Support vector machines (svm) machine vision system play a vital role in how computers understand images. These systems use support vector machines to separate different objects in pictures, helping computers recognize patterns and make decisions. SVM uses powerful mathematical tools like the kernel trick to boost accuracy in tasks such as pattern recognition and image classification. Studies show that svm works well in high-dimensional spaces, including medical images and other machine vision applications. While deep learning has gained popularity, svm remains a trusted choice for many machine learning projects in system design.
Key Takeaways
- Support Vector Machines (SVM) help computers recognize and separate objects in images by finding clear boundaries called hyperplanes.
- SVM works well with complex, high-dimensional data like medical images and face recognition, often achieving high accuracy.
- Using kernels, SVM can handle data that is not easily separated by a straight line, improving its ability to classify images correctly.
- Feature extraction and selection improve SVM performance by focusing on important image details and reducing processing time.
- SVM is widely used in real-world applications like industrial inspection and medical imaging, offering reliable and accurate results even with limited data.
Support Vector Machines Overview
SVM Principles
Support vector machines belong to a group of supervised learning algorithms. These algorithms help computers learn from labeled training data. SVMs work well for classification, regression, and outlier detection tasks. In a typical binary classification problem, the algorithm tries to separate two groups in the data. It does this by finding a line or a plane, called a hyperplane, that divides the groups as clearly as possible.
The main goal of an SVM is to maximize the margin. The margin is the distance between the hyperplane and the closest points from each group. These closest points are called support vectors. Support vectors play a key role because they define the position and direction of the hyperplane. If the margin is wide, the classifier is more likely to make correct predictions on new data.
Note: SVMs use kernel functions to handle data that cannot be separated by a straight line. Kernels transform the data into a higher-dimensional space, making it easier to find a dividing hyperplane.
SVMs have strong theoretical foundations in machine learning. The Vapnik-Chervonenkis (VC) dimension helps explain why SVMs can generalize well to new data. This means they can make accurate predictions even when the data is complex.
How SVM Works
The support vector machine algorithm starts by taking labeled training data. It looks for the best hyperplane that separates the classes. The algorithm uses only the support vectors to define this hyperplane. This focus on key data points makes SVMs efficient and robust.
The optimization problem for SVMs aims to minimize the size of the weight vector while keeping the data points correctly classified. The mathematical formula for this is:
Minimize: (1/2) * ||w||^2
Subject to: y_i (w^T x_i + b) ≥ 1 for all training samples
Here, w is the weight vector, b is the bias, x_i is a training data point, and y_i is its label. If the data is not perfectly separable, the algorithm introduces slack variables. These allow some points to be on the wrong side of the margin, which helps the model handle real-world data.
SVMs perform well in high-dimensional spaces, such as image data. For example, studies show that SVMs can achieve over 95% accuracy in image classification tasks when combined with feature extraction methods. However, SVMs can face challenges like overfitting and high computational cost, especially with large datasets. Researchers use techniques like dimensionality reduction, regularization, and advanced kernels to improve performance.
| Measure/Concept | Description | Role in SVM Optimization for Image Data | ||
|---|---|---|---|---|
| Margin Maximization Objective | Minimizes (1/2) * | w | ^2 while keeping data correctly classified | Ensures robust separation between image data classes by maximizing margin. |
| Number of Support Vectors | Critical data points that define the hyperplane | Reduces computational complexity by focusing on representative samples. | ||
| KKT Conditions | Selects support vectors and removes non-support vectors | Enables sample size reduction while retaining classification accuracy. | ||
| Intrinsic Dimension Estimation | Analyzes the link between support vectors and data complexity | Helps in dimensionality reduction and efficient handling of high-dimensional image data. |
SVMs remain a popular choice in machine learning for classification problems. They offer strong performance, especially when the right kernel and parameters are chosen. While other algorithms like Random Forest and Logistic Regression may run faster on large datasets, SVMs often provide higher accuracy when tuned properly. Hybrid models and automated feature selection continue to improve SVM efficiency and scalability.
SVM in Machine Vision
Image Classification
Support vector machines (svm) machine vision system help computers analyze and sort images into different groups. These systems use labeled image classification datasets to learn how to tell objects apart. For example, in facial recognition, the system looks at pictures of faces with different expressions and angles. It learns to identify each person by finding patterns in the features of their faces.
