
Image segmentation in a machine vision system lets a machine separate an image into parts, so it can find each object and understand what is happening. This process helps machines in computer vision tasks, such as detection of objects and scene analysis. In real world applications, segmentation enables machines to inspect hundreds of parts per minute, spot defects with over 99% accuracy, and reduce downtime by 25%.
- The SA-1B Dataset offers over 1 billion masks for training, helping machines recognize objects in many settings.
- Segmentation models like U-Net and Mask R-CNN help machines find small abnormalities and guide autonomous vehicles to see objects like pedestrians and road signs.
Image Segmentation machine vision system technology opens the door for more accurate, fast, and reliable object analysis.
Key Takeaways
- Image segmentation helps machines divide images into parts to identify and analyze objects accurately.
- Different types of segmentation—semantic, instance, and panoptic—serve unique purposes in recognizing and counting objects.
- Machine vision systems use segmentation to improve inspection speed, accuracy, and reliability in industries like manufacturing and healthcare.
- Deep learning methods like U-Net and Mask R-CNN offer higher accuracy but need more data and computing power than traditional techniques.
- Beginners can start learning image segmentation using free tools and simple projects, building skills for real-world computer vision applications.
Image Segmentation in Machine Vision
What Is Image Segmentation?
Image segmentation is a process in computer vision where a machine divides an image into smaller parts. Each part, or segment, represents a different object or region. This helps the machine see where one object ends and another begins. For example, in a photo of a street, segmentation can separate cars, people, and road signs. The machine can then focus on each object for further analysis.
Segmentation uses different techniques to group pixels that look similar. Some methods use color, texture, or shape. Others use advanced computer vision models that learn from many images. These models help the machine find the edges of objects, even when they overlap or have complex shapes.
Researchers use several metrics to measure how well segmentation works. The table below shows common metrics and what they mean:
| Metric / Criterion | Description / Use Case | Notes / Considerations |
|---|---|---|
| Dice Similarity Coefficient (DSC) | Measures overlap between predicted and ground truth segmentation; widely used in medical image segmentation | Good for imbalanced classes; focuses on true positives |
| Intersection-over-Union (IoU) | Measures ratio of intersection over union of predicted and ground truth regions | IoU threshold should be clearly defined |
| F1-score | Harmonic mean of precision and recall; related to DSC and IoU | Specify averaging strategy and IoU threshold |
| Sensitivity and Specificity | Measure true positive rate and true negative rate respectively | Can be misleading in imbalanced scenarios |
| Accuracy | Overall correctness of classification | Not always reliable for imbalanced tasks |
| Cohen’s Kappa | Measures agreement between predicted and ground truth beyond chance | Useful for assessing reliability |
| Average Hausdorff Distance (AHD) | Measures spatial discrepancy between contours | Important for exact contour evaluation |
Tip: When evaluating segmentation, always check if the metric is calculated for each pixel or for each object. This helps avoid confusion and ensures fair comparison.
Why It Matters
Image segmentation plays a key role in computer vision. It allows a machine to understand scenes by separating and identifying objects. This is important for many real-world tasks, such as object detection, medical imaging, and self-driving cars.
Segmentation improves both the accuracy and reliability of computer vision systems. Researchers use metrics like precision, recall, F1-score, and IoU to measure how well segmentation finds and separates objects. For example:
- Segmentation methods that use community detection, such as Louvain or Leiden, show high accuracy and robustness.
- An IoU threshold of 0.5 is often used to balance true positives and false positives, making object detection more reliable.
- Advanced thresholding methods, like the Equilibrium Optimizer, achieve higher scores in PSNR and SSIM, which means better segmentation quality and fewer errors.
- Adaptive algorithms can adjust in real time, reducing false positives and negatives, which is important for changing environments.
Industry benchmarks also highlight the value of segmentation. Models like the Segment Anything Model (SAM) use binary cross entropy and IoU to measure accuracy. SAM and its improved versions, such as DIS-SAM and MedSAM, set new standards in fields like art design, image editing, and autonomous driving by refining how machines find object boundaries.
