
Active learning helps computer vision systems learn efficiently by selecting the most useful images for labeling. In many machine vision projects, data labeling takes a lot of time and money. Teams often need thousands of labeled images to train accurate models. Manual data labeling can lead to errors and slow progress. Active learning solves this by picking only the most important samples for annotation, which cuts costs and boosts accuracy.
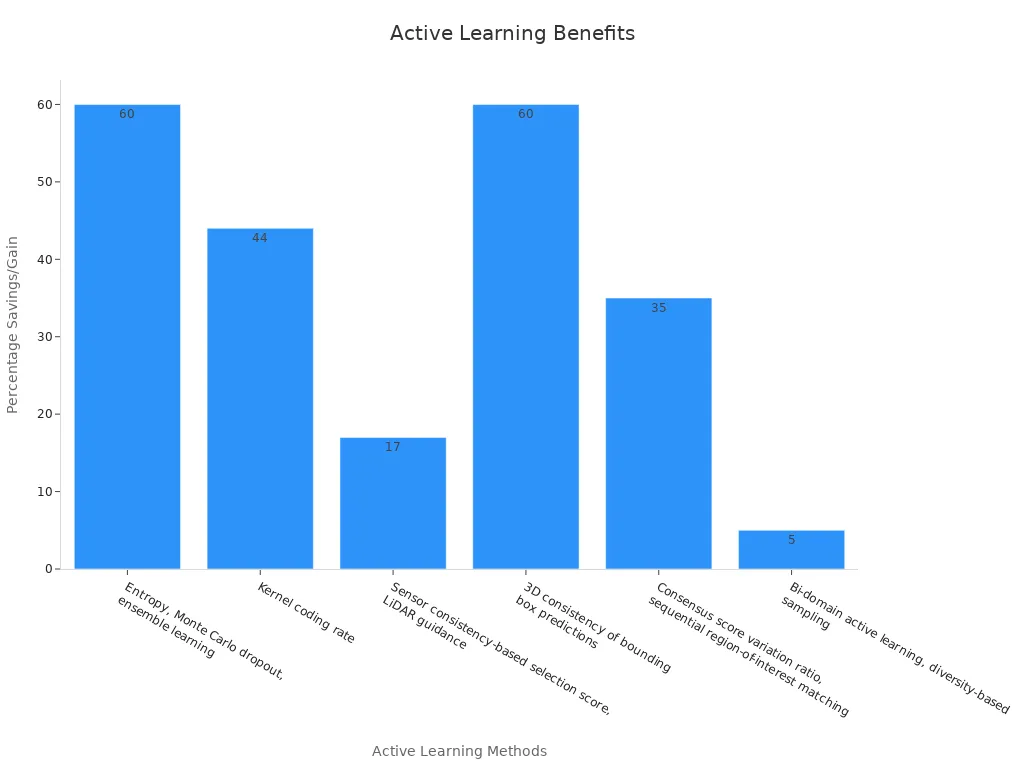
For example, studies show that using active learning on large datasets like KITTI and Waymo can cut data labeling costs by up to 60% without losing performance. These savings make active learning a key part of any Active Learning Strategy machine vision system. Statistical tools such as Area Under the Margin and Learning Loss help computer vision models find hard or mislabeled images. By focusing on these samples, active learning speeds up training and improves results.
Key Takeaways
- Active learning helps machine vision models learn faster by selecting only the most useful images for labeling, saving time and reducing costs.
- The iterative process of active learning improves model accuracy by focusing on uncertain or hard-to-classify images and retraining the model repeatedly.
- Main active learning strategies include pool-based, stream-based, and membership query, each helping models learn efficiently from different types of data.
- Querying frameworks like uncertainty sampling and query-by-committee guide models to pick the most informative images, boosting performance and reducing labeling effort.
- Strong annotation workflows and human-in-the-loop systems ensure high-quality labeled data, which is essential for building reliable and accurate vision models.
