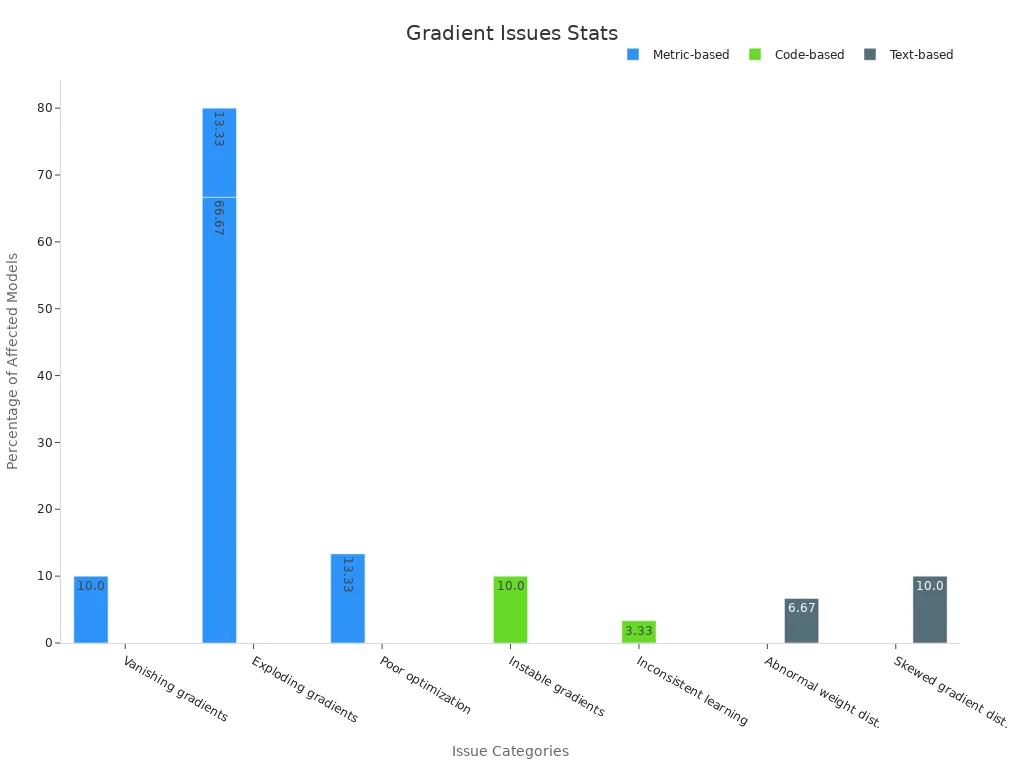
Vanishing and exploding gradients machine vision system problems can halt the learning process in deep neural networks. Imagine training a robot to see, but sometimes the learning signals either vanish, becoming too small to detect, or explode, growing so large they disrupt the system. In deep learning, these vanishing/exploding gradients machine vision system issues frequently occur in very deep neural networks. A recent study reveals that up to 66% of machine vision models experience exploding gradients, particularly in their output layers.
These vanishing/exploding gradients machine vision system challenges make it difficult for neural networks to accurately interpret images, hindering progress in deep learning.
Key Takeaways
- Vanishing gradients happen when learning signals shrink too much in deep networks, stopping early layers from learning important features.
- Exploding gradients occur when learning signals grow too large, causing unstable training and poor model performance.
- Choosing the right activation functions like ReLU and proper weight initialization methods helps keep gradients stable and improves learning.
- Techniques like batch normalization and gradient clipping make training deep vision models more stable and faster.
- Monitoring training signs and using tools to track gradients can help detect and fix gradient problems early, saving time and resources.
Vanishing/Exploding Gradients Overview
Vanishing Gradients
Vanishing gradients often appear in deep neural networks during the backpropagation algorithm. When a machine vision system uses many layers, the learning signal, or gradient, can shrink as it moves backward through the network. This shrinking happens because the backpropagation algorithm multiplies small numbers together, especially when using activation functions like the hyperbolic tangent. As a result, the gradient becomes so small that early layers in the network stop learning. This problem makes it hard for the vanishing/exploding gradients machine vision system to recognize patterns in images.
