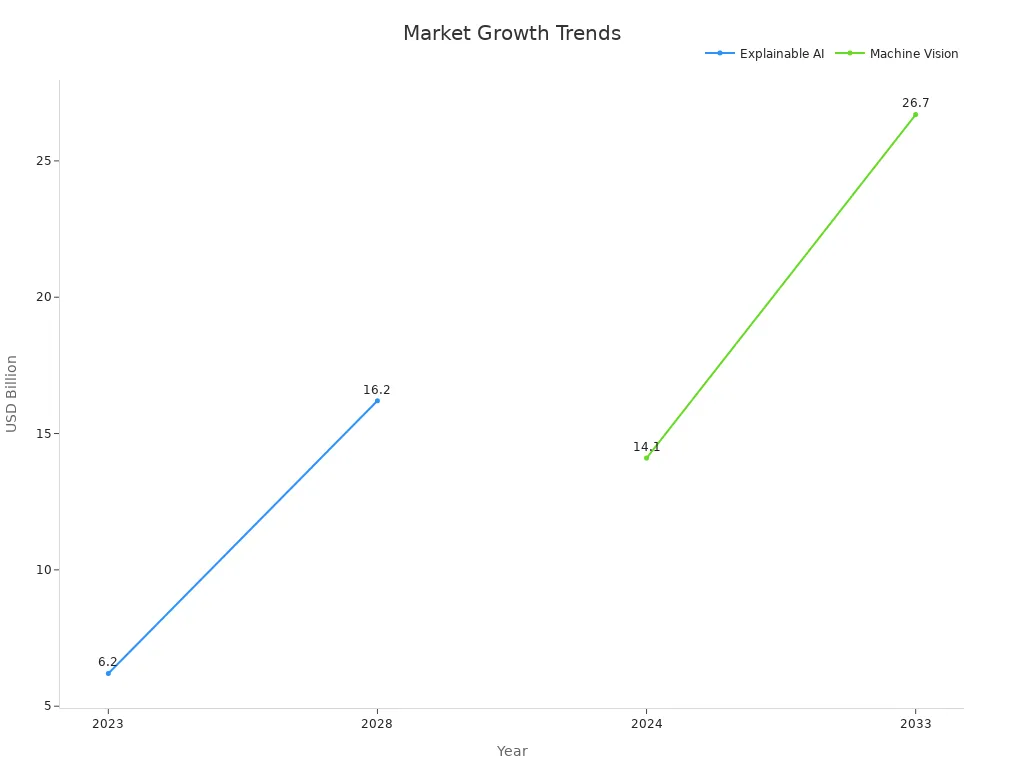
A chain-of-thought machine vision system helps computers understand images by breaking down tasks into smaller, logical steps, much like solving a puzzle one piece at a time. Many beginners find this technology valuable because it makes AI decisions easier to follow and trust. In recent years, the market for explainable AI and machine vision has grown rapidly:
Researchers show that combining visual and text explanations improves how people understand AI’s reasoning. A chain-of-thought machine vision system can boost accuracy, reduce costs, and make technology safer and more useful in daily life.
Key Takeaways
- Chain-of-thought machine vision systems solve visual problems step by step, making AI decisions easier to understand and trust.
- Breaking tasks into smaller steps improves accuracy and helps computers explain their reasoning clearly.
- These systems use advanced models like Vision Transformers to analyze images and connect visual data with text.
- Beginners can start by creating simple prompts and testing them, which helps build skills and improve results quickly.
- Chain-of-thought prompting makes AI more transparent, reliable, and useful in real-world tasks like robotics and education.
Chain-of-Thought Machine Vision System
What Is It?
A chain-of-thought machine vision system helps computers solve visual problems by thinking through each step, just like a person might do when answering a question about a picture. Instead of jumping straight to an answer, the system breaks down the task into smaller parts. For example, if someone asks, "What is the boy doing in the photo?" the system first finds the boy, then looks at his actions, and finally explains what he is doing.
This approach makes the computer’s reasoning easier to understand. People can see how the system reaches its answer, which builds trust. Many researchers use this method to improve accuracy and make AI more reliable. The system often uses advanced models, such as transformers and vision-language models, to process both images and text.
