
The Actor-Critic machine vision system plays a crucial role in enhancing the capabilities of machine vision by enabling them to learn and adapt to changing environments. It combines reinforcement learning with vision-based tasks, allowing systems to make smarter decisions based on visual data. This approach helps machines process and interpret complex images more efficiently. For example, experiments show that optimizing the critic component with advanced methods like GWO improves performance significantly. These studies, which analyze thousands of iterations, highlight how Actor-Critic machine vision systems excel in solving visual challenges. By integrating learning into vision systems, this method ensures adaptability and precision in real-world applications.
Key Takeaways
- The Actor-Critic method helps machines see better by mixing decision-making with evaluation. This lets systems adjust to new situations.
- The actor part makes choices, and the critic checks them. Together, they form a loop that gets better over time.
- Tools like Advantage Function and Priority Experience Replay make Actor-Critic faster and steadier. This makes it good for real-time use.
- Actor-Critic systems are great at finding objects and guiding robots. They process visual data quickly and correctly.
- Even though it’s useful, it can be costly and tricky to keep stable. Solutions like target networks can fix these problems.
Understanding the Actor-Critic Algorithm
The Actor Component in Reinforcement Learning
The actor component focuses on decision-making. It determines the actions a system should take based on the current state. You can think of it as the "policy maker" that guides the system toward achieving its goals. The actor uses a policy, which is a mapping from states to actions, to maximize expected cumulative rewards.
In reinforcement learning, the actor updates its policy by interacting with the environment. For example, when a machine vision system detects objects, the actor decides how to classify or respond to them. The advantage actor-critic approach enhances this process by using the advantage function to refine the actor’s decisions. This ensures the system learns more effectively and adapts to complex scenarios.
Recent studies highlight the importance of the actor in reinforcement learning algorithms. Smaller actors often lead to performance degradation due to limited decision-making capabilities. Overfitting of critics and poor data collection further emphasize the need for robust actor components.
The Critic Component in Reinforcement Learning
The critic evaluates the actions taken by the actor. It estimates the value of a given state or action, helping the actor improve its policy. You can think of the critic as the "advisor" that provides feedback to the actor. This feedback is based on the expected cumulative rewards, which guide the actor toward better decisions.
The critic uses a value function to assess the quality of actions. For instance, in machine vision systems, the critic might evaluate how accurately an object is detected or recognized. By comparing the predicted outcomes with actual results, the critic helps the actor refine its policy.
Research has shown that advancements in the critic component significantly improve the effectiveness of the actor-critic algorithm. The Realistic Actor-Critic (RAC) framework demonstrated a tenfold increase in sample efficiency and a 25% improvement in performance compared to the Soft Actor-Critic. These findings highlight the critical role of the critic in reinforcement learning.
Collaboration Between Actor and Critic
The actor and critic work together to optimize the system’s performance. While the actor decides on actions, the critic evaluates them and provides feedback. This collaboration creates a reinforcement learning framework that continuously improves the policy.
The actor-critic method relies on this dynamic interaction to handle complex tasks. For example, in machine vision systems, the actor might identify objects, while the critic assesses the accuracy of identification. The actor then updates its policy based on the critic’s feedback, ensuring better performance over time.
Innovations like the Relative Importance Sampling (RIS) estimator further enhance this collaboration. RIS-off-PAC reduces variance and improves stability, enabling the actor-critic framework to achieve competitive performance against state-of-the-art benchmarks. Additionally, the PAAC method has shown faster convergence to optimal policies, reduced learning variance, and increased success rates in achieving desired outcomes.
Tip: The actor-critic algorithm‘s ability to adapt and learn from feedback makes it a powerful tool for machine vision systems.
How the Actor-Critic Algorithm Powers Machine Vision
Policy Optimization and Objective Function
The actor-critic algorithm relies on policy optimization to improve decision-making in machine vision systems. The actor component generates actions based on a policy, which is a set of rules guiding the system’s behavior. The critic evaluates these actions and provides feedback to refine the policy. This feedback loop ensures that the system learns to achieve an optimal policy over time.
In machine vision, policy optimization helps systems adapt to dynamic environments. For instance, when identifying objects in a cluttered scene, the actor adjusts its policy to focus on relevant features. The critic ensures that these adjustments lead to better outcomes. By continuously refining the policy, the actor-critic algorithm enables systems to handle complex visual tasks with greater accuracy.
The Role of the Advantage Function
The advantage function plays a crucial role in the advantage actor-critic framework. It measures how much better a specific action is compared to the average action in a given state. This information helps the actor prioritize actions that maximize rewards.
