
A dropout machine vision system uses dropout to randomly disable some neurons during training in deep learning models. This method helps prevent overfitting, a common issue in machine learning when a model memorizes training images but struggles with new ones. Dropout leads to better generalization, making computer vision models more reliable for real-world tasks. On benchmark datasets, dropout improves test accuracy and reduces test loss compared to other regularization methods.
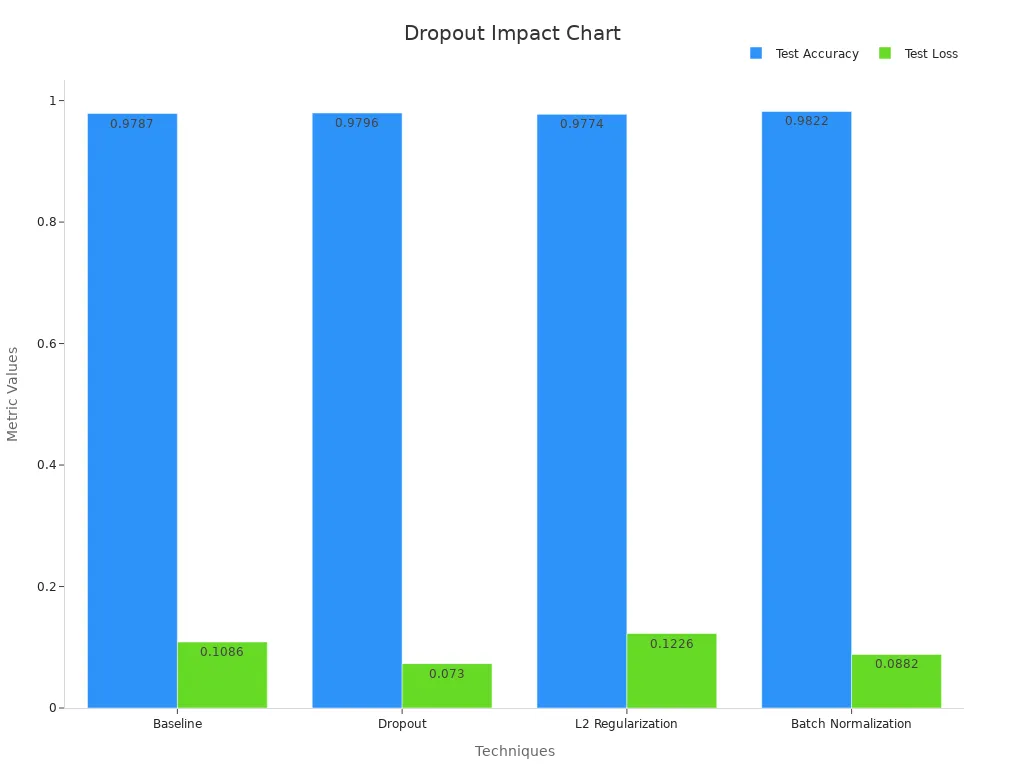
In practice, a dropout machine vision system can increase model stability by about 20% and reduce prediction variance by 25%. These results show that dropout strengthens both machine learning and computer vision systems.
Key Takeaways
- Dropout helps machine vision models avoid overfitting by randomly disabling neurons during training, which improves their ability to recognize new images.
- Using dropout leads to better model accuracy, stability, and generalization, making vision systems more reliable in real-world tasks.
- Typical dropout rates range from 0.2 to 0.5, with careful tuning needed to balance learning and avoid underfitting or overfitting.
- Dropout works best when placed after fully connected or convolutional layers and should be turned off during testing to ensure stable predictions.
- Combining dropout with other methods like L2 regularization and data augmentation can further boost model performance and reduce errors.
What Is Dropout?
Overfitting in Vision Models
Overfitting happens when a model learns the training data too well. It memorizes details and noise instead of understanding the main patterns. In machine learning, especially in deep learning, overfitting causes models to perform poorly on new images. Deep neural networks often have millions of parameters. These networks can easily fit the training data but struggle to generalize to unseen examples.
