Data augmentation in a machine vision system involves transforming existing datasets to make them more diverse and robust. By modifying images through techniques like rotation, scaling, or adding noise, you enhance the ability of the data augmentation machine vision system to learn better patterns. This process addresses one of the biggest challenges in computer vision—limited access to large, high-quality datasets. Research shows that models trained with synthetic data, a form of augmentation, achieve a 28% improvement in adapting to new scenarios. These enhanced datasets not only reduce overfitting but also improve generalization, making your data augmentation machine vision system more reliable when analyzing unseen images.
Key Takeaways
- Data augmentation improves how models work by making varied datasets. Methods like turning and resizing help models find better patterns.
- Using data augmentation means you don’t need huge datasets. It lets models train well with less data, saving effort and time.
- Augmentation stops overfitting by adding differences. This helps models work better with new images they haven’t seen before.
- Cool methods like mixup and cutout make special image changes. These techniques help models handle real-world challenges better.
- Tools like TensorFlow and PyTorch make augmentation easier. They save time and keep the process steady when creating new datasets.
Why Data Augmentation Matters in Machine Vision Systems
Enhancing model performance and accuracy
Data augmentation plays a critical role in improving the performance and accuracy of machine vision systems. By applying transformations to images, you can expose your models to a wider variety of scenarios. This helps them learn better patterns and make more accurate predictions. For example, techniques like geometric transformations or photometric adjustments allow your models to recognize objects in different orientations, lighting conditions, or scales.
A study on EfficientNet_b0 demonstrates how augmentation techniques significantly boost accuracy. The table below highlights the impact of various methods:
| Model Name | Augmentation Technique | Accuracy (before overfitting) |
|---|---|---|
| EfficientNet_b0 | No augmentation | 44.0 |
| EfficientNet_b0 | Horizontal strip augmentation | 44.20 |
| EfficientNet_b0 | Hue Saturation Channel transfer | 50.27 |
| EfficientNet_b0 | Pairwise channel transfer | 52.13 |
| EfficientNet_b0 | All proposed augmentations combined | 96.740 |
| EfficientNet_b0 | All existing augmentations combined | 85.782 |
This data shows that combining multiple augmentation techniques can lead to a dramatic improvement in accuracy, with results jumping from 44.0% to 96.74%. Such enhancements make your machine vision systems more reliable for computer vision tasks like object detection or classification.
Reducing dependency on large datasets
Collecting large, high-quality datasets for machine vision systems can be time-consuming and expensive. Data augmentation reduces this dependency by creating synthetic variations of existing images. This approach allows you to train deep learning models effectively, even with limited data. For instance, introducing noise or flipping images can simulate new scenarios, helping your models generalize better.
Statistical data supports this claim. Augmentation not only improves model optimization but also addresses dataset imbalances. Here are some key benefits:
- It enhances the effectiveness of models trained on limited data.
- It acts as a regularizer, reducing overfitting during training.
- It improves learning outcomes for models that initially perform poorly.
By using data augmentation, you can achieve enhanced generalization without the need for massive datasets, saving both time and resources.
Mitigating overfitting and improving generalization
Overfitting occurs when your models perform well on training data but fail to generalize to new, unseen images. Data augmentation mitigates this issue by introducing variability into the training process. When your models encounter diverse augmented images, they learn to focus on essential features rather than memorizing specific patterns.
