
Generative Adversarial Networks (GANs) are revolutionizing the way machines perceive and process visual data within a machine vision system. You can think of GANs as a creative duo where one part generates data while the other evaluates its realism. This dynamic helps GANs produce lifelike images, videos, and other visual content. By enabling machines to simulate reality, GANs have become essential for building advanced generative adversarial network GAN machine vision systems. From creating synthetic training data to improving image quality, their applications push the boundaries of what machines can achieve in visual tasks.
Key Takeaways
- Generative Adversarial Networks (GANs) use two parts: a generator and a discriminator. The generator makes data, and the discriminator checks it. They compete to make better data.
- GANs are useful for creating images, improving data, and making clearer pictures. They help in areas like medicine and self-driving cars.
- Training GANs needs balance. If one part gets too strong, the other part struggles. This can cause problems like repeating the same results.
- Conditional GANs let you create specific types of data. You can control how the output looks, which helps in special tasks.
- It’s important to use GANs responsibly. Be careful about misuse, privacy issues, and unfair results in the data.
Understanding Generative Adversarial Networks
What is a GAN?
A Generative Adversarial Network (GAN) is a type of artificial intelligence framework that uses two neural networks to create and evaluate data. These networks, called the generator and the discriminator, work together in a competitive process. The generator produces new data, such as images, by modifying random input. Meanwhile, the discriminator evaluates whether the data is real or fake. This adversarial process continues until the discriminator can no longer distinguish between real and generated data.
- Key concepts of a GAN include:
- The generator creates data that mimics real-world samples.
- The discriminator acts as a judge, determining the authenticity of the data.
- Both networks improve through competition, refining their outputs over time.
This dynamic makes GANs powerful tools for generating realistic images and other types of data.
Generator and Discriminator Roles
In a GAN, the generator and discriminator have distinct but interconnected roles. The generator starts with random noise and transforms it into data that resembles real-world examples. Its goal is to "fool" the discriminator into believing the data is authentic. On the other hand, the discriminator evaluates both real and generated data, providing feedback to the generator.
-
The generator’s role:
- Produces data that mimics real samples.
- Learns from the discriminator’s feedback to improve its output.
-
The discriminator’s role:
- Differentiates between real and generated data.
- Helps the generator refine its data generation process.
This interplay ensures that the generator becomes better at creating realistic data, while the discriminator sharpens its ability to detect fake data.
Adversarial Training Explained
Adversarial training is the core process that drives a GAN. It involves the generator and discriminator competing against each other to improve their performance. The generator tries to create data that looks real, while the discriminator attempts to identify fake data. This competition pushes both networks to enhance their capabilities.
However, adversarial training comes with challenges. Issues like gradient vanishing and mode collapse can disrupt the process. To address these, researchers have developed advanced models like PMF-GAN. This model uses kernel optimization and histogram transformation to improve the discriminator’s performance and prevent mode collapse. As a result, PMF-GAN achieves higher visual quality and better evaluation metrics compared to traditional GANs.
A study comparing different GAN architectures highlights their effectiveness in various applications:
| GAN Architecture | Medical Imaging Modality | FID Score | Segmentation Accuracy |
|---|---|---|---|
| DCGAN | Cardiac cine-MRI | High | Moderate |
| Style-based GAN | Liver CT | Very High | High |
| Other GANs | RGB Retina Images | Variable | Low |
This table demonstrates how GANs excel in generating realistic data for specific tasks, such as medical imaging. By refining adversarial training techniques, GANs continue to push the boundaries of data generation and machine vision systems.
How GANs Work in Machine Vision
Training Process Overview
The training process of a generative adversarial network involves two neural networks, the generator and the discriminator, working in tandem. The generator creates data, such as images, that mimic real-world samples. The discriminator evaluates these images to determine if they are real or fake. This back-and-forth process refines both networks over time, enabling the generation of highly realistic images.
GAN training is iterative and requires careful tuning. For example, researchers have used Wasserstein GANs to improve conditional sampling and U-Net generators to enhance conditional data inclusion. These advancements demonstrate how GANs adapt to specific tasks, such as generating 3D models or improving image quality in medical imaging.
Adversarial Dynamics in GANs
The adversarial nature of GANs is what makes them unique. The generator and discriminator engage in a non-cooperative game, where each tries to outperform the other. The generator aims to create convincing images, while the discriminator works to identify fake ones. This dynamic ensures continuous improvement but also introduces challenges.
