
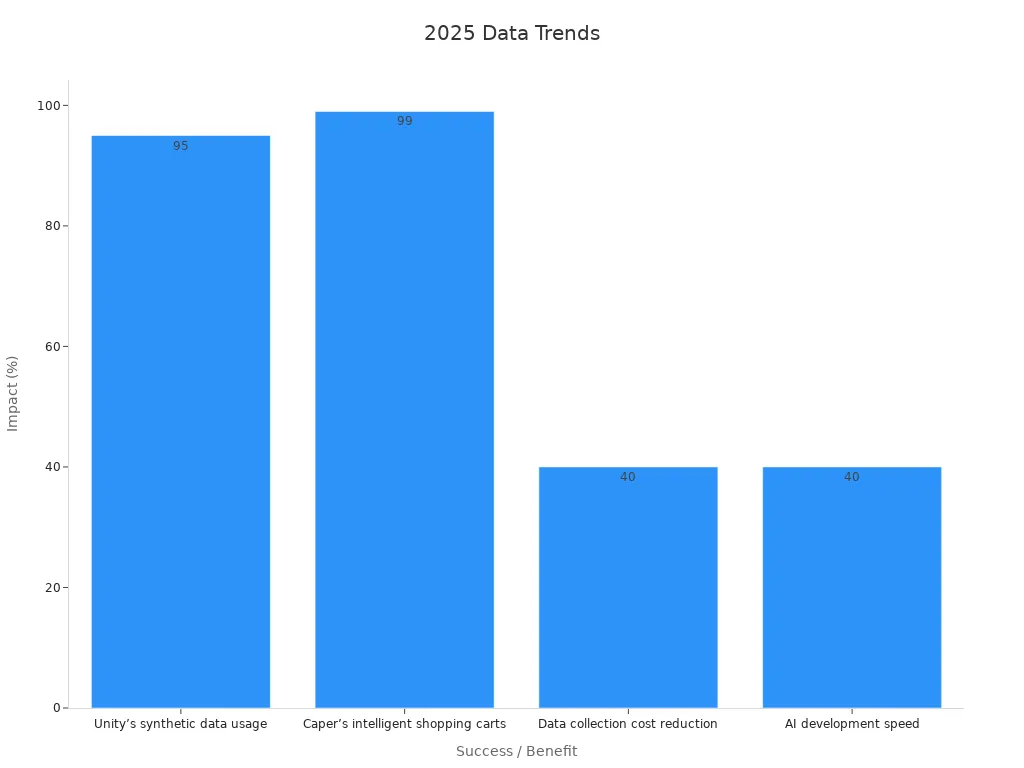
Training data forms the foundation of every machine vision application in 2025. It consists of images, videos, and annotations that help computer vision models learn to recognize objects and patterns. High-quality data with accurate labeling leads to better system performance. For example, companies using synthetic data have achieved up to 99% recognition accuracy and reduced development time by 40%.
A Training Data machine vision system depends on both real and synthetic data to reach higher accuracy and recall. Improving data quality can boost model efficiency by up to 88% and save millions in operational costs.
Key Takeaways
- High-quality training data, including real and synthetic images, is essential for accurate and efficient machine vision systems in 2025.
- Using diverse data types and smart labeling methods improves model performance and reduces errors in object recognition and classification.
- Automation and AI-assisted tools speed up data annotation, cut costs, and enhance quality control in machine vision projects.
- Addressing challenges like data bias, quality issues, and scalability ensures reliable and fair machine vision results in manufacturing and beyond.
- Future trends show growing use of synthetic data and automation, helping teams build better datasets and achieve higher accuracy in real-world tasks.
Training Data Machine Vision System
A training data machine vision system relies on high-quality data to help computers see and understand the world. These systems use training data to teach models how to recognize objects, scenes, and actions. The role of training data in machine vision is critical. Without enough good data, even the best algorithms cannot perform well. Machine learning systems need large, well-labeled datasets to improve accuracy and reliability. In 2025, companies use both real and synthetic data to build robust computer vision solutions. The quality of training data directly affects system performance in areas like autonomous vehicles, medical imaging, and industrial inspection.