Research findings highlight the effectiveness of augmentation in combating overfitting. For example, EfficientNet_b0 saw a 50% improvement in accuracy when augmentation techniques were applied. The chart below illustrates the overall accuracy boost and kappa value improvements:
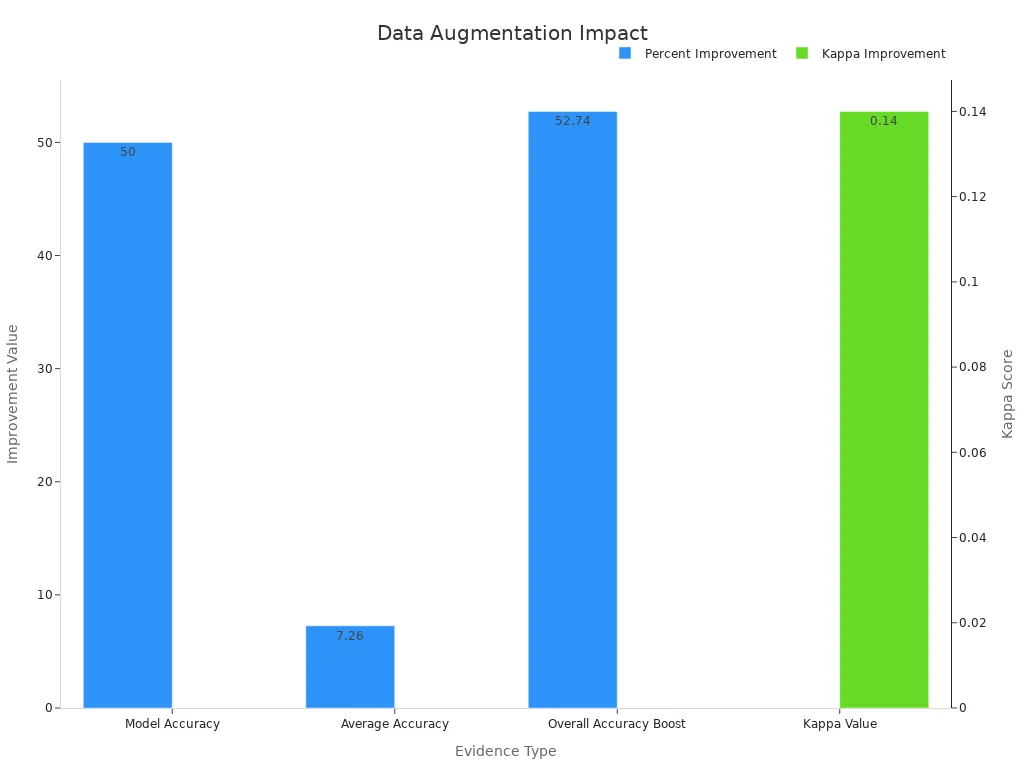
These results demonstrate how augmentation fosters enhanced generalization, enabling your machine vision systems to perform consistently across different datasets. By incorporating techniques like noise injection or mixup, you can ensure your models remain robust and adaptable.
How Data Augmentation Works
Exploring datasets and identifying gaps
Before applying data augmentation, you need to evaluate your dataset to identify gaps that could hinder model performance. This step ensures that the augmented data addresses specific weaknesses in your image datasets. Several methodologies help you pinpoint these gaps:
- Evaluate the generalization gap by comparing model performance on training and validation datasets.
- Assess how illumination variations affect your models’ ability to recognize objects.
- Analyze feature diversity by categorizing intrinsic properties (like texture or shape) and external environmental factors (like lighting or occlusion).
- Identify distribution imbalances in visual features, such as underrepresented colors or shapes, and their impact on predictions.
By understanding these gaps, you can tailor your augmentation techniques to improve the robustness of your machine learning models. For example, if your dataset lacks images with varying lighting conditions, photometric adjustments can simulate these scenarios effectively.
Applying data augmentation techniques
Once you identify gaps, you can apply data augmentation techniques to create diverse and representative datasets. These techniques modify existing images to generate augmented samples that enhance model learning. Common methods include geometric transformations, photometric adjustments, and noise injection. Advanced techniques like mixup and cutout combine multiple approaches to create even more complex variations.
Quantitative results validate the success of these techniques in machine vision applications. For example:
| Study | Technique | Performance Metric | Result |
|---|---|---|---|
| Kandel et al. (2021) | Test Time Augmentation (TTA) | Classification Performance | Dramatic improvement observed |
| Nanni et al. | Various Augmentation Techniques | ResNet50 Performance | Enhanced across multiple datasets |
These results highlight how augmentation improves accuracy and generalization across different datasets. Practical applications include handwritten digit recognition, postal code identification, and bank check processing. By applying these techniques, you can ensure your models perform well in diverse real-world scenarios.