Researchers first noticed the vanishing gradient problem in 1991. They found that deep networks could not learn well because the signal faded before reaching the first layers. Later studies showed that careful weight initialization and new network designs, like residual connections, help keep the gradient strong. These solutions allow the backpropagation algorithm to work better, even in networks with many layers.
| Evidence Aspect | Description |
|---|---|
| Mathematical Explanation | Gradients shrink exponentially during backpropagation through many layers due to repeated multiplications by values in [-1,1], such as from the hyperbolic tangent activation function, causing gradient magnitudes to decrease exponentially in earlier layers. |
| Historical Identification | The vanishing gradient problem was first formally identified by Hochreiter in 1991, explaining why deep networks initially failed to train effectively. |
| Theoretical Analysis | Yilmaz and Poli demonstrated that proper initialization of weights (setting the mean of initial weights according to a specific formula) can prevent gradient vanishing, enabling efficient training of networks with 10 to 15 hidden layers. |
| Hardware Impact | Advances in computing power (e.g., GPUs) have allowed deeper networks to be trained despite the vanishing gradient problem, but this does not fundamentally solve the issue. |
| Architectural Solutions | Residual (skip) connections help alleviate the vanishing gradient problem by allowing gradients to flow more directly through the network, improving training stability and signal strength across deep layers. |
Exploding Gradients
Exploding gradients create a different challenge for the vanishing/exploding gradients machine vision system. During the backpropagation algorithm, the gradient can grow very large instead of shrinking. This happens when the network multiplies numbers greater than one many times. The result is a gradient that becomes so big it causes the model’s weights to change too much. Training becomes unstable, and the model may fail to learn anything useful from images.
Exploding gradients often appear in very deep networks or when the weights are not set correctly at the start. The backpropagation algorithm cannot handle these huge numbers, so the network’s output becomes unpredictable. In machine vision systems, exploding gradients can make the model miss important details in images or even crash during training. Both vanishing gradients and exploding gradients limit how well a vanishing/exploding gradients machine vision system can learn from visual data.
Causes in Machine Vision Systems
Deep Networks
Deep neural networks power many machine vision systems. These networks have many layers stacked together. Each layer passes information to the next, but this process can cause problems. When the network is very deep, the gradients can either shrink or grow as they move through each layer. This leads to vanishing gradients or exploding gradients.
- Experiments on visual data, such as CIFAR-10, show that deeper networks often struggle with gradient instability. When researchers shuffled labels or changed the environment, deeper neural networks lost accuracy and their gradients became much smaller.
- In deep reinforcement learning, deeper models showed a drop in performance and their gradients almost disappeared.
- These results prove that as the number of layers increases, the risk of vanishing gradient and exploding gradient problems also rises. The gradients multiply at each layer, which can make them either too small or too large for the neural network model to learn well.
Activation Functions
Activation functions decide how signals move from one layer to the next in deep learning. The choice of activation function affects whether gradients vanish or explode.
- Sigmoid and Tanh functions often cause vanishing gradients. Their outputs get stuck at the extremes, making gradients very small or very large.
- ReLU and its variants help prevent vanishing gradients. They keep the gradient strong for positive values, which helps deep neural networks learn better.
- Newer functions like SELU and GELU offer more stable learning and smoother gradient flow, especially in complex neural networks.
- The right activation function, combined with other techniques, can reduce exploding gradients and improve training in machine vision systems.
Weight Initialization
Weight initialization sets the starting values for each layer in a neural network. Poor choices can lead to vanishing gradients or exploding gradients. If the weights are too small, gradients vanish. If the weights are too large, gradients explode.