A dropout machine vision system uses dropout as a machine learning technique to address this problem. Dropout randomly disables some neurons during training. This process forces the network to learn more robust features. As a result, the model does not rely too much on any single neuron or path. Researchers tested dropout on standard vision datasets like MNIST, CIFAR-10, CIFAR-100, SVHN, and ImageNet. They found that dropout consistently improved generalization and reduced test errors compared to models without dropout. On MNIST, models with dropout showed much lower test errors across different architectures. Dropout combined with max-norm regularization achieved the lowest generalization errors among tested regularizers, outperforming L2 weight decay, Lasso, and KL sparsity.
Dropout in deep learning works best within a certain dataset size range. It does not help or may even hurt performance on extremely small or very large datasets.
Why Dropout Matters
Dropout plays a key role in learning regularization for deep neural networks. It helps reduce overfitting and improves the ability of models to handle new data. In deep learning, dropout acts as a simple yet powerful tool to make models more reliable. By randomly dropping neurons, the network cannot depend on specific paths. This encourages the model to learn general patterns that work for many images.
Researchers have applied dropout to convolutional layers in SVHN and found improved performance. This result shows that even layers previously thought less prone to overfitting can benefit from dropout. The optimal dropout rate for hidden layers is about 0.5, while the input layer needs a rate close to 1.0. Dropout layers are often placed after dense layers in architectures like DenseNet121 and after residual blocks in ResNets.
In modern computer vision tasks, dropout remains a popular choice. Dropout rates vary by dataset, such as 0.1 for cervical images and 0.2 for knee osteoarthritis. Monte Carlo dropout, which repeats predictions multiple times and averages the results, improves model stability and reduces test-retest variability. This approach has been validated on medical imaging tasks using deep neural networks like ResNet18, ResNet50, and DenseNet121.
- Dropout models show improved repeatability and calibration, especially at class boundaries.
- After about 20 Monte Carlo iterations, further repeatability gains become minimal.
- Dropout incurs higher computational cost but offers better stability and reduced overfitting.
Dropout stands out as a reliable learning regularization method in deep learning. It helps machine learning models generalize better and reduces the risk of overfitting. For anyone building a machine learning system, dropout offers a practical way to improve performance and reliability.
Dropout Machine Vision System Basics
How Dropout Works
A dropout machine vision system uses dropout to improve the reliability of deep neural networks. Dropout works by randomly disabling some neurons during training. This process prevents the network from relying too much on any single neuron. The following steps outline how dropout implementation works in practice:
- During each training iteration, the system selects each neuron (except output neurons) to be dropped with a probability called the dropout rate.
- The system chooses which neurons to drop at random.
- The forward pass uses the reduced network, with dropped neurons set to zero.
- Backpropagation updates only the active neurons, ignoring the dropped ones.
- During testing, dropout is turned off, and all neurons remain active.
- To keep the output consistent, the system scales the weights of neurons by (1 – dropout rate) during testing.
This approach creates an implicit ensemble of neural networks. Each iteration trains a slightly different subnetwork. The neural network dropout method helps deep learning models generalize better by forcing them to learn robust features. Dropout regularization ensures that the model does not depend on specific neurons, which helps reduce overfitting and improves performance on new data.
Tip: Dropout implementation does not remove neurons permanently. It only ignores them temporarily during each training step.
Typical Dropout Rates
Choosing the right dropout probability is important for effective dropout regularization. Most deep learning models use dropout rates between 0.2 and 0.5. The effect of different rates depends on the type of network and the task:
- Dropout rates around 0.2 may not be enough to prevent overfitting in large deep neural networks.
- Rates near 0.5 work well for fully connected layers, especially in deep learning models for image recognition.
- Very high rates, such as 0.7, can cause underfitting by dropping too many neurons, making it hard for the model to learn.
- In convolutional neural networks, spatial dropout drops entire feature maps, usually with rates between 0.2 and 0.3.
- For recurrent neural networks, dropout is applied to non-recurrent connections, often with rates from 0.3 to 0.5.
