
A super-resolution machine vision system uses advanced technology to make image details much clearer. This system improves image resolution, so machines can see objects with greater accuracy. Super-resolution changes blurry or low-quality image data into sharp, high-resolution pictures. These systems help vision tools spot tiny features that normal cameras might miss. In many cases, super-resolution increases resolution by up to seven times, giving images much more detail. The table below shows how super-resolution methods boost image resolution and quality for vision tasks:
| Method | Image Resolution Gain | Imaging Speed |
|---|---|---|
| CFCNN | 7-fold increase | Up to 11 volumes/s |
| U-Net (low-light) | 3 images needed | Fast |
| scU-Net | 3 images, higher clarity | Fast |
Super-resolution machine vision system technology gives beginners a strong way to improve image enhancement and resolution for many vision needs.
Key Takeaways
- Super-resolution machine vision systems improve image clarity by increasing resolution, helping machines see tiny details missed by normal cameras.
- Deep learning methods offer sharper, more accurate images than traditional techniques, making them ideal for complex vision tasks.
- High-resolution images boost accuracy in fields like medical imaging, industrial inspection, and security by revealing small features and defects.
- Beginners can start using super-resolution with basic tools like a good camera, stable tripod, and open-source software, following simple testing steps.
- Super-resolution technology continues to evolve, offering powerful ways to enhance images and support better decision-making across many industries.
What Is a Super-Resolution Machine Vision System
Key Features
A super-resolution machine vision system uses advanced algorithms to improve the resolution of images. This system takes low-resolution images and transforms them into high-resolution versions. The main goal is to help machines see more details than standard cameras can capture. Super-resolution works by using both traditional and deep learning methods. These methods include convolutional neural networks, pixel attention mechanisms, and transformer-based models. Each method focuses on making images clearer and sharper for vision tasks.
Recent advances in super-resolution machine vision systems show strong results. Researchers have compared many algorithms on public datasets. They use both qualitative and quantitative analysis to measure performance. Key parameters include network complexity, architecture, and optimization. For example, deep convolutional networks and improved residual networks have set new standards for image super-resolution. These advances help machines process images faster and with better quality. Bibliometric data shows that research in this field continues to grow, with new publications and higher citation counts each year.
A super-resolution machine vision system often uses metrics like Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measurement (SSIM), and Information Fidelity Criterion (IFC) to measure image quality. These metrics help engineers and researchers compare different super-resolution methods. The Neural Explicit Representation (NExpR) method, for example, speeds up image rescaling by over 100 times without losing image quality. This improvement means machines can analyze images quickly and accurately.
Tip: Super-resolution systems can turn blurry images into sharp ones, making it easier for machines to recognize small features.
Purpose and Value
The main purpose of a super-resolution machine vision system is to enhance the resolution of images for better machine perception. High-resolution images allow machines to detect tiny details that low-resolution images might miss. This enhancement is important for many vision applications, such as medical imaging, industrial inspection, and security systems.
Super-resolution helps solve common problems in vision tasks. Low-resolution images can hide important features or cause errors in object detection. By increasing the resolution, super-resolution systems improve the accuracy of machine vision. For example, in medical imaging, image super-resolution can reveal small structures in scans, helping doctors make better decisions. In industrial settings, these systems help spot defects that standard cameras cannot see.
Statistical data supports the value of super-resolution. The adaptive fusion of Dual Super-Resolution Generative Adversarial Network (DSRGAN) models with Top-Hat Gradient-Domain Filtering (THGDF) achieves high perception scores. These scores come from objective image quality metrics, showing that super-resolution outperforms older methods. Machines using these systems can process images faster and with greater clarity.
A super-resolution machine vision system brings value by making vision tools more powerful. It allows for better image enhancement, sharper details, and improved decision-making. As research continues, these systems will become even more effective for a wide range of vision tasks.
Resolution Challenges
Low-Resolution Issues
Low-resolution images create many problems for machine vision systems. These problems appear in different fields, such as medical imaging, satellite studies, and industrial inspection. When an image has low resolution, small details disappear. Machines cannot see tiny defects or important features. In medical imaging, low resolution can hide signs of disease. In satellite images, low resolution causes errors in measuring land or tracking changes. Many studies still use low-resolution data, even when better options exist. This choice leads to mistakes and missed information.
