
An in context learning machine vision system helps computers understand images by using examples, not by retraining the whole model. This system adapts to new visual tasks when given a few sample images and instructions. In context learning machine vision system plays a key role in computer vision because it allows quick solutions for new problems. It uses ideas from machine learning to help computers see and learn in a smarter way. Many experts see this as a big step forward for computer vision.
Key Takeaways
- In-context learning machine vision systems solve new visual tasks using a few examples and instructions without retraining the whole model.
- These systems adapt quickly and save time by using existing knowledge and prompts, making them more flexible than traditional methods.
- They work well with limited labeled data, helping industries like healthcare, manufacturing, and finance improve accuracy and reduce costs.
- Combining images and language, vision-language models enhance understanding and handle complex tasks with fewer examples.
- While powerful, these systems need good quality examples and enough computing power to perform best in real-world applications.
How It Works
Core Concepts
In-context learning changes how computers solve visual problems. Instead of retraining, a machine vision system uses examples and instructions to learn new tasks. This method relies on large vision models that already know a lot about images. These models use their existing knowledge to understand new situations. When someone gives a few sample images and a question, the system looks for patterns and context. It does not change its core settings or weights. Instead, it uses what it has learned before to answer new questions.
In-context learning lets computers generalize to tasks they have never seen. The system uses context examples as input. It finds clues in the images and the instructions. This process is similar to how large language models work with text. Both types of models use context to adapt their behavior. The main idea behind in-context learning is to use pretrained knowledge and context, not to retrain the model every time.
Machine vision systems use deep learning to recognize objects and patterns in raw images. They do not need manual rules or features. In-context learning helps these systems learn-to-learn. They get better at solving new problems over time. They do this by grounding their answers in the visual context and the query. This approach saves time and resources because the system does not start from scratch.
Prompting and Examples
Prompts and examples play a big role in in-context learning. A prompt is a set of instructions or a question. Examples are sample images with labels or answers. When a user wants the system to solve a new task, they give a prompt and a few examples. The system studies these inputs. It looks for patterns that match the new task. Then, it uses its pretrained knowledge to make predictions.
In-context learning uses prompt retrieval to find the best examples. The system can search its memory for similar tasks. It picks examples that help it understand the new problem. Some new methods, like Denoising In-Context Learning (DICL), help the system ignore noise or mistakes in the examples. This makes the system more accurate and reliable.
The process works like this:
- The user gives a prompt and a few labeled images.
- The system compares these examples to its own knowledge.
- It finds patterns and context clues.
- It predicts the answer for new, unseen images.
This method allows in-context learning to work with very little data. The system does not need thousands of labeled images. A few good examples are enough.
Tip: In-context learning works best when the examples are clear and closely related to the new task.
Vision-Language Models
Vision-language models combine image understanding with language skills. These models can read instructions and look at images at the same time. They use in-context learning to solve tasks that need both vision and language. For example, a vision-language model can answer questions about a picture or describe what it sees.
Recent research shows that vision-language models like CLIP can handle complex tasks in fields like medicine. Scientists used a framework called BiomedCoOp to test these models on medical images. They gave the models prompts and examples from different organs and imaging types. The models showed better accuracy and generalizability than older methods. This proves that in-context learning with vision-language models works well, even when there is not much labeled data.
Multimodal models, which use both images and text, make in-context learning even stronger. They can understand more complex tasks. They can also learn from fewer examples. This makes them useful in real-world situations where data is limited.
In-context learning helps large models adapt quickly. They do not need retraining for every new task. They use prompts, examples, and their own knowledge to solve problems. This approach saves time and makes machine vision systems more flexible.
In Context Learning Machine Vision System

Key Features
An in context learning machine vision system stands out because it can handle many tasks without retraining. This system uses in-context learning to process new visual problems by looking at examples and prompts. It does not need large amounts of labeled data for every new task. Instead, it uses its existing knowledge and adapts quickly.
Some key features include:
- Few-shot learning: The system learns from just a few examples.
- Prompt-based adaptation: It follows instructions or questions given by the user.
- No retraining required: The core model stays the same, saving time and resources.
- Multimodal understanding: It can work with both images and text, making it more flexible.
These features help the system solve real-world problems faster than traditional machine vision. For example, time series machine vision systems can analyze sequences of images over time. This ability leads to better pattern recognition and event detection. In manufacturing, these systems have reduced unplanned downtime by 25% and lowered error rates to below 1%, compared to about 10% in manual inspections. In finance, real-time anomaly detection has cut fraudulent transactions by 30%. Healthcare applications show improved patient outcomes and shorter hospital stays. The table below shows how in context learning machine vision systems compare to traditional systems in different industries:
| Industry / Metric | Description / Outcome | Numerical Data / Performance Metrics |
|---|---|---|
| Manufacturing | Early failure detection in machinery | 25% reduction in unplanned downtime; error rates below 1% (vs ~10% manual) |
| Finance | Real-time anomaly detection | 30% reduction in fraud |
| Healthcare | Patient vitals monitoring | Improved outcomes, reduced stays |
| AD-GS Framework | Anomaly detection performance | Accuracy: 96.8%, False Positive Rate: 1.8%, Reaction Time: 98.4%, Latency: <15 ms, 10.2% less computational overhead |
Note: These results show that in context learning machine vision systems deliver higher accuracy and efficiency across many fields.
