
A word embedding machine vision system uses mathematical representations called vectors to connect language with visual information. Word embeddings turn words into vectors that capture meaning and relationships. This process helps machines understand both images and text. Studies show that grounding embeddings with visual data improves their performance, even with small datasets.
| Embedding Type | Dataset | Performance | p-value |
|---|---|---|---|
| Visually grounded (TASA-G, Text8-G) | TASA, Text8 | Higher | ≤ 0.0008 |
| Purely textual (TASA-T, Text8-T) | TASA, Text8 | Lower |
Researchers find that combining visual and textual data in embeddings outperforms text-only models in tasks like natural language processing and predicting human similarity judgments. Word embeddings, vectors, and embedding models work together to bridge language and vision for smarter AI.
Key Takeaways
- Word embeddings turn words into numbers that help computers understand language and images together.
- Combining visual and text data in embeddings makes AI systems more accurate and faster at recognizing objects and scenes.
- Embedding models like Word2Vec and BERT improve many AI tasks, including image recognition, search, and language processing.
- Multimodal learning joins language and vision, enabling AI to better describe images and answer questions about them.
- Embedding models reduce manual work, handle large data efficiently, and keep improving AI performance in real-world applications.
Word Embedding Machine Vision System
Definition
A word embedding machine vision system uses mathematical techniques to represent words and images as vectors. These vectors capture the meaning and relationships between words and visual objects. In this system, word embedding models transform language into numbers that computers can understand. The models also connect these numbers to visual features found in images. This process helps computers recognize objects, understand scenes, and relate words to what they see.
Researchers have shown that embedding models form the backbone of many modern machine learning applications. For example, AMP Robotics’ vision system processes over 50 billion items each year. Their robots use embedding-based neural networks to recognize and sort materials at speeds greater than 100 feet per minute. This scale and speed highlight how embedding models enable efficient and accurate recognition in real-world machine vision systems.
The foundation of embedding comes from the way these models capture both semantic and structural relationships. By mapping words and images into a shared space, the system can compare and connect different types of information. This geometric approach allows the model to learn patterns and similarities, making it possible for computers to understand both text and visuals.
| Numerical Evidence | Description |
|---|---|
| 50 billion items processed annually | Size of dataset informing AMP Robotics’ vision system, demonstrating large-scale application of embedding-based AI recognition in machine vision |
| +100 feet per minute conveyor belt speed | Increase in conveyor belt speed when robots perform quality control compared to human sorters, showing efficiency gains enabled by machine vision |
Role in AI
The role of a word embedding machine vision system in AI is transformative. Embedding models allow computers to learn from both language and images. These models help AI systems understand context, meaning, and relationships in data. For example, word embedding models like Word2Vec, GloVe, and BERT have changed how machines process language and images. They provide dense, context-aware representations that improve tasks such as image recognition, semantic search, and natural language processing.
Recent research shows that embedding models outperform traditional models in many AI tasks. In clinical information retrieval, the BGE-large-en embedding model achieved a mean average precision score of 0.403 on the University of Wisconsin dataset and 0.475 on the MIMIC-III dataset. These scores were significantly higher than those of models without embeddings, which sometimes performed worse than random guessing. This evidence demonstrates that embedding models improve accuracy and reliability in complex AI systems.
Word embedding models also support advanced applications like conversational AI, text-to-image generation, and cross-modal search. For example, models such as OpenAI’s text-embedding-ada-002 and DALL·E use embeddings to connect text and images. These systems can generate images from text descriptions or find similar images based on a written query. In computer vision, embedding models help AI recognize objects, classify scenes, and even generate new images.
Industry reports confirm the impact of word embedding models. One study analyzed 22,000 documents from 128 central banks using embedding models. The results showed that embeddings outperformed dictionary methods in predicting monetary policy shocks. Another report examined 36,200 firm-year observations from Chinese companies. It found that digital capabilities measured by embedding models were linked to financial performance. These findings highlight the broad value of embedding models in research and industry.
Word embeddings also improve accuracy in machine vision-related tasks. Combining Word2Vec and GloVe embeddings in intrusion detection systems led to better balanced accuracy and generalization. These models capture both semantic and contextual relationships, which helps AI systems detect patterns even with limited training data.
Tip: Embedding models reduce the need for manual feature engineering. They help AI systems scale across different tasks and adapt to new data quickly.