Integrating augmented data into training pipelines
After generating augmented samples, you need to integrate them into your training pipelines. This step involves combining original and augmented data to create a comprehensive dataset for model training. You can use automation tools and libraries like TensorFlow or PyTorch to streamline this process.
When integrating augmented data, focus on maintaining a balance between original and synthetic images. Overloading your dataset with augmented samples can lead to overfitting, where models rely too heavily on specific patterns. Instead, aim for a mix that enhances feature diversity without compromising generalization.
Augmented data also plays a crucial role in iterative training. By continuously introducing new variations, you can refine your models and improve their adaptability to unseen images. This approach ensures your machine vision systems remain robust and reliable across different applications.
Key Data Augmentation Techniques

Geometric transformations
Geometric transformations modify the spatial structure of images, helping your models recognize objects in different orientations or positions. These transformations include rotation, scaling, flipping, and cropping. For example, rotating an image by 90 degrees or flipping it horizontally creates new perspectives for your models to learn. This technique is especially useful in computer vision tasks like object detection, where objects may appear in various angles or sizes.
By applying geometric transformations, you can generate augmented images that improve feature diversity. This ensures your models become more adaptable to real-world scenarios. For instance, scaling an image simulates objects at different distances, while cropping focuses on specific regions, enhancing your model’s ability to detect details.
Photometric adjustments
Photometric adjustments alter the visual properties of images, such as brightness, contrast, and color. These adjustments simulate different lighting conditions, enabling your models to perform well under varying environments. For example, increasing brightness mimics daylight, while reducing it replicates nighttime conditions.
Statistical comparisons highlight the effectiveness of photometric adjustments in image data augmentation. The table below shows how these methods outperform traditional imaging approaches:
| Method | RMSE Value (mm) | Performance |
|---|---|---|
| Proposed Method | 0.025 | Best |
| Other Approaches (Object D) | >1.1 | Poor |
| Other Approaches (Object E) | >1.1 | Poor |
These results demonstrate how photometric adjustments enhance accuracy and reliability in computer vision applications. By incorporating these adjustments, you can ensure your models remain robust across diverse lighting conditions.
Noise injection and occlusion
Noise injection and occlusion techniques introduce imperfections into images, helping your models handle real-world challenges. Noise injection adds random variations, such as pixel distortions, to simulate camera errors or environmental interference. Occlusion involves blocking parts of an image, forcing your models to focus on essential features rather than relying on specific areas.
Research shows that these techniques significantly improve model generalization. Noise injection enhances robustness by teaching your models to manage image imperfections effectively. Occlusion methods, such as adding noise blocks or deleting pixels, regularize your models and address occlusion challenges. These techniques ensure your models perform consistently, even when images contain unexpected obstacles.
By using noise injection and occlusion, you can create augmented images that prepare your models for unpredictable scenarios. This makes your computer vision systems more reliable in applications like autonomous vehicles or medical imaging.
Advanced methods like mixup and cutout
Advanced data augmentation techniques like mixup and cutout push the boundaries of traditional methods. These approaches create unique variations of images, helping your models learn more effectively and generalize better in computer vision tasks.
Mixup combines two images by blending their pixel values and labels. This technique generates new training samples that lie between the original images. For example, if you mix a cat image with a dog image, the result is a hybrid image with features of both. This forces your models to focus on broader patterns rather than memorizing specific details. Mixup reduces overfitting and improves robustness, especially when your dataset is small or imbalanced.
Cutout introduces random occlusions by masking parts of an image with a black or gray box. This simulates real-world scenarios where objects may be partially hidden. For instance, a car might be obscured by a tree branch in a photo. By training on these augmented images, your models learn to identify objects even when parts are missing. Cutout enhances feature recognition and makes your models more adaptable to challenging environments.
