Overfitting occurs when a machine vision model learns patterns specific to the training data, including noise or irrelevant details, which hampers its ability to generalize to new data. An overfitting machine vision system can produce unreliable outcomes, such as misclassifying objects in real-world applications, leading to significant performance issues.
Research indicates that smaller datasets often yield higher reported accuracy, but this accuracy may not translate to unseen data, further exacerbating the problem of an overfitting machine vision system. Additionally, reusing test sets during model development can unintentionally contribute to overfitting. Tackling overfitting in a machine vision system is crucial to ensure models deliver accurate predictions and perform effectively across diverse scenarios.
Key Takeaways
-
Overfitting happens when a model learns too much from training data, including useless details, and performs badly on new data.
-
To stop overfitting, use tricks like data augmentation. This adds changes to training data, helping models work well on different data.
-
Regularization methods, like dropout and L2 regularization, reduce overfitting. They stop the model from depending too much on certain details in the training data.
-
Watching training and validation errors can show overfitting. If training error gets smaller but validation error gets bigger, it’s a warning sign.
-
Cross-validation is important for testing models. It checks the model on different data groups, making it stronger and less likely to overfit.
What is Overfitting in Machine Vision?
Definition and Key Characteristics
Overfitting happens when a machine vision model learns the training data too well, including noise or irrelevant details. This makes the model perform poorly on new data. Imagine teaching a child to recognize cats by showing them only pictures of black cats. If the child assumes all cats are black, they’ve “overfitted” to the examples provided. Similarly, an overfitting machine vision system struggles to generalize well to unseen data.
Key characteristics of overfitting include:
-
A significant gap between training and validation errors. Training error decreases, but validation error either increases or stays the same.
-
The model performs exceptionally well on training data but fails to deliver accurate results on test data.
-
Complex models with too many parameters are more prone to overfitting, especially when the training dataset is small.
For example, studies show that overfitting often occurs when models are overly complex for the problem at hand. A practical case involves predicting retail purchases using timestamps, which may work for the training data but fail to generalize well to new data.
Why Overfitting Matters in Computer Vision
Overfitting in computer vision can severely impact the reliability of your models. When a model overfits, it memorizes the training data instead of learning the underlying patterns. This leads to poor performance in real-world applications, where the data is often different from the training set. For instance, a facial recognition system trained on a limited dataset might fail to recognize faces in different lighting conditions or angles.
Metrics like accuracy, precision, and recall can help you identify overfitting. If your model shows high accuracy on training data but low accuracy on validation data, it’s a clear sign of overfitting. Learning curves also provide valuable insights. A large gap between training and validation error curves indicates that the model is not generalizing well.
Empirical studies highlight that overfitting is more common in computer vision systems with small sample sizes. For example, in speech and language sciences, small datasets often lead to models that perform well on training data but fail on unseen data. Addressing overfitting ensures your computer vision systems remain robust and reliable across diverse scenarios.
Generalization vs. Memorization in Machine Vision Models
Generalization and memorization represent two sides of the same coin in machine vision. Generalization refers to a model’s ability to perform well on new, unseen data. Memorization, on the other hand, occurs when a model learns the training data too specifically, including noise and irrelevant details. Striking the right balance between these two is crucial for building effective machine vision systems.
Research on ResNet models reveals that memorization plays a role in generalization under certain conditions. As model complexity increases, memorization patterns change. For example, deeper models may initially memorize more but later show improved generalization as they learn to focus on meaningful patterns. Techniques like distillation can reduce memorization, especially for challenging examples, enhancing the model’s ability to generalize well.
To avoid overfitting in machine learning, you can use strategies like data augmentation, regularization, and simplifying model architecture. These methods help your model focus on the essential features of the data rather than memorizing irrelevant details. By prioritizing generalization, you ensure your machine vision model performs reliably in real-world applications.
Causes of Overfitting in Machine Vision Systems
Model Complexity and Over-parameterization
When a machine vision model becomes too complex, it starts to memorize the training set instead of learning meaningful patterns. This happens because overly complex models, with too many parameters, can fit even the noise in the dataset. For example, a deep neural network with excessive layers might perform perfectly on the training set but fail to generalize to new data.
