
An attention mechanism in machine vision helps a system focus on important parts of an image, much like how a person pays attention to key details in a scene. These attention mechanisms mimic human visual attention, allowing models to prioritize features and improve accuracy. Studies show that attention changes in neural activity can greatly boost object detection. In fact, models inspired by visual attention, like STRA-Net, achieve higher accuracy and robustness in vision tasks. Think of attention as a spotlight that guides the Attention Mechanism machine vision system to see what matters most.
Study (Author, Year) Subjects (Type & Number) Method Data Source Classification Task Reported Accuracy Borhani et al. (2018) Healthy adults, N=38 CNN EEG 2-class attentional state 73% Hosseini & Guo (2019) Healthy adults, N=2 CNN EEG Focusing vs mind wandering 91.78% Ho et al. (2019) Healthy adults, N=16 CNN fNIRS 3-class mental workload 65.43%
Key Takeaways
- Attention mechanisms help computer vision models focus on important parts of images, improving accuracy and efficiency.
- Different types of attention, like spatial, channel, temporal, and self-attention, allow models to capture key features, regions, or frames effectively.
- Attention improves many vision tasks such as object detection, image segmentation, medical imaging, and scene classification.
- Models using attention, like Vision Transformers and SENet, achieve higher accuracy and better performance than traditional methods.
- Adding attention mechanisms makes vision systems smarter and faster, helping them handle complex images and real-world challenges.
Attention Mechanism Machine Vision System
Definition
An attention mechanism machine vision system uses a special process to help computers focus on the most important parts of an image. In machine vision, attention mechanisms act like filters that highlight key features while ignoring less useful information. Researchers describe attention as a dynamic weight adjustment inspired by how people notice important things in a busy scene. The system changes the importance, or weight, of different image features as it processes them. This approach helps the computer vision model find patterns, objects, or details that matter most for the task. Attention mechanisms can work in different ways, such as focusing on certain channels, locations, or even time steps in a video. These methods help the attention mechanism machine vision system perform better in tasks like image classification, object detection, and segmentation. In deep learning, attention mechanisms guide the network to learn which parts of the image to look at, making the process more efficient and accurate. This dynamic focus marks a big step forward in machine learning and computer vision.
Analogy
Imagine walking into a crowded room. Your eyes scan the space, but your mind quickly picks out a friend waving at you. You focus on your friend and tune out the rest of the crowd. The attention mechanism machine vision system works in a similar way. It acts like a spotlight, shining on the most important parts of an image while leaving the background in the shadows. This spotlight helps the system understand what matters most, just as your brain helps you find your friend in a busy place. Some experts compare attention to a memory bank or a control system that decides where to look next. In computer vision, attention mechanisms can also act like a ‘what-is-it’ detector, quickly shifting focus to new or surprising details in an image. These analogies show how attention in computer vision mimics human thinking and perception, making machines better at understanding complex scenes.
Benefits
The attention mechanism machine vision system brings many benefits to computer vision and deep learning. First, it improves focus by letting the model concentrate on the most relevant parts of an image. This leads to higher accuracy in tasks like object detection and image segmentation. Studies show that attention mechanisms, such as self-attention and channel attention, help models capture complex patterns and global relationships in images. For example, Vision Transformers use self-attention to outperform traditional convolutional neural networks in many vision tasks. These models often achieve better results in medical imaging, where finding small or hidden details is important. Attention mechanisms also make the system more efficient. They reduce the amount of unnecessary information the model processes, saving time and computing power. Empirical results show that attention-based models, like CBAM and Residual Attention Networks, improve classification accuracy and tracking with only a small increase in computation. Fine-tuned models with attention mechanisms can boost F1 scores and other metrics, making them valuable for real-world applications. In summary, the attention mechanism helps in automating deep learning applications by making them smarter, faster, and more reliable.