Both techniques have proven effective in improving model performance. Studies show that mixup increases accuracy by encouraging smoother decision boundaries, while cutout strengthens spatial awareness. These methods complement traditional data augmentation techniques, offering a powerful way to create diverse and representative datasets.
When you integrate mixup and cutout into your training pipeline, you unlock new possibilities for image data augmentation. These advanced methods prepare your models for real-world challenges, ensuring they perform reliably across various computer vision applications.
Applications of Data Augmentation in Machine Vision Systems

Healthcare and medical imaging
Data augmentation plays a vital role in healthcare, especially in medical imaging. By creating diverse variations of medical images, you can improve the diagnostic accuracy of machine vision systems. For instance, augmenting X-rays or MRI scans with techniques like rotation, scaling, or noise injection helps models identify abnormalities under different conditions. This ensures that your system performs well across a wide range of patient data.
Recent studies highlight the impact of augmentation in this field:
- Deep learning-based augmentation improves model robustness and diagnostic performance.
- SMOTE and Gaussian noise-based techniques enhance AI performance in medical imaging.
- Untrainable Data Cleansing (UDC) shows that removing poor-quality data, combined with augmentation, significantly boosts accuracy and generalizability.
These advancements make machine vision systems more reliable for tasks like tumor detection, organ segmentation, and disease classification.
Manufacturing and quality control
In manufacturing, data augmentation enhances quality control processes by improving defect detection rates. Augmented images simulate various production scenarios, enabling machine vision systems to identify defects more accurately. For example, applying geometric transformations or noise injection can mimic real-world variations in product appearance, such as scratches, dents, or misalignments.
Performance metrics demonstrate the effectiveness of augmentation in this domain:
- Defect detection rates improve by an average of 32% with augmented analytics.
- Automated anomaly detection reduces the number of defective products reaching customers.
- Enhanced inspection processes lower rework requirements, saving time and resources.
By integrating augmented images into your quality control pipeline, you can ensure consistent product standards and minimize waste.
Retail and inventory management
In retail, data augmentation helps machine vision systems manage inventory more efficiently. Augmented images allow models to recognize products under different lighting conditions, angles, or packaging variations. For example, photometric adjustments can simulate store lighting, while geometric transformations prepare models to identify items from various perspectives.
This approach improves tasks like shelf monitoring, stock counting, and product categorization. By training your system with augmented images, you can reduce errors in inventory tracking and enhance customer satisfaction. Augmentation also supports applications like automated checkout systems, where accurate product recognition is essential.
Autonomous vehicles and object detection
Autonomous vehicles rely heavily on object detection to navigate safely and make decisions in real-time. Data augmentation plays a crucial role in enhancing the performance of object detection models by creating diverse and representative datasets. When you apply augmentation techniques, you help these systems recognize objects under varying conditions, such as different weather, lighting, or angles.
One effective approach involves using image augmentation to simulate real-world scenarios. For example, you can modify images to represent rainy or foggy conditions, ensuring the object detection model learns to identify obstacles in adverse environments. Generative Adversarial Networks (GANs) take this a step further by generating synthetic datasets that mimic complex weather patterns. These datasets improve the model’s ability to generalize across unseen situations. Artificial data creation, such as adding droplets or smudges to images, further prepares the model for challenges it might face on the road.
Here’s a breakdown of methodologies used to enhance object detection in autonomous vehicles:
| Methodology | Description |
|---|---|
| Image Augmentation | Techniques to artificially increase dataset size to improve detection performance in various weather conditions. |
| Generative Adversarial Networks (GANs) | Used to create multiple versions of datasets under different weather conditions, enhancing the model’s ability to generalize. |
| Artificial Data Creation | Involves adding fictitious elements (like droplets) to simulate adverse weather, aiding in training models for real-world scenarios. |
By leveraging these techniques, you ensure that autonomous vehicles can detect objects accurately, even in unpredictable environments. For instance, augmented images of pedestrians in foggy conditions or vehicles in heavy rain enable the system to make reliable decisions. This reduces the risk of accidents and improves overall safety.