The table below summarizes typical dropout rates and their effects on different architectures:
| Network Type | Typical Dropout Rate | Effect on Model |
|---|---|---|
| Fully Connected Layers | 0.5 | Balances overfitting and underfitting |
| Convolutional Neural Networks | 0.2 – 0.3 | Prevents overfitting, especially in deep models |
| Recurrent Neural Networks | 0.3 – 0.5 | Improves generalization on sequence data |
Tuning the dropout rate for each architecture and dataset is key. Dropout regularization works best when the rate matches the complexity of the model and the size of the dataset.
Impact on Model Performance
Dropout regularization has a strong impact on the performance of deep neural networks in machine learning and computer vision. By using dropout, models can achieve higher accuracy and require fewer training epochs. The following table shows how dropout affects different models on benchmark datasets:
| Model | Dataset | Baseline Accuracy (%) | Dropout Variant Accuracy (%) | Effective Epochs (Dropout) | Notes |
|---|---|---|---|---|---|
| EfficientNet-B0 | CIFAR-10 | ~88-90 | 89.87 – 90.01 | ~9-10 | Maintains or improves accuracy with fewer epochs |
| EfficientNet-B0 | CIFAR-100 | ~60-68 | 68.80 – 70.75 | 33 – 46 | Improves accuracy and reduces training epochs |
| MobileNet-V2 | CIFAR-10 | ~87.4 | 87.44 – 87.62 | ~9-10 | Comparable accuracy with fewer epochs |
| MobileNet-V2 | CIFAR-100 | ~63-75 | 63.31 – 75.23 | 40 – 55 | Improves accuracy and reduces epochs |
| ResNet-50 | CIFAR-10 | ~87-88 | 87.01 – 88.20 | 7 – 10 | Maintains accuracy with fewer epochs |
| ResNet-50 | CIFAR-100 | ~60-81 | 60.22 – 81.45 | 21 – 42 | Improves accuracy and reduces epochs |
| EfficientFormer-L1 | CIFAR-10 | ~80.6 | 80.66 – 80.81 | 15 | Comparable accuracy with fewer epochs |
| EfficientFormer-L1 | CIFAR-100 | ~58-87 | 58.08 – 87.78 | 39 – 76 | Improves accuracy and reduces epochs |
| ViT-B-MAE (pretrained) | CIFAR-100 | ~86.9 | 86.94 – 87.45 | 71 – 82 | Slight accuracy improvement with dropout |
Dropout machine vision system results show that dropout regularization can maintain or even improve accuracy while reducing the number of training epochs. This makes training more efficient and less costly.
The following chart shows how changing the dropout threshold affects accuracy on the CIFAR-100 dataset using EfficientNet-B0:
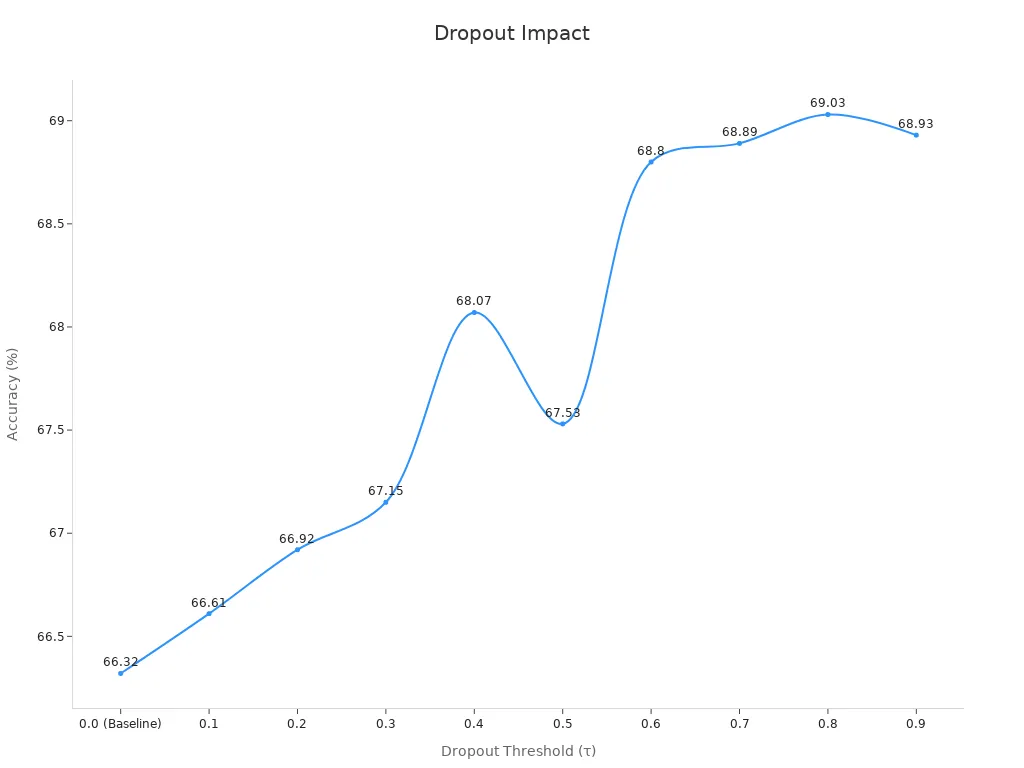
As the dropout threshold increases, accuracy generally improves up to a certain point. This pattern shows that dropout implementation can enhance generalization in deep learning models. However, setting the threshold too high may lead to underfitting.
Dropout regularization also helps reduce overfitting by making the model less sensitive to noise in the training data. In deep learning, this leads to better generalization and more reliable predictions on new images. Dropout machine vision system designers often combine dropout with other learning regularization methods to achieve the best results in computer vision tasks.
Deep Learning and Dropout
Where to Use Dropout