Recent research from Stanford University indicates that over-parameterized models can generalize well, even achieving near-zero training error, which contradicts classical learning theory that associates low training error with poor generalization.
While some studies suggest that over-parameterized models can still generalize under specific conditions, this is not always the case. In most scenarios, simpler models are better at avoiding overfitting in machine learning.
|
Cause of Overfitting |
Explanation |
|---|---|
|
Limited Training Data |
Small datasets lead to models fitting to noise rather than genuine patterns. |
|
Noise in Datasets |
Random errors in data can mislead models into identifying false patterns as significant. |
|
Excessively Complex Models |
Highly complex models can capture noise instead of the underlying data distribution, leading to overfitting. |
Insufficient or Poor-Quality Training Data
The quality and quantity of your dataset play a critical role in preventing overfitting. A small or noisy dataset makes it difficult for the model to learn generalizable patterns. Instead, the model memorizes the training set, leading to poor performance on new data.
-
A study found that improving data quality from 10% to 100% increased machine learning performance from 20% to 98%.
-
Lower quality datasets showed less than 70% performance, while higher quality datasets improved accuracy by over 70%.
-
Even small datasets with high quality achieved good performance, with effect sizes around 0.9 and accuracy near 95%.
To reduce overfitting, you should focus on collecting diverse, high-quality data. This ensures the model learns meaningful patterns that apply to real-world scenarios.
Lack of Regularization Techniques
Regularization techniques are essential for controlling overfitting in machine learning. Without them, models tend to fit both the relevant patterns and the noise in the training set. This results in high accuracy on the training set but poor generalization to new data.
-
Regularization can reduce test error by up to 35%, improving generalization on unseen data.
-
Models with regularization show a 20% increase in stability across different data splits.
-
Regularization techniques also reduce variance by approximately 25%, making predictions more robust against noise.
By applying methods like L2 regularization or dropout, you can prevent your model from overfitting. These techniques encourage the model to focus on the most important features of the data, improving its ability to handle new data effectively.
Over-reliance on Training Data Patterns
Over-reliance on training data patterns is a common cause of overfitting in machine learning. When your model depends too heavily on the specific patterns in the training dataset, it struggles to adapt to new data. This happens because the model memorizes the training examples instead of learning generalizable features. As a result, the model performs well on the training set but fails to deliver accurate predictions on unseen data.
Imagine training a machine vision model to identify animals using a dataset that contains only images of cats and dogs. If the model relies solely on the patterns in this dataset, it might misclassify other animals, such as horses or birds, in real-world scenarios. This reliance limits the model’s ability to generalize, making it less effective in diverse applications.
To reduce over-reliance on training data patterns, you can diversify your dataset. Include a wide range of examples that represent different scenarios, lighting conditions, and object variations. For instance, if you’re training a facial recognition system, use images with various angles, expressions, and backgrounds. This approach helps your model learn broader patterns, improving its ability to handle new data.
Tip: Data augmentation techniques, such as flipping, rotating, or cropping images, can create additional examples from your existing dataset. These techniques enhance diversity without requiring new data collection.
Another strategy involves using regularization methods. Techniques like dropout force the model to rely less on specific neurons, encouraging it to focus on general features. Regularization reduces the risk of overfitting and improves the model’s robustness.
By addressing over-reliance on training data patterns, you ensure your machine vision system performs reliably across different environments. This step is crucial for building models that generalize well and avoid the pitfalls of overfitting.
Detecting Overfitting in Computer Vision
Monitoring Training and Validation Errors
Monitoring training and validation errors is one of the most effective ways to identify overfitting in computer vision models. You can observe these errors during the training process to understand how well your model generalizes to unseen data. A clear sign of overfitting is when the training error continues to decrease while the validation error plateaus or starts increasing. This indicates that the model is memorizing the training set instead of learning general patterns.
Quantitative metrics like the F1 Score, confusion matrix, and ROC curve can help you analyze the performance of your model. For example:
|
Metric |
Description |
|---|---|
|
F1 Score |
Balances precision and recall, especially useful for binary classification tasks. |
|
Confusion Matrix |
Displays actual versus predicted classifications, highlighting correct and incorrect predictions. |
|
ROC Curve |
Plots the true positive rate against the false positive rate, helping you evaluate classification thresholds. |
By regularly comparing these metrics for both training and validation datasets, you can detect and avoid overfitting before it becomes a significant issue.