In machine vision, the advantage function allows the system to focus on high-value actions. For example, when analyzing a video, the system can prioritize frames with significant changes. This targeted approach improves efficiency and ensures that the system processes only the most relevant data.
By incorporating the advantage function, the actor-critic algorithm enhances learning efficiency. It reduces the time required to identify an optimal policy, making it a valuable tool for real-time applications.
Update Mechanisms for Actor and Critic
Efficient update mechanisms are essential for the actor-critic algorithm to function effectively. Recent advancements, such as the A2CPER algorithm, have significantly improved these mechanisms.
- A2CPER introduces a target network mechanism that delays parameter updates. This approach strengthens stability and ensures consistent training for both the actor and critic.
- A fixed temporal window reduces approximation errors, enhancing the reliability of updates.
- Priority Experience Replay (PER) improves sampling efficiency by replaying important experiences during training.
These innovations address common challenges like slow convergence and high volatility. They enable the actor-critic framework to maintain stability while achieving an optimal policy. In machine vision, these improvements translate to faster and more accurate processing of visual data.
Note: The actor-critic algorithm’s ability to optimize policies and adapt to feedback makes it a cornerstone of modern machine vision systems.
Applications of Actor-Critic in Machine Vision Systems
Object Detection and Recognition
Object detection and recognition are fundamental tasks in machine vision. The actor-critic machine vision system enhances these processes by enabling adaptive decision-making. The actor component identifies objects in an image, while the critic evaluates the accuracy of these identifications. This feedback loop ensures continuous improvement in object recognition performance.
For example, when analyzing a crowded image, the actor focuses on detecting objects of interest. The critic then assesses whether the detected objects match the expected outcomes. If discrepancies arise, the actor refines its policy to improve future detections. This iterative process allows the system to handle complex visual scenes with greater precision.
You can see the impact of this approach in real-world applications like facial recognition and medical imaging. In facial recognition, the actor-critic algorithm helps systems identify faces even in challenging conditions, such as poor lighting or occlusions. In medical imaging, it assists in detecting anomalies like tumors, ensuring accurate diagnoses.
Tip: By combining the strengths of value-based RL and policy optimization, the actor-critic machine vision system achieves remarkable accuracy in object detection and recognition tasks.
Autonomous Navigation and Robotics
Autonomous navigation and robotics rely heavily on the actor-critic machine vision system for decision-making in dynamic environments. The actor guides the agent’s movements, while the critic evaluates the outcomes to refine the navigation policy. This collaboration ensures that the agent adapts to changing conditions and avoids obstacles effectively.
Several advanced algorithms demonstrate the power of the actor-critic approach in robotics. The table below highlights key findings from recent research:
| Evidence Description | Key Findings |
|---|---|
| SANG Algorithm | Focuses on socially aware navigation using an actor-critic approach, improving decision-making in group dynamics. |
| DARC Algorithm | Utilizes a dual-critic structure to improve value estimation, reducing bias and enhancing stability in policy learning. |
| Regularization Mechanism | Ensures consistency in Q-value estimates, crucial for effective navigation in dynamic environments. |
| Soft Update Mechanism | Balances exploration and exploitation, improving learning efficiency. |
| A2C Learning Technique | Implements an advantage function to measure TD Error, guiding agents in decision-making for navigation. |
| Voice in Head Actor-Critic Framework | Incorporates feedback from a Critic to refine the Actor’s decisions, enhancing navigation capabilities. |
These innovations enable robots to navigate complex terrains, interact with humans safely, and perform tasks autonomously. For instance, delivery robots use the actor-critic algorithm to plan routes, avoid obstacles, and deliver packages efficiently. Similarly, autonomous vehicles rely on this system to make split-second decisions, ensuring passenger safety.
Video Analysis and Surveillance
Video analysis and surveillance have become more efficient with the integration of the actor-critic machine vision system. This system processes video frames in real time, detecting objects, tracking movements, and identifying events of interest. The actor selects the most relevant frames for analysis, while the critic evaluates the accuracy of the detected events.
Companies like IBM are leveraging this technology to develop advanced surveillance systems. These systems not only monitor scenes automatically but also manage surveillance data, perform event-based retrieval, and provide real-time alerts. This capability enhances the overall efficiency and effectiveness of video analysis.
Key operations in video surveillance include:
- Detecting and tracking objects and people across video frames.
- Calculating spatio-temporal relations based on their positions over time.
- Enhancing event detection using predefined or learned models.
The actor-critic algorithm ensures that these operations are performed accurately and efficiently. For example, in a crowded public space, the system can identify suspicious activities and alert authorities in real time. This proactive approach improves public safety and reduces response times.
Note: The actor-critic machine vision system’s ability to process large volumes of video data makes it an invaluable tool for modern surveillance applications.