A comparison of segmentation methods shows that deep learning models, such as U-Net and Mask R-CNN, achieve the highest accuracy but take more time to process images. Machine learning methods offer a balance between speed and accuracy, while simple methods are fastest but less accurate. This trade-off helps users choose the right approach for their needs.
Types of Image Segmentation

Semantic Segmentation
Semantic segmentation helps a machine vision system understand what is in an image. This method assigns a label to every pixel in the image. Each pixel gets grouped by its category, such as road, car, or tree. The system does not care about which object the pixel belongs to, only the class. For example, all pixels that show a car get the same label, even if there are many cars. Semantic segmentation works well for tasks where knowing the type of object matters more than knowing which specific object it is.
Note: Semantic segmentation cannot tell the difference between two objects of the same class. It treats all similar objects as one group.
Instance Segmentation
Instance segmentation takes the process further. It not only labels each pixel by category but also separates each object instance. The system can tell one car from another, even if they touch. Instance segmentation is important for counting objects or tracking them. In a factory, the system uses instance segmentation to count each product on a conveyor belt. This method helps in situations where the number of objects matters.
A table below shows the difference between semantic segmentation and instance segmentation:
| Feature | Semantic Segmentation | Instance Segmentation |
|---|---|---|
| Labels per pixel | Yes | Yes |
| Distinguishes objects | No | Yes |
| Counts objects | No | Yes |
Panoptic Segmentation
Panoptic segmentation combines the strengths of both semantic segmentation and instance segmentation. It gives each pixel a semantic label and also separates each object instance. The system can tell what type of object is present and which specific instance it is. Panoptic segmentation helps in complex scenes where both the class and the identity of each object matter. For example, in street scenes, panoptic segmentation lets the system see every car, person, and road sign, and know which is which.
Panoptic segmentation gives a complete view of the scene. It supports both object recognition and instance tracking.
Image Segmentation Machine Vision System
System Types
Machine vision systems come in three main types: 1D, 2D, and 3D. Each type uses segmentation to solve different problems. In 1D systems, the machine analyzes data along a single line, often used for inspecting wires or printed labels. Combining 1D and 2D feature maps can improve accuracy in tasks like EEG data analysis and facial recognition. For example, composite features have increased accuracy by up to 18.75% in Parkinson’s disease datasets.
2D machine vision systems work with flat images. They help machines inspect surfaces, check dimensions, and read barcodes. Automotive manufacturers use these systems to inspect over 30,000 parts per vehicle. 2D segmentation finds defects and ensures quality in industries like electronics and food processing.
3D machine vision systems add depth information. They allow machines to measure shapes and volumes. In medical imaging, the 3D TransUNet architecture combines convolutional neural networks and Transformers. This approach improves segmentation of organs and tumors, leading to better diagnosis. 3D systems also help with precise alignment and assembly in manufacturing.
Machine vision systems using segmentation have reduced facial recognition error rates from 4% to 0.08% between 2014 and 2020. These improvements show the power of advanced image segmentation machine vision system technology.
Segmentation Workflow
A typical image segmentation machine vision system follows a clear workflow. The process starts with image acquisition. High-resolution cameras or scanners capture detailed images. In medical and biological research, two-photon excitation and laser scanning microscopy produce images with clear cell boundaries.
Next, preprocessing prepares the images for segmentation. Techniques like BM3D denoising remove noise but keep important details. Stacking multiple scans can also improve the signal-to-noise ratio.
Segmentation comes after preprocessing. Models such as the Segment Anything Model (SAM) use zero-shot learning to identify objects without extra training. Post-processing then refines the results, removing overlapping or partial masks and improving accuracy.