Experiments show that methods like Xavier and Kaiming initialization help control gradient size and improve accuracy in deep learning. For example, on the MNIST dataset, models with Kaiming or Orthogonal initialization performed better and had more stable gradients than those with random weights.
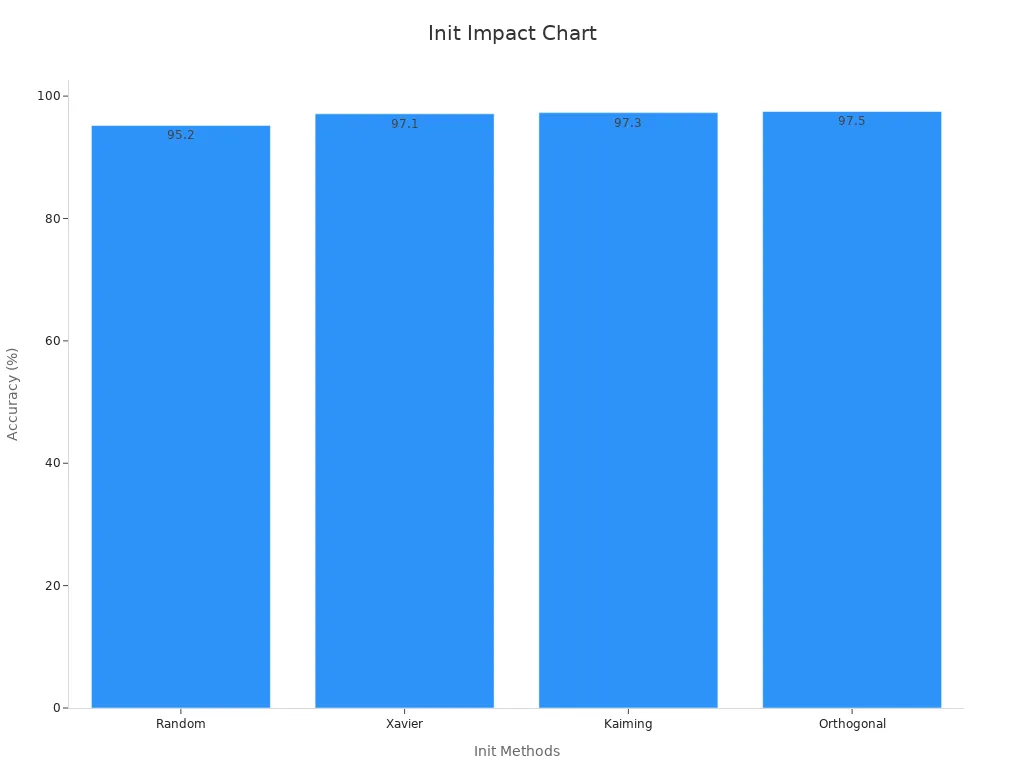
Choosing the right initialization method helps neural networks avoid vanishing gradients and exploding gradients, making training more stable and effective.
Effects on Model Training

Training Instability
Training instability often appears when a neural network model faces exploding gradient problems. During training, the gradients can become extremely large. This causes the weights in the model to change too much from one step to the next. As a result, the loss value may jump up and down or even increase instead of decrease. The model may never settle into a pattern that helps it learn from images. Researchers have measured this by tracking training loss and accuracy over many epochs. When exploding gradients occur, the loss and accuracy values often swing wildly or fail to improve. This makes it hard to achieve model stability and reliable results.
| Metric Type | Description |
|---|---|
| Training Loss | Shows if the model is learning or if the loss is unstable. |
| Training Accuracy | Reflects how well the model is learning from the data. |
| Validation Loss | Helps check if the model can generalize to new data. |
| Validation Accuracy | Measures performance on unseen images. |
| Precision | Tells how many positive predictions are correct. |
| Recall | Shows how many actual positives are found. |
| F1-Score | Combines precision and recall for a balanced view. |
| Overall Accuracy | Summarizes the model’s effectiveness. |
Exploding gradient issues can cause these metrics to behave abnormally, making it clear that training dynamics are not healthy.