Types of Data
Machine vision systems use many types of data for training and classification. The most common type is image data, which includes photos and video frames. These images can be in grayscale or color (RGB). Some datasets use RGB-D images, which add depth information to help with 3D object recognition. Multispectral data, such as thermal or near-infrared images, support specialized detection tasks. 3D point clouds provide detailed shape information for robotics and mapping. Video sequences allow models to learn about movement and changes over time.
Note: Datasets often include different annotation types, such as class labels, bounding boxes, polygons, and attributes. These help with tasks like object classification, scene recognition, and fine-grained categorization.
Recent research shows that machine vision datasets support a wide range of classification tasks. For example, datasets like COCO offer images with multiple object categories and captions. Scene recognition datasets, such as Places365, include many scene classes. Facial image datasets provide attribute annotations for tasks like emotion detection. Satellite datasets use multispectral data for land cover classification. These varied data types help computer vision models learn to solve many real-world problems.
Data Sources
A training data machine vision system gathers data from many sources. Real-world images come from cameras, smartphones, drones, and satellites. Video data often comes from surveillance systems, dashcams, or industrial robots. Synthetic data, created by computer graphics or simulation tools, fills gaps where real data is hard to collect. Synthetic images help models learn about rare objects or unusual situations.
Large, well-labeled datasets have driven major advances in computer vision. The ImageNet project, for example, used millions of labeled images to train deep learning models. This led to a big jump in image classification accuracy. Google’s JFT-300 dataset, with 300 million images, pushed the limits even further. These examples show that more and better data leads to better machine vision systems. However, studies in medical imaging reveal that simply increasing dataset size does not always improve accuracy. Dataset bias and labeling errors can hurt performance. Careful curation and validation remain essential.
Labeling Methods
Labeling is a key step in building a training data machine vision system. Supervised learning depends on accurate labels to guide the model. Manual labeling, where people annotate each image, gives precise results but takes a lot of time. Automated labeling uses algorithms to speed up the process, but it may miss small details. Hybrid methods combine both approaches for better balance.
| Labeling Method | Strengths | Weaknesses |
|---|---|---|
| Manual | High precision, human judgment | Slow, expensive |
| Automated | Fast, scalable | May miss details, less accurate |
| Hybrid | Balances speed and accuracy | Needs careful management |
AI-driven labeling systems now achieve error rates below 1%, much lower than manual inspection. Synthetic data also helps by improving model accuracy and reducing bias. For example, synthetic images can boost accuracy by about 10% and lower data collection costs by 40%. These methods help detect rare objects and minority cases more effectively.
Supervised learning in computer vision relies on well-labeled data for tasks like image classification and object detection. The machine learning pipeline automates data handling, training, and evaluation. This improves accuracy, speed, and throughput. Ethical considerations, such as re-sampling and adversarial debiasing, help address bias and fairness in datasets.
A training data machine vision system must focus on data quality, diverse sources, and effective labeling. These factors ensure strong performance in classification and image analysis tasks. As machine vision grows, the need for better training data and smarter labeling methods will only increase.
Computer Vision and Deep Learning
Feature Extraction
Feature extraction helps computer vision models understand images and videos. Deep learning models, such as convolutional neural networks (CNNs), learn features directly from raw data. These models use layers to find patterns, shapes, and textures. This process removes the need for manual feature engineering. A benchmarking study from Oxford shows that feature extraction can narrow the performance gap between simple models and complex deep learning methods. The study compares white-box models using unsupervised feature extraction with black-box models on raw data. Results show that unsupervised learning techniques, like principal component analysis, help optimize training data for classification tasks. This approach improves accuracy for both binary and multiclass classification.
Note: Automatic feature extraction in deep learning supports tasks like object classification, scene recognition, and semantic segmentation. These tasks are important in machine vision and computer vision projects.
