
A neural networks machine vision system almost always finds patterns because designers train these systems to associate input and output through weighted connections. This deep ability brings both power and risk. For example, in artificial intelligence, deep learning methods help machine vision systems recognize complex shapes. However, deep models sometimes lose important details when data points are too close together or too small, especially if the system uses traditional error measures. Deep solutions, such as adjusting neuron activation curves, help improve accuracy, but deep pitfalls remain.
Key Takeaways
- Neural networks in machine vision find patterns by analyzing images through feature extraction, training, and decision-making steps.
- Choosing the right feature extraction method improves accuracy and helps the system handle different image conditions effectively.
- Deep learning models can overfit by memorizing training data, so techniques like regularization and cross-validation are essential to prevent errors.
- Neural networks sometimes see patterns in random noise, which can cause mistakes; methods like data augmentation help reduce this risk.
- Applications like object detection, medical imaging, and industrial inspection benefit from neural networks but require careful training to avoid false positives.
Pattern Recognition
Pattern recognition stands at the core of every neural networks machine vision system. These systems use deep learning and machine learning to analyze images, extract meaningful features, and make reliable decisions. The process involves three main steps: feature extraction, training and learning, and decision-making. Each step plays a vital role in computer vision, image classification, and image recognition tasks.
Feature Extraction
Feature extraction helps neural networks identify important patterns in images. The system scans each image to find edges, textures, shapes, and colors. Deep learning algorithms, such as convolutional neural networks (CNNs), use layers to detect simple features in early layers and more complex patterns in deeper layers. This process allows the neural network to focus on the most useful information for image classification and recognition.
Note: Selecting the right feature extraction method is crucial for computer vision tasks. The table below shows how different algorithms perform under various image conditions:
| Image Transformation Condition | Recommended Feature Extractor(s) | Key Empirical Findings |
|---|---|---|
| Real-time applications (speed critical) | FAST (detector), ORB (descriptor), BF matcher | Fastest extraction and matching times, suitable for real-time machine vision tasks. |
| Affine-transformed images | ORB | Preferred for handling affine transformations effectively. |
| Blurring, rotation, scaling | AKAZE | Demonstrated superior robustness, ideal for compromised image quality. |
| Barrel fisheye distortion | SURF, SIFT, KAZE, AKAZE | Similar matching accuracy performance under fisheye distortion. |
| Horizontal/vertical perspective distortion | AKAZE or STAR (detector) + DAISY (descriptor) | Optimal performance for perspective distortions. |
| Significant brightness variations | ORB | Highest matching success under varying illumination conditions. |
| Salt-and-pepper noise | BRISK | Best performance in presence of salt-and-pepper noise. |
Empirical studies show that ORB works best when images have different brightness levels. AKAZE performs well with rotated or scaled images. These findings highlight the importance of choosing the right feature extractor for each computer vision application.
Performance metrics such as accuracy, F1 score, and mean squared error help measure the quality of feature extraction. Normalization techniques like min-max scaling and z-score standardization improve the stability and speed of deep learning algorithms. Ensemble methods, such as bagging and boosting, combine different feature extraction techniques to increase accuracy and robustness in machine learning.
Training and Learning
Training forms the backbone of every neural network. During training, the system learns to connect features from images to specific labels or categories. Deep learning methods use large datasets of labeled images to teach the neural network how to recognize patterns. The process involves adjusting weights and biases in the network to minimize errors.
Deep learning algorithms use cost functions, such as mean squared error, to measure the difference between predicted and actual outputs. Optimization techniques like gradient descent help the neural network update its parameters and improve accuracy. Backpropagation allows the system to calculate errors and adjust weights across all layers, making learning more effective.
Machine learning and deep learning rely on repeated training cycles. Each cycle helps the neural network improve its ability to recognize patterns in new images. The more diverse and high-quality the training data, the better the system performs in real-world computer vision tasks.
Decision-Making
Decision-making is the final step in pattern recognition. After feature extraction and training, the neural networks machine vision system uses its learned knowledge to classify new images. The system assigns importance to different features using weighted inputs and biases. Activation functions, such as sigmoid or ReLU, transform these weighted sums into outputs between 0 and 1. This process allows the neural network to make reliable decisions, even when images contain noise or distortions.
- Neural networks use weighted inputs and biases to decide which features matter most.
- Activation functions create nonlinear boundaries, helping the system handle complex image recognition tasks.
- Cost functions guide the learning process by measuring prediction errors.
- Optimization techniques, like gradient descent, improve accuracy by updating weights and biases.
- Backpropagation ensures precise updates throughout the neural network.
- CNNs use matrix multiplication to detect patterns in images, providing a strong foundation for computer vision.