Low-resolution images often suffer from blurring and noise. These issues make it hard for vision systems to find edges or separate objects. The table below shows common metrics and methods used to measure low-resolution challenges in imaging:
| Metric / Method | Description / Role in Low-Resolution Challenges |
|---|---|
| Rayleigh’s and Abbe’s criteria | Classical resolution measures, limited for modern imaging systems. |
| Local Impulse Response (LIR) | Measures spatially varying resolution, helps address blurring. |
| Point Spread Function (PSF) | Describes blurring in linear systems, key for resolution checks. |
| Contrast-to-Noise Ratio (CNR) | Shows how noise affects image contrast and quality. |
| Contrast Recovery Coefficient (CRC) | Tests if true contrast can be recovered, shows resolution and noise effects. |
| Variance and Covariance | Measure noise and uncertainty, important for image reliability. |
| Ensemble Mean Squared Error (EMSE) | Combines bias and variance, shows total error in image reconstruction. |
| Fixed-Point Analysis | Computes covariance and LIR, helps assess resolution without heavy simulations. |
| Monte Carlo Simulations | Validates analytical metrics, especially at low noise. |
Low-resolution problems also come from lens distortions, sensor limits, and poor lighting. These factors lower the quality of the image and make it harder for super-resolution methods to work well. Matching the right lens and sensor is important to avoid blurring or vignetting. Repeatability metrics, like variance and standard deviation, help check if the vision system can keep high resolution in every image.
Note: Modern imaging systems need new ways to measure resolution. Old methods, like Rayleigh’s and Abbe’s criteria, do not work well for today’s complex algorithms. Super-resolution techniques must use better metrics to solve these challenges.
Why Resolution Matters
Resolution plays a key role in the success of any vision system. High-resolution images let machines see small features and tiny defects. Super-resolution methods help vision systems reach this level of detail. When resolution improves, machines can detect problems that would stay hidden in low-resolution images.
Statistical studies show that higher resolution leads to better accuracy in machine vision. For example, research from the Fraunhofer Institute found that high-resolution sensors can spot defects as small as 1.5 micrometers. This improvement means fewer mistakes and better results in quality control. Validation tests, like Gage Repeatability and Reproducibility, confirm that high-resolution imaging gives reliable and repeatable results.
Low-resolution images can cause both false positives and false negatives. In satellite studies, using low-resolution data increases the chance of missing real changes or finding patterns that do not exist. In medical imaging, low resolution can hide important signs, leading to wrong decisions. Super-resolution methods help fix these problems by making images clearer and more useful.
Super-resolution also helps vision systems work in tough conditions. Poor lighting, sensor limits, and lens problems all affect resolution. By using advanced super-resolution techniques, machines can overcome these limits and get better images. This improvement leads to more accurate inspections, better medical diagnoses, and stronger security systems.
Super-Resolution Methods
Traditional Techniques
Traditional super-resolution techniques use mathematical formulas to increase the resolution of an image. These methods include interpolation approaches like nearest neighbor, bilinear, and bicubic interpolation. Engineers often choose these methods because they work quickly and require little computer memory. For example, when a vision system needs to upscale a small image, interpolation can stretch the pixels to fill a larger space. However, these methods often create images with blocky edges or smooth out important details. The final result may look blurry or artificial.
Some traditional super-resolution techniques use multiple low-resolution images of the same scene. By combining these images, the system can estimate missing details and create a higher-resolution result. This process works well when the images have slight differences, such as small shifts or rotations. However, these methods struggle when only one image is available or when the original images have too much noise.
The table below compares traditional interpolation techniques with deep learning methods for super-resolution:
| Metric | Traditional Interpolation Techniques | Deep Learning Methods (e.g., GFPGAN, CodeFormer) |
|---|---|---|
| Inference Time (CPU) | Significantly faster (e.g., super resolving 64×64 to 1024×1024 in less time) | Longer inference time due to complex processing |
| CPU Memory Utilization | Lower memory usage | Higher memory usage required |
| GPU Inference Time | Not typically used or less effective | Faster than CPU but still higher than interpolation |
| GPU Memory Utilization | N/A | High memory consumption (e.g., NVIDIA Quadro P1000 GPU) |
| Image Quality (PSNR, SSIM) | Lower scores, images tend to have artifacts like blockiness or smoothing | Higher scores, better texture and detail recovery |
| No Reference Image Quality (NR-IQA) | Lower visual quality scores | Higher visual quality scores reflecting better realism |
| Library Dependencies | Minimal (e.g., only OpenCV) | More complex (e.g., PyTorch >=1.7 plus OpenCV) |
| Practical Use Case | Quick, large-scale upsampling with acceptable quality | High fidelity super resolution for specific instances |
Note: Traditional super-resolution techniques offer speed and simplicity, but they cannot match the detail and clarity of modern deep learning methods.