This workflow leads to strong results. For example, combining BM3D denoising and post-processing with SAM-H achieved an average error rate of just 3.0% in cell segmentation tasks. The table below shows how each step improves accuracy:
| Configuration | Average Error Rate (%) |
|---|---|
| Original + SAM | 17.4 |
| BM3D + SAM | 5.3 |
| BM3D + SAM + Post-Processing | 3.0 |
Machine vision systems using this workflow process images in milliseconds. They reduce inspection time by 25% and cut defect rates by up to 80%. The chart below shows measurable workflow improvements:
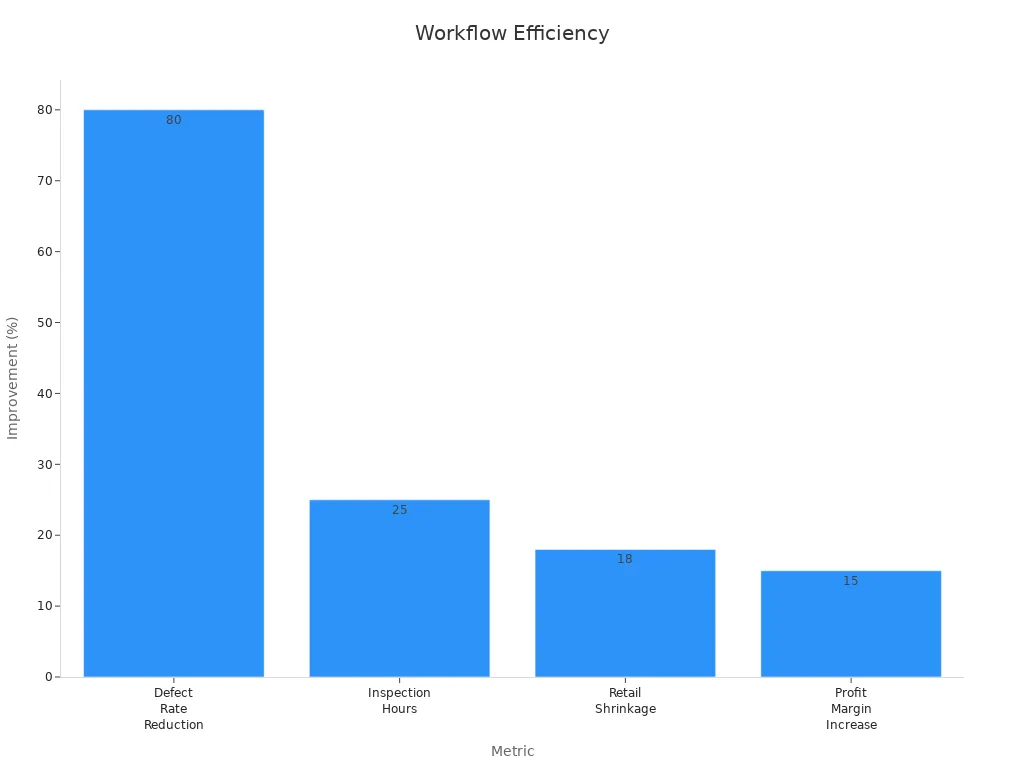
Segmentation in machine vision systems enables rapid, high-precision inspections. It supports real-time monitoring, improves safety, and increases production output. The image segmentation machine vision system has become essential for modern industry and research.
Image Segmentation Techniques
Traditional Methods
Traditional image segmentation techniques have played a key role in machine vision for many years. These techniques include thresholding, edge detection, clustering, and atlas-based segmentation. Each method uses different rules to separate objects in an image. For example, thresholding sets a value to split pixels into groups. Edge detection finds lines where objects meet. Clustering groups pixels with similar colors or textures. Atlas-based segmentation uses reference images to guide the process.
These techniques depend on handcrafted features and expert knowledge. They work well in simple scenes but struggle with noise and changes in lighting. Human factors can affect the results, making them less reliable in new situations. In medical imaging, geometric active contours help segment complex shapes like organs or tumors. This method adapts to irregular boundaries but needs careful setup and more computing power.
Researchers use several metrics to measure the performance of traditional segmentation. The table below shows common metrics and what they mean in machine vision:
| Metric | Description | Example Performance |
|---|---|---|
| Precision | Proportion of true positive predictions among all positive predictions made | High precision reduces false positives |
| Recall | Proportion of true positives identified among all actual positives | High recall reduces false negatives |
| F1 Score | Harmonic mean of precision and recall, balancing both metrics | Example F1 score of 0.997 shows very high segmentation accuracy |
These metrics help users understand the trade-off between missing objects and finding too many false ones. High F1 scores mean the technique balances both sides well.