Analyzing Learning Curves
Learning curves provide a visual representation of your model’s performance over time. These curves plot metrics like accuracy or loss for both the training and validation datasets across training epochs. A widening gap between the two curves is a strong indicator of overfitting in machine learning. Ideally, both curves should converge as training progresses.
Key indicators to watch for include:
-
High training accuracy with low validation accuracy.
-
A consistent decrease in training error while validation error remains stagnant or increases.
-
A lack of improvement in validation performance after a certain number of epochs.
|
Indicator |
Description |
|---|---|
|
Accuracy Discrepancy |
High training accuracy with low test accuracy indicates overfitting. |
|
Learning Curves |
A widening gap between training and validation error signals overfitting. |
|
Training Error |
Should decrease over time; validation error should plateau or decrease. |
|
Ideal Scenario |
Both training and validation errors decrease and converge. |
By analyzing these trends, you can determine when your model begins to overfit and take corrective actions, such as early stopping or regularization.
Visualization Techniques for Overfitting Detection
Visualization techniques offer powerful tools for detecting overfitting in computer vision models. Training dynamics plots, learning curves, and gradient plots are particularly useful for identifying when a model starts to memorize the training set instead of generalizing.
|
Visualization Technique |
Purpose |
|---|---|
|
Training Dynamics Plots |
Show performance metrics (e.g., loss and accuracy) over training epochs to identify overfitting. |
|
Learning Curves |
Compare training and validation performance to pinpoint when overfitting begins. |
|
Gradient Plots |
Visualize the gradients of the loss function to understand the model’s training progress. |
For example, a training dynamics plot can reveal if the model’s loss decreases on the training set but stagnates or increases on the validation set. Similarly, learning curves can help you identify the exact epoch where overfitting starts, allowing you to implement strategies like early stopping. These visual tools make it easier to diagnose and address overfitting in computer vision systems.
Tip: Use these visualization techniques alongside quantitative metrics for a more comprehensive evaluation of your model’s performance.
Cross-Validation for Robust Evaluation
Cross-validation is a powerful technique for evaluating your machine vision model’s ability to generalize to unseen data. It helps you detect overfitting by testing the model on multiple subsets of your dataset. Instead of relying on a single train-test split, cross-validation ensures a more robust evaluation by using different portions of the data for training and testing.
One of the most common strategies is K-Fold Cross-Validation. This method divides your dataset into k equal-sized groups, or folds. The model trains on k-1 folds and tests on the remaining fold. This process repeats k times, with each fold serving as the test set once. The final performance metric is the average of all test results, providing a comprehensive view of your model’s accuracy.
Another approach is Leave-One-Out Cross-Validation (LOO). In this method, each data point is used as a test set once, while the rest form the training set. Although computationally expensive, LOO is highly effective for small datasets, as it maximizes the use of available data.
|
Cross-validation Strategy |
Description |
|---|---|
|
K-Fold |
Divides samples into k groups (folds); uses k-1 for training and 1 for testing. |
|
Leave One Out (LOO) |
Each sample is left out once for testing, creating n different training sets. |
Cross-validation not only helps you evaluate your model but also provides insights into its stability. For example, if your model performs well on some folds but poorly on others, it may indicate overfitting or data imbalance. By incorporating cross-validation into your workflow, you can confidently assess your model’s performance and make necessary adjustments to improve its generalization.
Tip: Use K-Fold Cross-Validation with a higher value of k (e.g., 10) for larger datasets. For smaller datasets, consider LOO to maximize data usage.
Preventing Overfitting in Machine Vision Systems
Data Augmentation and Diversification
Data augmentation and diversification are powerful techniques to reduce overfitting in machine vision systems. By artificially expanding your dataset, you can help your model learn broader patterns and improve its ability to generalize to unseen data. These methods introduce variations in the training data, forcing the model to focus on meaningful features rather than memorizing specific examples.