Active Learning Overview
Definition
Active learning is a method in machine learning that helps models learn from fewer labeled images. Instead of labeling every image, the model picks the most useful images for humans to label. This process saves time and money. In supervised learning, models need many labeled images to learn patterns. Active learning changes this by focusing on the most important images. The model asks for labels only when it is unsure about an image. This approach helps build better computer vision systems with less effort.
Researchers have found that active learning uses several strategies to choose images. Pool-based sampling selects images from a large group when the model feels uncertain. Stream-based sampling checks each image as it comes in and asks for a label if needed. Membership query synthesis creates new images to help the model learn when there is not enough training data. These methods help the model learn faster and use fewer labeled images.
Note: Active learning works best when the model can measure its own uncertainty. This way, it can pick images that will help it learn the most.
Importance in Vision Systems
Active learning plays a key role in computer vision. Computer vision models often need thousands of labeled images for supervised learning. Labeling all these images takes a lot of time and resources. Active learning reduces this burden by picking only the most helpful images for labeling. This makes the process more efficient and less expensive.
Empirical studies show that active learning improves the accuracy of computer vision systems. For example, using uncertainty sampling and query-by-committee methods, models can focus on images that are hard to classify. This leads to better results, especially for rare classes in images. In medical imaging, active learning helps models learn from fewer labeled images while still reaching high accuracy. In fields like object detection and autonomous vehicles, active learning speeds up the process of building strong models with less training data.
Active learning also supports supervised learning by making sure the training data covers many types of images. This helps the model generalize better to new images. As a result, computer vision systems become more reliable and effective.
Active Learning Strategy Machine Vision System

Iterative Process
An active learning strategy machine vision system uses an iterative process to improve model performance. The cycle begins when the model reviews a large pool of unlabeled images. It selects the most uncertain or informative images for data labeling. Human annotators then label these images. The system adds the new labeled images to the training data. The model retrains on this updated set. This process repeats many times.
Each round of this cycle helps the model learn from the most valuable images. The model focuses on images where it struggles to make accurate predictions. By doing this, the system avoids wasting resources on easy or redundant images. The iterative process continues until the model reaches the desired accuracy or the labeling budget runs out.
Tip: Iterative active learning helps teams use their data labeling resources wisely. They can achieve high accuracy with fewer labeled images.
Researchers have tested this approach using different methods. For example, a study used a Query by Committee method with ten models. Each model had different settings. The system picked new training points based on how much the models disagreed. This method improved model performance with each cycle. The study compared this active learning approach to training on all data and random sampling. The results showed that iterative active learning worked better and used less labeled data.
The table below shows how different methods perform in machine vision tasks:
| Method | Performance Metric | Dataset | Result |
|---|---|---|---|
| Active learning framework | F1 score | 40% labeled training data | 0.70 |
| Transformer-PPO-based RL | AUC score | Classification task | 0.89 |
| Auto-weighted RL method | Accuracy | Breast ultrasound images | 95.43% |
This table shows that an active learning strategy machine vision system can reach strong accuracy with much less labeled data. For example, the active learning framework achieved an F1 score of 0.70 using only 40% of the training data. This proves that the iterative process saves time and effort in data labeling while keeping model performance high.
Data Flywheel Effect
The data flywheel effect describes how an active learning strategy machine vision system gets better over time. As the model trains on more informative images, it becomes smarter at picking which images to label next. Each cycle adds new, valuable images to the training data. This makes the model stronger and more accurate with every round.
Focusing on the most informative images reduces the total data labeling effort. The system does not need to label every image. Instead, it targets images that help the model learn the most. Studies in computer vision show that this approach keeps accuracy high while lowering the number of labeled images needed. For example, researchers found that selecting uncertain samples for annotation leads to efficient use of resources. The Cost-Effective Active Learning (CEAL) method combines uncertain samples with confident pseudo-labeled images. This method improves training efficiency and accuracy even more.
Note: The data flywheel effect means that every new batch of labeled images makes the model better at choosing the next set of images. This creates a positive feedback loop.