Word Vectors & Meaning
Semantic Relationships
Word vectors help computers understand how words relate to each other. Each word in a corpus becomes a point in a space called vector space. The distance in vector space between two word vectors shows how similar their meanings are. For example, the word vectors for "cat" and "dog" will be close together because they often appear in similar contexts in the corpus. This closeness is measured using cosine similarity. Cosine similarity checks the angle between two vectors. If the angle is small, the words have similar meanings.
Word vectors capture more than just direct connections. They also show deeper relationships. For example, the vector for "king" minus the vector for "man" plus the vector for "woman" often lands near the vector for "queen." This pattern shows how word vectors can represent complex ideas from the corpus. Machine learning models use these patterns to find meaning and make predictions.
Context in Learning
Context plays a big role in how word vectors learn meaning. When a model trains on a corpus, it looks at the words around each target word. This process helps the model build word vectors that reflect how words are used in real life. Sometimes, words with opposite meanings, like "good" and "bad," appear in similar contexts. Research shows that their word vectors can have high cosine similarity even though their meanings differ. The table below shows how context affects cosine similarity in word vectors:
| Aspect | Description | Quantitative Measure / Observation |
|---|---|---|
| Opposite sentiment words in similar contexts | Context-based learning causes embeddings of words with opposite sentiment polarities to have high similarity | High cosine similarity despite opposite sentiment |
| Same polarity sentiment words in relevant contexts | Embeddings show low similarity even when contexts are sentiment-relevant | Low cosine similarity |
| Between-class vs. within-class similarity | Average cosine similarity between sentiment classes is comparable or higher than within-class similarity | Between-class: 0.6685; Within-class positive: 0.6668; Within-class negative: 0.6881 |
Researchers found that adding lexical knowledge to word vectors can help separate meanings better. This method projects vectors into a new space, making it easier to tell words apart by their sentiment. Studies also show that combining local and global context from the corpus improves word vectors. Models that use both types of context perform better on tasks like text classification and corpus analysis. Contextual learning even helps word vectors match patterns found in the human brain, showing the power of context in machine learning.
Embedding Models
Popular Models
Researchers have developed many word embedding models to help computers understand language and images. These models use a training corpus to learn how words and images relate. Some of the most popular embedding models include Sentence-BERT, SGPT, GTR, E5, Cohere Embed v3, and OpenAI text-embedding models. Each model uses a different approach to turn words and images into vectors. These vectors capture meaning from the corpus and help computers find patterns.
Surveys and benchmarks compare these embedding models across many tasks. The BEIR and MTEB benchmarks test models on information retrieval, clustering, and classification. The table below shows how these benchmarks evaluate different models:
| Benchmark/Survey Name | Description | Tasks Covered | Notable Embedding Models Compared | Leaderboard Link |
|---|---|---|---|---|
| BEIR | Benchmark for information retrieval tasks | 9 tasks including fact-checking, citation prediction, duplicate question retrieval, argument retrieval, news retrieval, question answering, tweet retrieval, biomedical IR, entity retrieval | Various embedding models evaluated | https://openreview.net/forum?id=wCu6T5xFjeJ |
| MTEB | Massive Text Embedding Benchmark analyzing performance across multiple tasks | 8 tasks including clustering, bitext mining, retrieval, semantic textual similarity, classification, pair classification, reranking | Sentence-BERT, SGPT, GTR, E5, Cohere Embed v3, OpenAI text-embedding models | https://huggingface.co/spaces/mteb/leaderboard |
Researchers use these benchmarks to see which word embedding models work best for different applications. The NVIDIA Text Embedding Model, for example, achieves a high NDCG@10 score of 69.32 across 56 tasks. This shows strong retrieval performance and highlights the power of new model architectures.
Application in Vision
Word embedding models play a key role in machine vision systems. These models use vectors to connect language and images, making it easier for computers to understand both. In real-world applications, embedding models help with defect detection, automated inspection, and quality control. They often outperform humans in accuracy and speed.
Researchers have shown that embedding models like Vlm2Vec improve Precision@1 by 17.3 points, from 42.8% to 60.1%, across 36 multimodal embedding datasets. On zero-shot tasks, the model increases Precision@1 by 11.6 points. These results show that embedding models generalize well and handle new data from different domains. Ablation studies reveal that the LoRA variant of Vlm2Vec performs better than full fine-tuning, proving the practical value of embedding models.
Note: Improving label quality in the training data can boost model efficiency by up to 88%. This highlights the importance of good data for training embedding models.
