
A token machine vision system lets you see and understand images in a new way. In 2025, you use this technology to solve real-world problems faster than before. You do not look at every single pixel. Instead, you use small pieces called tokens. These tokens help you focus on important parts of a picture. Many industries use a token machine vision system to improve computer vision and make smarter decisions.
Key Takeaways
- Token machine vision systems use small pieces called tokens to focus on important parts of images, making image processing faster and more accurate.
- These systems combine process tokens and memory tokens to analyze images efficiently and remember key details, improving decision-making.
- Hierarchical token grouping and token pruning methods boost accuracy and speed while reducing computing power and energy use.
- Token-based vision systems excel in tasks like image recognition, semantic segmentation, and defect detection, helping industries improve quality and efficiency.
- Real-time integration with edge devices and API gateways allows quick responses and flexible operations in factories and other settings.
Token Machine Vision System Basics
What Are Tokens?
You can think of tokens as small, meaningful pieces of an image. Instead of looking at every pixel, a token machine vision system groups pixels into tokens. Each token represents important information, like a shape, color, or pattern. This approach helps you focus on the parts of an image that matter most.
A vision transformer uses these tokens to understand images. You do not need to process every detail. You only need to pay attention to the tokens that carry useful information. This method makes image recognition much faster and smarter.
Tip: Tokens help you ignore background noise and highlight the main objects in a picture. This makes tasks like image classification and semantic segmentation easier for both people and machines.
How Tokens Process Images
When you use a token machine vision system, you start by breaking an image into tokens. The vision transformer then arranges these tokens in a way that helps the system learn patterns. You can imagine each token as a puzzle piece. When you put the pieces together, you see the whole picture.
Here is how the process works:
- You split the image into patches.
- The system turns each patch into a token.
- The vision transformer looks at all tokens and finds connections between them.
- The system uses these connections to make decisions, such as recognizing objects or sorting items.
You get several benefits from this method:
- You process images faster. Some systems show up to 46.8% lower latency on powerful GPUs compared to older models.
- You see better accuracy. For example, token pruning methods can reach up to 99.01% accuracy on popular datasets, which is higher than many traditional models.
- You use less computing power. Hybrid models with token pruning need fewer calculations but still give you better results than older vision transformer or CNN models.
- You improve throughput. Some methods double the number of images you can process at once, even without retraining the system.
You use token machine vision systems for many computer vision tasks, such as image recognition and image classification. These systems help you solve real-world problems, from sorting coins to finding defects in products. You also get better results in semantic segmentation, where you need to label every part of an image.
Note: Token-based systems now outperform many conventional computer vision models. You get better accuracy and speed, even when you use less computing power.
Vision Token Turing Machines
Process and Memory Tokens
You use token turing machines to solve vision tasks in a smarter way. These systems do not just process images in a straight line. Instead, they use two special types of tokens: process tokens and memory tokens. Each type has a unique job.
- Process tokens help you handle the main steps of image analysis. They move through the system, carrying important details about the image. You can think of them as workers who look at different parts of a picture and report what they see.
- Memory tokens store information from earlier steps. They act like a notebook, letting you remember what you have already learned. This helps the system keep track of patterns and details across the whole image.
When you combine process tokens and memory tokens, you get a system that can focus on what matters most. You do not waste time on unimportant details. Instead, you keep the important information and use it to make better decisions.
Note: Research shows that when you prune or merge tokens, you make the system faster and more stable. This method also helps the model stay robust and clear, even when you use it for hard tasks like driving a car or controlling a robot. By focusing on the most useful tokens, you help the machine pay attention to changes that matter, just like your own eyes do.
Recent studies also show that adding local context to tokens, using special modules like LIFE, boosts the performance of vision transformers. You see better results in tasks like object detection and image segmentation. These improvements come with little extra cost in speed or memory. The system learns to look at the right parts of an image, making your results more accurate and reliable.
Architecture Overview
You can picture the architecture of token turing machines as a smart assembly line. Each part of the system has a clear job. Here is how it works:
- Image Input: You start with an image. The system splits it into small patches.
- Token Creation: Each patch becomes a token. Some tokens will act as process tokens, while others become memory tokens.