Data augmentation also supports iterative training. As you introduce new variations of images, the object detection model becomes more robust and adaptable. This ensures that autonomous vehicles perform consistently, whether navigating urban streets or rural highways.
Advanced Approaches in Data Augmentation
Generative adversarial networks (GANs)
Generative adversarial networks (GANs) have revolutionized data augmentation by creating synthetic images that closely resemble real-world data. These networks consist of two components: a generator and a discriminator. The generator creates new images, while the discriminator evaluates their authenticity. This process continues until the generated images become indistinguishable from real ones.
GANs are particularly effective in scenarios where collecting diverse datasets is challenging. For example, in medical imaging, GANs can generate synthetic X-rays or MRI scans to improve model training. Studies show that using GAN-based augmentation significantly enhances performance:
- An AC-GAN-based solution improved accuracy from 85% to 95% in binary classification tasks for COVID-19 detection.
- The CNN classifier achieved an accuracy of 80% with real data. After employing GAN-based augmentation, the accuracy improved to 96.67%.
| Method | Accuracy with Real Data | Accuracy with GAN-Augmented Data |
|---|---|---|
| CNN Classifier | 80% | 96.67% |
By incorporating GANs into your machine learning pipeline, you can create diverse datasets that improve model generalization and performance.
Variational autoencoders (VAEs)
Variational autoencoders (VAEs) offer another powerful approach to data augmentation. Unlike GANs, VAEs focus on learning the underlying structure of images to generate new samples. They encode input images into a latent space and then decode them back into augmented versions. This method ensures that the generated images retain essential features while introducing variability.
VAEs are particularly useful in applications like anomaly detection or object recognition. For instance, they can create augmented datasets that improve balanced accuracy, true positive rates, and true negative rates. The table below highlights measurable improvements achieved through VAE-based augmentation:
| Metric | Before Augmentation | After Augmentation | Improvement |
|---|---|---|---|
| Balanced Accuracy | X | Y | Small, yet significant |
| True Positive Rate | A | B | Small, yet significant |
| True Negative Rate | C | D | Small, yet significant |
By using VAEs, you can enhance your machine learning models’ ability to handle diverse and complex datasets.
Hybrid techniques combining traditional and AI-driven methods
Hybrid techniques combine traditional augmentation methods, like geometric transformations, with AI-driven approaches, such as GANs or VAEs. This combination leverages the strengths of both strategies to create highly diverse datasets. For example, you can apply geometric transformations to real images and then use GANs to generate synthetic variations. This layered approach ensures that your dataset covers a wide range of scenarios.
Hybrid techniques are especially valuable in computer vision tasks where data diversity is critical. For instance, in autonomous vehicles, you can use traditional methods to simulate different weather conditions and GANs to create synthetic images of rare events, like animals crossing the road. This ensures that your models perform reliably in real-world situations.
By adopting hybrid techniques, you can maximize the effectiveness of data augmentation and improve your models’ adaptability to unseen challenges.
Best Practices for Data Augmentation
Aligning techniques with the problem domain
Choosing the right augmentation techniques depends on the specific problem you are solving. You need to consider the characteristics of your dataset and the goals of your models. For example, if your task involves object detection in computer vision, geometric transformations like rotation or scaling can help your models recognize objects from different angles. On the other hand, photometric adjustments, such as altering brightness or contrast, are more suitable for tasks where lighting conditions vary.
To align augmentation with your problem domain, start by analyzing your dataset. Identify gaps or weaknesses, such as underrepresented features or environmental variations. Then, apply augmentation methods that address these gaps. This approach ensures that your augmented data improves model performance and accuracy in real-world scenarios.
Avoiding over-augmentation
While augmentation enhances datasets, overdoing it can harm your models. Adding too many transformations may introduce noise or unrealistic variations, confusing your models during training. For instance, excessive geometric transformations might distort images to the point where they no longer represent real-world conditions.
To avoid over-augmentation, maintain a balance between original and augmented data. Test different levels of augmentation and monitor your models’ accuracy. If accuracy drops, reduce the intensity or frequency of transformations. Always prioritize quality over quantity when creating augmented data.