Researchers also use embedding models in customer feedback analysis, document classification, and social media monitoring. For example, Sentence Transformers and SciBERT help group and visualize large sets of unstructured data. These models use vectors to cluster similar items, reducing manual work by up to 80%. In vision, models like CLIP map images into embedding spaces, making it possible to organize and search visual data. These applications show how embedding models transform both language and vision tasks using vectors learned from a large corpus.
Vector Representations
From One-Hot to Vectors
Early machine learning models used one-hot encoding to represent words. In this method, each word in a corpus became a long vector with only one value set to one and the rest set to zero. This approach created very large and sparse vectors. For example, a corpus with 10,000 words would need a 10,000-dimensional vector for each word. These vectors did not show any relationship or similarity between words. The model could not tell if two words had similar meanings or appeared in similar contexts.
Researchers developed new encoding methods to solve these problems. Label encoding and ordinal encoding reduced the size of the vectors but still did not capture relationships. Binary encoding helped lower the number of dimensions. Frequency and target encoding added information about how often a word appeared in the corpus or its connection to a target value. However, these methods still used fixed representations.
The real breakthrough came with embedding layers in neural networks. These layers learned dense, low-dimensional word vectors during training. Each word in the corpus received a unique vector that captured its meaning and relationships. Models like Word2Vec and GloVe trained on large corpora and created word vectors that reflected how words appeared together. Contextual models like BERT went further by creating vectors that changed based on the surrounding words in the corpus. Autoencoders also learned compact vector representations by compressing and reconstructing input data. This shift from static one-hot vectors to learned word vectors marked a major step forward.
| Encoding Method | Use Case Example | Key Advantages Over One-Hot Encoding |
|---|---|---|
| One-Hot Encoding | E-commerce product categories | Simple, treats categories equally, but high dimensionality and sparsity |
| Label Encoding | Player positions in sports analytics | Efficient integer representation, suitable for tree-based models, no false hierarchies |
| Ordinal Encoding | Customer feedback ratings | Preserves natural order in categories |
| Binary Encoding | ZIP codes in delivery logistics | Reduces dimensionality drastically (e.g., 500 ZIP codes → ~9 columns) |
| Frequency Encoding | Retail product sales frequency | Captures popularity patterns, useful in demand forecasting |
| Target Encoding | Real estate average house price by neighborhood | Encodes categories by target mean, captures relationship with target, but risks overfitting |
Advantages
Word vectors offer many advantages over older encoding methods. Dense vectors use much less memory and make models faster. Each word vector captures the meaning of a word and its relationship to other words in the corpus. When two word vectors are close together, it means the words have similar meanings or appear in similar contexts. Models use cosine similarity to measure how close two vectors are. Cosine similarity checks the angle between two word vectors. A small angle means high similarity.
Vector representations also help models learn patterns in the corpus. For example, the Fréchet Inception Distance (FID) uses vectors to compare generated images to real ones. Lower FID scores mean the generated images are more similar to real images. This method is more sensitive than older metrics and matches human judgment better. In biology, encoding protein structures as vectors lets models find patterns that older methods miss.
Dense word vectors reduce the risk of overfitting and handle large corpora better. Embedding layers in neural networks learn these vectors during training, capturing both local and global patterns. Models can now use word vectors to group similar words, find relationships, and improve tasks like search, classification, and translation. Cosine similarity and vector distance help models compare words and images, making AI systems smarter and more flexible.
Note: Embedding dimensionality often uses the square root of the number of categories in the corpus. This choice balances model size and learning power.
Multimodal Learning

Language & Vision
Multimodal learning combines language and vision by using embedding models that join word and visual vectors. These models help computers understand both text and images at the same time. Word embedding models map words into a vector space, while visual embedding models do the same for images. When these vectors are combined, the model can compare and connect information from both sources. This approach improves the ability of computer vision systems to interpret complex scenes and answer questions about images.
Researchers use large datasets to train these embedding models. Some popular datasets include COCO, Visual Genome, Conceptual Captions, and Webvid-2M. Newer datasets like LLaVA’s 158,000 language-image instruction-following samples and the MIMIC-IT dataset help models learn from both images and text. These resources allow embedding models to build stronger connections between language and vision, leading to better performance in real-world applications.
- COCO and Visual Genome provide paired images and captions for training.
- Conceptual Captions and Webvid-2M offer millions of image-text pairs.