Advantages and Challenges of Actor-Critic in Machine Vision
Benefits of Actor-Critic in Vision Systems
The actor-critic algorithm offers several benefits for machine vision systems. Its ability to combine decision-making and evaluation ensures continuous improvement during training. This makes it highly effective for handling complex visual tasks. For example, the actor-critic method allows systems to adapt to dynamic environments by refining their policy based on real-time feedback.
You can also rely on this approach to optimize resource usage. By focusing on high-value actions, the actor-critic framework reduces unnecessary computations. This efficiency is particularly valuable in applications like autonomous navigation and video surveillance, where real-time processing is critical.
Another advantage lies in its versatility. The actor-critic algorithm supports both policy-based RL and value-based methods, making it suitable for a wide range of machine vision tasks. Whether you are working on object detection or robotics, this method provides a robust foundation for learning and decision-making.
Challenges in Implementation
Despite its advantages, implementing the actor-critic algorithm in machine vision systems presents challenges. One major issue is the high computational cost during training. The algorithm requires frequent updates to both the actor and critic components, which can strain hardware resources.
Another challenge involves stability. The actor-critic framework relies on a delicate balance between exploration and exploitation. Without proper tuning, the training process may become unstable, leading to suboptimal policies.
Data efficiency is another concern. Training agents often require large datasets to achieve reliable performance. This can be a limitation in scenarios where labeled data is scarce or expensive to obtain.
Solutions to Overcome Challenges
Several strategies can address these challenges effectively. For instance, techniques like Priority Experience Replay (PER) improve data efficiency by prioritizing important experiences during training. This ensures that the system learns from the most relevant data, reducing the need for extensive datasets.
Advancements in reinforcement learning have also introduced mechanisms to enhance stability. The A2CPER algorithm, for example, uses a target network to delay parameter updates, ensuring consistent training. Similarly, soft update mechanisms balance exploration and exploitation, improving learning efficiency.
Experimental results further support these solutions. Studies on network threat mitigation show that reinforcement learning-based strategies can reduce attack probabilities and resource costs. In HVAC control, model-free algorithms like Soft Actor Critic achieve a 10% reduction in energy consumption while maintaining performance. These findings highlight the effectiveness of proposed solutions in real-world applications.
By adopting these strategies, you can overcome the challenges of implementing the actor-critic method, unlocking its full potential for machine vision systems.
Variants of Actor-Critic Algorithms in Machine Vision
Asynchronous Advantage Actor-Critic (A3C)
The asynchronous advantage actor-critic algorithm is a powerful variant that excels in machine vision tasks. It uses multiple agents to interact with the environment simultaneously, which speeds up training and improves learning efficiency. This approach allows the system to explore diverse scenarios, making it highly effective for complex visual environments.
A3C has demonstrated remarkable performance in various applications.
- It achieved state-of-the-art results across multiple games, completing training in half the time compared to earlier methods.
- After just 12 hours of training, A3C reached 75% to 90% of human performance in learning motor control policies.
- It also outperformed many existing models in detecting anomalies across three benchmark datasets.
This algorithm’s ability to handle parallel processing and adapt quickly makes it a valuable tool for machine vision systems.
Proximal Policy Optimization (PPO)
Proximal policy optimization is another widely used actor-critic variant. It simplifies the optimization process by ensuring that policy updates remain within a safe range. This prevents drastic changes that could destabilize the learning process. PPO is particularly effective in tasks requiring fine-tuned decision-making.
In machine vision, PPO helps systems adapt to dynamic environments while maintaining stability. For example, it can optimize object detection policies in real-time, ensuring accurate results even in challenging conditions. Its balance between exploration and exploitation makes it a reliable choice for applications like autonomous navigation and video analysis.
Deep Deterministic Policy Gradient (DDPG)
Deep deterministic policy gradient is designed for continuous action spaces, making it ideal for tasks like robotic control and autonomous driving. It combines the actor-critic framework with deep learning to handle high-dimensional inputs, such as images or videos.