Tip: Traditional image segmentation techniques are fast and easy to use, but they may not work well with complex or noisy images.
Deep Learning Methods
Deep learning methods have changed the way machines perform image segmentation. These techniques use convolutional neural networks (CNNs) to learn features from large datasets. CNNs can find patterns in images that humans might miss. Deep learning based segmentation techniques, such as U-Net and Mask R-CNN, have become popular for their high accuracy and adaptability.
Unlike traditional methods, deep learning techniques do not need handcrafted features. They learn from data, which makes them more flexible. In medical imaging, deep learning methods handle complex images with noise or artifacts better than older techniques. For example, studies show that deep learning models like FastSurferCNN and Kwyk produce more reliable results than traditional pipelines, even when images have motion artifacts.
A recent study compared 24 segmentation methods on lung CT images. The table below shows how deep learning and conventional methods performed using the Sørensen-Dice coefficient (DSC):
| Method Type | Best DSC Score | Notes on Performance and Computational Demand |
|---|---|---|
| Deep Learning | ~0.830 | Higher accuracy, more robust, needs more training and computing power |
| Conventional | ~0.610-0.808 | Lower accuracy, faster, less training needed |
Deep learning based segmentation techniques often require more computing resources and longer training times. However, they deliver better accuracy and can adapt to new types of images.
Note: Data augmentation, such as flipping or rotating images, helps deep learning models learn better and improves their performance.
Pros and Cons
Each image segmentation technique has its own strengths and weaknesses. The table below summarizes the main advantages and disadvantages of popular techniques used in machine vision:
| Technique | Advantages | Disadvantages |
|---|---|---|
| Grad-CAM | Highlights important image regions; robust visualization | May miss fine details; limited spatial information |
| Integrated Gradients (IG) | Quantifies feature importance; widely used in segmentation | Can generate noise in unrelated regions |
| Counterfactual Explanations (CE) | Improves interpretability and accountability | Computationally complex; needs careful calibration |
Grad-CAM helps users see which parts of an image a CNN focuses on during classification or segmentation. Integrated Gradients show which features matter most for the model’s decision. Counterfactual explanations provide deeper understanding but require more computing power.
In practice, traditional image segmentation techniques offer speed and simplicity. They work well for basic tasks and when computing resources are limited. Deep learning methods provide higher accuracy and adapt to complex scenes. They need more data, training, and computing power. Both types of techniques play important roles in machine vision, depending on the problem and available resources.
Note: Choosing the right image segmentation technique depends on the task, the quality of images, and the need for accuracy or speed.
Image Processing Techniques and Applications
Real-World Uses
Image processing techniques power many real world applications in manufacturing, medical imaging, surveillance, and robotics. In factories, these techniques help machines inspect products, detect defects, and count items on assembly lines. Medical imaging uses advanced processing to highlight organs, tumors, or blood vessels, supporting early detection and diagnosis. Robotics relies on object recognition and segmentation for navigation and manipulation tasks. Surveillance systems use computer vision to track people and vehicles, improving safety and security.