Key Benefits of Attention Mechanisms in Machine Vision:
- Improved focus on important image regions
- Higher accuracy in classification, detection, and segmentation
- Better efficiency with less wasted computation
- Enhanced ability to capture complex patterns and global context
- Strong performance in challenging fields like medical imaging and autonomous driving
| Model Type | Test Set F1 Score | AUROC Range | AUPRC Range |
|---|---|---|---|
| Pre-trained (no fine-tune) | 0.24 – 0.49 | N/A | N/A |
| Fine-tuned ChromTransfer | 0.73 – 0.86 | 0.79 – 0.89 | 0.4 – 0.74 |
| Direct Training (Binary) | +0.13 (mean inc.) | N/A | N/A |
The attention mechanism machine vision system represents a major advance in computer vision and deep learning. It allows machines to see and understand images more like humans do, leading to better results across many applications.
How Attention Mechanisms Work
Dynamic Weighting
Dynamic weighting forms the core of the attention mechanism in computer vision. This process lets neural networks decide which parts of an image deserve more focus. The transformer model uses a mathematical formula called scaled dot-product attention. In this formula, the system compares different features using queries, keys, and values. The softmax function helps the model assign higher weights to important features and lower weights to less useful ones. For example, in a vision task, the attention mechanism can highlight the edges of an object while ignoring the background. Dynamic weighting also appears in advanced neural networks like DWNet, which combines convolutional and transformer branches. A feature fusion gate in DWNet adjusts channel weights, helping the model merge local and global features. Studies show that removing dynamic weighting from attention mechanisms reduces accuracy in tasks like fault diagnosis and person re-identification. Dynamic weighting improves interpretability and helps the model adapt to new data.
Tip: Dynamic weighting allows attention mechanisms to adapt to changing patterns in images, making computer vision models more flexible and accurate.
Queries, Keys, Values
The transformer model uses three main parts: queries, keys, and values. These are vectors created from the input image using learned weights. The query asks what the model should focus on. The key stores information about each part of the image. The value holds the actual data the model retrieves. The attention mechanism compares the query to each key, measuring how similar they are. The model then uses these scores to decide how much attention to give each value. This process helps neural networks focus on the most relevant parts of the image, just like a person searching for a friend in a crowd. Self-attention uses the same input for queries, keys, and values, allowing the model to find connections within the image itself.
Process Overview
The attention mechanism follows a clear process in computer vision tasks:
- The model splits the image into patches or features.
- It creates queries, keys, and values from these features.
- The transformer computes attention scores by comparing queries and keys.
- The softmax function turns these scores into attention weights.
- The model multiplies the values by these weights, highlighting important features.
- The output passes through layers like a multilayer perceptron for final predictions.
- Stacked attention blocks in the transformer help the model learn complex patterns.
- The model produces attention maps, showing which parts of the image it focused on.
This step-by-step process lets neural networks in deep learning and machine learning adaptively focus on what matters most in vision tasks. Attention mechanisms make computer vision models smarter, more accurate, and better at handling complex images.
Types of Attention Mechanisms in Vision
Spatial Attention
Spatial attention helps a vision model focus on specific regions in an image. This type of attention mechanism works like a spotlight, highlighting important areas while ignoring less useful parts. Researchers found that spatial attention improves accuracy and speeds up response times in tasks that require high spatial resolution. For example, a study showed that spatial attention increased performance in gap and vernier resolution tasks by helping the model process only the most relevant locations. In computer vision, spatial attention mechanisms allow systems to detect objects or features more effectively, especially in complex scenes.
Channel Attention
Channel attention guides a vision model to focus on the most important feature channels. Each channel in an image can represent different types of information, such as color or texture. Channel attention mechanisms assign higher weights to channels that matter most for the task. Experiments show that adding channel attention to models like TransT improves tracking accuracy and feature representation. For instance:
- The pyramid channel attention mechanism increased average overlap and precision on object tracking datasets.
- Adding more channel attention modules led to higher accuracy in speaker recognition and image classification.