Adaptability
Adaptability is a major strength of in-context learning. The system can switch between tasks with ease. It does not need to start over each time the task changes. Instead, it uses context from new examples and instructions to adjust its behavior.
Researchers have found that in-context learning helps the system adapt to changes in visual tasks. For example:
- Statistical learning allows the system to quickly adjust when target locations change during visual search.
- The system combines information about what stands out in an image (salience) with learned patterns to set priorities.
- Brain activity studies show that the system updates its focus as soon as new information appears.
- Performance improves when the system uses both statistical learning and salience, even when the task changes.
- The system can learn new patterns and adjust its actions almost immediately.
These points show that in context learning machine vision systems can handle many types of visual tasks. They can adapt to new situations much faster than traditional systems.
Self-Supervised Approaches
Self-supervised learning is another important part of in-context learning. In this approach, the system learns from unlabeled data. It finds patterns and relationships in the data by itself. This method helps the system build a strong base of knowledge before it sees any labeled examples.
In context learning machine vision systems often use self-supervised learning to improve their flexibility. They can learn from large amounts of raw images without human help. When given a new task, the system uses in-context learning to apply what it has learned. This process makes the system more robust and less dependent on labeled data.
Generative models also play a role in self-supervised learning. These models can create new images or fill in missing parts of an image. They help the system understand the structure of visual data. By combining self-supervised and generative approaches, in context learning machine vision systems become even more powerful.
Traditional machine vision systems usually need retraining for each new task. They rely on labeled data and fixed rules. In contrast, in context learning machine vision systems use self-supervised learning and in-context learning to adapt quickly. This difference makes them more flexible and efficient.
Computer Vision Applications

Object Detection
Object detection helps computers find and label items in images or videos. In context learning machine vision systems use this skill to solve real-world problems. For example, healthcare teams use computer vision to spot diseases in X-rays and mammograms. AI systems have reached 99% accuracy in detecting breast cancer. In manufacturing, object detection finds defects on assembly lines. Tesla uses this technology to improve car inspections. Utilities companies inspect power lines with drones, finding four times more defects and saving millions each year.
| Industry/Application | Details/Statistics | Case Study Example |
|---|---|---|
| Healthcare | $150B cost reduction by 2026; 30% fewer medical errors; 99% breast cancer detection accuracy | Stanford’s pneumonia detection from X-rays |
| Utilities (Power Lines) | 400% more defect detection; €3M annual savings; 250 km inspected in 5 minutes | Hepta Airborne’s drone-based AI inspection system |
| Manufacturing | Improved defect detection, cycle time control, predictive maintenance | Tesla’s hybrid inspection; Shell’s AI-enhanced maintenance |
Computer vision systems adapt quickly to new object detection tasks using only a few examples. This flexibility saves time and improves safety in many industries.
Segmentation Tasks
Segmentation tasks divide images into parts to help computers understand what each part shows. Video object segmentation tracks moving objects in video clips. This helps farmers monitor crops and livestock with drones. Retailers use segmentation to track products on shelves. Video object segmentation also supports real-time inventory tracking and loss prevention.
Binary semantic segmentation separates objects from the background. For example, it helps doctors find tumors in medical scans. In agriculture, it identifies weeds or diseased plants. Video object segmentation and binary semantic segmentation both make computer vision systems more accurate and useful.
Tip: Video object segmentation works best with clear examples and high-quality video input.
Generative Models
Generative models create new images or fill in missing parts. These models help computer vision systems learn from fewer labeled examples. In medical imaging, generative models improve accuracy with only a few sample images. For instance, GPT-4V reached 80% accuracy on the PatchCamelyon dataset using just 10 examples. On the MHIST dataset, accuracy for some classes jumped from 30% to about 90% with ten-shot prompting.