- LLaVA and MIMIC-IT datasets support instruction-following and in-context learning.
Real-World Uses
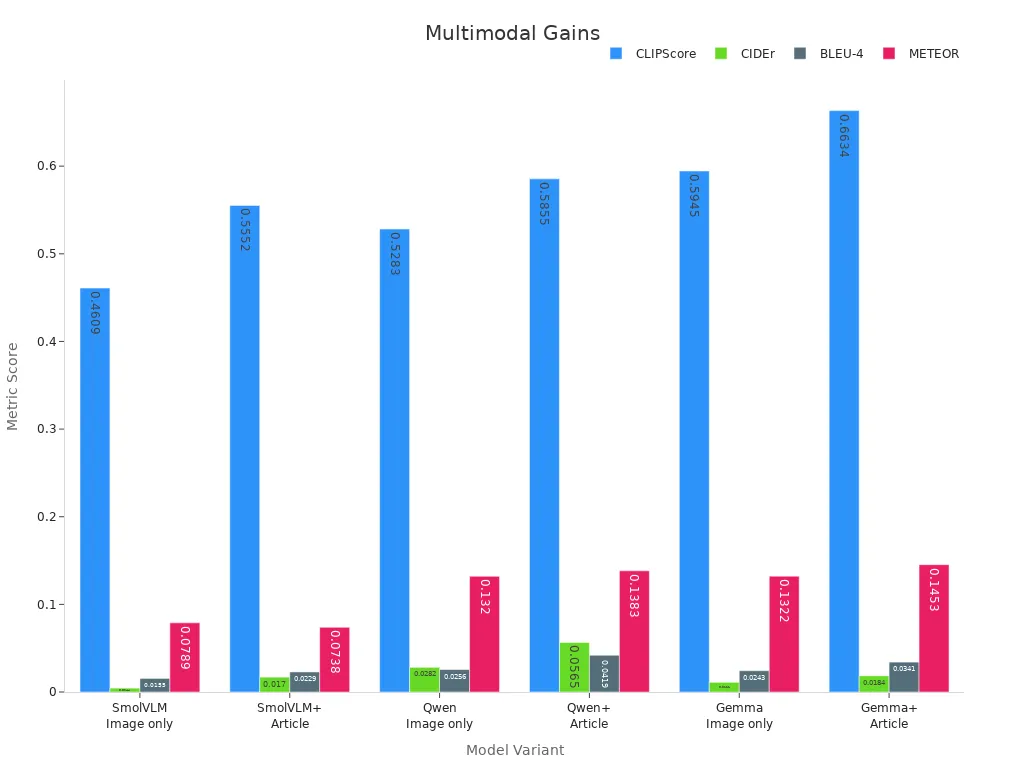
Embedding models power many real-world applications. In image captioning, models that use both image and article text outperform those using images alone. The OpenEvents V1 benchmark shows that adding textual context improves metrics like CLIPScore, CIDEr, BLEU-4, and METEOR.
| Model Variant | CLIPScore | CIDEr | BLEU-4 | METEOR |
|---|---|---|---|---|
| SmolVLM (Image only) | 0.4609 | 0.0044 | 0.0155 | 0.0789 |
| SmolVLM + Article | 0.5552 | 0.0170 | 0.0229 | 0.0738 |
| Qwen (Image only) | 0.5283 | 0.0282 | 0.0256 | 0.1320 |
| Qwen + Article | 0.5855 | 0.0565 | 0.0419 | 0.1383 |
| Gemma (Image only) | 0.5945 | 0.0111 | 0.0243 | 0.1322 |
| Gemma + Article | 0.6634 | 0.0184 | 0.0341 | 0.1453 |
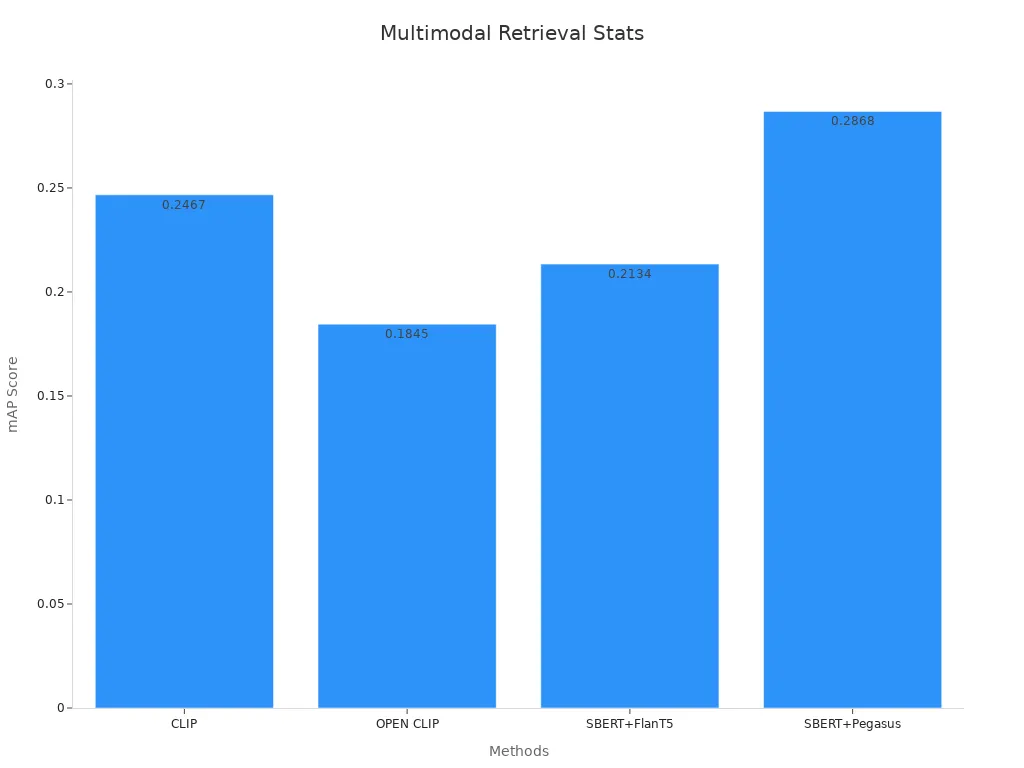
Multimodal embedding models also improve event-based image retrieval. Retrieval systems that use both textual semantics and visual similarity achieve higher accuracy than those using only image-caption matching.
| Method | mAP | NDCG | NN | AUC |
|---|---|---|---|---|
| CLIP (image-text only) | 0.2467 | 0.3407 | 0.1586 | 0.0302 |
| OPEN CLIP | 0.1845 | 0.2703 | 0.1845 | 0.0185 |
| SBERT + Flan T5 | 0.2134 | 0.2837 | 0.1376 | 0.0220 |
| SBERT + Pegasus | 0.2868 | 0.3665 | N/A | N/A |
| SBERT + Bart + CLIP | >0.32 | N/A | >0.22 | N/A |
In visual question answering, combining mono-modal and cross-modal retrieval methods leads to a 32% improvement in Precision@1 on the ViQuAE dataset. Similar gains appear on other datasets, showing that embedding models can answer questions about images more accurately. These advances support applications such as recommendation systems, recommender systems, and other real-world applications in computer vision.