Quantitative studies show that chain-of-thought machine vision systems perform better on complex visual tasks. For instance, the MuKCoT model, which uses this step-by-step reasoning, improved accuracy by 6.6% over previous models on a tough visual question answering test. These results show that breaking down problems into steps helps computers think more logically and explain their answers more clearly.
How It Works
A chain-of-thought machine vision system follows a clear process. First, it takes an image as input. Next, it uses a series of reasoning steps to analyze the image. Each step builds on the last, allowing the system to solve complicated tasks in a logical order. Finally, it generates an answer or explanation that people can understand.
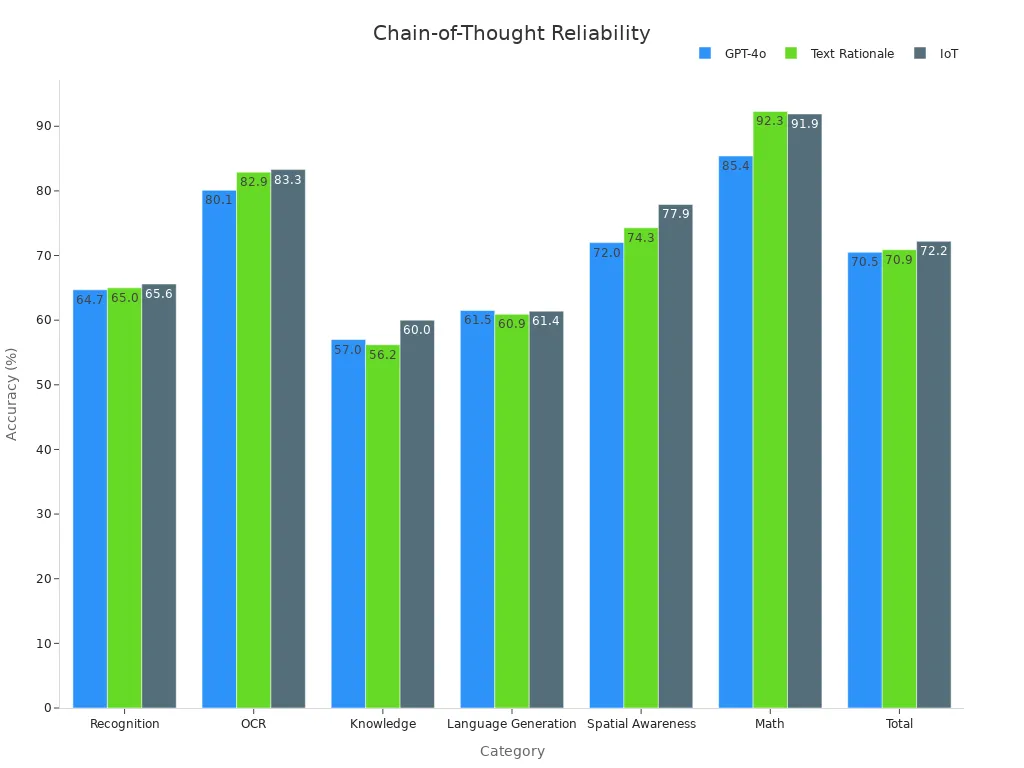
Researchers have tested these systems using large benchmark datasets. These tests measure how well the system recognizes objects, reads text, understands knowledge, and solves math problems. The table below shows how adding step-by-step reasoning, called Image-of-Thought (IoT) prompting, improves accuracy in many areas:
| Category | GPT-4o Accuracy (%) | + Text Rationale (%) | + Image-of-Thought (IoT) (%) |
|---|---|---|---|
| Recognition | 64.7 | 65.0 | 65.6 |
| OCR | 80.1 | 82.9 | 83.3 |
| Knowledge | 57.0 | 56.2 | 60.0 |
| Language Generation | 61.5 | 60.9 | 61.4 |
| Spatial Awareness | 72.0 | 74.3 | 77.9 |
| Math | 85.4 | 92.3 | 91.9 |
| Total | 70.5 | 70.9 | 72.2 |
These results come from tests like MMBench, MME, and MMVet. Each test checks different skills, such as object recognition, reading, and logical reasoning. The system often starts with object detection, then moves to more detailed steps like segmentation and zooming in on important parts. This process matches how humans look at images, making the system’s reasoning more natural and reliable.