Engineers often place dropout layers after dense or fully connected layers in deep learning models. These layers help prevent overfitting by randomly disabling some neurons during training. In convolutional neural networks, dropout works best after the convolutional blocks or just before the final classification layer. This placement allows the model to learn strong features from images while still gaining the benefits of regularization.
Dropout in deep learning also appears in some input layers, but experts use lower rates there. For example, a model might use a dropout rate of 0.2 after the input layer and 0.5 after hidden layers. This approach helps the model avoid losing too much information early in the process. When building a machine learning system for vision, developers should experiment with different placements and rates to find the best setup for their data.
Tip: Place dropout layers after activation functions like ReLU for better results.
Common Pitfalls
Many teams make mistakes when using dropout. The most common error involves setting the dropout rate too high. If the model drops too many neurons, it cannot learn enough from the data. This problem leads to underfitting, where the model performs poorly on both training and test images.
Another mistake involves using dropout during testing or inference. Dropout should only work during training. If left on during testing, the model gives unstable and unreliable predictions.
The table below lists common pitfalls and solutions:
| Pitfall | Solution |
|---|---|
| Dropout rate too high | Use rates between 0.2 and 0.5 |
| Dropout used during testing | Turn off dropout for inference |
| Dropout before convolutional layers | Place after convolutional or dense layers |
Developers should always monitor model performance and adjust dropout settings as needed. Careful tuning ensures that deep learning models generalize well and avoid both overfitting and underfitting.
Comparing Regularization Methods
Dropout vs. L2 Regularization
Dropout regularization and L2 regularization both help deep learning models avoid overfitting. They use different approaches. L2 regularization adds a penalty to the loss function for large weights. This penalty encourages the model to keep weights small. Smaller weights help the model stay simple and avoid memorizing the training data.
Dropout regularization works by randomly disabling neurons during training. This method forces the network to learn features that do not depend on any single neuron. Dropout regularization creates many smaller subnetworks inside the main network. Each subnetwork learns to solve the task in a slightly different way. This process leads to better generalization.
Dropout regularization often works well with L2 regularization. Many engineers use both methods together for stronger results.
L2 regularization changes the model by shrinking weights. Dropout regularization changes the model by removing parts of the network during training. Both methods reduce overfitting, but dropout regularization often gives better results in deep neural networks for vision tasks.