Deep learning methods and deep learning algorithms have transformed artificial intelligence and computer vision. These advances allow ai systems to achieve high accuracy in image classification, object detection, and other vision tasks. However, the system’s ability to always find patterns means it can sometimes see structure where none exists. Careful training and validation help reduce these risks and improve the reliability of machine learning and deep learning solutions.
Why Patterns Emerge
Mathematical Basis
Deep learning models in computer vision work by connecting many layers of artificial neurons. Each layer processes information from the previous one. This structure allows the system to find patterns at different levels. Researchers use graph theory to measure how well these networks connect across layers. They count the number of paths between nodes in different layers. A higher number means the network can form more complex patterns. When engineers design networks with more connections, the system learns faster and performs better in vision tasks.
Scientists also use a framework called computational mechanics to explain how patterns appear. This method uses devices called ε-machines. These devices predict future states based on current ones. They group similar states together, creating a hierarchy. This helps explain how simple actions in one part of the network can lead to big patterns in the whole system. In deep learning, this means the network can recognize objects or shapes even if the details change. The mathematical structure of deep learning models gives them a strong ability to find patterns in images.
Overfitting Risks
Deep learning models in computer vision often face the problem of overfitting. Overfitting happens when a model learns the training data too well, including its noise and random details. This makes the model perform poorly on new images. Overfitting is common in deep learning because these models have many parameters and can memorize data.
- Zhang et al. (2016) showed that deep learning models can fit even corrupted datasets with zero training error. This means the model learns every detail, even if it is not useful.
- The bias-variance tradeoff curve shows that as models become more complex, they first improve but then start to overfit.
- In one example, a model fits 10 samples perfectly but fails to work on new data. This shows overfitting in a simple way.
- In a breast cancer metastasis study, the training AUC kept rising, but the test AUC dropped. This means the model did well on training data but not on new data.
Overfitting often appears when the model has high variance and low bias. A model with a very high R-squared value may fit the noise instead of the real signal. In computer vision, a model might get over 98% accuracy on training images but only 50% on new images. This shows the model memorized the training set instead of learning general rules. Cross-validation methods, like k-fold or leave-one-out, help detect overfitting. Using separate test sets and checking metrics like AUC and F1 Score also help measure overfitting risk. Causes include too few training examples, too many features, or models that are too complex.
Tip: Regularization and careful validation can help reduce overfitting in deep learning models.
Structure in Noise
Deep learning models in computer vision often find patterns even when none exist. This happens because the models look for structure in every image they see. The mathematical design of deep learning networks makes them sensitive to any regularity, even if it is just random noise. When the system sees random dots or lines, it may still try to group them or find shapes.
This tendency can cause problems in real-world applications. For example, in anomaly detection, the model might flag normal images as unusual because it sees a pattern in random noise. In deep learning, this is called "hallucination." The model creates a pattern where there is none. This happens because deep learning models have many layers and can fit almost any data. The more complex the model, the more likely it is to find structure in noise.
Computer vision engineers use techniques like data augmentation and dropout to make models less sensitive to noise. These methods help the model focus on real patterns instead of random details. Still, the risk remains, especially in deep learning systems with many parameters. Understanding this behavior is important for anyone using deep learning in vision tasks.
neural networks machine vision system Applications

Object Detection
Object detection stands as one of the most important computer vision applications. Deep learning models help machines find and classify objects in images. These systems use large datasets, such as MS COCO, to test how well they work. Engineers measure performance using metrics like frames per second (FPS), power use, and cost. They test models like YOLOv3, YOLOv5, and YOLOX on devices such as NVIDIA Jetson Nano and Google Coral Dev Board.
- FPS shows how fast the system can process images.
- FPS/Power Consumption tells how efficient the model is.
- FPS/Cost helps compare different systems for budget planning.
Deep learning models can detect many objects in real time. However, these systems sometimes make mistakes. They may see objects that are not there, which leads to false positives. Adversarial examples can also trick deep models into making wrong detections.
Medical Imaging
Medical imaging uses deep learning to help doctors find diseases in images. Researchers have tested many deep learning applications in this field. The table below shows some results:
| Study / Author | Model Type | Dataset Size | Reported Accuracy and Metrics | Key Advantages |
|---|---|---|---|---|
| Shahzadi et al. | Cascaded brain tumor classifier | 100 | High accuracy | Accurate classification |
| Srikantamurthy et al. | Hybrid breast cancer classifier | 5,000 | High accuracy, robust | Large-scale training |
| Banerjee et al. | CNN + LSTM for cancer images | 828 | High accuracy, AUC | Multi-metric performance |
| Nandhini Abirami et al. | Deep CNNs and GANs | 70,000 | High accuracy, robust | Adaptable to large datasets |
Deep learning helps doctors find tumors, heart disease, and other problems in medical images. These models improve accuracy and help with early detection. Sometimes, deep models may find patterns that do not mean disease, which can cause false alarms.