Pre-trained Models
Pre-trained models play a big role in machine vision and computer vision. These models use large datasets for training before deployment. Deep learning architectures, such as CNNs, R-CNNs, and GANs, learn from millions of labeled images. CNNs use convolutional, pooling, and fully connected layers to extract features. R-CNNs focus on regions in images for better object detection. GANs generate new images through adversarial training. Pre-trained models save time and resources. They also improve classification accuracy in machine learning tasks. Deep learning models can handle complex datasets and provide pixel-level understanding for tasks like semantic segmentation. Unsupervised learning methods, such as deep belief networks, train models without labeled data. These methods help in situations where labeled data is limited.
Hardware and GPUs
Modern hardware accelerates deep learning and machine vision. GPUs process data in parallel, making them faster than CPUs for computer vision tasks. Recent advancements, like NVIDIA’s H200 GPU and RTX 50-series, boost AI inference speed and memory bandwidth. The H200 GPU delivers 141 teraflops of performance and supports large datasets. The RTX 5070 Ti offers improved bandwidth and high throughput. These GPUs help machine learning models train faster and run more efficiently. Popular frameworks, such as Detectron2 and NVIDIA TAO Toolkit, use GPU acceleration for better performance. Model quantization and pruning also make models smaller and faster. These improvements support real-time classification and unsupervised learning in edge devices.
Automation in Data Preparation

Annotation Tools
Annotation tools help teams label images and videos for machine vision projects. These tools use automation to speed up the process and reduce errors. In many projects, annotation takes about 25% of the total time. Automatic annotation tools can cut this time by up to 80%. This means teams finish projects faster and spend less time on manual work. Automation also helps reduce human mistakes and makes it easier to handle large amounts of data. Many industrial automation systems use these tools to prepare data for training models. Teams can now train models more quickly and improve the quality of their datasets.
AI-Assisted Labeling
AI-assisted labeling uses smart algorithms to help with data annotation. These systems learn from past labels and suggest new ones, making the process faster and more accurate. In industrial automation, AI-assisted labeling helps companies inspect thousands of parts every hour. For example, some machine vision systems now inspect up to 10,000 parts per hour. Automation in labeling also reduces inspection errors by over 90% compared to manual checks. Companies see up to 80% fewer defects when they use automated visual inspection. 3D vision systems in industrial automation improve picking accuracy by up to 25% over older 2D systems. These improvements show how automation boosts both speed and quality in machine vision.
Quality Control
Quality control ensures that labeled data meets high standards. Teams use several methods to check the quality of annotations. Professional benchmarks use expert review panels, pilot testing, and statistical checks. Industry best practices include clear annotations, diverse samples, and reproducible results. Many companies use machine learning models to spot errors early. Tools like Labelbox and Amazon SageMaker Ground Truth offer automated quality checks and feedback loops. These systems flag mistakes in real time and help annotators fix them quickly. Automated sampling lets teams review small groups of data for spot checks, saving time and effort. Quality control in industrial automation keeps data reliable and supports better machine vision results.
Challenges and Solutions
Data Quality
Machine vision systems in manufacturing depend on high-quality data for accurate classification and detection. Teams often face challenges with inconsistencies and changes in input data. Noisy data can hide true patterns and reduce the reliability of deep learning models. In manufacturing, data sparsity and missing points can lead to missed defects. Heterogeneous sources introduce inconsistencies, making supervised learning harder. Dynamic environments cause data to become outdated, which affects production quality.
Teams use several strategies to improve data quality:
- Regular data monitoring and validation processes
- Real-time frameworks to catch errors quickly
- Human-machine collaboration for better labeling
- Structured testing to reduce errors in production
Continuous monitoring helps detect data drift and performance drops. Strong validation keeps machine vision models robust for defect detection and classification tasks.
Bias and Fairness
Bias in training data can cause deep learning models to perform poorly in manufacturing. Studies show that large datasets often contain gender, racial, or geographic biases. These biases can lead to unfair detection and classification results. For example, face recognition systems may show accuracy gaps across different groups. Bias can also amplify during supervised learning, making defects harder to spot in some cases.
Researchers audit pretrained models to find and reduce bias. They use numerical methods to measure fairness and accuracy trade-offs. Teams in manufacturing use these findings to design better machine vision systems. They adjust model training and data collection to improve fairness in defect detection and classification.