- Channel attention also improved Top-1 accuracy on datasets like CIFAR-100 and ImageNet.
These results show that channel attention mechanisms help models learn which features to prioritize, boosting overall performance.
Temporal Attention
Temporal attention allows vision systems to focus on the most important frames in a video sequence. This attention mechanism works by assigning higher weights to frames that contain key actions or events. Temporal attention helps models skip unimportant frames, reducing computational load and improving accuracy. Studies show that temporal attention captures the flow and context of actions better than traditional methods. For example, models using temporal attention can detect action boundaries and highlight critical moments in sports or surveillance videos. This makes temporal attention essential for video analysis tasks.
Self-Attention
Self-attention enables a vision model to relate different parts of an image or sequence to each other. This attention mechanism compares every feature with every other feature, allowing the model to capture long-range dependencies. Recent research on full-range self-attention mechanisms shows that they improve performance on tasks like image classification and object detection without increasing computational cost. Self-attention mechanisms also allow parallel processing, making them efficient and scalable. Models using self-attention achieve higher accuracy and better handle complex visual data compared to traditional convolutional models.
Multi-Head Attention
Multi-head attention uses several attention mechanisms in parallel, with each head focusing on different aspects of the input. This approach helps the model capture diverse patterns and relationships in visual data. Benchmarks show that advanced multi-head attention models, like MoH-ViT-B, achieve higher accuracy on tasks such as ImageNet classification. Each attention head can specialize in recognizing different categories or features, leading to richer representations. Multi-head attention also improves efficiency and generalization, making it a powerful tool for handling complex vision tasks.
Tip: Choosing the right attention mechanism can help vision models balance accuracy and efficiency, especially in large-scale applications.
| Attention Mechanism | Focus Area | Key Benefit |
|---|---|---|
| Spatial | Image regions | Improves detection in complex scenes |