Tip: Chain-of-thought machine vision systems not only improve accuracy but also make AI decisions easier to follow. This helps people trust and use AI in real-world situations.
Chain-of-Thought Prompting in Vision
Visual Chain-of-Thought Reasoning
Chain-of-thought prompting helps computers solve visual problems by guiding them through each step, just like a person would. This method allows the system to break down a big question into smaller, easier parts. For example, when a computer looks at a picture and needs to answer, "What is happening here?", it does not guess right away. Instead, it follows a path:
- First, it finds important objects in the image.
- Next, it checks what each object is doing.
- Then, it connects these actions to understand the whole scene.
Researchers use chain-of-thought prompting to improve how computers reason about images. They measure the system’s progress using several metrics:
- Reasoning performance: This shows how well the model answers visual questions.
- Reasoning consistency: This checks if the model’s answers stay logical and stable.
- Chain-of-thought based consistency measure: This new metric looks at how clear and connected each step in the reasoning process is.
- Relative improvement of 4%: After using a two-stage training process, models show a 4% boost in both reasoning performance and consistency.
The CURE benchmark uses these metrics to test how well vision-language models handle new problems without extra training. Chain-of-thought prompting helps these models think more clearly and explain their answers better. Students and beginners can see how each step leads to the final answer, making the process easier to follow.
Note: Chain-of-thought prompting does not just improve accuracy. It also helps people see and understand how the computer thinks about each part of the problem.
Explainability and Transparency
Chain-of-thought prompting makes AI systems more transparent. When a computer explains its answer step by step, people can see how it reached its decision. This builds trust and helps users spot mistakes or misunderstandings.
In one example, a system uses chain-of-thought prompting to analyze a restaurant review. The computer breaks the review into parts, such as service, food quality, and staff behavior. It gives each part an emotional weight, like "amazing" for positive or "slow" for negative. The system then adds up these weights to decide if the review is positive or negative. It shows both a label, like "Positive," and a score, such as 4 out of 5. This makes the reasoning process clear and easy to check.
- Chain-of-thought prompting breaks down complex tasks into smaller steps.
- Each step is visible, so users can follow the logic.
- The final answer includes both a label and a score, making the process more open.
Chain-of-thought prompting helps people understand why the AI made a certain choice. It also makes it easier to improve the system, since developers can see which step might need fixing. This level of transparency is important for safety and fairness in AI.
Tip: When using chain-of-thought prompting, always check the steps the system takes. This helps catch errors early and makes the AI more reliable.
Chain of thought methods in vision tasks continue to grow in importance. They help both experts and beginners see how AI systems work, making technology more accessible and trustworthy.
Key Components
Visual Input
A chain-of-thought machine vision system starts with visual input. The system receives an image or a sequence of images. It uses advanced models, such as Vision Transformers (ViTs) and vision-language models, to process this input. These models scan the image to find important objects, colors, and shapes.
- Vision Transformers use self-attention mechanisms to analyze images.
- Over 150 experiments have compared these models for speed, memory, and accuracy.
- ViTs often show the best balance between speed and accuracy, especially when the model size increases.
- Scaling up the model size usually gives faster and more accurate results than increasing image resolution.
- ViTs remain efficient for training and inference, making them a popular choice for visual tasks.
Reasoning Steps
After the system processes the image, it begins the reasoning steps. The model breaks down the problem into smaller parts. This process is called multi-step reasoning. Each step builds on the last, helping the system solve complex tasks.
Recent studies have looked inside these models to see how they reason. Researchers found that models often simulate multi-step reasoning in their hidden layers. Sometimes, the model finds the answer using shortcut methods, but true multi-step reasoning helps the system explain its logic.
Zero-shot chain-of-thought prompting, which uses a simple prompt like “Let’s think step by step,” can guide models to use multi-step reasoning. This method improves performance on many reasoning tasks and makes the system’s thinking clearer.
Output Generation
The final stage is output generation. The system takes the results from each reasoning step and forms a clear answer or explanation. This output can be a sentence, a label, or even a score.
Vision-language models help connect the visual information with words. The output shows not just the answer but also the steps taken to reach it. This makes the system’s decisions easier to understand and trust.
Multi-step reasoning in output generation helps users see how the system solved the problem, making the process more transparent.