Common data augmentation techniques include random cropping, flipping, rotating, and adding noise to images. For instance, random cropping can improve accuracy by exposing the model to different parts of an image, while noise injection challenges the model to identify objects despite distortions. These techniques have shown measurable improvements in reducing overfitting:
|
Technique |
Improvement Metric |
|---|---|
|
Random Cropping |
Accuracy increased from 72.88% to 80.14% |
|
Kappa value improved from 0.43 to 0.57 |
|
|
Noise Injection |
Accuracy boost from 44.0% to 96.74% |
Tip: Use data augmentation tools like TensorFlow or PyTorch to automate these processes. They simplify the implementation and ensure consistent results.
Diversifying your dataset is equally important. Include images with varying lighting conditions, angles, and object sizes. For example, if you’re training a neural network to recognize vehicles, add images of cars in different weather conditions and from multiple perspectives. This approach ensures your model learns patterns that apply to real-world scenarios, reducing the risk of overfitting.
Regularization Techniques (e.g., Dropout, L2 Regularization)
Regularization techniques play a crucial role in controlling overfitting. These methods prevent your model from relying too heavily on specific features in the training data, encouraging it to generalize better. Two widely used techniques are dropout and L2 regularization.
Dropout works by randomly “dropping out” neurons during training. This forces the model to rely on multiple pathways to make predictions, reducing its dependency on specific neurons. L2 regularization, on the other hand, penalizes large weights in the model, encouraging simpler and more generalizable solutions.
Statistical comparisons highlight the effectiveness of these techniques:
|
Technique |
Test Accuracy |
Test Loss |
|---|---|---|
|
Baseline |
0.9787 |
0.1086 |
|
Dropout |
0.9796 |
0.0730 |
|
L2 Regularization |
0.9774 |
0.1226 |
|
Batch Normalization |
0.9822 |
0.0882 |
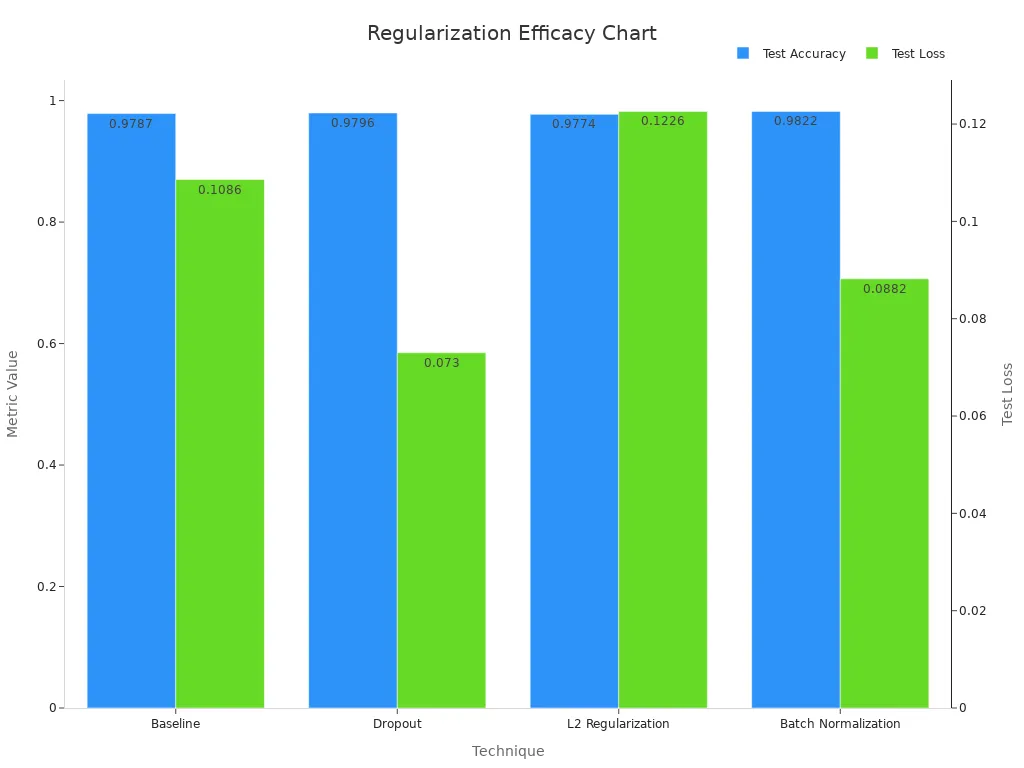
Note: Combining dropout with L2 regularization often yields better results. Experiment with different regularization strengths to find the optimal balance for your model.