Deep Learning Approaches
Deep learning for super-resolution has changed the way vision systems improve image quality. These methods use artificial intelligence models, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), and transformer-based models. The system learns from thousands of high-resolution and low-resolution image pairs. It then predicts how to add missing details to new images. This process helps the system create images with sharp edges, clear textures, and fewer artifacts.
Researchers have shown that deep learning methods outperform traditional super-resolution techniques in both quality and accuracy. For example, deep learning models like SRCNN and EUSR produce images with sharper boundaries and better texture recovery. These improvements are measured using metrics such as Peak Signal-to-Noise Ratio (PSNR), Root Mean Square Error (RMSE), and Structural Similarity Index (SSIM). GAN-based approaches, like SRGAN, focus on making images look more realistic to the human eye. However, they sometimes lower the scores on pixel-level tests. Newer models, such as 4PP-EUSR, balance both quantitative and perceptual quality, giving vision systems the best of both worlds.
The success rate of deep learning methods in image super-resolution tasks is high. In medical imaging, deep learning models achieve Dice Similarity Coefficient (DSC) scores up to 0.91 and Intersection over Union (IoU) scores up to 84.9%. This means deep learning for super-resolution improves segmentation precision by about 19.5% compared to low-resolution images. The table below shows these improvements:
| Image Type | Dice Similarity Coefficient (DSC) | Intersection over Union (IoU) |
|---|---|---|
| Low resolution | 0.72 | 65.4% |
| SRGAN-enhanced | 0.91 | 84.9% |
Deep learning models also show higher success rates in vision tasks. For example, convolutional networks like U-Net and VGG16-based FCN reach DSC scores between 79.3% and 83.0%, while traditional methods range from 61.0% to 80.8%. This difference highlights the power of deep learning for super-resolution in improving image clarity and accuracy.
| Method Type | Reported Success Rate (DSC %) | Notes |
|---|---|---|
| Deep Learning | 79.3% to 83.0% | Using convolutional networks such as U-Net and VGG16-based FCN for pulmonary nodule segmentation |
| Traditional | 61.0% to 80.8% | Hand-designed multi-step approaches and level-set active contours |
Tip: Deep learning for super-resolution not only increases resolution but also helps vision systems find small features that traditional methods miss.
Bayesian methods play a key role in modern super-resolution techniques. These methods help the system measure uncertainty in its predictions. In medical imaging, Bayesian models improve diagnostic confidence and image clarity. Studies show that artificial intelligence models using Bayesian approaches reach high accuracy and sensitivity. For example, U-Net models for breast cancer detection achieve up to 99.33% accuracy and 100% sensitivity. Other studies report sensitivity improvements from 84% to 92% in thyroid cancer screening.