- Processing Layer: Process tokens move through layers, picking up details and learning patterns.
- Memory Layer: Memory tokens store key information from each layer. They help the system remember what it has seen before.
- Decision Making: The system uses both types of tokens to make sense of the image. It can recognize objects, spot defects, or sort items.
| Step | What Happens | Token Type |
|---|---|---|
| Image Input | Split image into patches | – |
| Token Creation | Turn patches into tokens | Process, Memory |
| Processing Layer | Analyze and learn from tokens | Process |
| Memory Layer | Store and recall important details | Memory |
| Decision Making | Use all information for predictions | Both |
You use token turing machines for many vision tasks that need quick and accurate results. These systems work well for non-sequential tasks, where you do not need to follow a strict order. For example, you can use them to check for defects in products or to help robots understand their surroundings.
Tip: By using both process and memory tokens, you make your machine vision system more efficient and reliable. You get better results, even when you work with complex images or long video sequences.
Vision token turing machines help you handle large amounts of visual data. They let you focus on the most important parts of an image, store what you learn, and make smart decisions. You see improvements in speed, accuracy, and the ability to handle real-world challenges.
Key Features and Improvements
Hierarchical Token Grouping
You can use hierarchical token grouping to make image analysis more structured and accurate. This method lets you organize tokens at different levels, from simple shapes to complex objects. When you group tokens in a hierarchy, you help the system focus on both fine details and big-picture patterns. For example, the H-CAST method aligns how the system looks at images across different levels. On the Aircraft dataset, this approach improves Full-Path Accuracy by about 11.6 percentage points. On the CUB dataset, you see a 6.3-point gain. These improvements show that hierarchical token grouping makes your results more consistent and reduces mistakes between different levels of analysis. You get better accuracy and fewer conflicts when the system uses both fine and coarse features together. This technique helps you build efficient vision models that handle complex images with ease.
Efficiency and Accuracy
You want your vision system to be fast and reliable. Token-based models give you both. They use fewer tokens but keep high accuracy. For example, the AT-SNN approach uses up to 42.4% fewer tokens than older methods on the CIFAR-100 dataset. You still get higher accuracy and better energy efficiency. The TRAM token pruning method also cuts down on computation while keeping results as good as state-of-the-art models. These advances mean you can process more images in less time. You achieve competitive accuracy-latency trade-offs, which is important for real-world tasks. The table below shows how token machine vision systems outperform traditional methods in several key metrics:
| Metric | Description | Statistical Significance |
|---|---|---|
| Model Accuracy (Supervised) | Baseline accuracy using traditional supervised learning methods | N/A |
| Model Accuracy (Semi-Supervised/Self-Supervised) | Accuracy achieved using token-based self-supervised or semi-supervised learning methods | p < 0.05 (significant improvement) |
| Mean Average Precision (mAP@0.5:0.95) | Measures object localization accuracy across IoU thresholds from 0.5 to 0.95 | N/A |
| Average Precision (AP@0.5 and AP@0.3) | Evaluates detection accuracy, with AP@0.3 focusing on smaller objects | N/A |
| Intersection-over-Union (IoU) Scores | Quantifies segmentation and classification accuracy, indicating precise boundary detection | N/A |
| Correlation Coefficients (r) | Overlap and inter-class aSTD metrics showing robustness and generalization (r=0.99, r=0.96) | N/A |
You see that state-of-the-art token-based systems deliver better accuracy, object detection, and generalization, especially when you have limited labeled data. These improvements help you reach competitive accuracy-latency trade-offs in many applications.