Maintaining balance between the two networks is critical. If the discriminator becomes too strong, the generator struggles to improve. Conversely, if the generator dominates, the discriminator fails to learn effectively. This balance is akin to finding a Nash Equilibrium, where both networks minimize their respective costs simultaneously. However, the non-convex nature of their cost functions makes this process complex.
| Phase | Description |
|---|---|
| Fitting | The generator begins learning the data distribution. |
| Refining | The generator improves its outputs but may encounter mode mixture. |
| Collapsing | The generator produces limited outputs, leading to mode collapse. |
Steps in GAN Training
Training a GAN involves several sequential steps. Each step plays a crucial role in ensuring the generator and discriminator improve effectively:
- Define the problem and collect relevant data.
- Design the architecture of the generator and discriminator.
- Train the discriminator on real data for several epochs.
- Generate fake inputs and train the discriminator to identify them.
- Use the discriminator’s feedback to train the generator.
- Evaluate the generated images to determine if further training is needed.
For instance, super-resolution GANs have been used to enhance image resolution, which is vital for medical imaging applications like ophthalmology. Conditional GANs have also proven effective in generating synthetic images for better segmentation in OCT imaging. These steps highlight the adaptability of GANs in solving real-world problems within a generative adversarial network GAN machine vision system.
Types of Generative Adversarial Networks
Vanilla GAN
Vanilla GAN is the simplest form of a generative adversarial network. It consists of two neural networks: a generator and a discriminator. The generator creates data samples, while the discriminator evaluates their authenticity. These networks compete in an adversarial process, refining their outputs over time. Vanilla GANs are ideal for basic image generation tasks, but they often face challenges like mode collapse, where the generator produces limited variations of data.
Despite its simplicity, Vanilla GAN laid the foundation for more advanced GAN architectures. Researchers have used it to explore the potential of adversarial training in generating realistic images. However, its performance metrics, such as RMSE and MS-SSIM, often fall short compared to specialized GANs like CycleGAN and SinGAN.
| GAN Type | RMSE Performance | UQI Performance | MS-SSIM Performance | VIF Performance |
|---|---|---|---|---|
| CycleGAN | Best | N/A | Best | N/A |
| SinGAN | N/A | Best | N/A | N/A |
| CGAN | N/A | N/A | N/A | N/A |
| StarGAN | N/A | N/A | N/A | N/A |
Conditional GAN
Conditional GAN (cGAN) introduces conditional information into the adversarial process, allowing you to control the characteristics of generated data. By providing labels or specific inputs, cGANs can produce customized outputs tailored to your needs. For example, you can use cGANs to generate images with specific defect characteristics or enhance data diversity in training datasets.
- Benefits of Conditional GANs:
- Customization: You can control defect characteristics by providing conditional information.
- Data diversity: cGANs generate a wide range of variations, improving dataset robustness.
- Faster convergence: Patterns introduced in the random distribution help the generator learn more efficiently.
- Controlled outputs: Labels provided during testing enable precise control over generated data.
Conditional GANs have proven effective in applications like medical imaging and object detection, where controlled image generation is crucial. Their ability to adapt to specific requirements makes them a powerful tool in machine vision systems.
Deep Convolutional GAN
Deep Convolutional GAN (DCGAN) enhances the Vanilla GAN architecture by incorporating convolutional layers. These layers improve the generator’s ability to create high-quality images and the discriminator’s ability to evaluate them. DCGANs are particularly effective in tasks requiring detailed image generation, such as medical imaging and wireless systems.
Several metrics evaluate DCGAN performance, including Fréchet Inception Distance (FID), Inception Score (IS), and Maximum Mean Discrepancy (MMD). FID, for instance, measures the similarity between generated and real images, providing a quantitative assessment of image quality.
- Key evaluations of DCGANs:
- DCGANs address dataset imbalance in medical imaging by generating realistic samples.
- They improve object detection models significantly compared to other methods.
- Their framework supports deep learning applications in wireless systems.
DCGANs demonstrate remarkable versatility and performance, making them a preferred choice for advanced machine vision tasks.
Super-Resolution GAN
Super-Resolution GAN (SRGAN) is a specialized type of GAN designed to improve image resolution. It takes low-resolution images and transforms them into high-resolution versions with remarkable detail. This process is essential in fields like medical imaging, where clarity and precision are critical.
You might wonder how SRGAN achieves such impressive results. The generator in SRGAN creates high-resolution images by learning patterns from real-world data. Meanwhile, the discriminator evaluates these images to ensure they look authentic. This adversarial process pushes both networks to improve continuously. The result is a system capable of producing images with enhanced sharpness and detail.