Research highlights DDPG’s success in vision systems:
| Algorithm | Success Rate |
|---|---|
| SAC | 92.3% |
| PPO | 89.7% |
| DDPG | 85.2% |
| Q-learning | 78.9% |
Further improvements to DDPG have enhanced its performance:
| DDPG Variant | Success Rate |
|---|---|
| Original DDPG | 40-50% |
| DDPG with improved reward | 60-70% |
| DDPG with improved experience pool | 60-70% |
| Hybrid improved DDPG | ~90% |
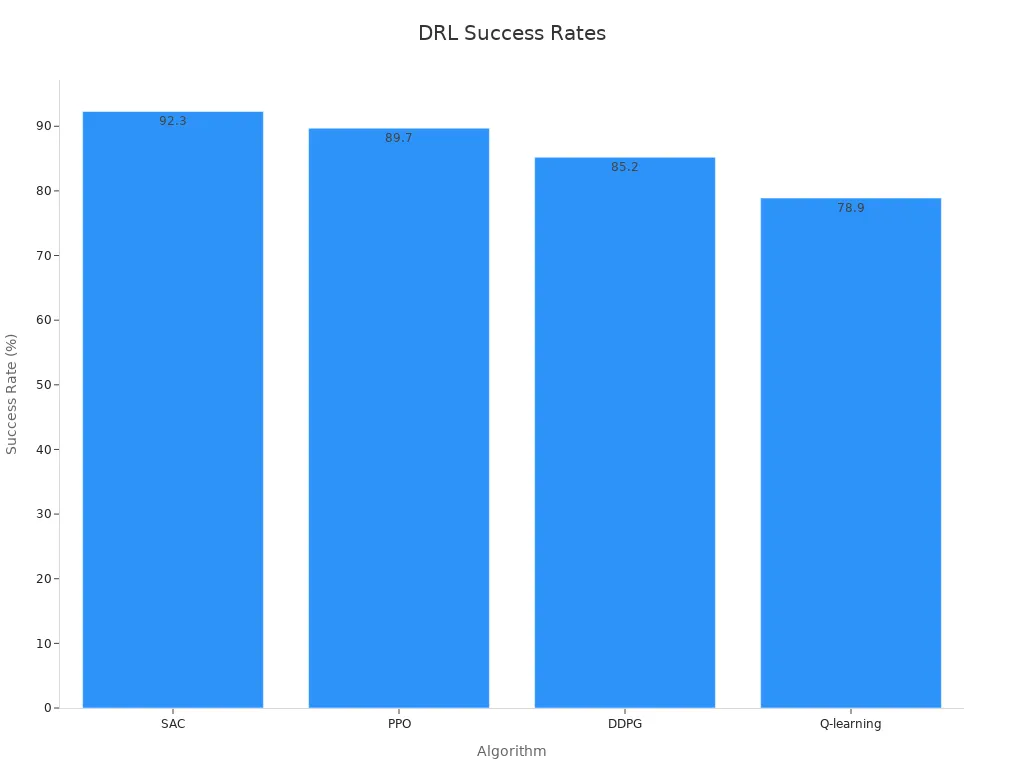
These advancements make DDPG a competitive option for machine vision systems, especially in scenarios requiring precise control and decision-making.
The Actor-Critic algorithm plays a pivotal role in advancing machine vision systems. It combines policy search with learned value functions, enabling systems to learn from returns and temporal difference errors. This approach has scaled from simulations to real-world applications like robotic visual navigation.
- Actor-Dueling-Critic (ADC) methods improve efficiency in continuous control tasks.
- ADC also excels in obstacle avoidance for sensor-based robots, a critical aspect of visual processing.
These advancements show how Actor-Critic algorithms can revolutionize visual tasks. You can explore this field further to unlock its full potential in real-world applications.
FAQ
1. How does the Actor-Critic algorithm differ from other reinforcement learning methods?
The Actor-Critic algorithm combines two components: the actor for decision-making and the critic for evaluation. Unlike other methods, it uses feedback loops to refine policies continuously, making it more adaptive for complex tasks like machine vision.
2. Can the Actor-Critic algorithm handle real-time applications?
Yes, it excels in real-time scenarios. Efficient update mechanisms, such as Priority Experience Replay (PER), ensure quick learning and decision-making. This makes it ideal for applications like autonomous navigation and video surveillance.
3. What makes the advantage function important in Actor-Critic systems?
The advantage function helps prioritize actions that yield higher rewards. It improves learning efficiency by focusing on valuable decisions. In machine vision, this ensures systems process relevant data, enhancing accuracy and speed.
4. Are Actor-Critic algorithms suitable for robotics?
Absolutely! They enable robots to adapt to dynamic environments. Algorithms like DDPG and A3C optimize robotic control and navigation, ensuring precise movements and obstacle avoidance in real-world scenarios.
5. What challenges should you expect when implementing Actor-Critic algorithms?
You may face high computational costs and stability issues during training. Data efficiency can also be a concern. Solutions like target networks and PER help overcome these challenges, ensuring reliable performance.
See Also
How Image Recognition Influences Quality Control in Machine Vision
Understanding Guidance Machine Vision’s Importance in Robotics
An Overview of Computer Vision Models and Machine Vision