Semantic Segmentation
You use semantic segmentation to label every part of an image. Token-based vision systems make this task more accurate and stable. Dual-branch TokenMix methods, like D1 and D3, show higher mIoU scores than other designs, even when you have fewer labeled images. The table below shows how these methods perform on the Pascal VOC 2012 benchmark:
| Branch Design / Method | 732 Labels mIoU | 366 Labels mIoU | 183 Labels mIoU | 92 Labels mIoU |
|---|---|---|---|---|
| Dual TokenMix (D1) | 77.07 | 76.22 | 75.50 | 71.48 |
| TokenMix and Dropout Divergent (D2) | 77.18 | 75.58 | 74.51 | 70.09 |
| Dual TokenMix with Dropout (D3) | 77.35 | 76.12 | 75.40 | 72.90 |
| Dual TokenMix and Single Dropout (D4) | 77.28 | 75.77 | 75.34 | 70.41 |
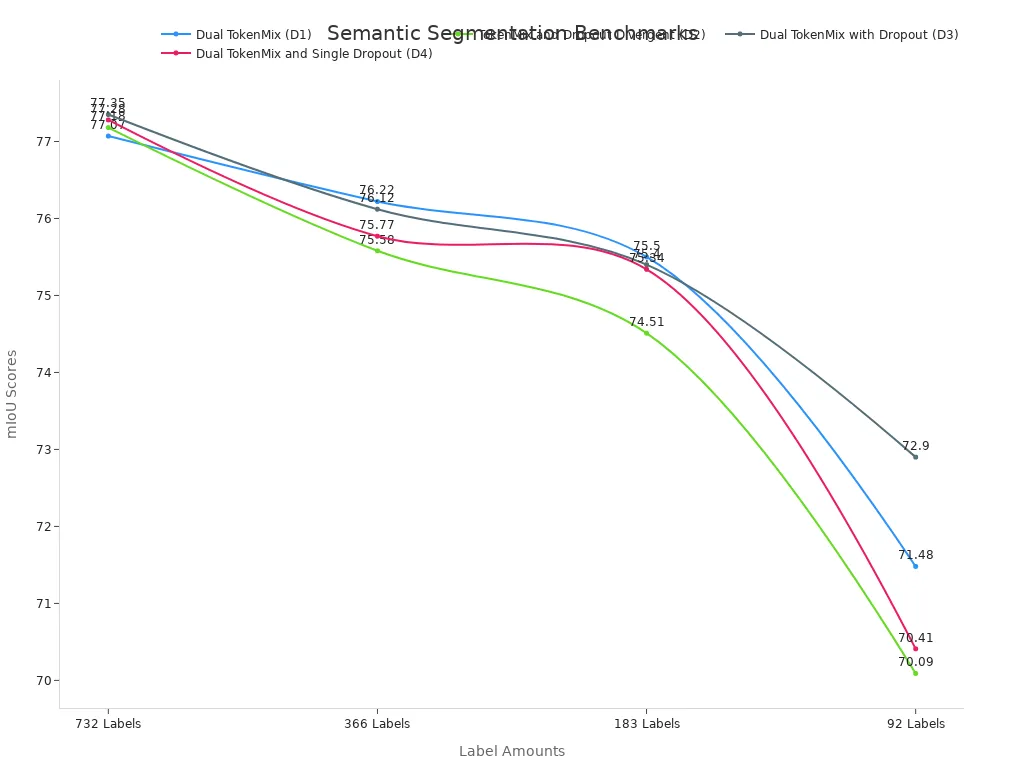
You also improve results by tuning hyperparameters. For example, a confidence threshold of 0.95 and a high momentum decay factor give you the best mIoU scores with only 92 labels. Token-based systems work well with state-of-the-art models like Swin Transformer and SegFormer-B5. You see better object boundaries and more stable results in real-world images. This makes semantic segmentation more powerful and reliable for your projects.
Real-World Applications

Industrial and Manufacturing Uses
You see token machine vision systems making a big difference in factories and warehouses. These systems help you sort coins, scan barcodes, and guide robots with high speed and accuracy. Many companies use them to handle thousands of parts every hour. You can reduce labor costs and improve quality control at the same time.