The chart below shows how accuracy in medical imaging has improved over the years with advanced super-resolution techniques:
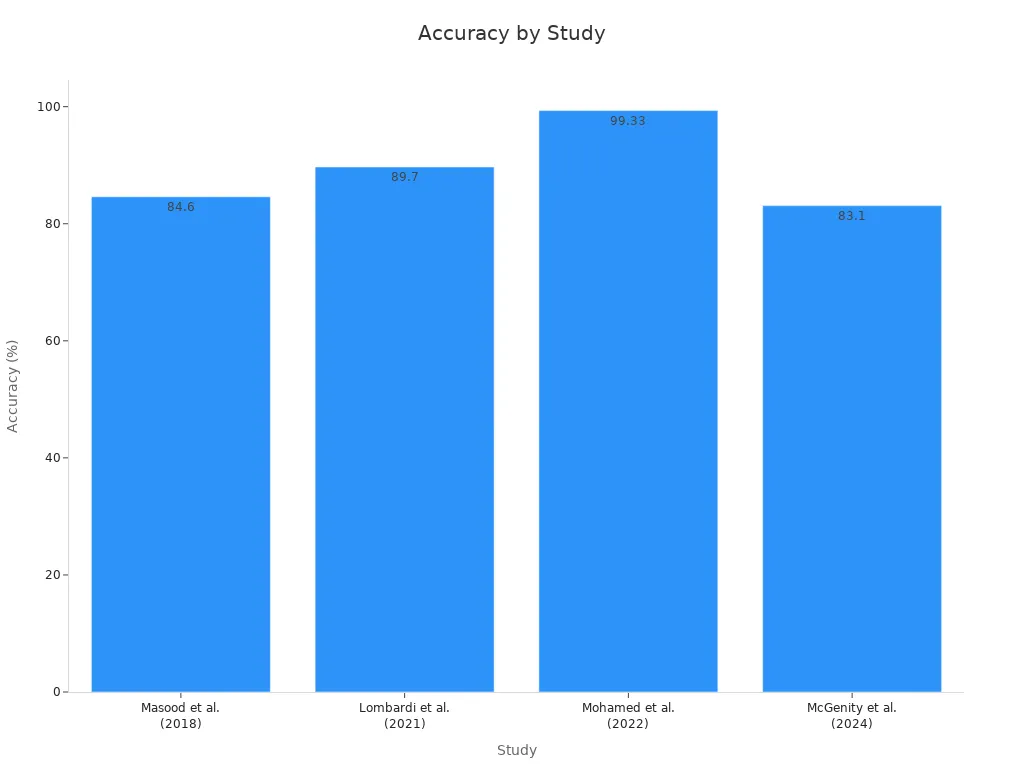
Deep learning for super-resolution also maintains high fidelity in enhanced images. In PET/CT imaging, over 80% of radiomic features in deep learning-enhanced images match those in gold-standard images. This result means that deep learning methods can create high-resolution images that are almost as good as the original high-quality scans.
Super-resolution techniques continue to evolve. New models use multi-pass upscaling and score predictors to balance sharpness and realism. These advances help vision systems in many fields, from industrial inspection to medical diagnosis. As research grows, super-resolution will become even more important for image enhancement and resolution improvement.
Note: Super-resolution techniques using deep learning and Bayesian models give vision systems the ability to see more, detect more, and make better decisions.
Applications of Super-Resolution
Industrial Uses
Super-resolution technology has changed how industries use machine vision. In manufacturing, engineers use super-resolution to inspect products for tiny defects. Line scan cameras with high resolution can find scratches or cracks that standard cameras miss. Factories use these systems to check circuit boards, bottles, and textiles. Super-resolution helps machines see small parts clearly, which improves quality control. In robotics, vision systems with super-resolution guide robots to pick and place objects with high accuracy. These applications of super-resolution make production lines faster and more reliable.
- Super-resolution increases image resolution, so machines can spot flaws early.
- High-resolution images help with object recognition in sorting and packaging.
- Vision systems use super-resolution to read small barcodes and labels.
Medical Imaging
Super-resolution has many applications in medical imaging. Doctors use it to get clearer images from CT, MRI, PET, ultrasound, and fMRI scans. This technology improves resolution, which helps doctors see small lesions and fine details. Clinical research shows that super-resolution increases diagnostic accuracy and supports early detection of diseases. AI models like convolutional neural networks and GANs play a big role in these improvements.
- The number of studies on super-resolution in medical imaging has grown from 2000 to 2023.
- Super-resolution helps with better segmentation and organ assessment.
- Lightweight models with attention mechanisms focus on important regions, making it easier to find subtle abnormalities.
- Enhanced image clarity supports early diagnosis and treatment planning.
Advanced AI methods, such as vision transformers, improve image edges and textures. These models help doctors see organ shapes more clearly, which is important for planning surgeries and treatments.
Security and Surveillance
Security and surveillance systems use super-resolution to improve image resolution in video feeds. This technology helps cameras capture clear images even in low light or from far distances. Deep learning with super-resolution boosts object recognition, making it easier to detect threats in real time.
- Super-resolution improves detection accuracy and speed in video surveillance.
- Advanced algorithms handle low-resolution images and occlusion, making systems more robust.
- Object recognition finds small items, such as weapons, in crowded places.
- Real-time detection helps prevent crime in banks, gas stations, and other sensitive locations.