Embedding models transform machine vision by connecting language and images through vector representations. Research shows that embedding models, when trained on a large corpus, improve AI performance and enable real-time processing. Word vectors help models learn meaning, while multimodal embedding supports accurate evaluation and validation. Studies highlight that embedding models increase speed, efficiency, and reliability, especially on mobile devices. The market for embedding in vision systems continues to grow, driven by advances in hardware and software. Validating the model with real-world data and ongoing research ensures that embedding models remain essential for future innovation.
FAQ
What is a corpus in machine vision systems?
A corpus is a large collection of text or images that researchers use to train models. The corpus helps models learn patterns and relationships. Each model uses the corpus to build word vectors and connect language with visual data.
How do embedding models use a corpus?
Embedding models analyze the corpus to find how words and images relate. The model learns from the corpus by mapping words and images into vectors. These models use the patterns in the corpus to improve understanding and accuracy.
Why do models need both language and visual data?
Models need both language and visual data to understand complex information. A model that uses only text or only images misses important details. By combining both, models can connect words to objects and actions found in the corpus.
How do models improve with a larger corpus?
A larger corpus gives models more examples to learn from. The model can find more patterns and relationships. When models train on a bigger corpus, they usually perform better on tasks like image recognition and text analysis.
What makes some embedding models better than others?
Some embedding models work better because they use advanced training methods and larger corpus data. The model architecture, the quality of the corpus, and how the model learns from the corpus all affect performance. Researchers compare models to find the best results.