The table below shows how image processing techniques perform in medical imaging across different benchmarks:
| Benchmark | Imaging Modality | Dice Similarity Coefficient (DSC) | Normalized Surface Dice (NSD) |
|---|---|---|---|
| BTCV | CT | 85.38% | 87.82% |
| ACDC | MRI | 92.16% | 96.54% |
| EndoVis17 | Endoscopy | 67.14% | 68.70% |
| ATLAS23 | MRI | 84.06% | 88.47% |
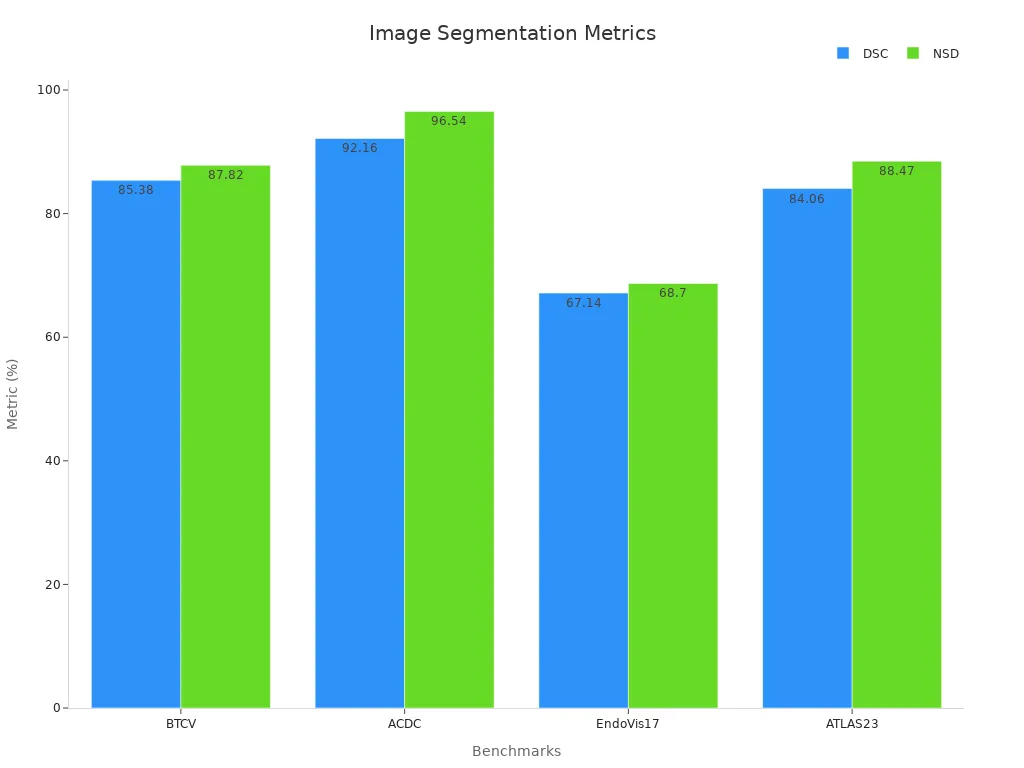
These results show that deep image processing techniques, like SAMA-UNet, achieve high accuracy in segmenting medical images.
Tools and Datasets
Many tools and datasets support image processing techniques for object detection and recognition. Open-source libraries such as OpenCV, scikit-image, and PyTorch provide easy access to processing functions. Beginners can use these tools to experiment with segmentation and object detection tasks.
Popular datasets help train and test models for various applications. The table below lists some widely used datasets:
| Dataset | Description & Scale | Application Domains |
|---|---|---|
| PASCAL VOC | 11,530 images, 27,450 ROI annotated objects, 6,929 segmentations; 21 object classes | General segmentation, object detection |
| MS COCO | 328k images, 2.5 million labeled segmented instances, 91 object types | Complex everyday scenes, object detection |
| Cityscapes | 5,000 fully annotated images, 20,000 weakly annotated frames, 30 classes | Urban street scenes, autonomous driving |
| ADE20K | 20,210 training images, 2,000 validation, 3,000 testing; 150 semantic categories | Scene parsing, semantic segmentation |
| KITTI | Video sequences of traffic scenes, manual semantic segmentation annotations | Mobile robotics, autonomous driving |
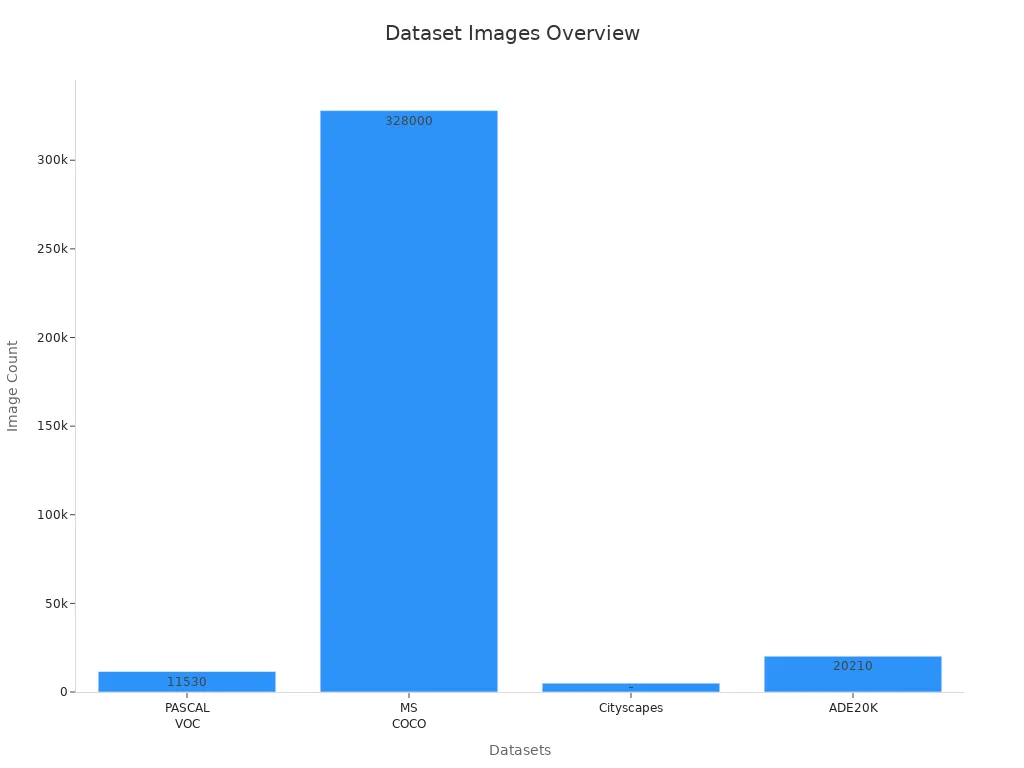
U-Net models trained on medical imaging datasets show strong performance, measured by the Dice Similarity Coefficient. These datasets support both academic research and industrial applications.
Getting Started
Beginners can start with simple image processing techniques using Python and OpenCV. They can try thresholding, edge detection, or basic segmentation on sample images. Many tutorials guide users through object recognition and detection projects. For a first project, students can segment coins in a photo or detect cars in street scenes. Using public datasets, they can train deep models for more advanced applications. Practice with these techniques builds skills for real world applications in computer vision.