A support vector machines (svm) machine vision system uses a decision boundary, called a hyperplane, to separate different classes in the data. The system tries to make this boundary as wide as possible, so it can correctly classify new images it has never seen before. This ability to generalize makes svm a strong choice for many image processing tasks.
Researchers have tested svm on many real-world problems. In one study, a support vector machines (svm) machine vision system using an RBF kernel achieved over 95% accuracy in face recognition. Another study used svm to classify brain tumor images and reached an AUC of 0.91, showing strong performance in medical image analysis. In remote sensing, svm handled multi-spectral satellite images and achieved high classification accuracy, even when the data had class imbalance.
| Case Study | Application Domain | Dataset/Task Description | SVM Variant/Kernel | Performance Metric | Result Summary |
|---|---|---|---|---|---|
| Face Recognition | Facial image classification | Dataset with varied expressions and angles | RBF kernel | Accuracy | Over 95% accuracy in distinguishing identities |
| Medical Image Analysis | Tumor classification | Segmented brain tumor MRI images | Standard SVM | AUC (Area Under ROC Curve) | AUC of 0.91 indicating strong classification |
| Remote Sensing Image Classification | Land cover classification | Multi-spectral and multi-temporal satellite data | Standard SVM | Classification accuracy | Superior accuracy, addressing class imbalance |
Svm can work with many features at once, such as color, shape, and texture. In image processing, the system often uses feature extraction to pick out the most important details from each image. This helps the classifier focus on what matters most for the task. Studies show that reducing the number of features from thousands to just over a hundred can still give high accuracy. For example, one experiment reduced features from 27,620 to 114 and still achieved a root mean square error of cross-validation (RMSECV) of 0.4013 and a determination coefficient (RCV2) of 0.9908. This shows that svm can handle large, complex datasets and still make precise predictions.
Svm also works well in challenging situations. For instance, in forest fire detection, researchers used different kernels and found that the Gaussian kernel outperformed others. The system handled high-dimensional image data better than logistic regression, especially when the images had many details.
Pattern Recognition
Pattern recognition is another important job for support vector machines (svm) machine vision system. These systems help computers find and understand patterns in visual data, such as handwriting, printed text, or objects in a scene. In optical character recognition, the system learns to tell letters and numbers apart, even when the writing is messy or the images are noisy.
Svm uses its decision boundary to separate different patterns. The system looks for the best way to split the data, so it can recognize new patterns later. This makes svm a good choice for character recognition and other pattern recognition tasks in machine vision.
Researchers have studied how svm works in pattern recognition by using statistical methods. For example:
- Scientists used Information Theory and Statistical Mechanics to study hazelnut X-ray images. They found two key statistical scales that affect how well the system can recognize patterns.
- The ratio of these scales and the image resolution both play a role in classification accuracy.
- Experiments with svm confirmed that there is an optimal resolution for recognizing patterns.
- The results were averaged over many training samples to make sure they were reliable.
- The study showed that separating scales and averaging results can improve svm-based pattern recognition in visual data.
Svm can also detect small changes in image features. In medical imaging, a one-class svm found population drift in diagnostic data. When the noise level was low, the system misclassified only 27 out of 10,000 test samples. As noise increased, misclassifications rose, showing that svm is sensitive to changes in image-derived features.
Svm stands out in machine vision because it can handle many features and work with limited training samples. In one study, svm classified readers by their eye movement patterns, using complex feature sets. The system achieved high predictive accuracy, with a root mean square error of 0.4013 and a determination coefficient of 0.9908 after feature selection.
Support vector machines (svm) machine vision system continue to play a key role in computer vision. They offer strong performance in both image classification and pattern recognition. While deep learning has become popular, svm remains a reliable classifier, especially when the dataset is small or the features are well chosen. Svm also works well in combination with other image processing techniques, making it a valuable tool for many machine vision applications.
Feature Extraction and Kernels
Feature Extraction in Machine Vision
Feature extraction plays a key role in machine vision. It helps computers find important details in images. In image processing, feature extraction algorithms look for patterns such as edges, textures, and shapes. These patterns help the system understand what is in each picture. For example, gray level-based texture features, shape features, and first-order statistical features all provide different information about an image. When combined, these features can improve how well a support vector machine classifies images.