Scalability
Manufacturing projects often use large-scale datasets for deep learning and supervised learning. Scalability becomes a challenge when handling massive amounts of data for detection and classification. Teams must manage storage, data access, and tool limitations. Distributed computing frameworks like Hadoop and Spark help process data that exceeds single-machine capacity.
To address scalability, teams use:
- Distributed file systems and data partitioning
- Compression and columnar storage formats
- Parallel processing and sampling for data preprocessing
- Specialized visualization tools for large datasets
Scalable pipelines and strong infrastructure support deep learning in manufacturing. These solutions help maintain high production quality and improve defect detection across many products.
Best Practices and Trends
Dataset Management
Effective dataset management helps machine vision projects succeed. Teams should use clear documentation and data curation principles. This approach improves transparency and makes it easier to find and fix problems. Good documentation also helps teams track changes and understand how data supports deep learning models. Experts recommend using tools to check dataset quality and spot weaknesses. Teams can then focus on fixing these issues first.
Data augmentation is another best practice. Teams use geometric changes, color adjustments, and noise to make datasets stronger. AI-driven methods, like GANs and VAEs, create new images that help deep learning models learn better. These techniques boost accuracy and help models work well in different situations. For example, using augmentation in manufacturing can improve defect detection rates by over 30%. Teams should match augmentation methods to their specific problem and avoid adding too much, which can confuse the model.
Tip: Always validate new data to make sure it looks real and matches the task. This step keeps the dataset useful for deep learning.
Future Directions
Machine vision will see big changes in the next decade. Automation will play a larger role in data preparation and quality control. Smart tools will help teams label data faster and with fewer mistakes. Synthetic data will become even more important. By 2024, most training data for AI will be synthetic, helping deep learning models handle rare or hard-to-find cases.
A table below shows key trends shaping the future:
| Trend | Impact on Machine Vision |
|---|---|
| Automation | Faster data labeling, improved efficiency |
| Synthetic Data | Better model accuracy, privacy protection |
| Compliance | Stronger data security, meets regulations |
| Deep Learning Growth | Higher demand for large, labeled datasets |
The market for training data in computer vision is growing fast. Experts predict it will reach over $170 billion by 2034. Deep learning will remain the main driver, with supervised learning leading the way. As automation and synthetic data tools improve, teams will build better datasets and achieve higher accuracy in real-world tasks.
High-quality training data drives progress in machine vision and computer vision for 2025. Teams now use both real and synthetic data to improve accuracy and reduce costs. Synthetic data helps machine vision systems scale, with some organizations seeing up to 50% lower costs and better results. Diverse datasets let computer vision models handle complex tasks and adapt to new challenges. Teams should focus on strong data curation and automation. As machine vision evolves, robust training data will remain essential for future breakthroughs.
FAQ
What is the main purpose of training data in computer vision?
Training data helps computer vision models learn to recognize objects, scenes, and actions. The data teaches the model how to make decisions. High-quality training data leads to better results in computer vision tasks.
How does synthetic data help computer vision projects?
Synthetic data fills gaps when real images are hard to collect. It helps computer vision models learn about rare cases or unusual situations. Teams use synthetic data to improve accuracy and reduce costs in computer vision projects.
Why is data labeling important for computer vision?
Data labeling gives computer vision models the correct answers during training. Labels show the model what to look for in each image or video. Good labeling improves the accuracy and reliability of computer vision systems.
What challenges do teams face with computer vision training data?
Teams often find it hard to collect enough diverse data for computer vision. They may face problems with bias, errors, or outdated information. These issues can lower the performance of computer vision models.
How do teams keep computer vision data high quality?
Teams use tools and checks to review data for computer vision. They monitor for errors, update old data, and use both real and synthetic sources. Quality control helps computer vision models stay accurate and useful.
See Also
Understanding The Role Of Synthetic Data In Vision
Future Trends In Machine Vision Segmentation For 2025
A Comprehensive Guide To Computer And Machine Vision Models