In clinical decision support, active learning frameworks use uncertainty scores to pick which images to label. The model adds these images to the training set and retrains. This cycle repeats, and the model’s accuracy improves with each round. The process ensures that the system uses fewer labeled images but still reaches high accuracy.
An active learning strategy machine vision system uses this flywheel effect to build better models faster. Teams can focus their efforts on labeling training data that matters most. This leads to higher accuracy, less wasted effort, and faster progress in machine learning projects.
Active Learning Strategies
Active learning strategies help machine vision systems choose which images to label. These strategies guide algorithms to select the most useful images, making the learning process faster and more efficient. Researchers use different active learning techniques to reduce the number of labeled images needed for training. The three main strategies are pool-based, stream-based, and membership query.
Pool-Based
Pool-based active learning is one of the most common active learning strategies. In this approach, the algorithm starts with a large pool of unlabeled images. The model reviews all the images and selects the ones it finds most uncertain or informative. Human annotators then label these selected images. The model adds the new labels to its training set and retrains. This process repeats until the model reaches the desired accuracy.
Researchers often use pool-based active learning in vision systems because it works well with large datasets. The model can scan thousands of images and pick only those that help it learn the most. For example, a study by Liang and Grauman introduced a setwise active learning strategy. Their method selects sets of images for annotation by balancing informativeness and diversity. They compared their approach to five baseline strategies, including random selection and margin-based selection. The setwise method reduced annotation costs by about 39% compared to passive approaches. This shows that pool-based active learning strategies can save time and resources.
Performance metrics help measure the success of pool-based algorithms. The learning curve shows how quickly the model improves as it labels more images. Annotation cost measures the time and effort needed to label the selected images. These metrics help teams decide which active learning techniques work best for their projects.
Pool-based active learning helps models learn faster by focusing on the most valuable images in a large dataset.
Stream-Based
Stream-based active learning strategies work differently. In this approach, images arrive one at a time, like a stream. The algorithm decides for each image whether to ask for a label or skip it. This method suits situations where images come in continuously, such as from cameras or sensors.
Stream-based algorithms must make quick decisions. They cannot look at all the images at once. Instead, they use rules to decide if an image is worth labeling. For example, if the model feels uncertain about an image, it asks for a label. If the image seems easy, the model skips it. This process helps the model focus on learning from challenging images.
Researchers use stream-based active learning techniques in real-time vision systems. These systems need to process images quickly and cannot wait for large batches. Performance metrics like mean squared error (MSE) and annotation cost help measure how well stream-based algorithms work. Teams compare the model’s MSE before and after labeling new images to see how much the model improves.
- Initial MSE: Shows model error before labeling new images.
- Updated MSE: Shows model error after labeling.
- Improvement: Measures how much the model gets better.
Stream-based active learning strategies help models adapt to new data and improve over time.
Membership Query
Membership query is another important active learning strategy. In this approach, the algorithm creates new images or modifies existing ones. The goal is to generate images that challenge the model and help it learn better. The model then asks human annotators to label these synthetic images.
Membership query algorithms use different techniques to create new images. Some algorithms change parts of existing images, while others use generative models to make entirely new ones. This strategy helps the model explore areas of the data it has not seen before.
Researchers use membership query active learning techniques when the available images do not cover all possible cases. For example, in medical imaging, the model might create images showing rare conditions. Human experts then label these images, helping the model learn about rare cases.
Performance metrics for membership query include the learning curve and mean squared error. These metrics show how quickly the model improves as it labels new, challenging images. The Sagacify article highlights that membership query strategies can help address challenges like unreliable confidence estimates and the need for diverse training data.
Membership query active learning strategies allow models to learn from new and rare images, making them more robust.
Active learning strategies play a key role in machine vision systems. By using pool-based, stream-based, and membership query approaches, teams can train models with fewer labeled images. These strategies help algorithms focus on the most informative images, reduce annotation costs, and improve model accuracy. Comparative studies show that combining informativeness and diversity in sample selection leads to better results. Performance metrics like learning curves, annotation cost, and mean squared error help researchers evaluate the effectiveness of different active learning algorithms.