Dropout vs. Data Augmentation
Dropout regularization and data augmentation both improve model performance, but they use different strategies. Dropout regularization changes the network during training. Data augmentation changes the input images. Engineers use data augmentation to create new training samples by flipping, blurring, or combining images. This process helps the model see more examples and learn to handle different situations.
The table below shows how data augmentation improves results in machine vision tasks:
| Method | mAP@0.50 | Precision | Recall |
|---|---|---|---|
| Baseline (no augmentation) | 0.654 | N/A | N/A |
| Classical Augmentation (flipping, blurring) | 0.821 | N/A | N/A |
| Image Compositing (proposed method) | 0.911 | 0.904 | 0.907 |
Dropout regularization does not change the input data. It helps the model learn robust features by preventing reliance on any single set of features. Data augmentation increases the variety of training data. Both methods reduce overfitting and improve generalization. Many teams use dropout regularization and data augmentation together for the best results.
Data augmentation can give large gains in accuracy, but dropout regularization remains a key tool for building strong and reliable machine vision systems.
Real-World Examples

Image Classification Case
A team of researchers explored image classification using the CIFAR-10 dataset. They built two models: one with regularization and one without. The model without regularization learned the training images quickly. However, its validation loss increased after only a few training rounds. This pattern showed that the model memorized the training data but failed to perform well on new images. The team then added regularization to the second model. They placed regularization layers in the network architecture using PyTorch. The new model learned more slowly, but its validation accuracy improved. The validation loss stayed low, even after many training rounds. This result demonstrated that regularization helped the model generalize better. The team concluded that regularization reduced overfitting and improved performance on unseen images.
Results Overview
Recent machine vision projects use several outcome metrics to measure the success of regularization methods. The table below summarizes these metrics:
| Outcome Metric | Description |
|---|---|
| Early Dropout | Participants who completed the first module but did not continue, or logged in fewer than seven unique days. |
| Participant Duration | Number of days between the first and last login to the system. |
| Intervention Success | Completion of all modules and achievement of target goals, such as meeting a specific registration threshold. |
| Classification Accuracy | Accuracy of the machine learning model in predicting early dropout, with values up to 81.81% after tuning. |
Machine vision teams often use algorithms like Decision Tree, SVM, and boosting methods such as LightGBM and CatBoost. They apply techniques like SMOTE to balance the data and use hyperparameter tuning to improve results. Boosting algorithms often provide the best predictive performance. These metrics help teams understand how well their models perform and where improvements are needed.
Dropout strengthens machine vision systems by reducing overfitting and improving generalization. Engineers achieve the best results by placing dropout after fully connected layers and tracking progress with metrics like validation accuracy and training loss.
- Dropout works well with higher learning rates and momentum, though it may increase training time.
- Batch normalization often replaces dropout in convolutional layers.
- Teams should experiment with dropout rates between 0.2 and 0.5, using grid or random search for tuning.
Consistent evaluation and careful documentation help teams build reliable, high-performing vision models.
FAQ
What is the main benefit of using dropout in machine vision systems?
Dropout helps models avoid overfitting. It improves the ability of a system to recognize new images. Engineers see more reliable results in real-world tasks.
Can dropout be used with other regularization methods?
Yes. Engineers often combine dropout with L2 regularization or data augmentation. This combination can further improve model performance and stability.
Does dropout slow down training?
Dropout may increase training time because the model learns from many subnetworks. However, it often leads to better accuracy and more stable results.
How does one choose the right dropout rate?
Engineers test different rates, usually between 0.2 and 0.5. They monitor validation accuracy and loss. The best rate depends on the model and dataset.
See Also
Understanding How Electronics Power Machine Vision Systems
A Comprehensive Guide To Cameras Used In Machine Vision
Exploring Computer Vision Models Within Machine Vision Systems
An Introduction To Sorting Using Machine Vision Technology
Comparing Firmware-Based Machine Vision With Traditional Methods