Here is a table showing how these systems improve industrial performance:
| Metric / Example | Description / Value |
|---|---|
| Classification accuracy improvement | 20% increase over traditional algorithms |
| Parts handled per hour by robots | Up to 10,000 parts |
| Reduction in quality assurance labor | About 50% reduction |
| Robotic part-picking efficiency | Over 40% increase |
| Barcode reading accuracy | Up to 30% higher than traditional scanners |
| Sorting error reduction | 25% fewer errors |
| High-density barcode reading accuracy | 98% accuracy rate |
| Real-world company examples | Siemens, Tyson Foods, Toyota, Walmart, Amazon, Pfizer |
You can also see these improvements in the chart below:
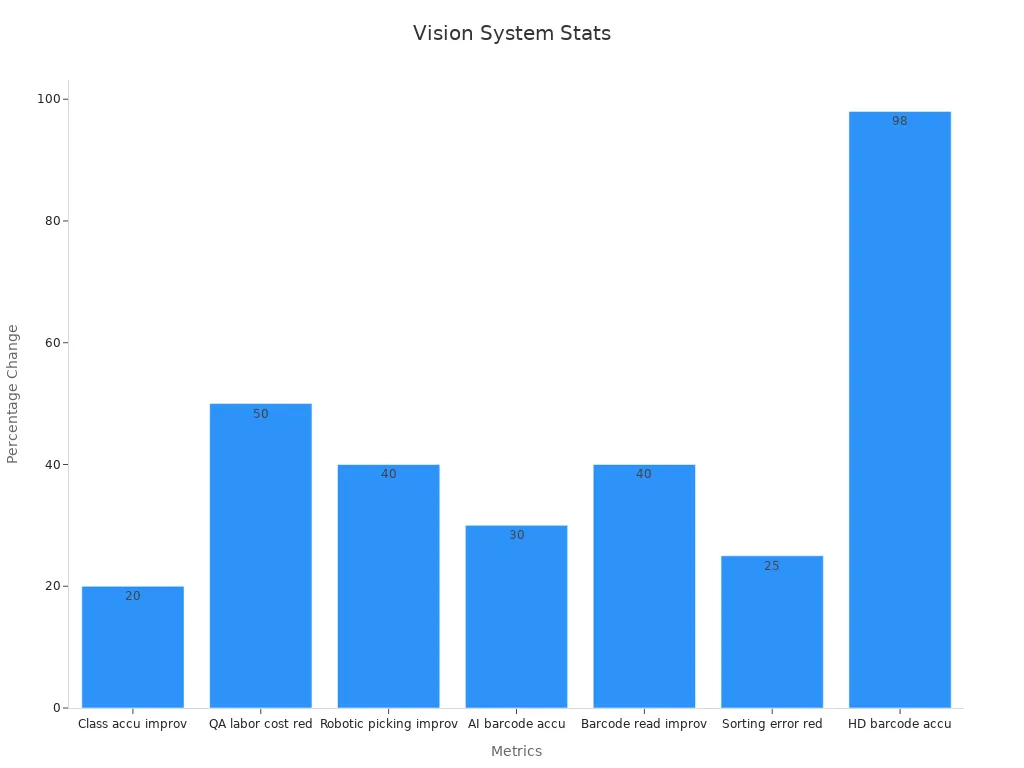
Tip: When you use token-based systems, you get faster sorting and fewer mistakes, even in tough environments with glare or poor lighting.
Defect Recognition
You can use token machine vision systems to spot defects in products with high accuracy. These systems help you find small, medium, and large defects that older systems might miss. You get better results because the system learns from each image and adapts to new types of defects.