Querying Frameworks
Active learning algorithms use different querying frameworks to select the best images for labeling. These frameworks help improve performance by focusing on the most useful data. The three main frameworks are uncertainty sampling, query-by-committee, and diversity sampling.
Uncertainty Sampling
Uncertainty sampling is one of the most popular active learning techniques. The model picks images where it feels least confident. It measures uncertainty using methods like entropy or the margin between top predictions. When the model cannot decide between classes, it asks for a label. This approach helps the model learn from challenging examples and boosts performance quickly. Research shows that uncertainty-based algorithms, such as least confidence and margin sampling, often outperform other methods in annotation efficiency and model performance. These algorithms help reduce the number of labeled images needed for strong results.
Query-by-Committee
Query-by-Committee (QBC) uses a group of models, called a committee, to make decisions. Each model in the committee reviews the same image and votes on the label. The system selects images where the committee members disagree the most. This disagreement signals that the image is hard to classify. QBC captures different viewpoints and helps the model learn from diverse examples. Studies by Seung et al. (1992) and Cohn et al. (1994) show that QBC improves model performance by focusing on samples with high disagreement. This method works well in active learning algorithms for vision tasks.
Diversity Sampling
Diversity sampling selects images that are different from those already labeled. The goal is to cover as much of the data space as possible. This reduces redundancy and helps the model learn from a wide range of examples. Algorithms use clustering or similarity measures to find diverse samples. Research by Brinker (2003) and others found that diversity-based algorithms are efficient and model-independent. However, some studies report that diversity sampling alone may not match the performance of uncertainty sampling. Combining both strategies remains an open area in active learning techniques.
Tip: Combining uncertainty and diversity sampling can help balance learning from hard and unique examples.
| Query Strategy | Description | Key References and Notes |
|---|---|---|
| Uncertainty Sampling | Selects samples where the model is least confident, often measured by entropy or margin of predictions. | Implemented via Query by Committee (QBC) using a voting classifier with multiple models to capture disagreement. |
| Query-by-Committee (QBC) | Uses a committee of diverse models trained on the same data; selects samples with highest disagreement. | Based on Seung et al. (1992) and formalized by Cohn et al. (1994); voting entropy quantifies uncertainty. |
| Diversity Sampling | Ensures selected samples are well-distributed in feature space to reduce redundancy. | Integrated with uncertainty sampling to improve representativeness; explored by Brinker (2003) and others. |
These querying frameworks help active learning algorithms improve performance, reduce labeling costs, and build better models for machine vision systems.
Deep Learning Integration
Challenges
Deep learning models have changed how people use supervised learning in vision systems. These models need a lot of labeled data for training. Active learning helps reduce the number of labeled images, but deep learning brings new challenges. Training deep neural networks takes a long time and uses a lot of computer power. Each time the model adds new labeled data, it must retrain. This process can slow down the whole system.
Supervised learning with deep models also faces problems with uncertainty. Sometimes, the model cannot tell if it is making a good choice. This makes it hard to pick the best images for labeling. Overfitting can happen if the model trains too much on a small set of labeled images. This hurts performance on new data. Researchers must find ways to balance training time, data size, and model accuracy.
Note: Deep learning models often need special hardware for fast training. Teams should plan for this when building active learning systems.
Hybrid Approaches
Hybrid approaches combine different methods to improve supervised learning in vision systems. Some teams use both uncertainty sampling and diversity sampling during training. This helps the model learn from hard and unique images. Other teams mix active learning with semi-supervised learning. The model uses labeled images for training and also learns from unlabeled images.
Hybrid methods can boost performance by making the most of every labeled image. For example, a team might use pseudo-labeling. The model guesses labels for easy images and uses real labels for hard ones. This reduces the need for human labeling and speeds up training. Researchers also use transfer learning to start with a model trained on a big dataset. They then use active learning to fine-tune the model for a new task.