Learning Stalls
A vanishing gradient problem can stop a neural network model from learning. When gradients shrink as they move backward through the layers, the early layers stop updating. This means the model cannot learn important features from images. In experiments, some machine vision models like VGG and NASNet failed to improve during training. Early stopping methods often halted these models because their validation accuracy did not get better. Training curves showed flat lines, which means the model made no progress. Vanishing gradients often happen when using activation functions like sigmoid or tanh, or when neurons become saturated. Tools such as Amazon SageMaker Debugger can track gradients and spot when learning stalls. This helps researchers fix the problem before wasting time on a model that cannot learn.
Tip: Using ReLU activations and careful weight initialization can help prevent both vanishing gradient and exploding gradient problems, leading to better training outcomes.
Identifying Gradient Problems
Signs in Training
Machine vision models often show clear signs when they face gradient problems. Training loss may stop decreasing or even increase. Sometimes, accuracy stays the same for many epochs. The model might make random guesses instead of learning from images. These issues often point to vanishing or exploding gradients.
- Loss values become stuck or jump up and down.
- Accuracy does not improve, even after many training steps.
- Model predictions look random or do not match the input images.
- Training takes much longer than expected.
Researchers often notice these signs when using the backpropagation algorithm. The algorithm tries to update the model, but gradient problems stop it from working well. When gradients vanish, the model cannot learn new features. When gradients explode, the model becomes unstable.
Tip: If a model’s loss or accuracy does not change, check for gradient problems early. This can save time and resources.
Diagnostic Tools
Several tools help detect gradient problems in machine vision systems. These tools track the gradients during training and show if they become too small or too large.
| Tool Name | What It Does |
|---|---|
| TensorBoard | Plots gradient values for each layer. |
| Amazon SageMaker Debugger | Monitors gradients and alerts for issues. |
| PyTorch Hooks | Captures gradients during the backpropagation algorithm. |
| Gradient Histograms | Visualizes the spread of gradients in the network. |
Engineers use these tools to watch the backpropagation algorithm in action. They can spot when gradients vanish or explode. This helps them fix the model before training fails.
Solutions and Best Practices
Weight Initialization
Weight initialization sets the starting point for learning in a neural network. When engineers choose the right method, they help the network avoid vanishing or exploding gradients. Xavier initialization works well for networks that use sigmoid or tanh activation functions. It balances the variance of activations across layers, which keeps gradients from shrinking or growing too much. Kaiming initialization fits networks that use ReLU activations. It preserves the size of gradients and helps the network learn faster. In deep convolutional neural networks, Kaiming initialization often leads to better accuracy and more stable training. Other methods, like orthogonal initialization, help in special cases such as recurrent neural networks.
Selecting the right initialization method depends on the network’s architecture and the activation functions in use. For example, a deep vision model with ReLU layers benefits from Kaiming initialization. This choice improves convergence speed and reduces training errors. Using pretrained weights also helps, especially in transfer learning. It aligns the filters and speeds up learning on new tasks. Engineers should monitor gradient flow and training metrics to fine-tune initialization and ensure reliable results.
Tip: Always match the initialization method to the activation function. This simple step can prevent many gradient problems before training even begins.
Activation Functions (ReLU, etc.)
Activation functions decide how signals move through a neural network. The right choice can prevent vanishing or exploding gradients. ReLU (Rectified Linear Unit) is a popular option in machine vision systems. It keeps gradients strong for positive values and helps deep networks learn important features from images. Variants like Leaky ReLU and GELU offer smoother learning and reduce the risk of dead neurons.
Sigmoid and tanh functions can cause gradients to vanish, especially in deep networks. Their outputs get stuck at the extremes, making it hard for the network to learn. Newer activation functions, such as SELU and Swish, provide better gradient flow and improve training stability.
- ReLU and its variants work best for most vision tasks.