The table below shows how different modules perform in defect recognition:
| Module | Small Defects Accuracy | Medium Defects Accuracy | Large Defects Accuracy | Normal Sample Accuracy | Overall Accuracy |
|---|---|---|---|---|---|
| Baseline (LLaVA-1.6) | 100.0% | 100.0% | 100.0% | 16.1% | 76.9% |
| AnyRes (Finetune) | 90.9% | 81.0% | 65.7% | 82.9% | 79.8% |
| EG-RoI (Finetune) | 95.5% | 94.1% | 81.8% | 72.8% | 85.0% |
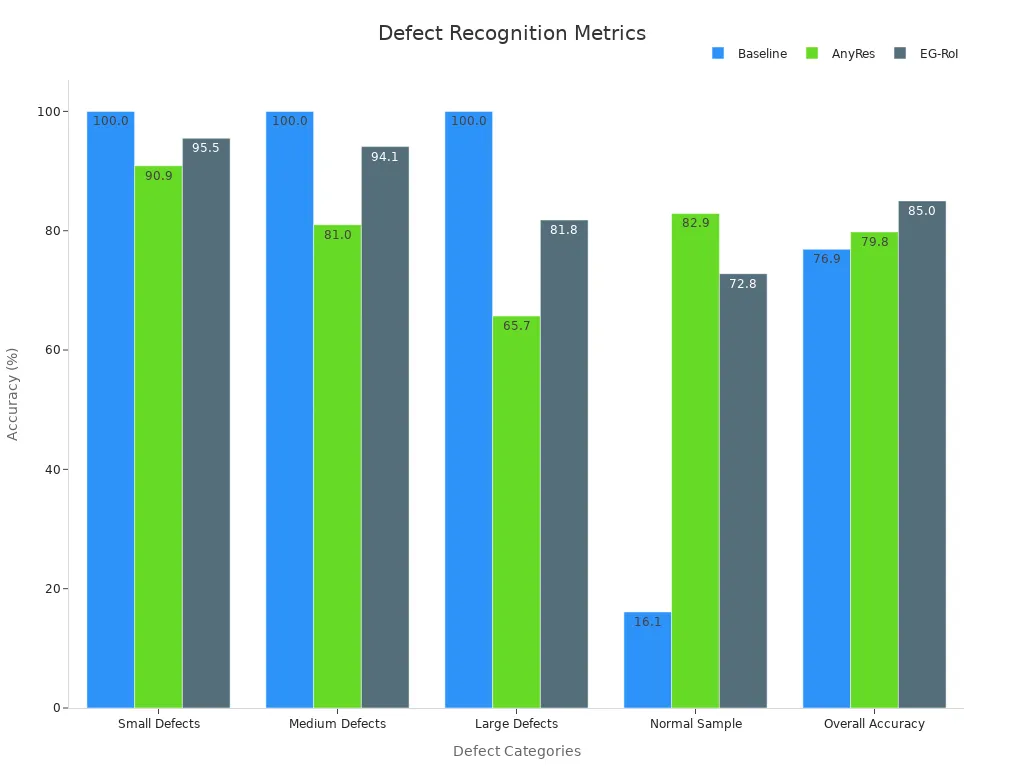
You can trust these systems to keep your production line running smoothly. They help you catch problems early and reduce waste.
API Gateway Integration
You can connect token machine vision systems to API gateways and edge devices for real-time processing. This setup lets you send images from cameras straight to the vision system. You get instant feedback and quick decisions. For example, you can use image recognition to sort products or check for defects as soon as they appear on the line.
Many factories use edge devices to process images close to where you collect them. This reduces delays and keeps your data secure. You can also scale your system easily by adding more devices or connecting to cloud services through APIs.
Note: Real-time integration helps you respond to changes fast. You improve efficiency and keep your operations flexible.
You now understand how a token machine vision system helps you process images faster and more accurately.
- You see better results in factories, quality control, and real-time tasks.
- You use less computing power and get smarter decisions.
Stay curious! New advances in machine vision arrive every year. You can follow these changes to keep your skills sharp and your projects successful.
FAQ
What is the main benefit of using tokens in machine vision?
You focus on important parts of an image. Tokens help you process images faster and with better accuracy. You use less computing power and get smarter results.
Can you use token machine vision systems with older cameras?
Yes, you can. Most systems work with standard image formats. You do not need special cameras. You only need to connect your camera to the vision system.
How do token machine vision systems handle privacy?
Token systems often process images on local devices. You keep your data secure and private. You do not need to send images to the cloud unless you want to.
Are token-based models hard to set up?
You find many systems easy to install. Most come with guides and support. You can start with basic settings and adjust as you learn more.
Where can you use token machine vision systems outside factories?
- You can use them in:
- Retail stores for shelf monitoring
- Hospitals for medical imaging
- Farms for crop inspection
- Smart cities for traffic analysis
See Also
Comprehensive Overview Of Semiconductor Vision Systems Technology
Future Trends In Machine Vision Segmentation For 2025
Understanding Pixel-Based Vision Systems In Contemporary Uses