The impact of SRGAN is evident in medical imaging. For example:
- In chest X-ray super-resolution, SRGAN achieved a Structural Similarity Index Measure (SSIM) of 0.991 and a Peak Signal-to-Noise Ratio (PSNR) of 38.36 dB.
- In pediatric radiology, SRGAN-based methods reached 0.978 accuracy and 0.900 Area Under the Curve (AUC) for brain MRI-based autism diagnosis.
- For abdominal CT scans, it delivered 31.9 Signal-to-Noise Ratio (SNR) and 21.2 Contrast-to-Noise Ratio (CNR) for denoising.
These metrics highlight the ability of SRGAN to enhance image quality, making it a valuable tool in healthcare. Beyond medicine, you can find SRGAN applications in satellite imaging, video enhancement, and even restoring old photographs. Its versatility and effectiveness make it a game-changer in machine vision systems.
By using SRGAN, you can unlock new possibilities in image processing, enabling machines to see the world with greater clarity and precision.
Applications of GANs in Machine Vision Systems

Image Generation and Synthesis
Generative adversarial networks have transformed how you approach image generation and synthesis. By leveraging the interplay between the generator and discriminator, GANs can create realistic images that closely resemble real-world data. This capability is particularly valuable in fields like medical imaging, autonomous driving, and entertainment, where generating high-quality images is essential.
For example, GANs have been used to generate new data for road damage detection and crack surface analysis. The performance improvements achieved through GAN-based image synthesis are remarkable. The table below highlights the percentage improvements across various datasets:
| Dataset | Improvement (%) |
|---|---|
| Road Damage Detection 2022 | 33.0 |
| Crack Dataset | 3.8 |
| Asphalt Pavement Detection Dataset | 46.3 |
| Crack Surface Dataset | 51.8 |
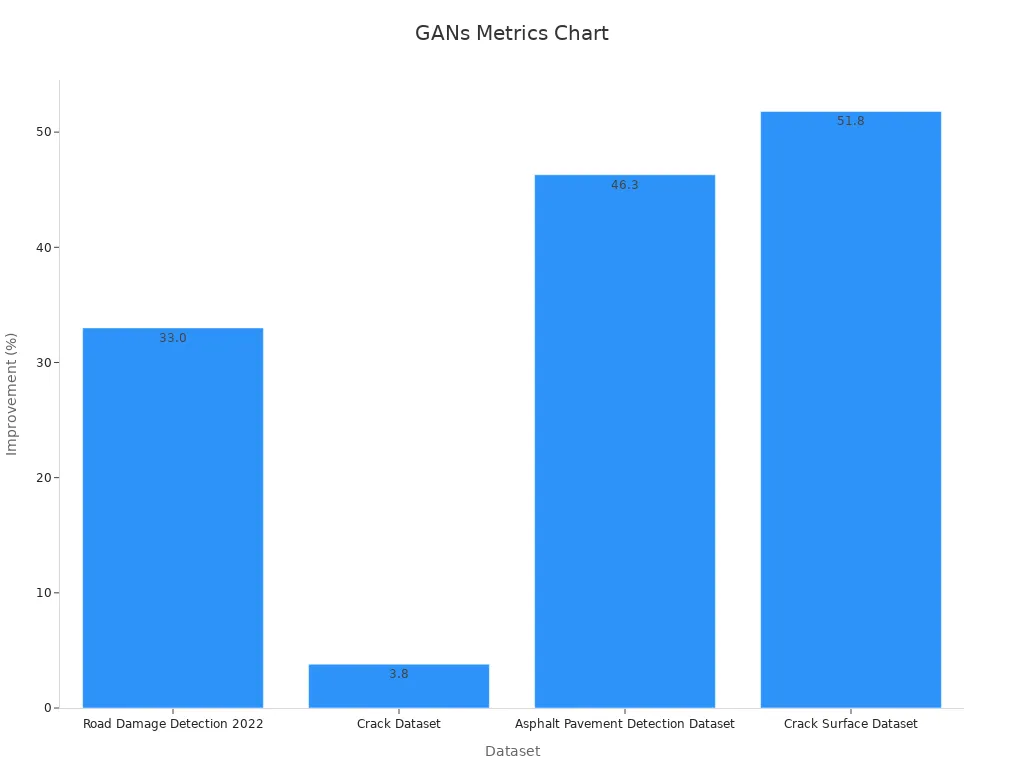
These results demonstrate how GANs excel in generating synthetic data for machine vision systems. By using GANs, you can enhance the quality and diversity of your datasets, enabling better performance in tasks like defect detection and object recognition.
Data Augmentation
GANs play a crucial role in data augmentation, especially when you face limited training data. By generating synthetic data, GANs help you expand your dataset, improving the performance of machine learning models. This is particularly useful in scenarios where collecting real-world data is challenging or expensive.