Industrial Inspection
Industrial inspection uses deep learning to check products for defects. Deep models look at images from cameras on assembly lines. Transfer learning helps these models learn faster and reach higher accuracy. The table below shows how transfer learning improves results:
| Metric | Transfer Learning | Training from Scratch | Notes |
|---|---|---|---|
| Classification accuracy | 99.90% | 70.87% | Higher with transfer learning |
| Training convergence speed | Few iterations | 140 times longer | Faster with transfer learning |
| Accuracy drop after compression | 0.48% | Nearly 5% | More stable with transfer |
Deep learning applications in industrial inspection make factories safer and more efficient. These systems can spot tiny defects in images that humans might miss. Sometimes, deep models may detect problems that are not real, which can slow down automation.
Note: Deep learning powers many computer vision applications, including object tracking and detection. These systems work well with images, but users must watch for false positives and other errors.
computer vision Challenges
Misinterpretation
Neural networks in computer vision often face misinterpretation risks. Deep learning models sometimes memorize noise instead of learning real patterns. This leads to failures when the system faces new data. Many models show high accuracy during training but perform poorly in real-world detection tasks. Improper validation methods can hide these weaknesses. Ignoring uncertainty in predictions causes overconfident decisions, especially in anomaly detection. Some common issues include:
- Overfitting causes the model to memorize noise, not general patterns.
- Models may succeed on training data but fail in practical computer vision detection.
- Weak validation methods give a false sense of reliability.
- Ignoring uncertainty leads to risky decisions in deep learning detection.
- Monte Carlo dropout helps estimate uncertainty by running the same input through the model multiple times.
- Statistical tools like bias-variance tradeoff, cross-validation, and regularization help spot misinterpretations.
- Poor understanding of statistics or bad initialization can cause deep learning failures.
Bias and Errors
Bias and errors often appear in deep learning computer vision systems. These systems may favor certain patterns or classes, leading to unfair detection results. In anomaly detection, bias can cause the system to miss rare events or over-report normal ones. Errors also come from noisy data, poor labeling, or unbalanced datasets. Deep learning models sometimes amplify these problems, making detection less reliable. Engineers must watch for these issues in every vision project.
Mitigation Strategies
Engineers use several strategies to reduce bias and errors in deep learning computer vision. Regularization, cross-validation, and uncertainty estimation improve detection reliability. Empirical studies show that neural network-based mitigation methods work well. The table below compares different approaches:
| Mitigation Method | Accuracy (%) | Mean Squared Error (MSE) | Runtime Efficiency | Notes |
|---|---|---|---|---|
| Fully Neural Network (NN) AM | 99.99 | 0.00005 | Low overhead; 20 min mitigation time for 5000 circuits | Highest accuracy and lowest MSE among tested adaptive mechanisms. |
| Random Forest + NN AM | 99.17 | 0.00354 | Slightly higher overhead | Good performance but slightly less accurate than fully NN AM. |
| SVM + NN AM | 99.06 | 0.00401 | Slightly higher overhead | Slightly lower accuracy and higher MSE than fully NN AM. |
| Logistic Regression + NN AM | 98.27 | 0.00739 | Slightly higher overhead | Lowest accuracy and highest MSE among tested adaptive mechanisms. |