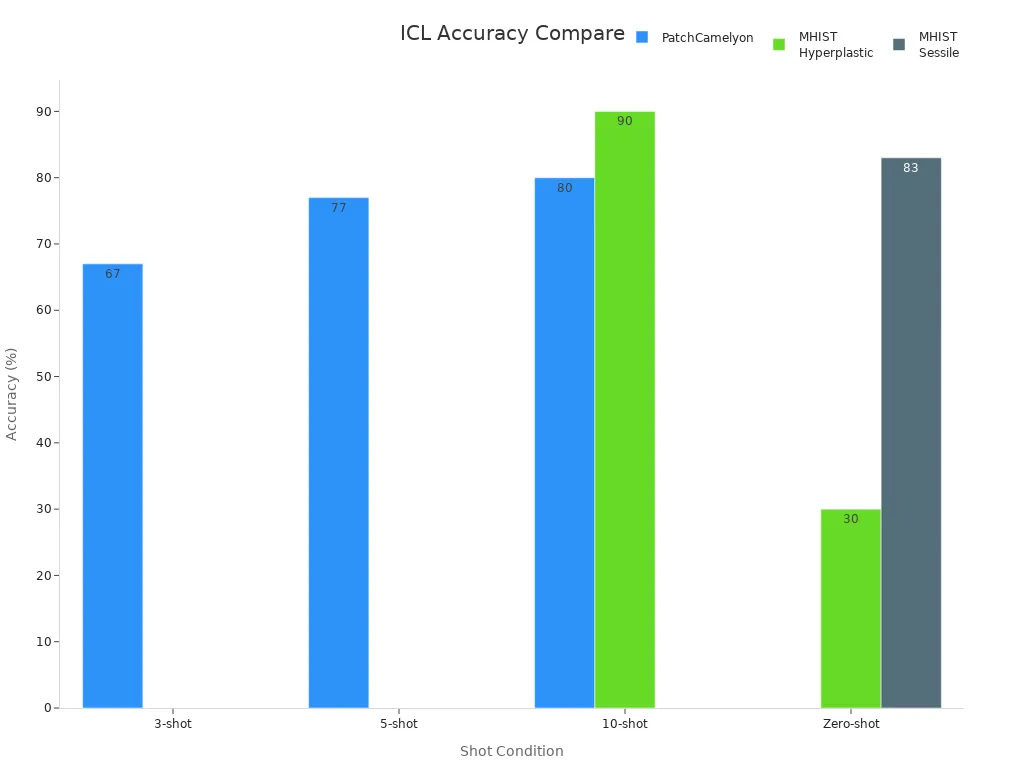
Generative models help democratize computer vision by reducing the need for large, labeled datasets. They allow faster adaptation to new tasks and support more accurate video object segmentation and binary semantic segmentation.
Benefits and Challenges
Advantages
In-context learning brings many benefits to machine vision systems. These systems can adapt to new tasks quickly. They do not need retraining for every change. This saves time and resources. Many studies show that in-context learning improves performance in real-world tasks.
- Annotation accuracy can reach 77% on small data sets. This means better labeling quality.
- Weighted average precision, recall, and F1-score values of about 0.77 show balanced learning.
- Active learning methods can cut data labeling costs by up to 60% on large datasets like KITTI and Waymo.
- Iterative cycles help the system pick the most useful images, which boosts accuracy and reduces extra work.
- Human-in-the-loop systems let experts review and improve results.
- Hybrid strategies that mix uncertainty and diversity sampling make the model stronger and reduce effort.
- In-context learning helps the system learn faster by focusing on the most useful samples.
- Querying frameworks guide the system to select the best images for learning.
- Studies confirm that active learning improves accuracy in medical imaging, object detection, and self-driving cars.
- Strong annotation workflows and quality checks keep labeled data reliable.
In-context learning also supports few-shot learning. The system can solve new problems with only a few examples. This makes it useful in fields where labeled data is hard to get.
Limitations
In-context learning has some limits. The system may not always perform well with very complex tasks. Sometimes, it struggles when examples are unclear or too different from the new task. The quality of the prompt and examples matters a lot. If the input is poor, the results may not be accurate.
Large models that use in-context learning need a lot of memory and computing power. This can make them hard to use on small devices. The system may also have trouble with tasks that need deep reasoning or long-term memory. In some cases, in-context learning may not match the accuracy of a fully retrained model.
Practical Concerns
People who use in-context learning machine vision systems should think about data quality and workflow. Good annotation and review processes help keep results strong. Teams need to check that the system works well on new tasks before using it in important settings.
Privacy and security also matter. Some data, like medical images, need extra care. Users should make sure the system follows rules for data safety. Cost is another concern. While in-context learning saves time, large models can still be expensive to run.
Tip: Teams should test in-context learning systems with real examples before full deployment.
In-context learning machine vision systems help computers solve new visual tasks by using examples. These systems work without retraining. In-context learning stands apart from traditional systems because it adapts quickly and uses fewer labeled images. Many industries now see real benefits from in-context learning, such as better accuracy and faster results. Some challenges remain, but in-context learning continues to improve. The future looks bright as in-context learning shapes how computers see and understand the world. Readers can explore how in-context learning might change their own fields.
FAQ
What is in-context learning in machine vision?
In-context learning lets a machine vision system solve new tasks by using examples and instructions. The system does not need retraining. It learns from the context given by the user.
How does in-context learning differ from traditional training?
Traditional systems need retraining for each new task. In-context learning uses a few examples and adapts quickly. The model keeps its core knowledge and learns from prompts.
Can in-context learning work with very little data?
Yes. In-context learning often needs only a few labeled examples. This makes it useful when labeled data is hard to find or expensive to create.
What are some real-world uses for in-context learning machine vision systems?
Healthcare teams use these systems for disease detection. Manufacturers find defects faster. Financial companies spot fraud. Farmers monitor crops. These systems help many industries solve problems with fewer resources.