A compelling example comes from a study on classifying C-shaped root canals in dental imaging. These canals are difficult to diagnose due to their complex shapes. Researchers used GANs to synthesize periapical images, which were then added to the training dataset. The results showed that the neural network’s classification accuracy improved significantly. Metrics like the Frechet Inception Distance (FID) confirmed that the GAN-generated images were visually indistinguishable from real ones. This case study highlights how GANs can enhance visual processing by providing high-quality synthetic data for training.
By incorporating GANs into your data augmentation strategy, you can overcome the limitations of small datasets. This approach not only improves model accuracy but also ensures that your machine vision system performs reliably in real-world scenarios.
Super-Resolution and Image Enhancement
Super-resolution GANs (SRGANs) have revolutionized image enhancement by transforming low-resolution images into high-resolution versions. This process is vital in fields like medical imaging, satellite imaging, and video processing, where clarity and detail are critical.
GANs achieve super-resolution by training the generator to learn patterns from real-world data while the discriminator evaluates the quality of the generated images. Metrics like Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) are commonly used to measure the effectiveness of GAN-based super-resolution models. The table below provides an overview of these metrics:
| Metric | Description | Example Values |
|---|---|---|
| PSNR | Peak Signal-to-Noise Ratio, measures the quality of reconstructed images | Higher values indicate better quality |
| SSIM | Structural Similarity Index, assesses the visual impact of three characteristics of an image | Values range from 0 to 1, with 1 being perfect similarity |
- ESRGAN, an advanced GAN model, outperforms SRGAN in both PSNR and SSIM metrics for ×2 scaling on the Set14 dataset.
- Other GAN models, such as PGGAN and ESRGAN, have been evaluated across datasets like BSD100 and DIV2K, showcasing their versatility.
By using super-resolution GANs, you can achieve photorealistic results that enhance the quality of images in various applications. Whether you’re working on medical diagnostics or restoring old photographs, GANs provide a powerful tool for improving image resolution and detail.
3D Model Creation
Generative Adversarial Networks (GANs) have unlocked new possibilities in creating 3D models from 2D images. This capability is transforming industries like gaming, architecture, and healthcare, where accurate 3D representations are essential. By leveraging adversarial training, GANs can learn patterns from 2D data and reconstruct them into detailed 3D models. This process eliminates the need for expensive and time-consuming manual modeling.
How GANs Enable 3D Model Creation
You might wonder how GANs manage to create 3D models from flat, 2D images. The secret lies in their ability to learn spatial relationships and depth information through adversarial training. The generator in a GAN predicts the 3D structure of an object, while the discriminator evaluates its accuracy. Over time, this back-and-forth process refines the 3D model, making it more realistic.
For example, GANs can take a single image of a car and generate a 3D model that captures its shape, proportions, and even surface details. This approach eliminates the need for multiple camera angles or pre-aligned 3D data, which traditional methods often require.
Advancements in 3D Modeling with GANs
Researchers have developed specialized GAN algorithms to improve 3D model creation. One such innovation is MapGANs, which excels at reconstructing 2D images into 3D models. These advancements address challenges like limited data availability and the complexity of 3D visualization. The table below highlights key findings from recent research:
| Evidence Description | Key Findings |
|---|---|
| MapGANs algorithm’s performance | Accurately reconstructs 2D images into 3D models and determines product qualification rates based on parameters. |
| Learning features through GANs | Demonstrates the ability of GANs to learn and generate images through adversarial training, providing a novel approach to 3D image construction. |
| Addressing challenges in 3D visualization | Focuses on learning 3D models from 2D images, overcoming limitations of previous models that required aligned 3D shape data. |
These findings show how GANs are reshaping the way you approach 3D modeling. By learning directly from 2D images, GANs reduce the dependency on traditional 3D datasets, making the process more efficient and accessible.
Applications of 3D Models in Machine Vision
The ability to create accurate 3D models has far-reaching applications. In healthcare, GANs help reconstruct 3D models of organs from medical scans, aiding in diagnosis and surgical planning. In the automotive industry, GANs generate 3D models of vehicles for design and testing. Even in entertainment, GANs bring characters and environments to life with stunning realism.
Tip: If you’re working on a project that requires 3D modeling, consider using GAN-based tools. They can save time and resources while delivering high-quality results.
By integrating GANs into your workflow, you can unlock new levels of creativity and precision in 3D modeling. Whether you’re designing a virtual world or analyzing medical data, GANs provide the tools you need to succeed.