Regularization techniques not only improve your model’s performance but also make it more robust against noise and variations in the data. By incorporating these methods, you can detect and avoid overfitting effectively.
Simplifying Model Architecture
Simplifying your model architecture is another effective way to prevent overfitting. Complex models with too many parameters often memorize the training data instead of learning generalizable patterns. By reducing the number of layers or neurons, you can create a model that focuses on essential features without overfitting.
For example, if you’re building a convolutional neural network for image classification, start with a smaller number of convolutional layers. Gradually increase complexity only if the model struggles to capture meaningful patterns. Avoid adding unnecessary layers or parameters that don’t contribute to better performance.
Tip: Use techniques like pruning to remove redundant neurons or layers. This reduces the model’s complexity while maintaining its accuracy.
Simpler architectures also train faster and require less computational power, making them ideal for applications with limited resources. By prioritizing simplicity, you ensure your model performs well on both training and validation data, minimizing the risk of overfitting.
Cross-Validation and Early Stopping
Cross-validation and early stopping are two effective techniques to prevent overfitting in machine vision systems. These methods help you evaluate your model’s performance and ensure it generalizes well to new data.
Cross-validation divides your dataset into multiple subsets, allowing you to test the model on different portions of the data. One popular approach is K-Fold Cross-Validation. This method splits the dataset into k groups, using k-1 groups for training and the remaining group for testing. The process repeats k times, and the final performance is the average of all test results. This technique ensures that your model is tested on various data splits, making it more robust. Leave-One-Out Cross-Validation (LOO) is another option, especially useful for small datasets. In this method, each data point serves as a test set once, maximizing the use of available data.
Early stopping, on the other hand, monitors your model’s performance during training. It halts the training process when the validation error stops improving, preventing the model from overfitting to the training set. For example, researchers like Shi et al. have successfully used early stopping in deep learning models, such as training a Siamese network to identify hidden patterns in chat messages. This technique ensures that your model focuses on meaningful patterns without memorizing irrelevant details.
To implement these methods effectively:
-
Use cross-validation to evaluate your model’s stability across different data splits.
-
Apply early stopping to halt training when validation performance plateaus or worsens.
These strategies not only improve your model’s ability to handle new data but also save computational resources by avoiding unnecessary training.
Improving Training Data Quality and Quantity
The quality and quantity of your dataset play a critical role in building a reliable machine vision system. A high-quality dataset ensures that your model learns meaningful patterns, while a larger dataset reduces the risk of overfitting.
To improve data quality, focus on removing noise and inconsistencies. For instance, clean up mislabeled images or blurry photos that could confuse your model. High-quality data allows your model to identify relevant features, improving its performance on new data. Diversifying your dataset is equally important. Include images with different lighting conditions, angles, and object variations. This ensures your model learns patterns that apply to real-world scenarios.
Increasing the quantity of your dataset can also enhance your model’s generalization. Data augmentation is a practical way to achieve this. Techniques like flipping, rotating, and cropping images create additional examples from your existing dataset. These methods expose your model to a wider range of scenarios, helping it perform better on unseen data. For example, adding noise to images can make your model more robust against distortions.
Tip: Use tools like TensorFlow or PyTorch to automate data augmentation. These libraries offer built-in functions to generate diverse training examples efficiently.
By improving both the quality and quantity of your dataset, you ensure your machine vision model performs reliably across different environments. This step is essential for reducing overfitting and building a system that generalizes well to new data.
Real-World Impacts of Overfitting in Computer Vision
Examples of Overfitting in Machine Vision Applications
Overfitting in computer vision often leads to models that excel during training but fail when exposed to new data. For example, a study on deep learning models for predicting breast cancer metastasis revealed this issue. Models trained with randomized data showed a clear pattern: as the number of training epochs increased, the models performed better on the training dataset but worse on testing data. This behavior highlights how overfitting can cause a model to memorize training patterns instead of learning generalizable features.