| Channel | Feature channels | Boosts feature selection accuracy |
| Temporal | Video frames | Highlights key moments in sequences |
| Self-Attention | All features | Captures long-range dependencies |
| Multi-Head | Multiple aspects | Enhances diversity and robustness |
Applications in Computer Vision

Object Detection
Attention plays a key role in object detection tasks. Models use attention to highlight important regions in an image, making it easier to find and classify objects. For example, the SFA attention mechanism in YOLOX-Nano increases mean Average Precision (mAP) from 73.26% to over 75%. This improvement comes with high inference speed, reaching 76.88 frames per second. Integrating attention after several feature layers in the YOLOX detector helps the model focus on critical features. The Multi-Head-Attention-Yolo method achieves a mAP of 50.7% on the DOTA dataset, outperforming other popular detectors.
| Method | mAP |
|---|---|
| Faster R-CNN | 44.1% |
| Swin Transformer Mask R-CNN | 46.9% |
| Yolov5 | 49.8% |
| Multi-Head-Attention-Yolo | 50.7% |
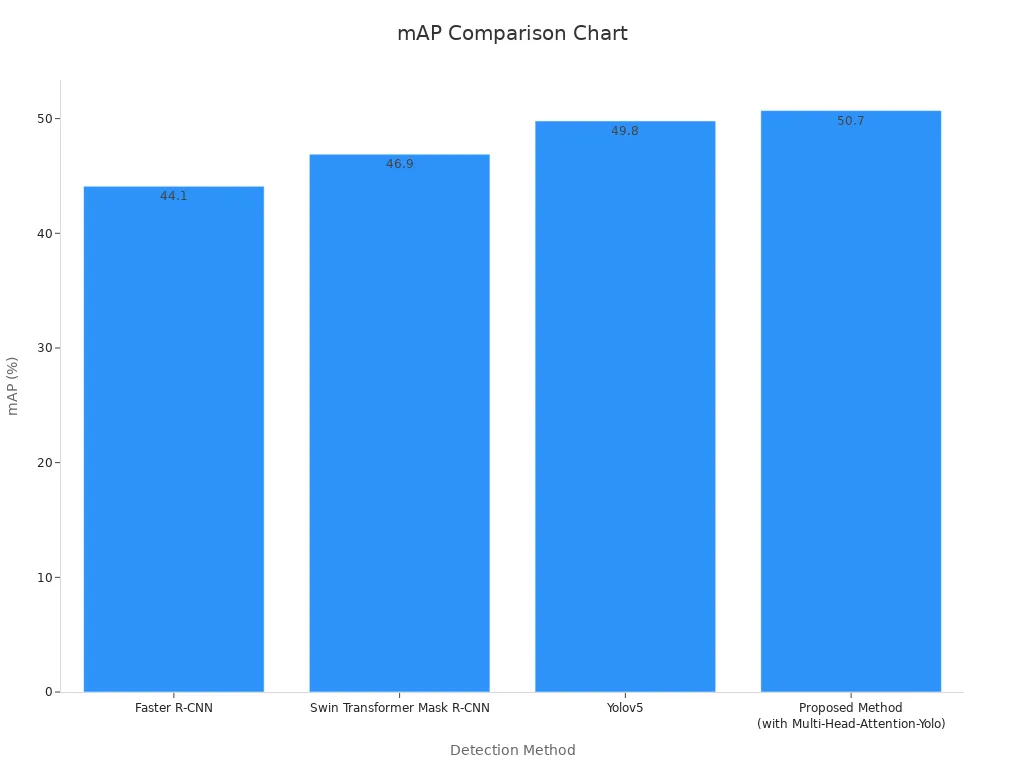
Image Segmentation
Image segmentation benefits from attention by allowing models to focus on the most informative parts of an image. The Mutual Inclusion of Position and Channel attention (MIPC) mechanism improves the Dice score from 77.48 to 80.00 and reduces the Hausdorff Distance, leading to more precise boundaries. This selective focus helps the network extract important features and improves classification accuracy in image recognition.
| Model Configuration | Dice Coefficient (DSC) | Hausdorff Distance (HD, mm) |
|---|---|---|
| Baseline (no attention) | 77.48 | 31.69 |
| MIPC-Net (with attention) | 79.28 | 25.27 |
| MIPC-Net + Skip-Residue | 80.00 | 19.32 |
Medical Imaging
Medical imaging uses attention to highlight critical regions and improve interpretability. Saliency maps, Class Activation Maps, and attention maps help radiologists see which parts of an image influence the model’s decision. Transformer-based models like EG-ViT and RadioTransformer use eye-gaze data from experts to guide focus, improving disease diagnosis in chest radiographs and X-rays. Clinical studies show that hierarchical attention models outperform other models on benchmarks such as Rad-ChestCT and Pub-Brain-5, with macro AUC improvements of 4.3%. Attention also helps identify model biases and errors, making medical AI more trustworthy.