Hybrid approaches help supervised learning systems reach high performance with less data and faster training. These methods make machine vision systems smarter and more efficient.
Practical Considerations
Annotation Workflows
Successful machine vision projects depend on strong annotation workflows. Teams need to manage data labeling with care to build high-quality training data. A mix of tools, clear guidelines, and expert review helps keep the process efficient. The table below shows key aspects that improve annotation and their effects on machine learning models:
| Key Aspect | Importance / Role | Effect on ML Models |
|---|---|---|
| Variety in Data | Prevents bias, ensures real-world applicability | Enhances model generalization and fairness |
| Data Annotation Tools | Critical for efficient and accurate tagging | Improves annotation speed and quality |
| Human Expertise | Adds contextual understanding | Increases annotation accuracy and nuance |
| Active Learning Techniques | Speeds up annotation by focusing on informative samples | Accelerates model training and accuracy |
| Clear Guidelines | Maintains consistency and quality | Reduces errors and bias in training data |
| Quality Assurance Protocols | Regular reviews and feedback cycles | Ensures reliable and unbiased annotations |
| Collaborative Annotation | Real-time teamwork and error correction | Enhances data quality and model reliability |
Statistical results from real-world projects show that annotation accuracy can reach 77% on small data subsets. Weighted average precision, recall, and F1-score also reach 0.77, which supports balanced and reliable annotation for supervised learning.
Human-in-the-Loop
Human-in-the-loop systems play a vital role in data labeling for machine vision. Experts review and correct labels for images, which boosts the quality of training data. These systems use feedback cycles and regular checks to catch errors early. Teams often use collaborative annotation, where several people work together to label images and fix mistakes in real time. This teamwork improves both speed and quality. Human expertise adds context that automated systems may miss, making the final dataset more accurate and useful for training.
Tip: Clear guidelines and regular quality checks help teams avoid bias and keep annotation standards high.
Measuring Effectiveness
Teams must measure the effectiveness of active learning in real-world machine vision projects. They track how well the model learns from new images and how much data labeling effort drops over time. Studies show that active learning, when combined with guided discovery and instant AI feedback, can improve learning outcomes by up to four times compared to hands-on activity alone. This approach helps models adapt to new data and handle changes in the environment. By focusing on the most informative images, active learning reduces labeling costs and keeps model accuracy high. Teams also use metrics like precision, recall, and F1-score to check the quality of training data and model performance.
Common pitfalls include poor annotation quality, lack of clear guidelines, and not updating training data often enough. Teams should set up regular reviews, use strong annotation tools, and keep humans involved in the loop. These steps help maintain high-quality data labeling and effective training for machine vision systems.
Active learning gives machine vision systems a smarter way to learn. Teams see faster results because active learning reduces the number of images that need labels. This method helps models reach high accuracy with less effort. Some challenges remain, like setting up strong annotation workflows and keeping human experts involved. Many experts expect active learning to grow as deep learning improves. Readers can try active learning in their own projects to save time and boost results.
FAQ
What is the main benefit of active learning in machine vision?
Active learning helps teams label fewer images. The model learns faster by focusing on the most useful data. This approach saves time and money while improving accuracy.
How does active learning choose which images to label?
The model checks which images confuse it the most. It then asks humans to label those images. This process helps the model learn from hard examples.
Can active learning work with deep learning models?
Yes, active learning supports deep learning. Teams often use special tools and hardware to speed up training. Combining active learning with deep learning helps build strong vision systems.
What challenges do teams face when using active learning?
Teams may face issues like poor annotation quality or slow retraining. They need clear guidelines and regular checks. Good tools and teamwork help solve these problems.
See Also
Understanding Few-Shot And Active Learning In Machine Vision
Ways Deep Learning Improves Performance Of Machine Vision
The Role Of Synthetic Data Within Machine Vision Systems