Benefits and Challenges of GANs
Advantages of GANs in Machine Vision
GANs offer remarkable benefits in machine vision, making them a powerful tool for various applications. One of their key strengths lies in their ability to generate realistic synthetic data. For instance, GANs have been used to create synthetic CTA images with an impressive diagnostic accuracy of 94%. This capability is particularly valuable in medical imaging, where high-quality data is essential for accurate diagnoses.
Another advantage of GANs is their ability to enhance image quality. Models like CycleGAN have demonstrated exceptional performance in image processing tasks. In a study involving 30 experiments, CycleGAN achieved the lowest Frechet Inception Distance (FID) score of 103.49 and Kernel Inception Distance (KID) score of 0.038. These metrics highlight the effectiveness of GANs in producing visually convincing images.
By leveraging adversarial training, GANs also improve the diversity of generated data. This feature is crucial for applications like autonomous driving, where diverse datasets help train robust machine vision systems. With these advantages, GANs continue to push the boundaries of what machines can achieve in visual tasks.
Challenges in Training GANs
Despite their potential, GANs face several challenges during training. One common issue is mode collapse, where the generator produces limited variations of data. For example, when trained on the MNIST dataset, a GAN might only generate images of the digit "0," failing to capture the full diversity of the data.
Another challenge is convergence failure. The dynamic interaction between the generator and discriminator often leads to instability. If the discriminator becomes too strong, the generator struggles to improve, and vice versa. This makes it difficult to achieve a stable balance during training.
| Challenge | Explanation |
|---|---|
| Mode Collapse | The generator fails to learn the full data distribution, resulting in a lack of variety in outputs. |
| Convergence Failure | The competing nature of the generator and discriminator creates instability, complicating the optimization process. |
Addressing these challenges requires careful tuning of hyperparameters and the use of advanced techniques like Wasserstein GANs. These methods help stabilize the training process and improve the overall performance of GANs.
Ethical Concerns in GAN Applications
The use of GANs raises important ethical concerns that you must consider when deploying these models. One major issue is the potential misuse of GANs for malicious purposes, such as creating deepfakes or generating misleading content. This highlights the need for responsible deployment and adherence to ethical guidelines like GDPR.
Privacy and data security are also critical concerns. GANs often require large datasets for training, which may include sensitive user information. Implementing robust security protocols can help protect this data and ensure compliance with privacy regulations.
Additionally, fairness and bias in GAN-generated data remain ongoing challenges. A review of GAN applications emphasized the importance of developing evaluation measures that address these issues. By prioritizing ethical considerations, you can ensure that GANs are used responsibly and for the benefit of society.
Note: Always evaluate the ethical implications of your GAN applications to avoid unintended consequences.
Generative adversarial networks have reshaped how machines process visual data. Their ability to create realistic images and enhance image quality has made them indispensable in machine vision systems. You can use these networks to generate synthetic data, improve super-resolution, and even reconstruct 3D models. These advancements highlight their potential to revolutionize visual data processing.
Exploring GANs further opens doors to innovative solutions in fields like healthcare, entertainment, and autonomous systems. By understanding their capabilities, you can unlock new possibilities for creating realistic images and improving machine vision systems.
FAQ
1. What makes GANs unique compared to other AI models?
GANs stand out because they use two networks—the generator and discriminator—that compete to improve each other. This adversarial process helps GANs create highly realistic images and data, which many other AI models cannot achieve.
2. Can GANs be used with small datasets?
Yes, you can use GANs with small datasets. They generate synthetic data to expand your dataset, improving model training. However, smaller datasets may limit the diversity of generated outputs, so careful tuning is essential.
3. How do GANs improve image quality?
GANs enhance image quality by learning patterns from real-world data. Models like SRGAN transform low-resolution images into high-resolution ones. This process sharpens details and improves clarity, making GANs ideal for applications like medical imaging and video enhancement.
4. Are GANs difficult to train?
Training GANs can be challenging. Issues like mode collapse and instability often arise. You can address these problems by fine-tuning hyperparameters and using advanced techniques like Wasserstein GANs, which stabilize the training process.
5. What are some ethical concerns with GANs?
GANs can create deepfakes or misleading content, raising ethical concerns. You should ensure responsible use by following guidelines like GDPR. Protecting user data and addressing biases in generated outputs are also critical for ethical deployment.
Tip: Always evaluate the potential risks before using GANs in sensitive applications.
See Also
Investigating Synthetic Data Applications in Vision Systems
The Impact of Neural Networks on Vision System Innovation
Deep Learning’s Role in Advancing Machine Vision Technology