- Attention mechanisms in medical imaging:
- Improve diagnostic accuracy
- Mimic expert visual search strategies
- Enhance trust and interpretability
Scene Classification
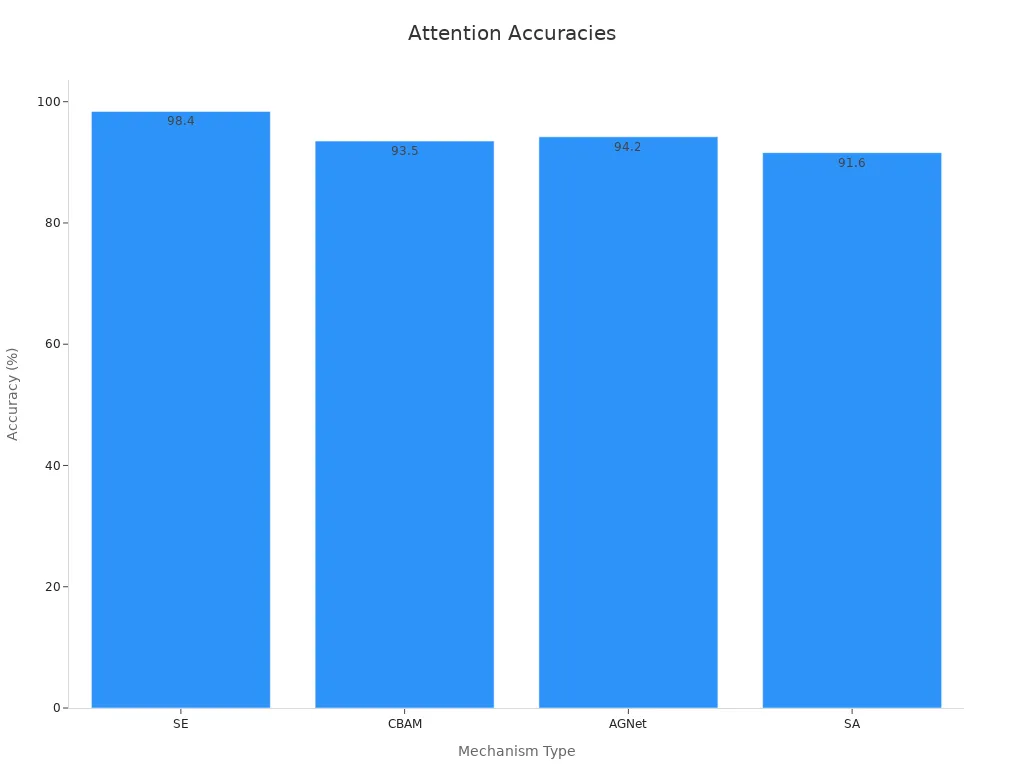
Scene classification tasks use attention to boost accuracy in image recognition. Channel-wise attention mechanisms like Squeeze-and-Excitation (SE) achieve an overall testing accuracy of 98.4%, higher than other methods. The table below shows the impact of different attention modules on classification metrics.
| Attention Mechanism | Overall Testing Accuracy (%) | AUC | Statistical Significance vs SE (p-value) |
|---|---|---|---|
| SE | 98.4 | 1.00 | Baseline: p < 0.05 |
| CBAM | 93.5 | ~0.993 | p = 0.002 |
| AGNet | 94.2 | ~0.992 | p = 0.006 |
| SA | 91.6 | ~0.988 | Worse than baseline |
| Baseline | ~92-93 | ~0.987 | Significantly lower than SE |
Attention mechanisms support a wide range of computer vision applications, making models more accurate, efficient, and interpretable.
Key Models Using Attention Mechanisms
Vision Transformers
Vision Transformers (ViT) have changed the way neural networks process images. These models use a transformer network to split an image into patches, then apply self-attention to capture relationships between all parts of the image. The transformer model allows ViT to focus on both local and global features. Large-scale benchmarks show that ViT achieves high accuracy on the ImageNet dataset, often outperforming traditional convolutional neural networks. ViT balances speed and memory use, even though self-attention has high computational demands. Researchers found that scaling the transformer model size is more effective than increasing image resolution. ViT stands out as a strong baseline for image classification tasks, showing how attention mechanisms can help neural networks learn from complex visual data.
| Metric | Vision Transformer (ViT) Performance | Comparison to CNNs and Other Models | Key Insight |
|---|---|---|---|
| Accuracy | High accuracy on ImageNet benchmark | Outperforms traditional CNNs | ViT is a strong baseline for image classification |
| Speed | Competitive inference speed | Remains Pareto optimal despite quadratic self-attention complexity | ViT balances speed and accuracy effectively |
| Memory Usage | Efficient memory usage | Hybrid attention-CNN models can be more memory efficient in some cases | ViT still remains preferred overall |
| Model Scaling | Larger ViT models more efficient than increasing image resolution | Scaling model size preferred over resolution increase | Contradicts common trends in efficient model evaluation |
| Number of Models | Benchmark includes over 45 models | ViT consistently on Pareto front | Comprehensive evaluation across many architectures |
A vision transformer uses the transformer model to apply attention to every patch, making it possible to capture global context in images.