Tip: Start small and build up. Experiment with different processing techniques and datasets to see what works best for each application.
Image segmentation continues to transform how a machine interprets and analyzes visual data across industries. Segmentation enables precise detection in medical imaging, manufacturing, and robotics, with deep learning models like U-Net and Mask R-CNN driving real-time applications. Long-term studies show that mastering both traditional and deep learning techniques provides lasting benefits.
- The global market for machine vision grows rapidly, fueled by automation and quality assurance needs.
- Beginners should share code, use robust workflows, and validate segmentation projects with real-world data.
Segmentation skills will remain essential as new technologies like Vision Transformers and 3D vision expand the field.
FAQ
What is the main goal of image segmentation in machine vision?
Image segmentation helps a machine separate an image into different parts. Each part shows a different object or region. This process lets the machine find and analyze objects more easily.
How does deep learning improve image segmentation?
Deep learning models learn patterns from many images. These models find objects even in complex or noisy scenes. They often give higher accuracy than traditional methods.
Which industries use image segmentation the most?
Manufacturing, healthcare, robotics, and security systems use image segmentation. For example, factories use it to check products, and hospitals use it to find tumors in scans.
Can beginners try image segmentation at home?
Yes! Beginners can use free tools like OpenCV or scikit-image. Many online tutorials show how to segment simple images, such as coins or cars.
What is the difference between semantic and instance segmentation?
| Feature | Semantic Segmentation | Instance Segmentation |
|---|---|---|
| Labels objects | By type | By type and instance |
| Counts objects | No | Yes |
Semantic segmentation groups by type. Instance segmentation also separates each object.
See Also
Understanding How Machine Vision Systems Process Images
Future Trends Of Segmentation In Machine Vision Systems
Complete Overview Of Machine Vision For Industrial Automation
An Introduction To Sorting Using Machine Vision Technology
Fundamental Principles Behind Edge Detection In Machine Vision