- Avoid sigmoid or tanh in deep layers unless necessary.
- Test different activation functions to see which one gives the best results for your data.
Activation functions also play a key role after batch normalization. They introduce nonlinearity, which makes the network more expressive. In binary networks, using hard Tanh can cause gradient vanishing, so engineers often choose smoother activations.
Batch Normalization
Batch normalization helps stabilize training by normalizing the outputs of each layer. It keeps the mean and variance of activations steady, which allows gradients to flow smoothly through the network. This technique makes training faster and more reliable, especially in deep machine vision models.
Batch normalization also regularizes the network. It reduces the need for other forms of regularization, such as dropout. Engineers can use larger batch sizes and train deeper networks without running into gradient problems. Attention-based batch normalization goes a step further. It helps the network focus on important parts of the image, improving accuracy and feature detection.
| Strategy | Key Findings and Impact on Training Performance |
|---|---|
| Batch Normalization | Downscales residual branches for stable gradients; eliminates mean-shift in activations; regularizes training; enables efficient large-batch training by smoothing loss landscape; sensitive to batch size and computationally expensive. |
| Attention-Based Batch Normalization (ABN) | Improves feature discrimination and convergence stability in binary neural networks; Grad-CAM visualizations show better focus on relevant image regions; enhances classification accuracy. |
Note: Batch normalization works best with moderate to large batch sizes. Small batches can make the normalization less effective.
Gradient Clipping
Gradient clipping controls the size of gradients during training. When gradients become too large, clipping sets them to a maximum value. This prevents the weights from changing too much in one step. Adaptive Gradient Clipping (AGC) improves on standard clipping by adjusting the limit based on the weight norms. AGC stabilizes training, speeds up convergence, and achieves high accuracy on tasks like ImageNet classification.
- Use gradient clipping when training very deep networks or when you see unstable loss values.
- AGC requires less tuning than standard clipping and works well in practice.
- Monitor gradients during training to decide if clipping is needed.
| Strategy | Key Findings and Impact on Training Performance |
|---|---|
| Adaptive Gradient Clipping (AGC) | Stabilizes training by clipping gradients relative to weight norms; enables faster convergence; achieves state-of-the-art accuracy on ImageNet; less sensitive to hyperparameter tuning than standard clipping. |
Engineers often combine gradient clipping with other techniques, such as batch normalization and careful weight initialization, to build robust machine vision systems.
By applying these best practices, engineers can train deep neural networks that learn effectively from images. Each technique addresses a different part of the gradient problem, making machine vision models more stable and accurate.
Addressing vanishing and exploding gradients helps machine vision models learn better and stay stable. Engineers can use smart weight initialization, strong activation functions, batch normalization, and gradient clipping to solve these problems.
- Stable gradients lead to better image recognition.
- Simple fixes can make training faster and more reliable.
Try these strategies in your own projects. Explore new tools and share your results with others in the machine vision community.
FAQ
What causes vanishing gradients in deep vision networks?
Vanishing gradients often happen when a network uses many layers with activation functions like sigmoid or tanh. The gradients shrink as they move backward, making it hard for early layers to learn.
How can engineers spot exploding gradients during training?
Engineers can watch for sudden spikes in loss or accuracy. Tools like TensorBoard show large gradient values. If the model becomes unstable or crashes, exploding gradients may be the cause.
Why does batch normalization help with gradient problems?
Batch normalization keeps the outputs of each layer steady. This helps gradients flow smoothly through the network. Models train faster and more reliably with batch normalization.
Which activation function works best for deep vision models?
ReLU and its variants work best for most deep vision tasks. They keep gradients strong and help networks learn important features from images.
Tip: Try different activation functions to see which one gives the best results for your data.
See Also
A Comprehensive Guide To Thresholding Techniques In Vision
Essential Principles Behind Edge Detection In Vision Systems
How Cameras Function Within Modern Machine Vision Systems