SENet
Squeeze-and-Excitation Networks (SENet) introduce channel-wise attention to deep learning neural networks. SENet recalibrates neural responses by learning which channels are most important for a given task. This attention mechanism helps the network focus on the most informative features. In a study on tomato fruit classification, a hybrid ViT-SENet model reached a testing accuracy of 99.90%. SENet also improved medical imaging tasks, such as ankle fracture identification, by guiding the neural network to focus on critical regions. Feature visualization before and after SENet integration shows a clear shift in attention, making the model more reliable and interpretable. SENet demonstrates how attention mechanisms can boost both accuracy and efficiency in vision applications.
CBAM
The Convolutional Block Attention Module (CBAM) combines channel and spatial attention to refine features in convolutional neural networks. CBAM applies attention in two steps: first across channels, then across spatial locations. This attention model helps neural networks highlight important features while suppressing noise. Empirical studies show that CBAM improves classification accuracy with only a small increase in parameters. For example, on ImageNet-1K, CBAM reduced the Top-1 error rate more than SE and max pooling methods.
| Model Variant | Parameters (M) | GFLOPs | Top-1 Error (%) | Top-5 Error (%) |
|---|---|---|---|---|
| ResNet-50 (baseline) | 25.56 | 3.86 | 24.56 | 7.50 |
| ResNet-50 + AvgPool (SE) | 25.92 | 3.94 | 23.14 | 6.70 |
| ResNet-50 + MaxPool | 25.92 | 3.94 | 23.20 | 6.83 |
| ResNet-50 + AvgPool & MaxPool | 25.92 | 4.02 | 22.80 | 6.52 |
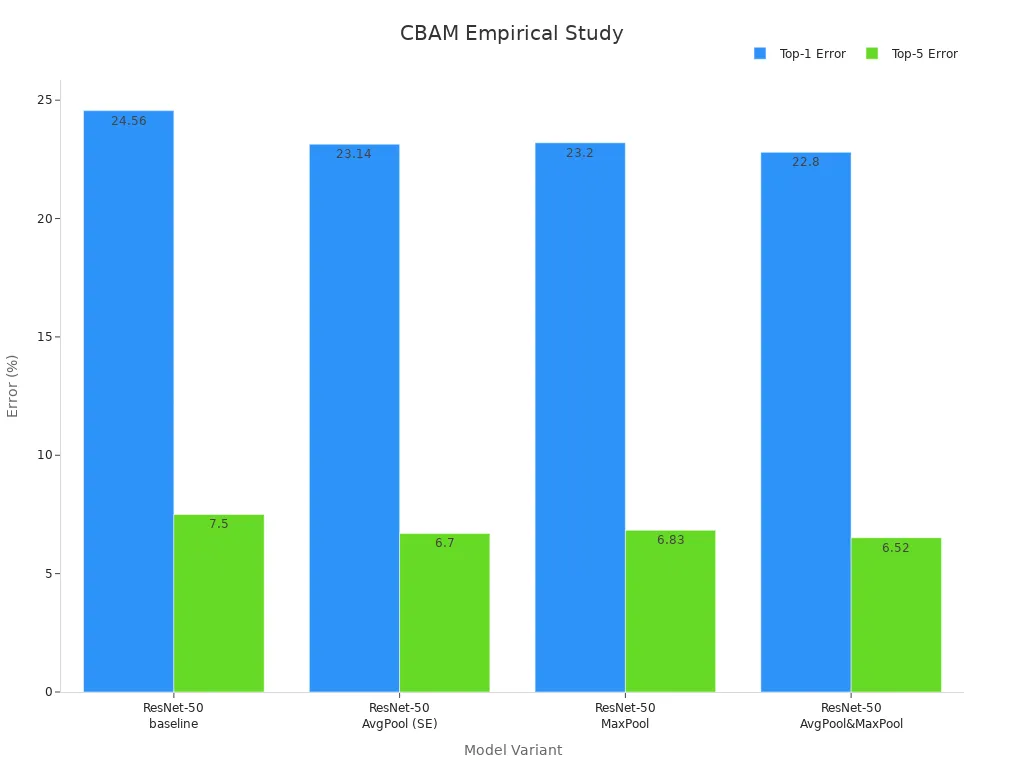
CBAM’s design allows neural networks to adaptively refine features, leading to better performance in deep learning tasks.