Studies show that super-resolution increases image quality metrics like PSNR and SSIM, which leads to better object detection. Combining super-resolution with transformer-based detectors gives higher accuracy, especially for small or hidden objects. These applications of super-resolution turn surveillance from passive watching into active protection.
Getting Started
Tools and Software
A beginner needs the right tools to explore super-resolution in machine vision. The most important hardware includes a digital camera with adjustable lenses. High-quality lenses help capture more detail in each image. A stable tripod keeps the camera steady, which improves resolution. Good lighting makes every image clearer and reduces noise.
For software, many users start with open-source programs. Tools like OpenCV and ImageJ allow users to process images and test super-resolution algorithms. Deep learning frameworks, such as TensorFlow and PyTorch, support advanced super-resolution models. Some companies offer commercial software with built-in super-resolution features. These programs often include easy-to-use interfaces for image enhancement and resolution improvement.
Tip: Always check if your computer meets the software’s requirements before installing super-resolution tools.
Simple Steps
Many beginners succeed with super-resolution by following a clear process. The steps below show how early users tested and measured their results:
- Develop a super-resolution algorithm using synthetic image data. This step allows controlled testing and helps users understand how resolution changes.
- Compare different segmentation methods on the same image. For example, try watershed with a gradient image and then use an inverted Gaussian. This comparison shows which method improves image clarity and removes noise.
- Measure how well the algorithm locates small features. Analyze overlapping objects in the image to see if the resolution is high enough to separate them.
- Process a video loop with thousands of events. Check if the detection results match the known number of events. This step tests the reliability of the super-resolution method.
- Test the algorithm with real images collected under the same settings as the synthetic data. This step confirms that the method works outside the lab.
- Compare the size and location of features in the super-resolution image with results from other imaging methods, such as optical coherence tomography. This comparison provides clear, measurable outcomes.
These steps help users see how super-resolution improves image resolution and accuracy.
Learning Resources
Many resources help beginners learn about super-resolution. Online tutorials explain how to use image processing software and build simple super-resolution models. Video courses on platforms like Coursera and YouTube teach the basics of resolution and image enhancement. Books on computer vision often include chapters about super-resolution techniques.
A checklist for beginners includes:
- A digital camera with adjustable lenses
- A stable tripod
- Good lighting equipment
- Open-source image processing software
- Access to online tutorials and video courses
Note: Joining online forums and reading research articles can help users stay updated on new super-resolution methods.
Super-resolution machine vision systems help users see more detail in every image. These systems improve resolution, making it easier to find small features and boost accuracy. Anyone can start learning about image enhancement, no matter their background. Beginners can explore many resources:
- Guides on interpolation and upsampling show how to increase image resolution.
- Frameworks explain model choices for better image results.
- Learning strategies use loss functions to improve image quality.
- Code repositories let users test image models.
- Survey papers offer more ways to study image resolution.
Super-resolution tools open new doors for anyone who wants to make every image clearer and sharper.
FAQ
What is the main benefit of super-resolution in machine vision?
Super-resolution helps machines see small details that standard cameras miss. This improvement leads to better accuracy in tasks like inspection, detection, and measurement. High-resolution images support more reliable decisions in many fields.
Can beginners use super-resolution tools without coding experience?
Many super-resolution tools offer user-friendly interfaces. Beginners can use these programs to enhance images without writing code. Some software provides step-by-step guides and tutorials for easy learning.
How does super-resolution for satellite images help researchers?
Super-resolution for satellite images gives researchers clearer views of land, water, and cities. This clarity helps track changes, spot small features, and improve mapping. Scientists use these images to study the environment and plan projects.
Are deep learning methods always better than traditional techniques?
Deep learning methods often create sharper and more realistic images. Traditional techniques work faster and use less memory. The best choice depends on the task, available hardware, and the level of detail needed.
What hardware is needed for super-resolution machine vision systems?
A digital camera with a good lens, stable tripod, and proper lighting form the basic setup. For advanced super-resolution, a computer with a strong processor or GPU helps run deep learning models quickly.
See Also
Understanding Camera Resolution In Machine Vision Applications
Comprehensive Overview Of Semiconductor-Based Machine Vision Systems
The Role Of Deep Learning In Improving Machine Vision
An Introduction To Image Processing In Machine Vision
Exploring Computer Vision Models Within Machine Vision Systems