Another example involves facial recognition systems. When trained on datasets with limited diversity, these systems may recognize faces accurately in controlled environments but struggle with variations like lighting or angles. This limitation reduces their effectiveness in real-world applications, where conditions are unpredictable.
Consequences for Model Performance and Decision-Making
Overfitting in computer vision can lead to poor model performance and flawed decision-making. Models that overfit often learn surface-level patterns rather than true relationships in the data. This issue becomes evident in production environments, where such models fail to adapt to new data. For instance, Zillow’s machine learning trading models suffered significant financial losses because they relied on patterns that did not generalize well, resulting in poor decisions.
In safety-critical applications, such as autonomous vehicles, overfitting can have severe consequences. A vehicle’s vision system might misinterpret objects or fail to detect hazards, leading to accidents. These failures underscore the importance of building robust computer vision systems that prioritize generalization over memorization.
Long-Term Implications for Machine Vision Systems
The long-term effects of overfitting extend beyond immediate performance issues. Overfitting machine vision systems can erode trust in AI technologies. Users may lose confidence in systems that fail to perform reliably in diverse scenarios. Additionally, organizations may face financial and reputational damage due to poor model performance.
Addressing overfitting is essential for the future of machine vision. By improving datasets, applying regularization techniques, and simplifying model architectures, you can ensure your systems remain effective and adaptable. These steps not only enhance performance but also build a foundation for sustainable advancements in computer vision.
Understanding and addressing overfitting is essential for building reliable machine vision systems. Overfitting limits a model’s ability to generalize, leading to poor performance on unseen data. By focusing on strategies like data augmentation, regularization, and simplifying architectures, you can create models that balance accuracy and adaptability. Improving the quality and diversity of your dataset also plays a critical role in reducing overfitting.
Ensemble methods further enhance robustness by combining predictions from multiple models. These approaches improve accuracy, reduce errors, and make predictions more resilient to noise, as shown below:
|
Benefit |
Description |
|---|---|
|
Accuracy improvement |
Multiple predictors help in averaging out errors, leading to better overall accuracy. |
|
Robust predictions |
Ensembles provide reliable outputs by highlighting different aspects of the data. |
|
Error reduction |
Reduces the risk of misclassification by leveraging diverse strategies. |
|
Variance reduction |
The ensemble approach can reduce the variance of predictions, enhancing stability. |
|
Resilience to noise |
Models in an ensemble process data independently, diluting the influence of anomalous data points. |
As machine vision technologies evolve, you must adopt proactive measures to manage overfitting. Leveraging larger, more diverse datasets and integrating advanced techniques will ensure your models remain effective in dynamic environments.
FAQ
What is the simplest way to detect overfitting in a machine vision model?
You can monitor the gap between training and validation errors. If training error decreases while validation error increases, your model is likely overfitting. Use learning curves to visualize this trend.
Tip: Regularly evaluate your model on unseen data to catch overfitting early.
How does data augmentation help prevent overfitting?
Data augmentation creates variations in your training data, forcing the model to learn general patterns. Techniques like flipping, rotating, and adding noise make your dataset more diverse, improving generalization.
|
Technique |
Example |
|---|---|
|
Flipping |
Horizontal image flip |
|
Adding Noise |
Random pixel changes |
Can overfitting occur even with a large dataset?
Yes, overfitting can still happen if your model is too complex. Large datasets reduce the risk but don’t eliminate it. Simplify your model architecture or apply regularization techniques to address this issue.
What is the role of early stopping in preventing overfitting?
Early stopping halts training when validation performance stops improving. This prevents your model from memorizing the training data. It’s an effective way to balance training time and model generalization.
Note: Use early stopping with cross-validation for optimal results.
Why is cross-validation important in machine vision?
Cross-validation tests your model on multiple data splits, ensuring it performs well across different subsets. This helps you detect overfitting and improves your model’s robustness.
Example: K-Fold Cross-Validation divides your data into k groups, training on k-1 and testing on the remaining fold.
See Also
Understanding Computer Vision Models And Their Systems
Do Filtered Machine Vision Systems Improve Precision?
Fundamentals Of Camera Resolution In Vision Systems
The Role Of Cameras In Machine Vision Systems
Essential Insights On Transfer Learning For Machine Vision