Researchers often use feature selection after extraction. This step keeps only the most useful features. A study on COVID-19 CT images showed that using feature extraction and selection together increased model accuracy from 75% to 85%. The number of features dropped from over 100 to about 20, which made the model faster and easier to use. The table below shows these improvements:
| Metric | Before Feature Selection | After Feature Selection |
|---|---|---|
| Number of Features | Over 100 | About 20 |
| Model Accuracy | 75% | 85% |
| Loss Function Value | Higher | Lower |
| Processing Time | Longer | Shorter |
| Dimensionality | High | Reduced |
Feature extraction also boosts performance in manufacturing. Inspection accuracy can rise from 85-90% to over 99.5%. Processing speed improves, and defect rates drop by 75%. These results show that feature extraction is vital for efficient and accurate machine vision systems.
Kernel Functions in SVM
Kernel functions help support vector machines handle complex data. The kernel trick lets the SVM find patterns that are not easy to see in the original data. By using the kernel trick, the SVM can work in a higher-dimensional space without extra computation. Common kernel types include linear, polynomial, and radial basis function (RBF) kernels.
Studies compare how different kernels affect SVM performance. For example, the RBF kernel often gives the best results. In one study, the RBF kernel reached an AUC of 0.833, while the linear kernel scored 0.716 and the sigmoid kernel scored 0.680. Polynomial kernels can fit training data well but may overfit and perform worse on new data. The table below shows these results:
| Kernel Function | AUC (Performance Metric) | Notes on Performance and Overfitting |
|---|---|---|
| RBF | 0.833 | Highest AUC, best overall performance, low overfitting |
| Linear (LN) | 0.716 | Moderate performance, slightly better prediction in validation |
| Sigmoid (SIG) | 0.680 | Lowest performance |
| Polynomial (PL) | Varies by degree | High degree can cause overfitting |
Researchers also tested kernels in many experiments. The RBF kernel performed best, especially when the data was imbalanced or after feature selection. Statistical tests confirmed that kernel choice has a big impact on SVM results.
Parameter tuning is important for getting the best performance from SVMs. Adjusting kernel parameters, such as the width of the RBF kernel, helps the model fit the data better. The kernel trick, combined with careful parameter tuning, allows SVMs to solve many real-world problems in machine vision.
Real-World Applications
Industrial Machine Vision Systems
Support vector machines help many industries improve their inspection and monitoring processes. These systems use SVM to spot defects, detect anomalies, and classify products on assembly lines. Researchers have shown that SVM models work well in real-time threat detection for industrial control systems. For example, Fang and colleagues in 2024 reported high accuracy when using SVM to find unusual operations. Imran and his team in 2023 also found that SVM models are robust and reliable for classifying threats in industrial settings.
Many studies compare SVM with other machine learning methods. The table below shows how SVM performs against Random Forest and CNN models in industrial inspection tasks:
| Metric | Support Vector Machine (SVM) | Random Forest | CNN |
|---|---|---|---|
| Accuracy (%) | 92.3 | 91.5 | 94.2 |
| Recall (%) | 90.8 | 88.6 | 91.7 |
| F1-Score (%) | 91.5 | 90.0 | 93.0 |