Residual Attention Networks
Residual Attention Networks (RA-Net) combine residual learning with attention mechanisms to improve deep learning neural networks. RA-Net uses a reverse attention branch to supervise lower-level features with high-level semantic information. This attention model helps bridge the gap between different layers in the network. Comparative studies show that RA-Net outperforms SE-Net and CBAM in both accuracy and efficiency, especially as networks get deeper.
| Backbone / Model | Parameter Increase | FLOPs Change | Top-1 Accuracy Improvement | Notes |
|---|---|---|---|---|
| ResNet18 + RA-Net | ~0 (comparable) | ~0 (comparable) | +1.0% | RA-Net outperforms SE-Net (+0.8%) and CBAM (+0.9%) with similar complexity |
| ResNet50 + RA-Net | Slight increase | Slight increase | +1.4% | RA-Net improves more than SE-Net (+1.1%) and CBAM (+1.2%) |
| ResNet101 + RA-Net | +0.03M | Minimal | +1.7% | RA-Net achieves higher accuracy gain with far fewer additional parameters than SE (+4.78M) and CBAM (+9.56M) |
| MobileNetV2 (0.5x) + RA-Net | Comparable | Comparable | +1.5% | RA-Net yields highest accuracy gain among SE (+0.8%) and CBAM (+1.0%) |
| Faster R-CNN (ResNet50 backbone) + RA-Net | +1.9% box AP increase | N/A | +1.9% box AP | RA-Net surpasses SE (+1.6%) and CBAM (+1.5%) with fewer added parameters |
| Mask R-CNN (ResNet50 backbone) + RA-Net | N/A | N/A | +1.7% box AP | RA-Net outperforms SE and CBAM (both +1.4%) |
RA-Net’s reverse attention mechanism allows the attention model to enhance both lightweight and heavyweight neural networks, making it a powerful tool in modern vision systems.
Attention has changed the way vision models work. These systems now focus on important details, which improves accuracy and makes results more reliable. Attention mechanisms help in many areas, such as medical imaging and autonomous driving. However, high computational costs and the need for large datasets remain challenges. Researchers continue to develop new attention models. As computational power grows, attention will make machine vision even more adaptable and intuitive.
FAQ
What is an attention mechanism in machine vision?
An attention mechanism helps a computer vision model focus on important parts of an image. The model learns to highlight key features, which improves accuracy and efficiency.
Why do machine vision systems need attention mechanisms?
Attention mechanisms help models ignore unimportant details. This focus allows the system to process images faster and make better decisions. Researchers see higher accuracy in tasks like object detection and image segmentation.
Can attention mechanisms work with videos?
Yes! Temporal attention lets models find important frames in a video. The system can spot key actions or events, which helps in sports analysis and security footage review.
Are attention mechanisms hard to add to existing models?
Many modern deep learning libraries support attention modules. Developers can add them to existing models with a few lines of code. Tutorials and open-source examples make the process easier for beginners.
See Also
Fundamental Principles Behind Edge Detection In Machine Vision
Why Triggering Plays A Crucial Role In Machine Vision
A Comprehensive Guide To Thresholding Within Machine Vision
Delving Into Presence Detection Technology For Machine Vision