| Zero Noise Extrapolation (ZNE) | N/A | Higher than ANN-QEM | Longer runtime (over 12 h for 1800 circuits) | Traditional method with higher MSE and longer runtime compared to ANN-QEM. |
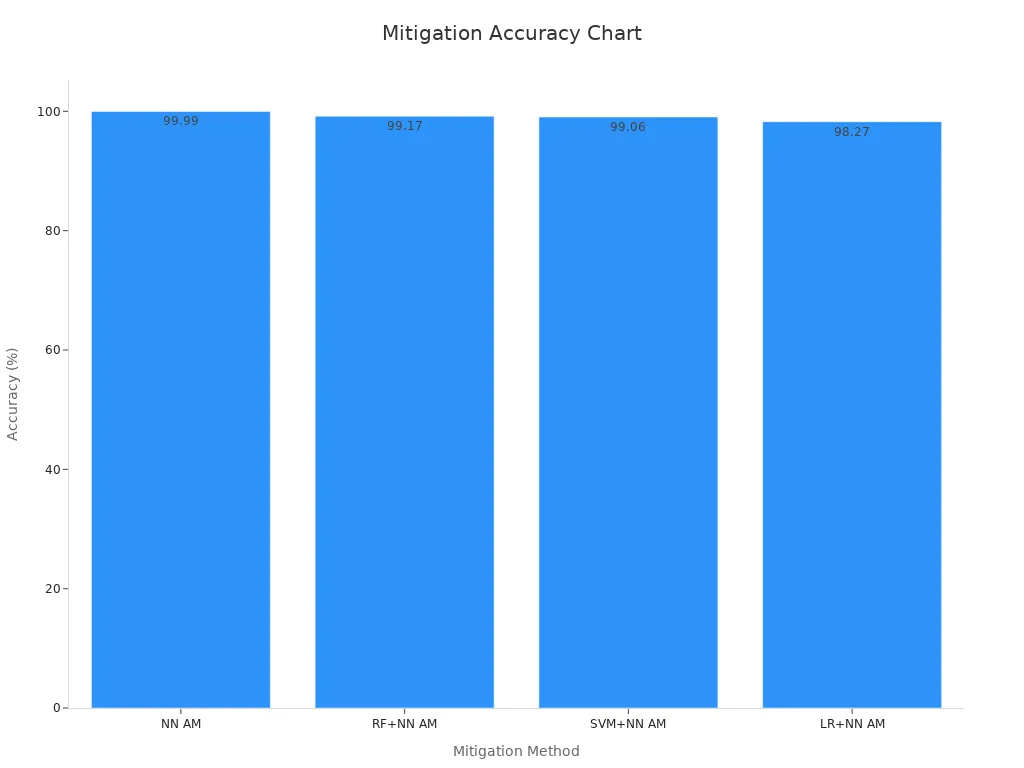
Deep learning and machine learning techniques can reduce detection errors by up to 50%. Adaptive neural networks improve accuracy and stability in anomaly detection. These strategies help computer vision systems make better decisions and avoid common deep learning pitfalls.
Neural networks machine vision systems show deep power in finding patterns. These deep systems help reduce injury risk, cut costs, and improve accuracy. Deep learning models reach up to 99% accuracy in tasks like license plate recognition. Deep automation leads to a 15% drop in material waste and deep model optimization doubles inference speed. Deep medical imaging gains a 35% resolution boost. Deep systems, however, need large labeled datasets and deep computational resources. Deep models act as black boxes and show deep sensitivity to input changes. Deep users must understand both strengths and deep risks. The table below highlights key deep benefits and deep limitations.
| Key Aspect | Numerical Summary / Metric |
|---|---|
| Injury Risk Reduction | Risk scores dropped from 14 to 4 and 14 to 2 in robotic applications, indicating improved safety |
| Cost Reduction from Automation | Expected cost reduction increased to 31% from 24% in 2020 |
| Accuracy Rates | Up to 99% accuracy in license plate recognition |
| Material Waste Reduction | 15% reduction in material waste |
| Model Optimization Effects | Model size reduced by 60-70% via quantization |
| Inference speed doubled (e.g., 40 ms to 20 ms) | |
| Power consumption cut by ~50% (e.g., 4J to 2J) | |
| Accuracy trade-off: 8-10% drop in visual quality | |
| Predictive Performance | R-squared values between 0.84 and 0.92 in coal property prediction |
| Medical Imaging Improvement | 35% resolution improvement using variational autoencoders |
| Limitations / Risks | Requires large labeled datasets, high computational resources, black-box decision processes, and sensitivity to input data changes |
Staying informed about deep advances and applying best practices helps users get the most from these deep systems.
FAQ
What is a neural network in machine vision?
A neural network in machine vision is a computer system that learns to recognize patterns in images. It uses layers of artificial neurons to process visual data and make decisions.
Why do neural networks sometimes see patterns that are not real?
Neural networks always look for structure in data. Sometimes, they find patterns in random noise because their design makes them sensitive to any regularity, even if it does not exist.
How can engineers prevent overfitting in deep learning models?
Engineers use regularization, cross-validation, and data augmentation to prevent overfitting. These methods help the model focus on real patterns and ignore random noise.
Where do people use neural networks in machine vision?
People use neural networks in machine vision for tasks like object detection, medical imaging, and industrial inspection. These systems help find objects, spot diseases, and check products for defects.
Can neural networks make mistakes in pattern recognition?
Yes, neural networks can make mistakes. They may see objects that are not there or miss important details. Careful training and validation help reduce these errors.
See Also
The Impact Of Neural Network Frameworks On Machine Vision
Is Machine Vision Using Neural Networks Able To Replace Humans
A Deep Dive Into Synthetic Data For Machine Vision
Understanding Pattern Recognition In Machine Vision Systems
Ways Deep Learning Improves The Performance Of Machine Vision