Validating augmented data
Validating augmented data is crucial to ensure it benefits your models. Poorly augmented images can mislead your models, reducing accuracy and generalization. To validate your augmented data, compare model performance on augmented and non-augmented datasets. Look for improvements in metrics like accuracy or error rates.
You can also use visualization tools to inspect augmented images. Check if the transformations align with real-world scenarios. For example, ensure that rotated or scaled images still represent the original objects accurately. By validating your augmented data, you can build reliable models that perform well in diverse conditions.
Leveraging automation tools and libraries
Automation tools and libraries make data augmentation faster and more efficient. Instead of manually applying transformations to images, you can use these tools to automate the process. This saves time and ensures consistency when creating augmented data for your machine vision systems.
Several popular libraries simplify automated data augmentation. TensorFlow and PyTorch, for example, offer built-in modules for applying transformations like rotation, flipping, and scaling. These libraries allow you to generate diverse datasets with just a few lines of code. For instance, TensorFlow’s ImageDataGenerator lets you apply real-time augmentation during training. This ensures your models learn from varied images without requiring a separate preprocessing step.
Another powerful tool is Albumentations. It provides a wide range of augmentation techniques, including advanced methods like mixup and cutout. Albumentations is known for its speed and flexibility, making it ideal for large datasets. You can also use OpenCV for basic transformations or Augmentor for creating custom augmentation pipelines.
Here’s an example of how you can use Python to apply automated data augmentation with TensorFlow:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
augmented_images = datagen.flow_from_directory('dataset_directory')
This code snippet demonstrates how to create augmented images directly from your dataset. By leveraging automated data augmentation, you can focus on improving your models rather than spending hours on manual preprocessing.
When choosing a tool or library, consider your project’s requirements. Some tools excel at handling large datasets, while others are better suited for real-time augmentation during training. Experiment with different options to find the best fit for your needs.
Tip: Always validate the augmented data generated by these tools. This ensures the transformations align with real-world scenarios and improve your model’s performance.
By using automation tools and libraries, you can streamline the augmentation process and enhance the quality of your datasets. This approach not only saves time but also ensures your models perform well across diverse applications.
Data augmentation is a cornerstone of any effective data augmentation machine vision system. It enhances model performance by introducing diverse variations, helping systems generalize better and focus on critical features. This approach reduces overfitting and improves accuracy, even when working with limited datasets. By applying transformations like scaling or cropping, you can create robust datasets without the need for extensive data collection.
Machine vision systems across industries, from healthcare to autonomous vehicles, benefit from these techniques. They save time, reduce resource dependency, and enable models to perform reliably in real-world scenarios. Explore data augmentation methods to unlock the full potential of your machine vision applications.
FAQ
What is the main purpose of data augmentation in machine vision?
Data augmentation helps you create diverse datasets by modifying existing images. This improves your model’s ability to generalize and reduces overfitting. It also enhances performance when working with limited data.
Can data augmentation replace the need for large datasets?
No, it cannot fully replace large datasets. However, it reduces your dependency on them by generating synthetic variations. This allows you to train models effectively even with smaller datasets.
Which industries benefit the most from data augmentation?
Industries like healthcare, manufacturing, retail, and autonomous vehicles benefit greatly. Data augmentation improves diagnostic accuracy, defect detection, inventory management, and object recognition in these fields.
Are there risks associated with over-augmentation?
Yes, over-augmentation can introduce unrealistic variations. This confuses your models and reduces accuracy. Always validate augmented data to ensure it aligns with real-world scenarios.
What tools can you use for data augmentation?
You can use tools like TensorFlow, PyTorch, and Albumentations. These libraries offer various techniques, including geometric transformations and advanced methods like mixup and cutout.
See Also
Investigating The Role Of Synthetic Data In Vision Systems
Essential Insights On Transfer Learning For Machine Vision
The Impact Of Deep Learning On Vision System Performance