Example Workflow
Step-by-Step Process
Chain-of-thought prompting helps a machine vision system solve problems by breaking them into smaller steps. Imagine a robot receives a photo of a kitchen and a question: "What should you do to make a sandwich?" The system follows a clear process:
- The model scans the image to find key objects, such as bread, knife, and vegetables.
- It predicts subgoals, like "get bread," "slice vegetables," and "assemble ingredients."
- For each subgoal, the system generates a visual thought, showing what the scene should look like after completing that step.
- The model checks if each subgoal is possible based on the current image.
- Finally, it combines the steps to answer the question with a clear explanation.
This approach uses chain-of-thought prompting to guide the robot through each action. The process matches how people solve tasks, making the system’s reasoning easy to follow. In real-world tests, frameworks like Chain of Code reach 84% accuracy on tough benchmarks, outperforming previous methods by 12%. For algorithmic tasks, these systems even solve problems correctly over 90% of the time, while humans average about 70%. These results show that chain-of-thought prompting improves both accuracy and understanding.
System in Action
Researchers have tested chain-of-thought prompting in robotics using a method called CoT-VLA. The system works as follows:
- The robot receives an image and a task.
- It predicts subgoal images, which act as visual checkpoints.
- The model uses a hybrid attention mechanism to connect images and text.
- Training happens in two stages: first, the system learns to predict subgoal images; then, it learns to generate actions.
- During deployment, the robot uses a closed-loop strategy, checking each subgoal before moving to the next.
A table below shows how unified visual reasoning improves performance:
| Method | Accuracy (%) | Inference Time (s) |
|---|---|---|
| Unified Mechanism | 77.6 | 0.336 |
| Toolkit-Based | 76.3 | 4.586 |
The unified approach, which uses chain-of-thought prompting, not only increases accuracy but also makes the system much faster. This method uses multi-step reasoning to help the robot understand, think, and answer in one smooth process. As a result, the robot can solve tasks more reliably and explain its actions clearly.
Applications of Chain-of-Thought Prompting
Vision-Language Models
Vision-language models use chain-of-thought prompting to improve how computers understand images and text together. These models can answer questions about pictures, describe scenes, or even solve math problems shown in images. Researchers have studied the applications of cot in these models by looking at different methods and datasets.
- The survey "Visual Prompting in Multimodal Large Language Models: A Survey" reviews how chain-of-thought prompting works in vision-language models.
- TextCoT uses a three-stage approach to help computers understand images with lots of text.
- DetToolChain combines a detection toolkit with a multimodal chain-of-thought method for object detection.
- The survey lists many datasets that help test and improve these models.
These models show better performance when they use step-by-step reasoning. They can handle complex tasks, such as finding objects in crowded scenes or explaining why something happens in a picture.
Robotics and Control
Robots use chain-of-thought prompting to plan and complete tasks in the real world. For example, a robot in a kitchen can break down the job of making a sandwich into smaller steps. It finds the bread, gathers ingredients, and puts everything together. This step-by-step process helps robots avoid mistakes and work safely around people.
Robotics researchers use applications of cot to teach robots how to adapt to new situations. Robots can explain their actions, which makes it easier for people to trust and guide them.
Everyday Uses
Chain-of-thought prompting appears in many daily tools. Smartphones use it to help users search for photos by describing what is in them. Apps for the visually impaired use it to explain scenes or read signs aloud. In education, teachers use these systems to help students understand science diagrams or solve math problems.
Note: Chain-of-thought prompting makes technology more helpful and easier to understand for everyone.
Benefits and Limitations
Advantages for Beginners
Chain-of-thought machine vision systems offer several benefits for those just starting out. These systems help users see how a computer solves a problem step by step. Beginners can follow each stage, which makes learning easier. The clear reasoning process builds trust and helps users understand why the system gives a certain answer.
Many studies show that chain-of-thought prompting improves reasoning transparency. This method breaks down complex problems, making them easier to solve. Large models often perform better on complex tasks when they use chain-of-thought prompting. Beginners can use simple prompts and still get strong results. In many cases, simple chain-of-thought approaches work just as well as more complicated ones.
Tip: Beginners should focus on understanding the step-by-step process. This approach helps them learn how computers think and solve problems.