| False Positive Rate (%) | 4.1 | 4.9 | 3.2 |
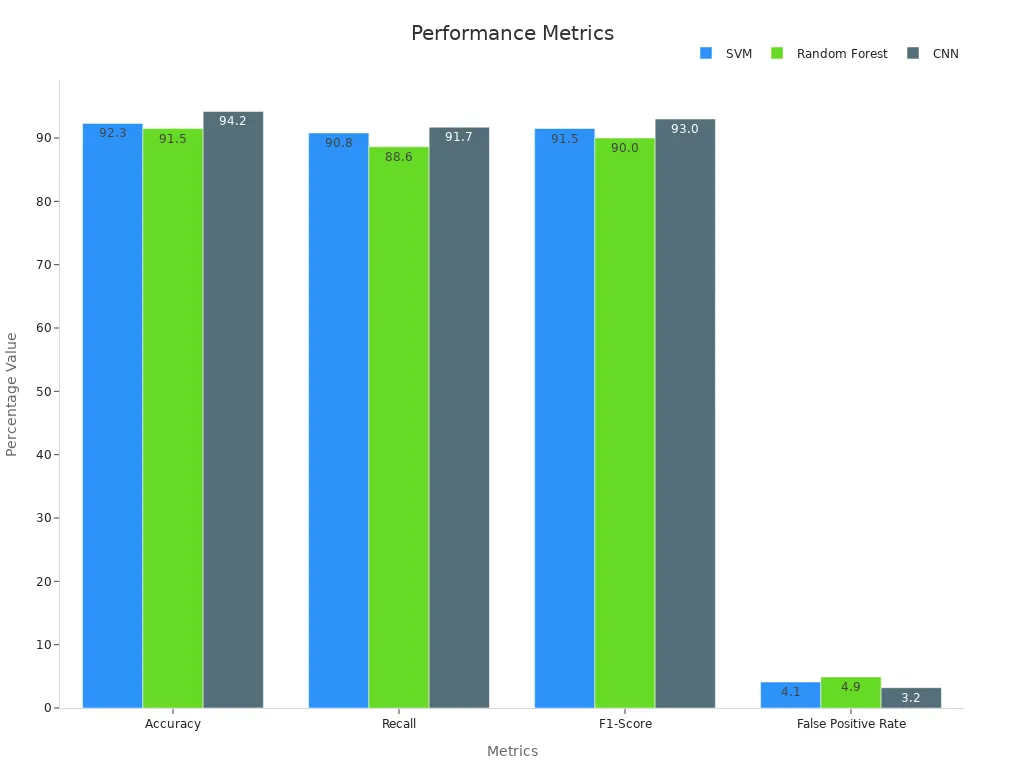
SVM models often need fewer training samples and show less overfitting than deep learning models. Engineers use regularization and cross-validation to make SVM more reliable. In practice, SVM systems can handle data imbalance and high-dimensional features by using techniques like SMOTE and dimensionality reduction. These improvements help SVM models deliver strong results in industrial machine vision.
Tip: Combining SVM with boosting algorithms, such as Adaboost, can further increase classification accuracy in industrial inspection tasks.
Medical Imaging
Support vector machines play a key role in medical imaging. Hospitals and clinics use SVM models to classify images, detect tumors, and support doctors in diagnosis. Researchers follow several steps to make sure SVM models work well in these settings:
- Select important features from images using methods like LASSO.
- Train SVM models with careful tuning of parameters such as gamma and cost.
- Build models using single or combined image sequences.
- Evaluate performance with ROC curves, AUC, sensitivity, and specificity.
- Validate models on new datasets to check generalization.
- Use statistical tests to compare results between groups.
- Compare different SVM models using tests like the Delong test.
- Apply cross-validation to estimate how well the model will work in practice.
Doctors and radiologists often review SVM predictions to confirm results. These steps help ensure that SVM systems provide accurate and reliable support in medical imaging. While deep learning has become popular in recent years, SVM remains a trusted choice when data is limited or features are well defined.
Support vector machines help computers see and understand images. They create clear boundaries between objects and patterns. SVMs work well in tasks like face detection and image recognition. The table below shows how SVMs improve accuracy in real-world cases:
| Application | Benefit Highlight | Numerical Improvement |
|---|---|---|
| Face Detection | Precise boundary creation | Achieves up to 95% correct classifications |
| Image Recognition | Effective processing of high-dimensional data | Up to 40% increase in accuracy compared to traditional methods |
Students and engineers can explore SVM tutorials or try building simple image classifiers to learn more.
FAQ
What is a support vector machine (SVM)?
A support vector machine is a type of computer algorithm. It helps computers separate data into groups. SVMs use math to draw a line or a plane between different types of data.
How does SVM help in machine vision?
SVM helps computers recognize objects in images. It finds patterns in pictures and sorts them into categories. For example, SVM can tell the difference between cats and dogs in photos.
Why do SVMs use kernels?
Kernels help SVMs solve problems when data cannot be separated by a straight line. Kernels change the data into a new space. This makes it easier for SVM to find a good dividing line.
Where do people use SVM in real life?
| Application Area | Example Use |
|---|---|
| Medicine | Tumor detection in images |
| Industry | Defect spotting on products |
| Security | Face recognition systems |
People use SVMs in many fields to help computers make smart decisions.
See Also
Understanding Machine Vision Systems And Computer Vision Models
A Comprehensive Guide To Image Processing In Machine Vision
How Guidance Machine Vision Enhances Robotics Performance