Common Challenges
While chain-of-thought systems have many strengths, they also come with challenges. Performance gains depend on the model’s design and training, not just the chain-of-thought method. Some models may show slower response times because they process each step in detail. In certain cases, the system might give answers that look logical but are actually misleading.
- Chain-of-thought prompting can underperform in some medical reasoning tasks.
- Results often depend on model size and training, not the complexity of the prompt.
- Simpler tasks may not benefit much from this method.
- Studies found no big differences between different chain-of-thought methods across datasets.
Sensitivity in cot can also affect results. Some systems react strongly to small changes in the prompt or input. This can make results less stable. Users should test their systems carefully to avoid mistakes.
Note: Beginners should remember that model capabilities matter more than prompt complexity. Testing and practice help reduce errors and improve results.
Getting Started
Tips for Beginners
Starting with chain-of-thought machine vision systems can feel challenging, but a step-by-step approach makes learning easier. Beginners should focus on breaking down problems into smaller reasoning steps. This method helps models pay attention to important details and improves accuracy. Many experts recommend using a prompt engineering technique to guide the model’s thinking process.
A simple plan can help beginners build skills and track progress:
-
Foundation Building
Choose a use case, create basic prompts, and test them with real images. Write down how the model reasons through each step. -
Refinement
Check the model’s answers for quality. Change the prompts if needed. Build a library of templates and teach others on the team. -
Scaling
Try more use cases. Measure results and ask for feedback. Make changes to improve performance. -
Advanced Implementation
Explore new features, connect the system to other tools, and plan for larger projects.
Tip: Beginners often see big improvements in accuracy and time savings by following this plan. Many teams report over 50% better accuracy and 60% less time spent checking results.
Resources
Many resources help beginners learn about chain-of-thought systems. Step-by-step tutorials show how to fine-tune models and improve reasoning. These guides often include performance data, which helps users see real benefits. Beginners can use online courses, open-source code, and community forums to get started.
| Reasoning Task | Benefit with Chain-of-Thought Prompting |
|---|---|
| Arithmetic Reasoning | Solves math problems more accurately and matches top benchmarks |
| Commonsense Reasoning | Improves understanding of everyday situations and human actions |
| Symbolic Reasoning | Handles tasks like letter puzzles and coin flips with high success rates |
| Question Answering | Breaks down complex questions, leading to fewer mistakes |
Note: Tutorials and guides often use real examples, making it easier for beginners to follow each step and understand how the system works.
Chain-of-thought machine vision systems help computers solve problems step by step. These systems build on important milestones, such as OpenAI’s o1 model and new methods like Tree-of-Thoughts and knowledge graphs.
- OpenAI’s o1 model set a new standard for logical reasoning.
- DeepSeek-V3 and Claude 3.5 Sonnet added self-verification and adaptive reasoning.
- Prompt engineering and CoT prompting now play a key role in making AI more transparent.
Experts expect future systems to use ideas from psychology and language processing. Researchers believe that new reasoning techniques will make these systems even better. Many see chain-of-thought prompting as a way to improve real-world tasks, like financial analysis. Anyone interested can explore tutorials, join online communities, or try simple projects. Curiosity and practice will help learners unlock the full power of chain-of-thought machine vision. 🚀
FAQ
What is chain-of-thought prompting in machine vision?
Chain-of-thought prompting guides a computer to solve visual problems step by step. The system explains each part of its reasoning. This helps people see how the computer reaches its answer.
How does chain-of-thought improve explainability?
Chain-of-thought methods show each step in the reasoning process. Users can follow the logic and spot mistakes. This makes the system’s decisions easier to trust.
Can beginners use chain-of-thought systems?
Yes! Beginners can start with simple prompts and examples. Many tools and tutorials help new users learn how to build and test these systems.
What types of tasks work best with chain-of-thought machine vision?
Tasks that need step-by-step reasoning work best. These include answering questions about images, solving math problems, and planning actions for robots.
Are chain-of-thought systems always accurate?
No system is perfect. Chain-of-thought systems can make mistakes, especially with unclear images or tricky questions. Testing and practice help improve results.
See Also
Comprehensive Overview Of Semiconductor-Based Vision Systems
Detailed Insights Into Machine Vision And Image Processing
How To Properly Position Equipment For Vision Systems








